论文笔记---Deblurring Shaken and Partially Saturated Images
抖动和部分饱和图像去模糊
摘要
我们解决了由相机抖动造成的模糊和饱和或过度曝光像素导致的图像去模糊的问题。饱和像素对于现有的非盲去模糊算法是一个问题,因为它们不符合图像形成过程是线性的这一假设,并且经常在去模糊输出中造成明显的伪像。我们提出一种包含传感器饱和度的前向模型,并使用它来推导出适当地处理饱和像素的去模糊算法。通过使用这个前向模型以及解释关于去模糊结果中的伪像的原因,我们得到比现有的去模糊算法显着更好的结果。我们进一步提出了前向模型的有效近似,导致显着的加速。
介绍
“抖动”图像去模糊工作近来已受到相当大的关注。在可靠地估计给定模糊图像的点扩散函数(PSF),并且反转模糊处理以恢复高质量清晰图像方面已经取得了显着进展。然而,“抖动”图像受到很少关注的一个特征是饱和像素。当场景的辐射度超过相机传感器的范围时,会导致这些饱和像素,从而以最大输出值(例如,对于8位图像为255)亮起亮点。对于那些试图在晚上拍照的人来说,这种效果应该是熟悉的,如电光源所显示的明显的明亮条纹,如图1(a)所示。这些明亮的像素,其截断值违反了许多算法所做的图像形成过程是线性的假设,并且因此可能在去模糊图像中引起突然的伪像。这可以在图1(b)&(c)中的去模糊图像中看到。
图像去模糊过程通常包括两个步骤。首先,估计PSF,其指定图像是如何模糊的。这可以使用“盲”去模糊算法来实现,该算法从模糊图像本身估计PSF,或者使用连接到相机的附加硬件,或借助相同场景的清晰参考图像来估计PSF。第二,给定PSF,使用“非盲”去模糊算法来估计清晰图像。 在这项工作中,我们使用Cho&Lee [4]的算法估计所有情况下的PSF,适用于空间变化的模糊(第2节)。然后,我们考虑包含饱和像素的图像非盲去模糊(因为PSF是已知的)。通过明确处理这些像素,我们可以产生比现有方法更好的结果。图1(d)示出了所提出的算法的输出,其包含比用于比较的两个现有算法少得多的伪像。

我们的主要贡献是提出一个包含传感器饱和度的相机抖动模糊的前向模型(第3.2节),并使用它来推导出正确处理饱和像素的理查森 - 露西算法的修改版本。我们提出通过明确地模拟去模糊图像中的不太好估计的像素,我们能够防止去模糊结果中的“振铃”伪像(第3.3节),如图1所示。我们还提出了在正向模型中空间变化模糊的有效的分段均匀近似,导致PSF估计和非盲去模糊步骤的显着加速(第4.3节)。
相关工作
饱和度在文献中没有得到广泛的关注,尽管它被引用为在去卷积算法中去模糊输出伪像的原因。例如,Fergus等人 [5] Cho&Lee [4]和Tai et al [20]提到饱和像素引起问题,有时显示它们对去模糊输出的影响,但是留下这个问题在将来的工作中解决。除此之外,Harmeling等人 [8],通过对模糊图像进行阈值处理来检测饱和像素,解决了多帧盲去模糊设置中的问题,以及在模糊过程中忽略这些。当相同场景的多个模糊图像可用时,可以安全地丢弃这些像素,因为在其它图像中通常将保留覆盖相同区域的不饱和像素。
用于相机抖动的单图像盲PSF估计已经被广泛研究,使用变分和最大后验(MAP)算法。Levin等人 [14]回顾了几种方法,并提供了一个用于比较空间不变模糊的真实标准数据集。虽然大多数工作都集中在空间不变模糊,但是还有几种方法也被提出用于空间变化的模糊[6,7,10,20,21]。
对于非盲目去模糊有许多算法存在,也许最著名的是理查森 - 露西算法[16,17]。最近的工作围绕着使用自然图像统计[1,10,11,13,20]的正则化,以抑制输出中的噪声,同时鼓励出现锐利边缘。
2. 模糊过程
在这项工作中,我们考虑以下图像形成过程的模型:我们正在拍摄静态场景,并且存在我们想要记录的这个场景的一些清晰的潜像f(用矢量表示)。但是,当相机的快门打开时,相机会移动,在这样的情况下捕获场景的不同视图序列。我们将假设每个视图可以通过应用一些转换Tk来建模清晰的图像f。记录的(模糊)图像g是场景的所有这些不同视图的总和,每个视图的持续时间加权:
其中权重wk与视图k所花费的时间成比例,并且 清晰图像f和模糊图像g是一个N维向量,其中N是像素数,并且每个Tk是一个NxN的稀疏矩阵。
清晰图像f和模糊图像g是一个N维向量,其中N是像素数,并且每个Tk是一个NxN的稀疏矩阵。
通常,变换Tk被假设为图像的2D平移,这使得等式 (1)使用2D卷积计算。在本文中,我们使用我们最近提出的空间变化相机抖动模糊模型,其中变换Tk是对应于相机围绕其光学中心的旋转的单应变换。然而,这项工作中提出的非盲去模糊算法同样适用于其他模型,空间变异或空间不变。
在非盲去模糊设置中,假定表征PSF的权重wk是已知的,而等式 (1)可以写成矩阵向量积

其中 给定PSF,非盲去模糊算法通常最大化观察到的模糊图像g在所有可能的潜在清晰图像f上的可能性,或者使潜在图像的后验概率最大化,给出关于其属性的一些先验知识。一个通俗的的例子是Richardson-Lucy(RL)[16,17]算法,其在泊松噪声模型[19]下收敛到潜在图像的最大似然估计,使用以下乘法更新方程:
给定PSF,非盲去模糊算法通常最大化观察到的模糊图像g在所有可能的潜在清晰图像f上的可能性,或者使潜在图像的后验概率最大化,给出关于其属性的一些先验知识。一个通俗的的例子是Richardson-Lucy(RL)[16,17]算法,其在泊松噪声模型[19]下收敛到潜在图像的最大似然估计,使用以下乘法更新方程:
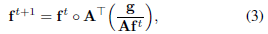
其中。表示元素乘法,分数表示元素除法,t表示迭代次数。
不幸的是,由数码相机产生的图像通常不遵循方程式(1)中的线性模型。所以非常适用于非盲去模糊算法如Richardson-Lucy可能会导致结果中的伪像,如图1所示。存储在图像文件中的像素值与场景辐射不直接成正比,原因主要有两个:(a)传感器的饱和度;(b)在将图像写入文件之前由相机应用于像素值的压缩曲线。为了处理后者,我们可以直接使用未应用任何压缩的原始图像文件,或者遵循预处理模糊图像的标准方法,应用固定曲线大致颠倒相机(通常为未知)的压缩曲线。然后在输出结果之前将曲线重新应用于去模糊图像。如图2所示,这将留下饱和作为图像形成模型中的非线性的剩余来源。

3. 明确处理饱和像素
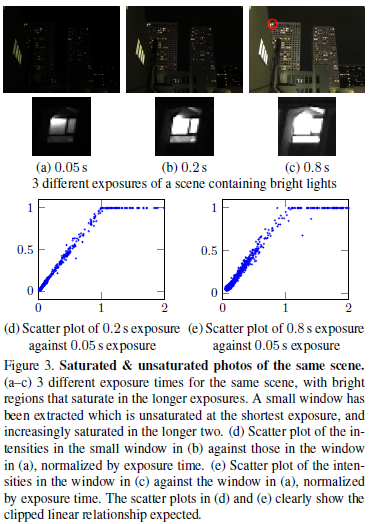
我们对传感器饱和度进行建模如下:传感器输出像素值与场景辐射成比例,达到一定限度,超过此值时,像素值将被限制在最大输出值。 该模型由图3中的数据支持,其显示了三种不同曝光中的亮光源之间的像素强度之间的关系。 短曝光(无饱和)和较长曝光(饱和度)下的像素值清楚地表现出这种剪切的线性关系。 随着曝光长度的增加,更多的像素饱和。
这提出了在执行非盲模糊算法时处理饱和度的两种可能的方法:(a)丢弃被截断的像素,使得我们仅使用遵循线性模型的数据,或(b)修改正向模型以考虑这种非线性关系。 我们在下面描述这两种方法。
3.1 丢弃饱和像素
可以通过定义阈值T来估计哪个模糊像素被饱和,在该阈值以上,模糊像素被认为是饱和的,因此是线性模型的异常值。如果我们丢弃这些像素,饱和像素的去模糊问题会变成丢失的数据去模糊。 通过定义不饱和(Inlier)像素z的二进制掩码,可以重新导出Richardson-Lucy算法以考虑缺失的数据,其中如果gi <T,每个元素zi = 1,否则为0。新的Richardson-Lucy更新方程是:

其中1是一个向量。对于不饱和像素gi,掩模zi = 1,括号中的项与标准RL更新相同。对于饱和(异常值)像素,zi = 0,因此括号中的项等于1。由于更新是乘法的,这意味着饱和观测gi对潜像f没有影响。
然而,阈值T的选择也会是一个问题; 低阈值可以从g中丢弃大量的内部像素,导致f的某些部分与数据分离。另一方面,高阈值可以将一些饱和像素视为内在因素,从而导致去模糊结果中的伪像。图4显示了使用公式 (4)对于阈值T的不同值。如图4所示,没有特定的阈值产生没有伪影的结果。在T值很高的地方,建筑物很好地去模糊了,但在灯光周围出现了伪影。在T值最低的情况下,灯光很好地被去模糊,但建筑物的外观被误删,因此在输出中保持模糊。
理想情况下,我们希望利用我们可用的所有数据,同时考虑到某些像素对其他像素更有用。 我们在以下部分描述这种方法。

3.2 饱和前向模型
代替试图将模糊图像分割成饱和和不饱和的区域,我们可以改变我们的前向模型来包括饱和过程。这避免了对哪些数据是内在或异常值作出先验决定,并允许我们使用模糊图像中的所有数据。为此,我们将响应函数R(·)引入到等式 (2),以使正向模型成为

其中函数R被应用到每个元素。使用此模型重新导出Richardson-Lucy算法产生新的更新方程:
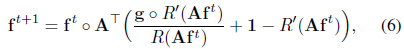
其中R,是R的导数。
R的一个选择将是简单地截断方程式(1)中的线性模型 在1(最大像素值),使用函数R(x)= min(x,1)。这种选择是经验验证的,如图3所示。然而,这个函数在x = 1时是不可微分的,即R,(1)没有定义。因此,我们使用平滑近似[3],其中

参数a控制近似的平滑度,在我们的所有实验中,我们设置a = 50。图5显示了与简单截断线性模型相比,R和R,的形状。

给定R的形状, 方程(6)可以容易地被解释:在线性部分 和
和 ,使得括号中的项与标准RL算法相同,而在饱和部分
,使得括号中的项与标准RL算法相同,而在饱和部分 和
和 ,使括号中的项等于1,对f没有影响。重要的是要注意,这两个方案没有使用阈值从模糊图像中检测到,而是从我们目前的潜像估计中自然出现,因此不需要将模糊图像明确分割成不饱和和饱和区域。我们将使用该更新规则的算法称为“饱和RL”。 图6显示了该方法在合成1D示例上的标准RL算法的优点。
,使括号中的项等于1,对f没有影响。重要的是要注意,这两个方案没有使用阈值从模糊图像中检测到,而是从我们目前的潜像估计中自然出现,因此不需要将模糊图像明确分割成不饱和和饱和区域。我们将使用该更新规则的算法称为“饱和RL”。 图6显示了该方法在合成1D示例上的标准RL算法的优点。
3.3 防止误差传播
重要的是要注意,即使使用正确的前向模型,我们不一定能够准确地估计f中的每一个潜在像素。在模糊处理中,潜像中的每个像素fj在模糊图像g中的多个像素上模糊。如果其中一些(或全部)饱和,我们将剩下关于fj的一组不完整的数据,我们对fj的估计可能不如我们有一整套不饱和观测值的准确性。这种错误估计是去除模糊输出中“振铃”伪影的一个来源; 在一个像素处的过度估计必须通过在相邻像素处的低估来平衡,这又必须由另一个过度估计来平衡。以这种方式,一个像素的错误在图像的波浪中向外扩展。 为了减轻这种影响,我们提出了Richardson-Lucy算法的第二个修改,以防止这些误差的传播。
我们首先将f分成两个不相交的区域:S,其中包括我们不太可能精确估计的亮像素,以及覆盖图像其余部分的U,我们可以准确地估计出来。我们相应地分解潜像:f = fU + fS。 我们的目标是防止误差从fS传播到fU。为了达到这个目的,我们提出仅使用不受S的任何像素影响的数据来估计fU。为此,我们首先定义与fS无关的模糊图像的区域(由V表示),通过使用 PSF的非零元素: ,其中UTk表示由Tk转换的集合U。通过采用U的所有变换版本,我们确保V仅包含完全独立于S的那些模糊像素。然后,可以通过定义对应于V的二进制掩码v来估计fU中仅使用V中的数据 并适应等式(4)的更新方程对于缺失数据的 Richardson-Lucy算法:
,其中UTk表示由Tk转换的集合U。通过采用U的所有变换版本,我们确保V仅包含完全独立于S的那些模糊像素。然后,可以通过定义对应于V的二进制掩码v来估计fU中仅使用V中的数据 并适应等式(4)的更新方程对于缺失数据的 Richardson-Lucy算法:

我们使用先前定义的“饱和RL”算法估计fS:

由于 Richardson-Lucy算法是一个迭代过程,我们事先不知道f中哪些部分属于U,哪个在S.因此,我们使用潜在图像上的阈值在每次迭代t执行分割:

我们分解f根据
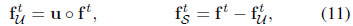
其中u是对应于U的二进制掩码。然后我们使用公式(8)和(9)计算V,更新fU和fS。并将它们重组形成我们对潜像f t + 1 = f t + 1 U + f t + 1 S的新估计。我们将该算法称为“组合RL”,图6示出了将其应用于合成1D示例的结果,证明了优于标准RL和“饱和RL”算法的优点。
虽然这种组合的RL算法涉及使用阈值来分割图像,但其效果不如第3.1节那么显着。 在这种情况下,阈值仅决定是否应使用所有可用数据或其子集来更新给定像素fj。 这与3.1节相反,其中数据的部分被丢弃,不再使用。 由于我们的目标是确保在fU中没有引入大的误差,所以我们将阈值设置得足够低,大多数潜在的亮像素被分配给S。经验上,我们选择 为本文的结果。
为本文的结果。
4.实现
在本节中,我们描述了所提出的算法的一些实现细节,所示结果的PSF估计,以及导致显着加速的正向模型的有效近似。
4.1 PSF估计
对于本文中所示的所有结果,我们使用Cho&Lee [4]提出的盲解模糊算法来估计PSF,适用于我们的空间变化模糊模型[21]。 由于空间考虑,我们建议读者参考[4]了解算法的细节。 使用该算法处理饱和图像所需的唯一修改是使用阈值来舍弃模糊图像的潜在饱和区域。 因为在这种情况下,目的只是估计PSF(而不是一个完整的去模糊图像),所以我们可以安全地丢弃所有这些像素,因为图像中饱和像素的数量与总像素数相比通常很小。 通常将保留足够的不饱和像素来估计PSF。
4.2 潜影分割
在组合RL算法中分割潜像的当前估计值时,我们采取额外的步骤来确保我们对可准确估计哪些像素进行保守估计。 首先,在等式 (10)对潜影阈值化后,我们使用半径为3像素的磁盘对U进行二进制侵蚀。 这样可以确保将所有低估像素正确分配给S(可能以错误地包括一些估计良好的像素为代价)。 相比之下,更少的伪像来自于将精确估计的像素错误地分配给S。 第二,为了避免引入两个区域之间的可见边界,我们使用标准偏差3像素的高斯滤波器稍微模糊掩模u,以在从等式11中的当前潜像f t提取ftU和ftS时产生更平滑的权重集合。
4.3 前向模型的有效近似
由于使用空间变化的模糊模型代替空间不变的模糊模型引起的额外的计算消耗,盲和非盲去模糊步骤都可能非常耗时。 公式 (1)中正态模型中的同形子Tk的数量可以很大,即使是中等大小的模糊:一个模糊30像素的大小,可能需要计算高达303 = 27000个同形体。 为了减少PSF估计和非盲去模糊的运行时间,我们扩展了Hirsch等人提出的局部均匀的“有效滤波流”近似值来处理公式(1)中形式的模糊模型。
局部均匀近似 这个想法是,对于平滑变化的模糊,如相机抖动模糊,附近的像素具有非常相似的点扩散功能。 因此,将模糊近似为局部均匀是合理的。在Hirsch等人提出的近似中,清晰图像f被覆盖有p个重叠块的粗糙网格,每个重叠块被建模为具有空间不变模糊。 块之间的重叠确保了模糊在整个图像上平滑变化,而不是在两个块之间的边界处突然变化。每个块具有空间不变模糊允许使用p个小卷积计算正向模型。 Hirsch等人 [9]分配每个块r空间不变模糊滤波器a(r),并且正向模型近似为:

其中矩阵F采用离散傅立叶变换,FH采用傅立叶逆变换(均使用FFT进行),Cr是从图像f中舍入第r个块的矩阵(并且因此CT r将其重新插入到其正确的位置)。 向量m是加窗函数,例如, Bartlett-Hann窗口,其产生相邻图像块之间的平滑过渡。
将近似应用于前向模型 在他们的原始工作中,Hirsch等人 [9]为每个块r存储单独的过滤器a(r)。 然而,给定公式 (1)中的模糊模型,它由一组权重w参数化,我们可以用w来写出每个a(r)。 对于每个块r,我们选择一个a(r)作为中心像素ir的点扩散函数,它由A的第i行给出。由于A在w中是线性的,所以我们可以构造一个矩阵Jr,使得a(r)= CrJrw。 每个Jr的元素只是矩阵Tk的元素的重新排列:Jr的元素(j; k)等于Tk的元素(ir; j)。 图7显示了近似值的质量如何随着使用的块数量而变化。 在我们的所有实验中,我们使用6x8网格的块。
用w表示每个滤波器a(r),我们可以将其代入方程 (12),并获得对于方程(1)的正向模型的以下近似:

这使得使用只有少量的频域卷积来快速计算正向模型。 此外,关于f和w的 的导数也可以使用少量的频域卷积和相关性来计算。 这三个操作是Cho&Lee [4]的盲PSF估计算法以及Richardson-Lucy算法中的计算瓶颈。
的导数也可以使用少量的频域卷积和相关性来计算。 这三个操作是Cho&Lee [4]的盲PSF估计算法以及Richardson-Lucy算法中的计算瓶颈。
5. 结论
图1和图8显示了使用第3.3节中描述的实际手持照片中提出的“组合RL”算法的非盲去除去模糊的结果。使用Cho&Lee [4]的算法(如第4.1节所述),从模糊图像本身估计这些图像的PSF。注意到标准的Richardson-Lucy算法和Krishnan & Fergus[11]的方法在饱和区域周围产生大量的振铃,而所提出的算法避免了这一点,而在其他地方没有质量损失。 在本文的所有结果中,我们对Richardson-Lucy算法进行了50次迭代。
作为4.3节描述的近似结果,我们能够在精确模型中获得盲PSF估计和非盲去模糊步骤的加速,质量没有明显的降低。 对于通常的1024x768图像,公式 (1)中的确切模型在我们的MATLAB实现中需要大约20秒钟,在我们的C实现中计算5秒,而在Intel Xeon 2.93GHz CPU上,我们的MATLAB实现近似为2秒。
6. 结论
在这项工作中,我们提出了一种通过相机抖动和饱和的模糊图像去模糊的方法。 所提出的算法能够有效地去除饱和图像,而不会引起振铃或牺牲细节,并且适用于任何模糊模型,无论是空间变化还是无空间变化。 我们还展示了一种用于计算空间变化模糊的有效近似,适用于任何模型,其具有方程式(1)的形式。
摘要
介绍本文解决了由相机抖动、饱和或过度曝光像素造成的模糊图像去模糊问题。饱和像素由于不满足图像成过程是线性的这一假设,并且会造成去模糊输出出现伪像,因此对已有的非盲去模糊算法是一个问题。故作者提出了一种包含饱和度在内的前向模型,并用它来得到正确处理饱和像素的去模糊算法。并由此得到比其他算法更好的效果。
第一部分
首先提出抖动图像中国饱和像素受到较少的关注,并且由于饱和像素的存在导致现有去模糊算法结果中出现伪像;
接着介绍图像去模糊过程分为两个步骤:(1)估计PSF;(2)给定PSF下,使用非盲去模糊算法对清晰图像进行估计。将问题视为包含饱和像素的图像非盲去模糊。通过明确地处理这类像素,得到比现有方法更好的效果。
本文的贡献有以下两点:(1)提出包含传感器饱和的相机抖动模糊的前向模型,并用它来得到正确处理饱和像素的Richardson-Lucy算法的修正版本。(2)提出了在正向模型中空间变化模糊的有效的分段均匀近似,导致PSF估计和非盲去模糊步骤的显着加速。
相关研究工作:
Fergus et al., Cho & Lee andTai et al.提到了饱和像素引起问题,会对去模糊输出有影响,但该问题未进行解决。
Harmeling等人,通过对模糊图像进行阈值处理来检测饱和像素,解决了多帧盲去模糊设置中的问题,并且在模糊过程中忽略这些
用于相机抖动的单图像盲PSF估计已经被广泛研究,使用变分和最大后验(MAP)算法。Levin等人回顾了几种方法,并提供了一个用于比较空间不变模糊的真实标准数据集。虽然大多数工作都集中在空间不变模糊,但是还有几种方法也被提出用于空间变化的模糊。
对于非盲目去模糊有许多算法存在,最著名的是理查森 - 露西算法。最近的工作围绕着使用自然图像统计的正则化,以抑制输出中的噪声,同时鼓励出现锐利边缘。
第二部分 模糊过程
f为清晰的图像,g为模糊图像,Tk为相应变换,wk为权重值(正比于在每张视图上的时间),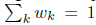 ,并且由此可得到模糊模型为:
,并且由此可得到模糊模型为:
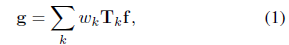
清晰图像f和模糊图像g都是N维向量,其中N表示像素数,并且每个Tk都是NxN的稀疏矩阵通常Tk都是图形的二维变换。因此可用二维卷积来计算方程(1)。在本文中,使用作者最近提出的空间变化相机抖动模糊模型,其中变换Tk是对应于相机围绕其光学中心的旋转的单应变换。然而,本文中提出的非盲去模糊算法同样适用于其他模型,空间变异或空间不变。
方程(1)还可表示为:
其中更新方程
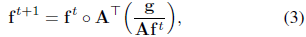
照相机拍摄的图像通常不满足方程1表示的线性模型,因此运用Richardson-Lucy算法会产生伪像。存储在图像文件中的像素值与场景辐射不直接成正比,原因主要有两个:(a)传感器的饱和度;(b)在将图像写入文件之前由相机应用于像素值的压缩曲线。为了处理后者,我们可以直接使用未应用任何压缩的原始图像文件,或者遵循预处理模糊图像的标准方法,应用固定曲线大致颠倒相机(通常为未知)的压缩曲线。然后在输出结果之前将曲线重新应用于去模糊图像。从而确保饱和作为图像形成模型中的非线性的剩余来源。
第三部分 明确处理饱和像素
论文笔记---Deblurring Shaken and Partially Saturated Images的更多相关文章
- Efficient Deblurring for Shaken and Partially Saturated Images
Try the online demo: http://willow-fd.rocq.inria.fr/unshake/ Overview One common feature of “shaken” ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
- 论文笔记(2):A fast learning algorithm for deep belief nets.
论文笔记(2):A fast learning algorithm for deep belief nets. 这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm ...
随机推荐
- CSS选择器【记录】
1.基本选择器 2.组合选择器 3.伪类选择器 4.伪元素选择器 CSS选择器规定了CSS规则会应用到哪些元素上 1.基本选择器 基本选择器:通配选择器.元素选择器.类选择器.ID选择器.属性选择器 ...
- 腾讯.NET&PHP面试题
在整个面试过程中,作为面试者的你,角色就是小怪兽,面试官的角色则是奥特曼,更不幸的是,作为小怪兽的你是孤身一人,而奥特曼却往往有好几个助攻,你总是被虐得不要不要的~ 作为复读一年才考上专科的我,遗憾的 ...
- HDU 1722 Cake (数论 gcd)(Java版)
Big Number 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1722 ——每天在线,欢迎留言谈论. 题目大意: 给你两个数 n1,n2 . 然后 ...
- javascript:面向对象和常见内置对象及操作
本文内容: 面向对象 常见内置对象及操作 首发日期:2018-05-11 面向对象: JavaScript 是面向对象的编程语言 (OOP).OOP 语言使我们有能力定义自己的对象和变量类型. 对象是 ...
- 实现wc部分功能 java
GitHub地址:https://github.com/carlylewen/ruangong 相关要求 基本功能 wc.exe -c file.c //返回文件 file.c 的字符数(实现 ...
- SQL Server如何用触发器捕获DML操作的会话信息
需求背景 上周遇到了这样一个需求,维护人员发现一个表的数据经常被修改,由于历史原因:文档缺少:以及维护人员的经常变更,导致他们对系统也业务也不完全熟悉,他们也不完全清楚哪些系统和应用程序会对这个表的数 ...
- php学习----面向对象
面向对象 项目代码都应该由单个能起子程序作用的对象组成 重用性.灵活性.扩展性 变量 $this 代表自身的对象. PHP_EOL 为换行符. PHP 中创建对象 类创建后,我们可以使用 new 运算 ...
- JavaScript -- 时光流逝(四):js中的 Math 对象的属性和方法
JavaScript -- 知识点回顾篇(四):js中的 Math 对象的属性和方法 1. Math 对象的属性 (1) E :返回算术常量 e,即自然对数的底数(约等于2.718). (2) LN2 ...
- February 26th, 2018 Week 9th Monday
A good beginning is half done. 良好的开端是成功的一半. We can't finish anything if we don't start, sometimes ge ...
- Lingo求解线性规划案例3——混料问题
凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 某糖果厂用原料A.B和C按不向比率混合加工而成甲.乙.丙三种糖果(假设混合加工中不损耗原料).原料A.B.C ...