【分布式事务】基于RocketMQ搭建生产级消息集群?
导读
目前很多互联网公司的系统都在朝着微服务化、分布式化系统的方向在演进,这带来了很多好处,也带来了一些棘手的问题,其中最棘手的莫过于数据一致性问题了。早期我们的软件功能都在一个进程中,数据的一致性可以通过数据库本地事务来加以控制。而在分布式架构下,原本比较完整的本地功能可能被拆分成了多个独立的服务进程。与之前相比,同样一笔业务订单此时可能会经历很多服务模块的处理,调用链路会变得很长,例如某电商平台,一笔购物订单可能会经过:商品中心、订单、支付、物流等多个服务的调用,而这可能还只是比较粗粒度的划分,某些比较大型的服务,如支付系统,可能本身又会按照分布式的架构拆分成多个微服务,所以整个业务的调用链路会变得更加冗长。
而这不可避免的就会产生数据不一致的问题,为了实现业务上的最终一致性,功能比较独立的系统,如订单系统与支付系统就会通过额外的业务逻辑设计来确保彼此之间的最终一致性,如订单系统会通过订单的支付状态来保持与支付系统的数据一致,而支付系统则会提供支付状态查询接口,或者实现最大可能的主动回调功能,来确保二者数据状态的最终一致。此外可能还会通过日终的订单对账来发现不一致的数据,并进行数据校正。
但是这些都只是业务逻辑上的手段,对于某些内部服务之间的调用,如果可以通过分布式事务解决方案来加以保证的话,其实是可以大大减少一些不必要的复杂业务逻辑的。实际上,目前市面上能够提供分布式事务解决方案、又比较成熟的开源技术框架比较少,而RocketMQ在4.3.0之后的版本提供了事务消息的功能,因为RocketMQ本身拥有比较多的生产实践的关系,所以这一功能备受关注,作者所在的公司也有一些实践。
以此为契机,为了给大家关于分布式事务一个比较清晰的认识,这里我打算以RocketMQ的事务消息功能为示例,来相对全面的总结下分布式事务的内容。本篇文章的主要内容,是先介绍如何搭建一套生产级的RocketMQ消息集群,以此准备下试验环境。在下一篇《【分布式事务】基于RocketMQ的分布式事务实现》会整体介绍下分布式事务的概念和原理,并做一些代码级的试验。
什么是RocketMQ
RocketMQ是阿里开源的并贡献给Apache基金会的一款分布式消息平台,它具有低延迟、高性能和可靠性、万亿级容量和灵活的可伸缩性的特点,单机也可以支持亿级的消息堆积能力、单机写入TPS单实例约7万条/秒,单机部署3个Broker,可以跑到最高12万条/秒。
基于以上强大的性能,以及阿里的技术影响力,RocketMQ目前在国内互联网公司中被使用得比较广泛。那么,我们先大概来了解一下RocketMQ的整体结构吧!
整个RocketMQ消息系统主要由如下4个部分组成:
从中间件服务角度来看整个RocketMQ消息系统(服务端)主要分为:NameSrv和Broker两个部分。
NameSrv:在RocketMQ分布式消息系统中,NameSrv主要提供两个功能:
提供服务发现和注册,这里主要是管理Broker,NameSrv接受来自Broker的注册,并通过心跳机制来检测Broker服务的健康性;
提供路由功能,集群(这里是指以集群方式部署的NameSrv)中的每个NameSrv都保存了Broker集群(这里是指以集群方式部署的Broker)中整个的路由信息和队列信息。这里需要注意,在NameSrv集群中,每个NameSrv都是相互独立的,所以每个Broker需要连接所有的NameSrv,每创建一个新的topic都要同步到所有的NameSrv上。
Broker:主要是负责消息的存储、传递、查询以及高可用(HA)保证等。其由如下几个子模块(源码总体上也是这么拆分的)构成:
remoting,是Broker的服务入口,负责客户端的接入(Producer和Consumer)和请求处理。
client,管理客户端和维护消费者对于Topic的订阅。
store,提供针对存储和消息查询的简单的API(数据存储在物理磁盘)。
HA, 提供数据在主从节点间同步的功能特性。
Index,通过特定的key构建消息索引,并提供快速的索引查询服务。
而从客户端的角度看主要有:Producer、Consumer两个部分。
Producer:消息的生产者,由用户进行分布式部署,消息由Producer通过多种负载均衡模式发送到Broker集群,发送低延时,支持快速失败。
Consumer:消息的消费者,也由用户部署,支持PUSH和PULL两种消费模式,支持集群消费和广播消息,提供实时的消息订阅机制,满足大多数消费场景。
来总结下,整个RocketMQ消息集群就是由NameSrv/Broker、Producer/Consumer组成的。为了让大家更清晰的理解它们之间的关系,我们以一条完整的信息流转为例,来看看RocketMQ消息系统是如何运转的,如下图所示:
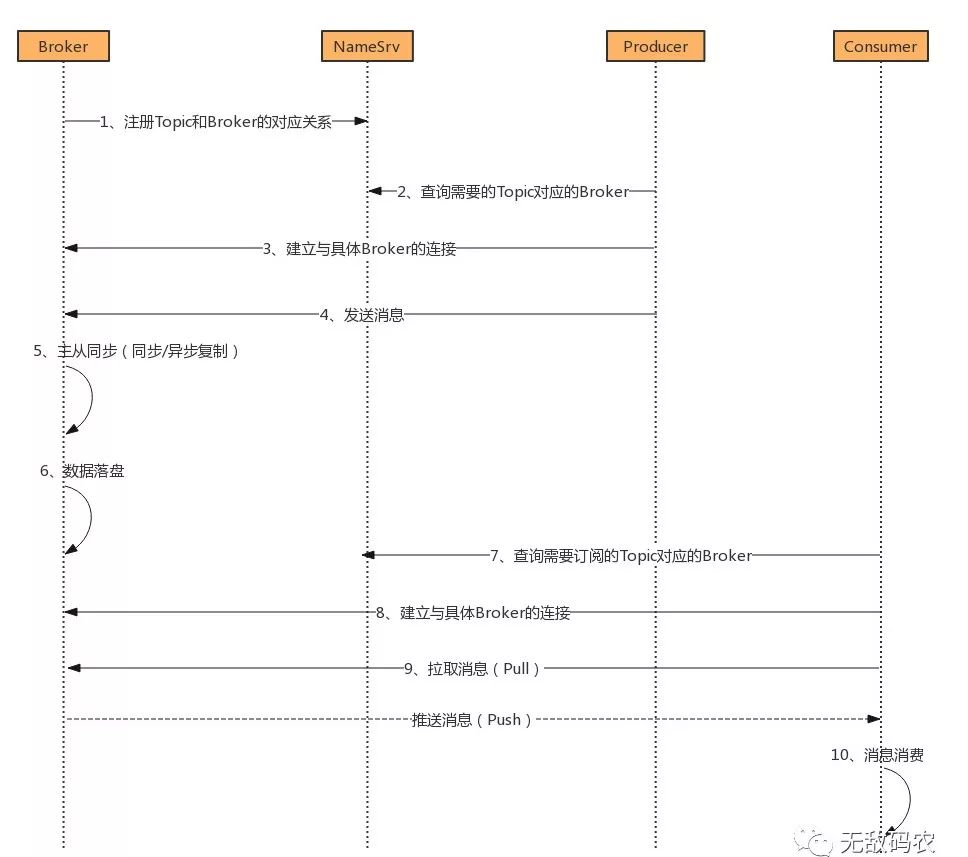
看到这里相信大家应该对RocketMQ有一个大致的了解了,那么下面我们就具体看看,如何搭建一套生产级的RocketMQ消息集群系统吧!
RocketMQ集群模式
RocketMQ集群部署有多种模式,对于NameSrv来说可以同时部署多个节点,并且这些节点间也不需要有任何的信息同步,这里因为每个NameSrv节点都会存储全量路由信息,在NameSrv集群模式下,每个Broker都需要同时向集群中的每个NameSrv节点发送注册信息,所以这里对于NameSrv的集群部署来说并不需要做什么额外的设置。
而对于Broker集群来说就有多种模式了,这里我先给大家介绍下这几种模式,然后我们再来看看生产级的部署方式是什么:
1)、单个Master模式
一个Broker作为主服务,不设置任何Slave,很显然这种方式风险比较大,存在单节点故障会导致整个基于消息的服务挂掉,所以生产环境不可能采用这种模式。
2)、多Master模式
这种模式的Broker集群,全是Master,没有Slave节点。这种方式的优缺点如下:
优点:配置会比较简单一些,如果单个Master挂掉或重启维护的话对应用是没有什么影响的。如果磁盘配置为RAID10(服务器的磁盘阵列模式,遗忘的同学可以自己查下资料)的话,即使在机器宕机不可恢复的情况下,由于RAID10磁盘本身的可靠性,消息也不会丢失(异步刷盘丢失少量消息,同步刷盘一条不丢),这种Broker的集群模式性能相对来说是最高的。
缺点:就是在单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前是不可以进行消息订阅的,这对消息的实时性会有一些影响。
3)、多Master多Slave模式(异步复制)
在这种模式下Broker集群存在多个Master节点,并且每个Master节点都会对应一个Slave节点,有多对Master-Slave,HA(高可用)之间采用异步复制的方式进行信息同步,在这种方式下主从之间会有短暂的毫秒级的消息延迟。
优点:在这种模式下即便磁盘损坏了,消息丢失的情况也非常少,因为主从之间有信息备份;并且,在这种模式下消息的实时性也不会受影响,因为Master宕机后Slave可以自动切换为Master模式,这样Consumer仍然可以通过Slave进行消息消费,而这个过程对应用来说则是完全透明的,并不需要人工干预;另外,这种模式的性能与多Master模式几乎差不多。
缺点:如果Master宕机,并且在磁盘损坏的情况下,会丢失少量的消息。
4)、多Master多Slave模式(同步复制)
这种模式与3)差不多,只是HA采用的是同步双写的方式,即主备都写成功后,才会向应用返回成功。
优点:在这种模式下数据与服务都不存在单点的情况,在Master宕机的情况下,消息也没有延迟,服务的可用性以及数据的可用性都非常高。
缺点:性能相比于异步复制来说略低一些(大约10%);另外一个缺点就是相比于异步复制,目前Slave备机还暂时不能实现自动切换为Master,可能后续的版本会支持Master-Slave的自动切换功能。
生产级RocketMQ集群
综合考虑以上集群模式的优缺点,在实际生产环境中目前基于RocketMQ消息集群的部署方式基本都是采用多Master多Slave(异步复制)这种模式,作者目前所在公司的生产环境的Rocket消息系统也是采用这种模式进行部署的。
以下为目前作者所在公司的实际部署结构:
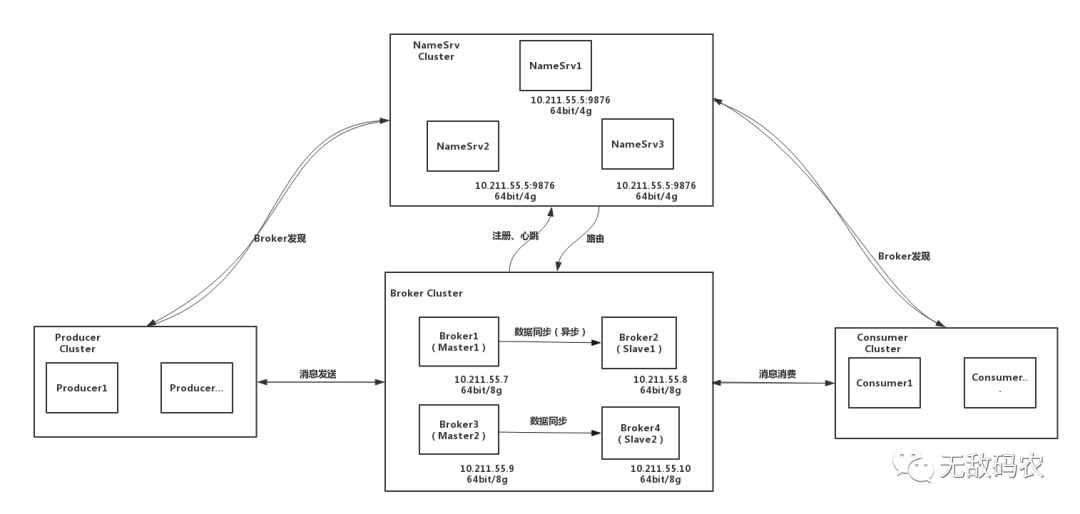
在以上实践中,部署了3个NameSrv节点,Broker采用2主2从的异步复制模式进行集群部署。
为了更好地理解RocketMQ的集群运行原理,接下来我们以4台虚拟机来模拟上述集群的搭建过程,假设这4台机器的IP分别为:
10.211.55.4
10.211.55.5
10.211.55.610.211.55.7
首先确保几台虚拟机上安装了JDK1.8+:
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" https://download.oracle.com/otn-pub/java/jdk/8u191-b12/2787e4a523244c269598db4e85c51e0c/jdk-8u191-linux-x64.tar.gz
JAVA_HOME=/opt/java/jdk1.8.0_191
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
其次我们打算通过RocketMQ的源码进行编译,因为源码是基于Maven开发的Java工程,所以我们需要安装下Maven环境:
wget https://archive.apache.org/dist/maven/binaries/apache-maven-3.2.1-bin.tar.gz
export MAVEN_HOME=/opt/apache-maven-3.2.1
export PATH=${PATH}:${MAVEN_HOME}/bin
#配置阿里云镜像
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
如果多台机器,没有必要依次下载,可以通过远程复制命令完成机器间的拷贝:
scp -r /opt/apache-maven-3.2.1/ root@10.211.55.6:/opt/
完成后,我们就可以在主机的指定目录下载RocketMQ的源码发布包(这里为4.3.2版本)进行编译了:
#download-4.3.2源码准备编译
wget http://mirror.bit.edu.cn/apache/rocketmq/4.3.2/rocketmq-all-4.3.2-source-release.zip
mvn -Prelease-all -DskipTests clean install -U
cd /opt/rocketmq-all-4.3.2/distribution/target/apache-rocketmq
以上动作需要在各个机器节点也同步操作!编译完成后,我们来规划下如何利用这4台虚拟机来实现“3个NameSrv节点、2组Master-Slave Broker集群”的效果。
1)Master-Broker-a的配置
#创建数据存储目录
[root@bogon local]# mkdir -p /usr/local/rocketmq/data/store
[root@bogon local]# mkdir -p /usr/local/rocketmq/data/store/commitlog
[root@bogon local]# mkdir -p /usr/local/rocketmq/data/store/consumequeue
[root@bogon local]# mkdir -p /usr/local/rocketmq/data/store/index
[root@bogon local]# mkdir -p /usr/local/rocketmq/data/store/checkpoint
[root@bogon local]# mkdir -p /usr/local/rocketmq/data/store/abort
#切换服务器目录为对应的配置文件目录
cd /opt/rocketmq-all-4.3.2/distribution/target/apache-rocketmq/conf
cd 2m-2s-async //这里因为我们采用的是异步复制模式,所以需要编辑2m-2s-async中的配置文件
#编辑Broker集群配置文件
[root@bogon 2m-2s-async]# vim broker-a.properties
#broker所属哪个集群,默认【DefaultCluster】
brokerClusterName=DefaultCluster
#broker 实列名称,主从关系的需要保持名称一致
brokerName=broker-a
#brokerId,必须是大等于0的整数,0表示Master,>0表示Slave
brokerId=0
#删除文件的时间点,默认为凌晨4点
deleteWhen=04
#文件保留时间,默认为48小时
fileReservedTime=48
#-ASYNC_MASTER 异步复制Master
#-SYNC_MASTER 同步双写Master
#-SLAVE
brokerRole=ASYNC_MASTER
#刷盘方式
#-ASYNC_FLUSH 异步刷盘
#-SYNC_FLUSH 同步刷盘
flushDiskType=ASYNC_FLUSH
#NameSrv集群地址
namesrvAddr=10.211.55.4:9876;10.211.55.5:9876;10.211.55.6:9876
#broker对外服务的监听端口
listenPort=10911
defaultTopicQueueNums=4
#是否允许broker自动创建Topic,建议线下开启,线上关闭,默认【true】
autoCreateTopicEnable=false
#是否允许broker自动创建订阅组,建议线下开启,线上关闭,默认【true】
autoCreateSubscriptionGroup=false
mapedFileSizeCommitLog=1073741824
mapedFileSizeConsumeQueue=50000000
destroyMapedFileIntervalForcibly=120000
redeleteHangedFileInterval=120000
diskMaxUsedSpaceRatio=88
storePathRootDir=/usr/local/rocketmq/data/store
storePathCommitLog=/usr/local/rocketmq/data/store/commitlog
#消费队列存储路径
storePathConsumeQueue=/usr/local/rocketmq/data/store/consumequeue
#消息索引存储路径
storePathIndex=/usr/local/rocketmq/data/store/index
#checkpoint文件存储路径
storeCheckpoint=/usr/local/rocketmq/data/store/checkpoint
#abort文件存储路径
abortFile=/usr/local/rocketmq/data/store/abort
maxMessageSize=65536
flushCommitLogLeastPages=4
flushConsumeQueueLeastPages=2
flushCommitLogThoroughInterval=10000
flushConsumeQueueThoroughInterval=60000
checkTransactionMessageEnable=false
sendMessageThreadPoolNums=128
pullMessageThreadPoolNums=128
2)、Slave-Broker-a的配置
#创建数据存储目录
[root@bogon local]# mkdir -p /usr/local/rocketmq/data/store
[root@bogon local]# mkdir -p /usr/local/rocketmq/data/store/commitlog
[root@bogon local]# mkdir -p /usr/local/rocketmq/data/store/consumequeue
[root@bogon local]# mkdir -p /usr/local/rocketmq/data/store/index
[root@bogon local]# mkdir -p /usr/local/rocketmq/data/store/checkpoint
[root@bogon local]# mkdir -p /usr/local/rocketmq/data/store/abort
#切换服务器目录为对应的配置文件目录
cd /opt/rocketmq-all-4.3.2/distribution/target/apache-rocketmq/conf
cd 2m-2s-async //这里因为我们采用的是异步复制模式,所以需要编辑2m-2s-async中的配置文件
#修改Slaves
[root@localhost 2m-2s-async]# vim broker-a-s.properties
#broker所属的那个集群,默认【DefaultCluster】
brokerClusterName=DefaultCluster
#broker实例名称,主从关系的需要保持名称一致
brokerName=broker-a
#brokerid,必须是大于0的整数,0表示Master,>0表示Slave,
#一个Master可以挂多个Slave,Master与Slave通过brokerName来配对,默认【0】
brokerId=1
#删除文件时间点,默认为凌晨4点
deleteWhen=04
#文件保留时间,默认48小时
fileReservedTime=48
#broker角色,这里为Slave节点
brokerRole=SLAVE
#刷盘方式 -ASYNC_FLUSH 异步刷盘;-SYNC_FLUSH 同步刷盘
flushDiskType=ASYNC_FLUSH
#NameSrv节点地址
namesrvAddr=10.211.55.4:9876;10.211.55.5:9876;10.211.55.6:9876
#Broker对外服务的监听端口,默认【10911】
listenPort=10911
defaultTopicQueueNums=4
#是否允许broker自动创建Topic,建议线下开启,线上关闭,默认【true】
autoCreateTopicEnable=false
#是否允许broker自动创建订阅组,建议线下开启,线上关闭,默认【true】
autoCreateSubscriptionGroup=false
mapedFileSizeCommitLog=1073741824
mapedFileSizeConsumeQueue=50000000
destroyMapedFileIntervalForcibly=120000
redeleteHangedFileInterval=120000
diskMaxUsedSpaceRatio=88
storePathRootDir=/usr/local/rocketmq/data/store
storePathCommitLog=/usr/local/rocketmq/data/store/commitlog
#消费队列存储路径
storePathConsumeQueue=/usr/local/rocketmq/data/store/consumequeue
#消息索引存储路径
storePathIndex=/usr/local/rocketmq/data/store/index
#checkpoint文件存储路径
storeCheckpoint=/usr/local/rocketmq/data/store/checkpoint
#abort文件存储路径
abortFile=/usr/local/rocketmq/data/store/abort
maxMessageSize=65536
flushCommitLogLeastPages=4
flushConsumeQueueLeastPages=2
flushCommitLogThoroughInterval=10000
flushConsumeQueueThoroughInterval=60000
checkTransactionMessageEnable=false
sendMessageThreadPoolNums=128
pullMessageThreadPoolNums=128
3)、Master-Broker-b的配置
参考Master-Broker-a的配置方式,只需要改下“brokerName=broker-b”即可,其他一样!
4)、Slave-Broker-b的配置
参考Slave-Broker-a的配置,只需要改下“brokerName=broker-b”即可,其他一样!
至此,我们就完成了整个RocketMQ集群的配置了!接下来我们启动整个集群。
#首先我们需要关闭各个节点的防火墙(很重要)
service iptables stop
#CentOs7
systemctl stop firewalld
#先分别启动三个NameSrv节点
cd /opt/rocketmq-all-4.3.2/distribution/target/apache-rocketmq
nohup sh bin/mqnamesrv &
tail -f ~/logs/rocketmqlogs/namesrv.log
#启动Broker集群
#启动Master broker-a服务(10.211.55.4)
cd /opt/rocketmq-all-4.3.2/distribution/target/apache-rocketmq/bin/
[root@bogon bin]#
nohup sh mqbroker -c /opt/rocketmq-all-4.3.2/distribution/target/apache-rocketmq/conf/2m-2s-sync/broker-a.properties >/dev/null 2>&1 &
#启动Slave broker-a-s服务
cd /opt/rocketmq-all-4.3.2/distribution/target/apache-rocketmq/bin/
nohup sh mqbroker -c /opt/rocketmq-all-4.3.2/distribution/target/apache-rocketmq/conf/2m-2s-sync/broker-a-s.properties >/dev/null 2>&1 &
#启动Master broker-b服务(10.211.55.6)
cd /opt/rocketmq-all-4.3.2/distribution/target/apache-rocketmq/bin/
nohup sh mqbroker -c /opt/rocketmq-all-4.3.2/distribution/target/apache-rocketmq/conf/2m-2s-sync/broker-b.properties >/dev/null 2>&1 &
#启动Slave broker-b-s服务(10.211.55.7)
cd /opt/rocketmq-all-4.3.2/distribution/target/apache-rocketmq/bin
nohup sh mqbroker -c /opt/rocketmq-all-4.3.2/distribution/target/apache-rocketmq/conf/2m-2s-sync/broker-b-s.properties >/dev/null 2>&1 &
到这里,我们就完成了RocketMQ生产级集群的模拟搭建,可以通过jps命令检查各节点NameSrv&Broker进程是否启动成功。
集群启动成功后,可以通过常用命令来进行查看!如:
#查看所有消费组group
[root@bogon bin]# sh mqadmin consumerProgress -n 10.211.55.6:9876
#查看集群消息
[root@bogon bin]# sh mqadmin clusterList -n 10.211.55.5:9876
由于篇幅的关系到这里本篇文章的内容就结束了!在下一篇文章中我们会详细介绍分布式事务的概念,敬请关注!
备注:本文首发于微信公众号「无敌码农」,感兴趣的朋友也可以关注下微信公众号,提前收看更多精彩内容!

【分布式事务】基于RocketMQ搭建生产级消息集群?的更多相关文章
- 基于 Docker 搭建 Consul 多数据中心集群
本文介绍了在 Windows 10 上基于 Docker 搭建 Consul 多数据中心集群的步骤,包括 Consul 镜像的拉取和容器的创建,每个数据中心对应服务端节点和客户节点的创建,节点之间相互 ...
- 一台虚拟机,基于docker搭建大数据HDP集群
前言 好多人问我,这种基于大数据平台的xxxx的毕业设计要怎么做.这个可以参考之前写得关于我大数据毕业设计的文章.这篇文章是将对之前的毕设进行优化. 个人觉得可以分为两个部分.第一个部分就是基础的平台 ...
- 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 二.前置条件 三.Spark集群搭建 3.1 下载解压 3.2 配置环境变量 3.3 集群配置 3.4 安装包分发 四.启 ...
- Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群
一.集群规划 这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop00 ...
- Spark 系列(七)—— 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 入门大数据---基于Zookeeper搭建Spark高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 基于keepalived搭建MySQL高可用集群
MySQL的高可用方案一般有如下几种: keepalived+双主,MHA,MMM,Heartbeat+DRBD,PXC,Galera Cluster 比较常用的是keepalived+双主,MHA和 ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
- Kafka —— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
随机推荐
- AX_CreateAndPostPurch
static void CreateAndPostPurch(Args _args) { List il = new List(Types::Record); DocumentNum Document ...
- 面向对象(特殊成员 组合 self)
- mysql sql mode
/usr/local/mysql/bin/mysqld --verbose --help | grep -A 1 'Default options' (1)关于配置文件路径 有时候,我发现虽然尝试修改 ...
- 阿里巴巴Java编码规范插件安装使用指南
编码规范插件安装使用指南 阿里技术公众号公布的<阿里巴巴Java开发规约>,瞬间引起全民代码规范的热潮,后又发布了PDF的终极版,大家踊跃留言,期待配套的静态扫描工具开放出来. 为了让开发 ...
- Python Day 12
阅读目录: 内容回顾 函数默认值的细节 三元表达式 列表与字典推导式 函数对象 名称空间 函数嵌套的定义 作用域 ##内容回顾 # 字符串的比较 -- 按照从左往右比较每一个字符,通过字符对应的asc ...
- 学以致用三十一-----IPAddressField has been removed
python 和 django版本 在进行makemigrations的时候报错 设置的字段 class Servers(models.Model): '''服务器信息''' hostname = m ...
- shell编写自动化安装dhcp服务
#!/bin/bash#Auth:Darius#自动化安装dhcp服务#"$1"为测试IP,用来查看IP段是否能通eno=`ifconfig|awk '{print $1}'|he ...
- SVN服务端和客户端的安装与搭建
版权声明:本文为博主原创文章,转载请注明原文出处. https://blog.csdn.net/zzfenglin/article/details/50931462 SVN简介 SVN全名Subver ...
- ubuntu安装spyder和jupyter notebook
ubuntu安装spyder和jupyter notebook 安装spyder 安装spyder sudo apt install spyder sudo apt install spyder3 安 ...
- 启动eclipse could not create the java Vittual Machine
查询并几种方法: 1.都说是 eclipse.ini 环境初始文件的内存问题,续增大堆内存大小,具体配置如,如果找不到问题所在可以试试(该方法是确定环境变量没问题下试行) -Xms64m-Xmx25 ...