Python开发【第十篇】:Redis
缓存数据库介绍
NoSQL(Not Only SQL),即"不仅仅是SQL",泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应对web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
NoSQL数据库的四大分类
有四大NoSQL类型:键值存储(key-value store)、文件存储(document store)、列导向的数据库(Column-Oriented Database)和图形数据库(graph database)。每种类型都解决了传统关系数据库无法解决的问题。实际的实现往往是这些组合的组合。例如结合NoSQL类型,Orientdb是一个多模式的数据库。Orientdb是图形数据库,每个节点都是一个文档。
键值(key-value)存储数据库
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/Value模型对于IT系统来说的优势在于简单、易部署。但是如果DBA只对部分值进行查询或更新的时候,Key/Value就显得效率低下了。代表数据库Tokyo Cabinet/Tyrant、Redis、Voldemort、Oracle BDB。
列存储数据库
这部分数据库通常是用来应对分布式存储的海量数据。键任然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。代表数据库Cassandra、HBase、Riak。
文档型数据库
文档型数据库的灵感来自于Lotus Notes办公软件,而且它同第一种键值存储类似。该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。代表数据库CouchDB、MongoDB,国内SequoiaDB。
图形(Graph)数据库
图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多台服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。代表数据库Neo4J、InfoGrid、Infinite Graph。
因此NoSQL数据库在以下几种情况比较适用:1、数据模型比较简单;2、需要灵活性更强的IT系统;3、对数据库性能要求较高;4、不需要高度的数据一致性;5、对于给定key比较容易映射复杂值的环境。
NoSQL数据库的四大分类对比
|
分类 |
代表数据库 |
典型应用场景 |
数据模型 |
优点 |
缺点 |
|
键值(key-value) |
Tokyo Cabinet/Tyrant、Redis、Voldemort、Oracle BDB |
内容缓存,主要用于处理大量数据的高访问负载,也用于一些日子系统。 |
key指向value的键值对,通常用hash table来实现。 |
查找速度快 |
数据无结构化,通常只被当作字符串或者二级制数据。 |
|
列存储数据库 |
Cassandra、HBase、Riak |
分布式的文件系统 |
以列簇式存储,将同一列数据存在一起 |
查找速度快,可扩展性强,更容易进行分布式扩展 |
功能相对局限性 |
|
文档型数据库 |
CouchDB、MongoDB |
web应用(与key-value类似,value是结构化的,不同的是数据库能够了解value的内容) |
key-value对应的键值对,value为结构化数据 |
数据结构要求不严格,表结构可变,不需要像关系数据库一样需要预先定义表结构 |
查询性能不高,而且缺乏统一的查询语法 |
|
图形(Graph)数据库 |
Neo4J、InfoGrid、Infinite Graph |
社交网络、推荐系统等。专注于构建关系图谱 |
图结构 |
利用图结构相关算法。比如最短路径寻址,N度关系查找等。 |
很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。 |
Redis
介绍
redis是业界主流的key-value nosql数据库之一。与Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis优点
异常快速:Redis是非常快的,每秒可以执行大约110000设置操作,81000个/秒的读取操作。
支持丰富的数据类型:Redis支持最大多数开发人员已经知道数据类型,如列表、集合、可排序集合、哈希等。这使得在应用中很容易解决各种问题,因为我们知道哪些问题处理使用哪些数据类型更好解决。
操作都是原子的:所有Redis的操作都是原子,从而确保当两个客户同时访问Redis服务器得到的是更新后的值(最新值)。
MultiUtility工具:Redis是一个多功能实用工具,可以在缓存、消息传递队列中使用(Redis原生支持发布/订阅),在应用程序中web应用程序会话,网站网页点击数等任何短暂的数据。
Redis缺点
持久化:Redis直接将数据存储到内存中,要将数据保存到磁盘上,Redis可以使用两种方式实现持久化过程。定时快照(snapshot),每隔一段时间将整个数据库写到磁盘上,每次均是写全部数据,代价非常高。基于语句追加(aof),只追踪变化的数据,但是追加的log可能过大,同时所有的操作均重新执行一遍,回复速度慢。
占用内存过高。
修改配置文件,进行重启,将硬盘中的数据加载进内存,时间比较久。这个过程中redis不能提供服务。
Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。为了避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费。
安装Redis环境
redis官网:https://redis.io/
下载源码,解压后编译源码
- wget http://download.redis.io/releases/redis-3.0.6.tar.gz
- tar xzf redis-3.0.6.tar.gz
- cd redis-3.0.6
- make
编译完成后,进入redis-3.0.6目录。将redis.conf中的daemonize配置为yes(以守护进程方式运行)。
进入src目录启动redis,指定配置文件位置,并后台运行。
- redis-server /root/redis-3.0.6/redis.conf &
查看是否启动
- lsof -i:6379
- COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
- COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
- redis-ser 1612 root 4u IPv6 13114 0t0 TCP *:6379 (LISTEN)
- redis-ser 1612 root 5u IPv4 13116 0t0 TCP *:6379 (LISTEN)
运行redis客户端redis-cli。
- redis-cli
- 127.0.0.1:6379> ping
- PONG
- 127.0.0.1:6379>
至这说明已经成功安装了redis。
Redis API使用
连接方式
操作模式
Redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
- __author__ = 'Golden'
- #!/usr/bin/env python3
- # -*- coding:utf-8 -*-
- import redis
- # 连接池
- pool = redis.ConnectionPool(host='192.168.31.128',port=6379)
- r = redis.Redis(connection_pool=pool)
- r.set('foo','golden')
- print(r.get('foo'))
连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
基本操作
String操作
Redis中的String在内存中按照一个name对应一个value来存储。
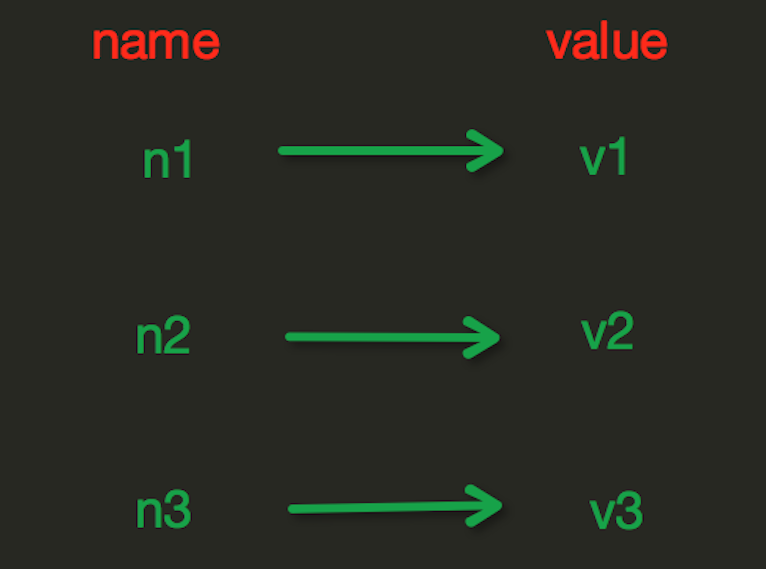
set(name,value,ex=None,px=None,nx=False,xx=False)
在Redis中设置值,默认不存在则创建,存在则修改。
ex过期时间(秒);px过期时间(毫秒);nx如果设置为True,则只有name不存在时,当前set操作才执行;xx如果设置为True,则只有name存在时,当前set操作才执行。
setnx(name,value)
设置值,只有name不存在时,执行设置操作(添加)。
psetex(name,time_ms,value)
time_ms过期时间(毫秒)
mset(*args,**kwargs)
批量设置值mset(k1='v1',k2='v2')或mget({'k1':'v1','k2':'v2'})。
get(name)
获取值。
mget(keys,*args)
批量获取值,mget('name1','name2')或r.mget(['name1','name2']。
getset(name,value)
设置新增并获取原来的值。
getrange(key,start,end)
获取子序列(根据字节获取,非字符)。一个汉字3个字节。
setrange(name,offset,value)
修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)。
setbit(name,offset,value)
对name对应值的二进制表示的位进行操作。offset位的索引将值变换成二进制后再进行索引,value值只能是1或0。例如setbit('name',6,1)表示将字符串name用二进制表示后,将第六位设置为1。
getbit(name,offset)
获取name对应的值的二进制表示中的某位的值。
bitcount(key,start=None,end=None)
获取name对应的值的二进制表示中1的个数。
strlen(name)
获取name对应值的字节长度(一个汉字3个字节)。
incr(self,name,amount=1)
自增name对应的值,当name不存在时,则创建name=amount,否则就自增,自增数必须是整数。
incrbyfloat(self,name,amount=1.0)
自增name对应的值,当name不存在时,则创建name=amount,否则就自增,自增数浮点型。
decr(self,name,amount=1)
自减name对应的值,当name不存在时,则创建name=amount,否则就自减,自减数整数。
append(key,value)
在key对应的值后面追加内容value。
Hash操作
Hash表现形式上有些像python中的dict,可以存储一组关联性较强的数据,redis中的Hash在内存中的存储格式如下图。
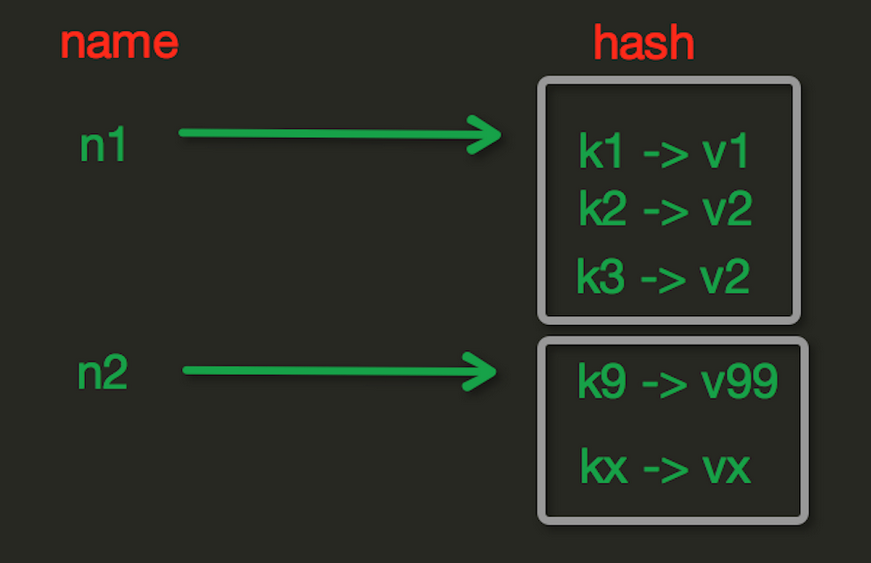
hset(name,key,value)
name对应的hash中设置一个键值对,不存在则创建,否则修改。
hmset(name,mapping)
在name对应的hash中批量设置键值对。
hgetall(name)
获取name对应hash的所有键值。
hlen(name)
获取name对应的hash中键值对的个数。
hkeys(name)
获取name对应的hash中所有的key值。
hvals(name)
获取name对应的hash中所有的value值。
hexists(name,key)
检查name对应的hash是否存在当前传入的key。
hdel(name,*keys)
将name对应的hash中指定key的键值对删除。
hincrby(name,key,amount=1)
自增name对应的hash中的指定key的值,不存在则创建key=amount。amount自增数(整数)。
hincrbyfloat(name,key,amount=1.0)
自增name对应的hash中的指定key的值,不存在则创建key=amount。amount自增数(浮点数)。
hscan_iter(name,match=None,count=None)
利用yield封装hscan创建生成器,实现分批去redis中获取数据。
List
Redis中的List在内存中安装一个name对应一个List来存储。如下图所示。

lpush(name,values)
在name对应的list中添加元素,每个新的元素都添加到列表的最左边。如r.lpush('test',11,22,33),保持顺序为33,22,11。rpush(name,values)表示从右向左操作。
lpushx(name,value)
在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边。rpushx(name,value)表示从右向左操作。
llen(name)
name对应的list元素的个数。
linsert(name,where,refvalue,value)
在name对应的列表的某一个值前或后插入一个新值。where:BEFORE或AFTER;refvalue:标杆值,即在它前后插入数据;value:要插入的数据。
r.lset(name,index,value)
对name对应的list中的某一个索引位置重新赋值。index:list的索引位置。
r.lrem(name,num,value)
在name对应的list中删除指定的值。value:要删除的值;num>0:从表头开始向表尾搜索,移除与value相等的元素,删除数量为num个;num<0:从表尾开始向表头搜索,移除与value相等的元素,删除数量为num个;num=0:移除表中所有与value相等的值。
lpop(name)
在name对应的列表的左侧获取第一个元素并在列表中移除,返回第一个元素。
lindex(name,index)
在name对应的列表中根据索引获取列表元素。
lrange(name,start,end)
在name对应的列表分片获取数据。
ltrim(name,start,end)
在name对应的列表中移除没有在start-end索引之间的值。
rpoplpush(src,dst)
从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边。src:要取数据的列表的name;dst:要添加数据的列表的name。
blpop(keys,timeout)
将多个列表排列,按照从左到右去pop对应列表的元素。timeout:超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒),0表示永远阻塞。
brpoplpush(src,dst,timeout=0)
从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧。
set
Redis的set是string类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
sadd(name,values)
name对应的集合中添加元素。
scard(name)
获取name对应的集合中元素个数。
sdiff(keys,*args)
在第一个name对应的集合中且不在其他name对应的集合元素的集合。
sdiffstore(dest,keys,*args)
获取第一个name对应的集合中且不在其他name对应的集合元素,再将其新加入到dest对应的集合中。
sinter(keys,*args)
获取多个name对应集合的交集。
sinterstore(dest,keys,*args)
获取多个name对应集合的并集,再将其加入到dest对应的集合中。
sismember(name,value)
检查value是否是name对应的集合的成员。
smembers(name)
获取name对应的集合的所有成员。
smove(src,dst,value)
将某个成员从一个集合中移动到另一个集合。
spop(name)
从集合的右侧(尾部)移除一个成员,并将其返回。
srandmember(name,numbers)
从name对应的集合中随机获取numbers个元素。
srem(name,values)
在name对应的集合中删除某些值。
sunion(keys,*args)
获取多个name对应的集合的并集。
sunionstore(dest,keys,*args)
获取多个name对应的集合的并集,并将结果保存到dest对应的集合中。
有序集合,在集合的基础上为每个元素排序,元素的排序需要根据另一个值来进行比较,所以,对于有序集合每一个元素有两个值,即值和分数,分数用来做排序。
zadd(name,*args,**kwargs)
在name对应的有序集合中添加元素。
zcard(name)
获取name对应的有序集合元素的数量。
zcount(name,min,max)
获取name对应的有序集合中分数在min和max之间的个数。
zincrby(name,value,amount)
对指定成员的分数加上增量value。
r.zrange(name,start,end,desc=False,score_cast_func=float)
按照索引范围获取name对应的有序集合的元素。
start:有序集合索引起始位置(非分数)。
end:有序集合索引结束位置(非分数)。
desc:排序规则,默认按照分数从小到大排序。
withscores:是否获取元素的分数,默认只获取元素的值。
score_cast_func:对分数进行数据转换的函数。
zrevrange(name,start,end,withscores=False,score_cast_func=float)
从大到小排序。
zrangebyscore(name,min,max,start=None,num=None,withscores=False,score_cast_func=float)
按照分数范围获取name对应的有序集合的元素。
zrevrangebyscore(name,max,min,start=None,num=None,withscores=False,score_cast_func=float)
从大到小排序。
zrank(name,value)
获取某个值在name对应的有序集合中的排行
zrevrank(name,value)
从大到小排序。
zrem(name,values)
删除name对应的有序集合中值是values的成员。
zremrangebyrank(name,min,max)
根据排行范围删除。
zremrangebyscore(name,min,max)
根据分数范围删除。
zscore(name,value)
获取name对应有序集合中value对应的分数。
zinterstore(dest,keys,aggregate=None)
获取两个有序集合的交集,如果遇到相同值不同分数则按照aggregate进行操作,aggregate的值为SUM、MIN、MAX。
其他操作
delete(*names)
根据name删除redis中的任意数据类型。
exists(name)
检测redis的name是否存在。
keys(pattern='*')
根据key匹配获取redis的name。
expire(name,time)
为某个redis的某个name设置超时时间。
rename(src,dst)
对redis的name重命名。
move(name,db)
将redis的某个值移动到指定的db下。
randomkey()
随机获取一个redis的name(不删除)。
type(name)
获取name对应值的类型。
管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作。如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline是原子性操作。(原子性操作是指不会被线程调度机制打断的操作,这种操作一旦开始就一直运行到结束,中间不会有任何context switch(切换到另一个线程))
发布订阅
Redis发布订阅(pub/sub)是一种消息通信模式,发送者(pub)发送消息,订阅者(sub)接收消息。Redis客户端可以订阅任意数量的频道。下图展示了频道channel1,以及订阅这个频道的三个客户端client1、client2和client5之间的关系。

当有新消息通过publish命令发送给频道channel1时,这个消息就会被发送给订阅它的三个客户端。

RedisHelper_basic
- __author__ = 'Golden'
- #!/usr/bin/env python3
- # -*- coding:utf-8 -*-
- import redis
- class RedisHelper(object):
- """
- RedisHelper
- """
- def __init__(self):
- self.__conn = redis.Redis(host='192.168.31.128')
- self.chan_sub = 'channel1'
- self.chan_pub = 'channel1'
- def public(self,msg):
- self.__conn.publish(self.chan_pub,msg)
- return True
- def subscribe(self):
- pub = self.__conn.pubsub()
- pub.subscribe(self.chan_sub)
- pub.parse_response()
- return pub
发布者
- __author__ = 'Golden'
- #!/usr/bin/env python3
- # -*- coding:utf-8 -*-
- import redisHelper_basic
- obj = redisHelper_basic.RedisHelper()
- obj.public('hello')
订阅者
- __author__ = 'Golden'
- #!/usr/bin/env python3
- # -*- coding:utf-8 -*-
- import redisHelper_basic
- obj = redisHelper_basic.RedisHelper()
- redis_sub = obj.subscribe()
- while True:
- msg = redis_sub.parse_response()
- print(msg)
结果
- [b'message', b'channel1', b'hello']
Python开发【第十篇】:Redis的更多相关文章
- Python开发【第二篇】:初识Python
Python开发[第二篇]:初识Python Python简介 Python前世今生 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏 ...
- Python开发【第一篇】:目录
本系列博文包含 Python基础.前端开发.Web框架.缓存以及队列等,希望可以给正在学习编程的童鞋提供一点帮助!!! Python开发[第一篇]:目录 Python开发[第二篇]:初识Python ...
- Python 学习 第十篇 CMDB用户权限管理
Python 学习 第十篇 CMDB用户权限管理 2016-10-10 16:29:17 标签: python 版权声明:原创作品,谢绝转载!否则将追究法律责任. 不管是什么系统,用户权限都是至关重要 ...
- Python开发【第一篇】:目录
本系列博文包含Python基础.前端开发.Web框架.缓存以及队列等,希望可以给正在学习Python编程的朋友们提供一点帮助! .Python开发[第一篇]:目录 .Python开发[第二篇]:初始P ...
- Python开发【第九篇】:HTML (二)
python[第十四篇]HTML基础 时间:2016-08-08 20:57:27 阅读:49 评论:0 收藏:0 [点我收藏+] 标签: 什么是HTML? H ...
- [Python笔记]第十篇:模块续
requests Python标准库中提供了:urllib等模块以供Http请求,但是,它的 API 太渣了.它是为另一个时代.另一个互联网所创建的.它需要巨量的工作,甚至包括各种方法覆盖,来完成最简 ...
- Python开发【第一篇】基础题目二
1 列表题 l1 = [11, 22, 33] l2 = [22, 33, 44] # a. 获取l1 中有,l2中没有的元素 for i in l1: if i not in l2: # b. 获取 ...
- 跟着老男孩教育学Python开发【第一篇】:初识Python
Python简介 Python前世今生 Python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解 ...
- Python开发【第一篇】:初识Python
初识python 一.python简介 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解 ...
- Python开发第五篇
面向对象程序设计 面向过程编程:就是分析问题的解决步骤,按部就班的编写代码解决问题 函数式编程:就是把代码封装到函数中,然后在使用时调用封装好的函数 面向对象编程:把一类事物所共有的属性和行为提取出来 ...
随机推荐
- 电脑忘记WiFi密码了,但又想知道,该怎么办?
如何查看电脑已经连过的WiFi的密码? 你有没有遇到这样的情况,电脑之前连过的WiFi,正好手机也想连此WiFi,但是忘记密码了,没有WiFi的手机怎么能叫手机呢?.下面我们来看看如何查看已连接过的W ...
- 深度学习(二)--深度信念网络(DBN)
深度学习(二)--深度信念网络(Deep Belief Network,DBN) 一.受限玻尔兹曼机(Restricted Boltzmann Machine,RBM) 在介绍深度信念网络之前需要先了 ...
- 解决idea spring boot项目中target中没有同步更新最新目录文件及资源
idea不像eclipse那样自动将新保存的文件或目录及其他资源更新到target目录中,必须在pom.xml中设置 <build> <resources> <resou ...
- jquery 防止当前页面被Iframe嵌套,防止登录页面Iframe被嵌套
<script type="text/javascript"> if (top.location != location) { top.location.href = ...
- tomcat启动问题 严重: End event threw exception
错误信息: 严重: End event threw exception java.lang.NoSuchMethodException: org.apache.catalina.deploy.WebX ...
- pip升级
只要出现报错:python -m pip install --upgrade pip.都表示需要进行升级pip版本 查看pip版本:pip -V(pip可能是python2版本或python3版本) ...
- 质心坐标(barycentric coordinates)及其应用
一.什么是质心坐标? 在几何结构中,质心坐标是指图形中的点相对各顶点的位置. 以图1的线段 AB 为例,点 P 位于线段 AB 之间, 图1 线段AB和点P 此时计算点 P 的公式为 . 同理,在三角 ...
- boost的named_mutex的一些坑
最近遇到一个问题,程序在a用户下运行后,然后注销windows,登陆b用户,发现程序奔溃,抓了下堆栈,发现了boost的named_mutex一些细节,记录下 #include <boost/i ...
- python-day2列表、元祖、字典;编码;字符串
@导入模块时,会先搜索目前路径的同名py文件,再去全局环境变量找 @看模块的环境变量 import sys print(sys.path) @site-package存放第三方库,可以把自己建的拷贝在 ...
- Delphi Exif
这久要用到读取JPG 的 Exif 信息,先是在盒子里下了个Demo,但是那个太老了,是2003年的,后来下载了个CCR 1.5.1是可以使用了,但是我个人用的是Delphi 2007,似乎CCR 1 ...