redis底层设计(四)——功能的实现
redis中我们会经常用到事务、订阅与发布、Lua脚本以及慢查询日志,接下来我们就一一对他们进行探讨学习。
4.1事务
redis通过MULTI、DISCARD、EXEC和WATCH四个命令来实现事务功能。
4.1.1 事务
事务提供了一种“将多个命令打包,一次性按顺序地执行”的机制,并且事务在执行的期间不会主动中断——服务器在执行完所有的命令之后,才会继续处理其他客户端的其他命令。如下:
redis> MULTI
OK
redis> SET book-name "Mastering C++ in 21 days"
QUEUED
redis> GET book-name
QUEUED
redis> SADD tag "C++" "Programming" "Mastering Series"
QUEUED
redis> SMEMBERS tag
QUEUED
redis> EXEC
) OK
) "Mastering C++ in 21 days"
) (integer)
) ) "Mastering Series"
) "C++"
) "Programming"
一个事务从开始到执行会经历3个过程:
1)开始事务
2)命令入队
3)执行事务
下面分别介绍这三个过程:
4.1.2 开始事务
MULTI命令标志着事务的开始。该命令的作用是将客户端的REDIS_MULTI选项打开,让客户端从非事务状态切换到事务状态。
4.1.3 命令入队
当客户端进入事务状态时,服务器在收到来自客户端的命令时,不会立即执行,而是将这些命令全部放进QUEUE事务队列中,然后返回QUEUE,表示命令已入队。
事务队列是一个数组,每个数组包含3个属性:
1)要执行的命令(cmd);
2)命令的参数(argv);
3)参数的个数(argc);
比如:
redis> MULTI
OK
redis> SET book-name "Mastering C++ in 21 days"
QUEUED
redis> GET book-name
QUEUED
redis> SADD tag "C++" "Programming" "Mastering Series"
QUEUED
redis> SMEMBERS tag
QUEUED
那么程序将为客户端创建以下事务队列:

4.1.4 执行事务
当客户端正处在事务状态,若接收到EXEC、DISCARD、MULTI和WATCH这四个命令时还是会直接执行,而其他的命令是会被放到QUEUE队列中去的。服务器会以先进先出(FIFO)的方式执行,将执行命令得到的结果以FIFO的方式存放到一个回复队列中
4.1.5 事务状态下的DISCARD、MULTI和WATCH命令
DISCARD 命令用于取消一个事务,它清空客户端的整个事务队列,然后将客户端从事务状态调整回非事务状态,最后返回字符串OK 给客户端,说明事务已被取消。
Redis 的事务是不可嵌套的,当客户端已经处于事务状态,而客户端又再向服务器发送MULTI时,服务器只是简单地向客户端发送一个错误,然后继续等待其他命令的入队。MULTI 命令的发送不会造成整个事务失败,也不会修改事务队列中已有的数据。
WATCH 只能在客户端进入事务状态之前执行,在事务状态下发送WATCH 命令会引发一个错误,但它不会造成整个事务失败,也不会修改事务队列中已有的数据(和前面处理MULTI的情况一样)。
4.1.6 带WATCH的事务
WATCH 命令用于在事务开始之前监视任意数量的键:当调用EXEC 命令执行事务时,如果任意一个被监视的键已经被其他客户端修改了,那么整个事务不再执行,直接返回失败。
如下:
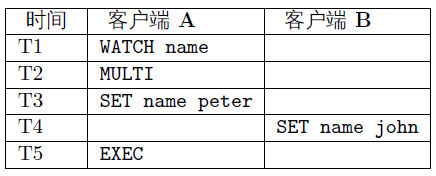
在时间T4 ,客户端B 修改了name 键的值,当客户端A 在T5 执行EXEC 时,Redis 会发现name 这个被监视的键已经被修改,因此客户端A 的事务不会被执行,而是直接返回失败。
4.1.7 WATCH命令的实现
在每个代表数据库的redis.h/redisDb结构类型中,都保存了一个watch_keys字典,字典的键是这个数据库被监视的键,而字典的值是一个链表,链表中保存着所有监视这个键的客户端。如下:

其中,key1正在被client2、client5、client1三个客户端监视,其他键也在被其他的客户端监视着。而WATCH的作用就是将客户端和要监视的键进行关联。
4.1.8 WATCH的触发
在任何对数据库键空间(key space)进行修改的命令成功执行之后(比如FLUSHDB 、SET、DEL 、LPUSH 、SADD 、ZREM ,诸如此类),multi.c/touchWatchKey 函数都会被调用——它检查数据库的watched_keys 字典,看是否有客户端在监视已经被命令修改的键,如果有的话,程序将所有监视这个/这些被修改键的客户端的REDIS_DIRTY_CAS 选项打开
当客户端发送EXEC 命令、触发事务执行时,服务器会对客户端的状态进行检查:
• 如果客户端的REDIS_DIRTY_CAS 选项已经被打开,那么说明被客户端监视的键至少有一个已经被修改了,事务的安全性已经被破坏。服务器会放弃执行这个事务,直接向客户端返回空回复,表示事务执行失败。
• 如果REDIS_DIRTY_CAS 选项没有被打开,那么说明所有监视键都安全,服务器正式执行事务。
4.1.9 事务的ACID性质
redis保证了事务的一致性(C)和隔离性(I),但并不保证原子性(A)和持久性(D)。
1)原子性(A):
单个redis命令的执行是原子性的,但redis没有在事务上增加任何维持原子性的机制,所以redis事务的执行并不是原子性的。
如果redis服务器进程在执行任务的过程中被停止——比如接到KILL命令、宿主机器停机等等,那么事务执行失败,当事务执行失败时,redis是不会做任何的重试或回滚的。
2)一致性(C):
redis的一致性可以从下面三个方面来讨论:入队错误、执行错误和redis进程被终结。
a.入队错误:
在命令入队的过程中,如果客户端想服务器发送了错误的命令,比如命令的参数数量错误等等,那么服务器将想客户端返回一个出错的信息,并且将客户端的事务状态设为REDIS_DIRTY_EXEC。当客户端执行EXEC命令的时候,redis会拒绝执行 REDIS_DIRTY_EXEC的事务,并返回失败信息。因此,带有不正确的入队命令的事务不会被执行,也不会影响数据库的一致性。
b.执行错误:
如果命令在事务执行的过程中发生错误,比如说,对一个不同类型的key 执行了错误的操作,那么Redis 只会将错误包含在事务的结果中,这不会引起事务中断或整个失败,不会影响已执行事务命令的结果,也不会影响后面要执行的事务命令,所以它对事务的一致性也没有影响。
c.redis进程被终结:
如果Redis 服务器进程在执行事务的过程中被其他进程终结,或者被管理员强制杀死,那么根据Redis 所使用的持久化模式,可能有以下情况出现:
• 内存模式:如果Redis 没有采取任何持久化机制,那么重启之后的数据库总是空白的,所以数据总是一致的。
• RDB 模式:在执行事务时,Redis 不会中断事务去执行保存RDB 的工作,只有在事务执行之后,保存RDB 的工作才有可能开始。所以当RDB 模式下的Redis 服务器进程在事务中途被杀死时,事务内执行的命令,不管成功了多少,都不会被保存到RDB 文件里。恢复数据库需要使用现有的RDB 文件,而这个RDB 文件的数据保存的是最近一次的数据库快照(snapshot),所以它的数据可能不是最新的,但只要RDB 文件本身没有因为其他问题而出错,那么还原后的数据库就是一致的。
• AOF 模式:因为保存AOF 文件的工作在后台线程进行,所以即使是在事务执行的中途,保存AOF 文件的工作也可以继续进行,因此,根据事务语句是否被写入并保存到AOF文件,有以下两种情况发生:
1)如果事务语句未写入到AOF 文件,或AOF 未被SYNC 调用保存到磁盘,那么当进程被杀死之后,Redis 可以根据最近一次成功保存到磁盘的AOF 文件来还原数据库,只要AOF 文件本身没有因为其他问题而出错,那么还原后的数据库总是一致的,但其中的数据不一定是最新的。
2)如果事务的部分语句被写入到AOF 文件,并且AOF 文件被成功保存,那么不完整的事务执行信息就会遗留在AOF 文件里,当重启Redis 时,程序会检测到AOF 文件并不完整,Redis 会退出,并报告错误。需要使用redis-check-aof 工具将部分成功的事务命令移除之后,才能再次启动服务器。还原之后的数据总是一致的,而且数据也是最新的(直到事务执行之前为止)。
3)隔离性(I):
redis是但进程程序,并且它保证在执行事务时,不会对事务进行中断,事务可以运行直到执行完所有事务队列中的命令为止。因此,redis的事务总是带有隔离性的。
4)持久性(D):
因为事务不过是用队列包裹起了一组Redis 命令,并没有提供任何额外的持久性功能,所以事务的持久性由Redis 所使用的持久化模式决定:
• 在单纯的内存模式下,事务肯定是不持久的。
• 在RDB 模式下,服务器可能在事务执行之后、RDB 文件更新之前的这段时间失败,所以RDB 模式下的Redis 事务也是不持久的。
• 在AOF 的“总是SYNC ”模式下,事务的每条命令在执行成功之后,都会立即调用fsync或fdatasync 将事务数据写入到AOF 文件。但是,这种保存是由后台线程进行的,主线程不会阻塞直到保存成功,所以从命令执行成功到数据保存到硬盘之间,还是有一段
非常小的间隔,所以这种模式下的事务也是不持久的。其他AOF 模式也和“总是SYNC ”模式类似,所以它们都是不持久的。
4.1.10 小结:
* 事务提供了一种将多个命令打包,然后一次性、有序地执行的机制;
* 事务在执行过程中不会被打断,所有事务命令执行完之后,事务才会结束;
* 多个命令会被入队到事务队列中,然后按先进先出(FIFO)的顺序执行;
* 带WATCH命令的事务会在数据库的WATCHED_KEYS字典中将客户端和被监视的键进行关联;当键被修改时,程序会将所有监视被修改键的客户端的REDIS_DIRTY_CAS选项打开;
* 只有在客户端的REDIS_DIRTY_CAS选项未被打开时,才能执行事务,否则事务直接返回失败;
* redis保持了事务的一致性和隔离性,但并不保证事务的原子性和持久性;
4.2 订阅与发布
Redis 通过PUBLISH 、SUBSCRIBE 等命令实现了订阅与发布模式,这个功能提供两种信息机制,分别是订阅/发布到频道和订阅/发布到模式,下文先讨论订阅/发布到频道的实现,再讨论订阅/发布到模式的实现。
4.2.1 频道的订阅
每个Redis 服务器进程都维持着一个表示服务器状态的redis.h/redisServer 结构,结构的pubsub_channels 属性是一个字典,这个字典就用于保存订阅频道的信息:
struct redisServer {
// ...
dict *pubsub_channels;
// ...
};
其中,字典的键为正在被订阅的频道,而字典的值则是一个链表,链表中保存了所有订阅这个频道的客户端。
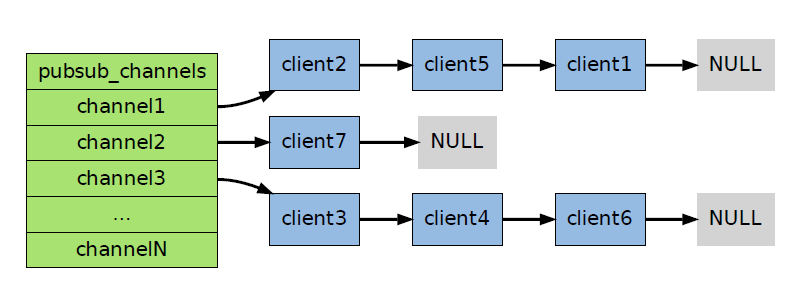
通过pubsub_channels 字典,程序只要检查某个频道是否字典的键,就可以知道该频道是否正在被客户端订阅;只要取出某个键的值,就可以得到所有订阅该频道的客户端的信息。
4.2.2 发送信息到频道
了解了pubsub_channels 字典的结构之后,解释PUBLISH 命令的实现就非常简单了:当调用PUBLISH channel message 命令,程序首先根据channel 定位到字典的键,然后将信息发送给字典值链表中的所有客户端。
4.2.3 退订频道
使用UNSUBSCRIBE 命令可以退订指定的频道,这个命令执行的是订阅的反操作:它从pubsub_channels 字典的给定频道(键)中,删除关于当前客户端的信息,这样被退订频道的信息就不会再发送给这个客户端。
4.2.4 模式的订阅与信息发送
当使用PUBLISH 命令发送信息到某个频道时,不仅所有订阅该频道的客户端会收到信息,如果有某个/某些模式和这个频道匹配的话,那么所有订阅这个/这些频道的客户端也同样会收到信息。
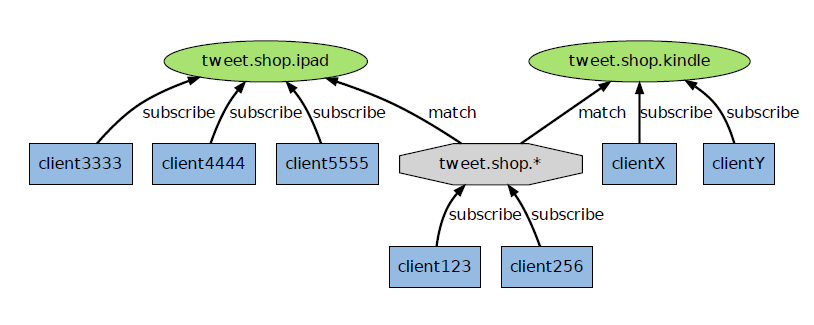
上图展示了一个带有频道和模式的例子,当有信息发送到tweet.shop.kindle 频道时,信息除了发送给clientX 和clientY 之外,还会发送给订阅tweet.shop.* 模式的client123 和client256。
2.4.5 订阅模式
redisServer.pubsub_patterns 属性是一个链表,链表中保存着所有和模式相关的信息:
struct redisServer {
// ...
list *pubsub_patterns;
// ...
};
链表中的每个节点都包含一个redis.h/pubsubPattern 结构:
typedef struct pubsubPattern {
redisClient *client;
robj *pattern;
} pubsubPattern;
client 属性保存着订阅模式的客户端,而pattern 属性则保存着被订阅的模式。每当调用PSUBSCRIBE 命令订阅一个模式时,程序就创建一个包含客户端信息和被订阅模式的pubsubPattern 结构,并将该结构添加到redisServer.pubsub_patterns 链表中。
作为例子,下图展示了一个包含两个模式的pubsub_patterns 链表,其中client123 和client256 都正在订阅tweet.shop.* 模式:
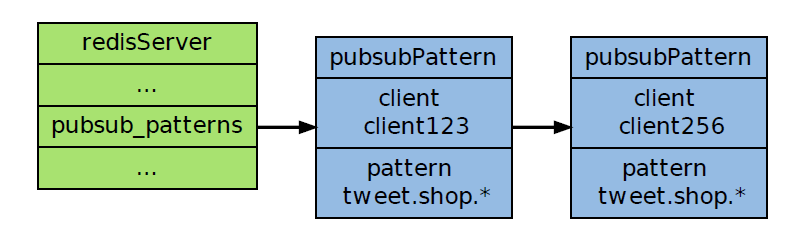
通过遍历整个pubsub_patterns 链表,程序可以检查所有正在被订阅的模式,以及订阅这些模式的客户端。
2.4.6 发送信息到模式
发送信息到模块的工作是由PUBLISH命令完成的,PUBLISH除了将message发送到所有订阅channel的客户端上,他还会将channel和pubsub_patterns中的模式进行对比,如果channel和某种模式匹配的话,那么也将message发送到订阅那个模式的客户端。
例如:redis服务器的pubsub_patterns状态如下:
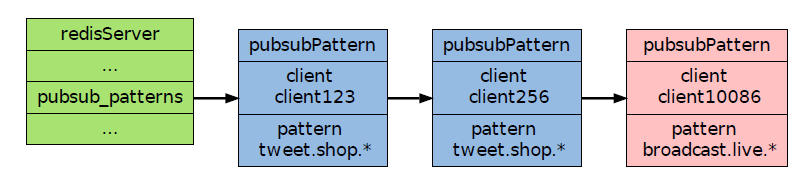
那么当某个客户端发送信息"Amazon Kindle, $69." 到tweet.shop.kindle 频道时,除了所有订阅了tweet.shop.kindle 频道的客户端会收到信息之外,客户端client123 和client256也同样会收到信息,因为这两个客户端订阅的tweet.shop.* 模式和tweet.shop.kindle 频道匹配。
4.2.7 退订模式
使用PUNSUBSCRIBE 命令可以退订指定的模式,这个命令执行的是订阅模式的反操作:程序会删除redisServer.pubsub_patterns 链表中,所有和被退订模式相关联的pubsubPattern结构,这样客户端就不会再收到和模式相匹配的频道发来的信息。
4.2.8 小结
* 订阅消息由服务器进程维持的RedisServer.pubsub_channels字典保存,字典的键是被订阅的频道,字典的值是订阅该频道的所有客户端;
* 当有新消息发送到频道时,程序遍历频道(键)所对应的客户端(值),然后将信息发送到所有订阅频道的客户端上;
* 订阅模式的信息由服务器进行维持的RedisServer_pubsub_patterns链表保存,链表的每个节点都保存着一个pubsubPattern 结构,结构中保存着被订阅的模式,以及订阅模式的客户端。程序通过遍历链表来查询某个频道是否和某个模式匹配;
* 当有新消息发送到频道时,除了订阅频道的客户端会接收到消息之外,所有与频道模式相匹配的客户端也会收到消息;
* 退订频道和退订模式都分别是订阅频道和订阅模式的反操作。
4.3Lua脚本
Lua是redis 2.6 版本最大的亮点,通过内嵌对Lua 环境的支持,Redis 解决了长久以来不能高效地处理CAS (check-and-set)命令的缺点,并且可以通过组合使用多个命令,轻松实现以前很难实现或者不能高效实现的模式。
4.3.1 初始化Lua环境
在初始化redis服务器的时候,对Lua环境的初始化也会一并进行;
整个初始化Lua环境的步骤如下:
1)调用lua_open函数,创建一个新的Lua环境;
2)载入指定的Lua函数库:基础库(base lib)、表格库(table lib)、字符串库(string lib)、数学库(math lib)、调试库(debug lib)、用于处理JSON对象的cjson库、在Lua值和C结构之间进行切换的struct库和处理MessagePack数据的cmsgpack库
3)屏蔽一些可能对Lua环境产生安全问题的函数,比如loadfile;
4)创建一个redis字典,保存Lua脚本,并在复制脚本是使用,字典的键为SHA1校验和,字典的值为Lua脚本;
5)创建一个redis全局表格到Lua环境,表格中包含了各种对redis进行操作的函数;
6)用redis自己定义的随机生成函数,替换math表原有的math.random函数和math.randomseed函数,新的函数具有这样的特质:每次执行Lua 脚本时,除非显式地调用math.randomseed ,否则math.random 生成的伪随机数序列总是相同的;
7)创建一个对Redis 多批量回复(multi bulk reply)进行排序的辅助函数;
8)对Lua 环境中的全局变量进行保护,以免被传入的脚本修改;
9)因为Redis 命令必须通过客户端来执行,所以需要在服务器状态中创建一个无网络连接的伪客户端(fake client),专门用于执行Lua 脚本中包含的Redis 命令:当Lua 脚本需要执行Redis 命令时,它通过伪客户端来向服务器发送命令请求,服务器在执行完命令之后,将结果返回给伪客户端,而伪客户端又转而将命令结果返回给Lua 脚本;
10)将Lua 环境的指针记录到Redis 服务器的全局状态中,等候Redis 的调用;
以上就是Redis 初始化Lua 环境的整个过程,当这些步骤都执行完之后,Redis 就可以使用Lua 环境来处理脚本了。严格来说,步骤1 至8 才是初始化Lua 环境的操作,而步骤9 和10 则是将Lua 环境关联到服务器的操作,为了按顺序观察整个初始化过程,我们将两种操作放在了一起。另外,步骤6 用于创建无副作用的脚本,而步骤7 则用于去除部分Redis 命令中的不确定性(non deterministic),关于这两点,请看下面一节关于脚本安全性的讨论。
4.3.2 脚本的安全性
当将Lua 脚本复制到附属节点,或者将Lua 脚本写入AOF 文件时,Redis 需要解决这样一个问题:如果一段Lua 脚本带有随机性质或副作用,当这段脚本在附属节点运行时,或从AOF 文件载入重新运行时,它得到的结果可能和之前运行的结果完全不同。
注意:只有在带有随机性的脚本进行写入时,随机性才是有害的,如果一个脚本只是执行只读操作,那么随机性是无害的
和随机性质类似,如果一个脚本的执行对任何副作用产生了依赖,那么这个脚本每次执行的结果都可能会不一样。为了解决这个问题,Redis 对Lua 环境所能执行的脚本做了一个严格的限制——所有脚本都必须是无副作用的纯函数(pure function)。
为此,Redis 对Lua 环境做了一些列相应的措施:
• 不提供访问系统状态状态的库(比如系统时间库)。
• 禁止使用loadfile 函数。
• 如果脚本在执行带有随机性质的命令(比如RANDOMKEY ),或者带有副作用的命令(比如TIME )之后,试图执行一个写入命令(比如SET ),那么Redis 将阻止这个脚本继续运行,并返回一个错误。
• 如果脚本执行了带有随机性质的读命令(比如SMEMBERS ),那么在脚本的输出返回给Redis 之前,会先被执行一个自动的字典序排序,从而确保输出结果是有序的。
• 用Redis 自己定义的随机生成函数,替换Lua 环境中math 表原有的math.random 函数地调用math.randomseed ,否则math.random 生成的伪随机数序列总是相同的。
经过这一系列的调整之后,Redis 可以保证被执行的脚本:
* 无副作用。
* 没有有害的随机性。
* 对于同样的输入参数和数据集,总是产生相同的写入命令。
4.3.3 脚本的执行
在脚本环境的初始化工作完成以后,Redis 就可以通过EVAL 命令或EVALSHA 命令执行Lua脚本了。
redis> EVAL "return 'hello world'" 0
"hello world"
redis> SCRIPT LOAD "return 'hello world'"
"5332031c6b470dc5a0dd9b4bf2030dea6d65de91"
redis> EVALSHA 5332031c6b470dc5a0dd9b4bf2030dea6d65de910 // 上一个脚本的校验和
"hello world"
4.3.4 EVAL命令的实现
EVAL 命令的执行可以分为以下步骤:
1) 为输入脚本定义一个Lua 函数。
2) 执行这个Lua 函数。
定义Lua函数:
所有被Redis 执行的Lua 脚本,在Lua 环境中都会有一个和该脚本相对应的无参数函数:当调用EVAL 命令执行脚本时,程序第一步要完成的工作就是为传入的脚本创建一个相应的Lua函数。
举个例子,当执行命令EVAL "return 'hello world'" 0 时,Lua 会为脚本"return 'hello world'" 创建以下函数:
function f_5332031c6b470dc5a0dd9b4bf2030dea6d65de91()
return 'hello world'
end
其中,函数名以f_ 为前缀,后跟脚本的SHA1 校验和(一个40 个字符长的字符串)拼接而成。而函数体(body)则是用户输入的脚本。以函数为单位保存Lua 脚本有以下好处:
• 执行脚本的步骤非常简单,只要调用和脚本相对应的函数即可。
• Lua 环境可以保持清洁,已有的脚本和新加入的脚本不会互相干扰,也可以将重置Lua环境和调用Lua GC 的次数降到最低。
• 如果某个脚本所对应的函数在Lua 环境中被定义过至少一次,那么只要记得这个脚本的SHA1 校验和,就可以直接执行该脚本——这是实现EVALSHA 命令的基础,稍后在介绍EVALSHA 的时候就会说到这一点。
在为脚本创建函数前,程序会先用函数名检查Lua 环境,只有在函数定义未存在时,程序才创建函数。重复定义函数一般并没有什么副作用,这算是一个小优化。
另外,如果定义的函数在编译过程中出错(比如,脚本的代码语法有错),那么程序向用户返回一个脚本错误,不再执行后面的步骤。
执行Lua函数:
在定义好Lua 函数之后,程序就可以通过运行这个函数来达到运行输入脚本的目的了。不过,在此之前,为了确保脚本的正确和安全执行,还需要执行一些设置钩子、传入参数之类的操作,整个执行函数的过程如下:
1. 将EVAL 命令中输入的KEYS 参数和ARGV 参数以全局数组的方式传入到Lua 环境中。
2. 设置伪客户端的目标数据库为调用者客户端的目标数据库: fake_client->db =caller_client->db ,确保脚本中执行的Redis 命令访问的是正确的数据库。
3. 为Lua 环境装载超时钩子,保证在脚本执行出现超时时可以杀死脚本,或者停止Redis服务器。
4. 执行脚本对应的Lua 函数。
5. 如果被执行的Lua 脚本中带有SELECT 命令,那么在脚本执行完毕之后,伪客户端中的数据库可能已经有所改变,所以需要对调用者客户端的目标数据库进行更新:caller_client->db = fake_client->db 。
6. 执行清理操作:清除钩子;清除指向调用者客户端的指针;等等。
7. 将Lua 函数执行所得的结果转换成Redis 回复,然后传给调用者客户端。
8. 对Lua 环境进行一次单步的渐进式GC 。
以下是执行EVAL "return 'hello world'" 0 的过程中,调用者客户端(caller)、Redis 服务器和Lua 环境之间的数据流表示图:

4.3.5 小结
初始化Lua脚本环境需要一系列步骤,其中包括:
* 创建Lua环境;
* 载入Lua库,比如字符串库、数学库、表格库、调试库等;
* 创建redis全局表格,包含各种对redis进行操作的函数,比如redis.call 和 redis.log等;
* 创建一个无网络的伪客户端,专门用于执行Lua脚本中的redis命令;
redis通过一系列的措施保证被执行的Lua脚本无副作用,也没有有害的写随机性:对于同样的输入参数和数据集,总是产生相同的写入命令。
EVAL命令为输入脚本定义一个Lua函数,然后通过执行这个函数来执行脚本。
EVALSHA通过构建函数名,直接调用Lua中已定义的函数,从而执行相应的脚本。
4.4 慢查询日志
慢查询日志是redis提供的一个用于观察系统性能的功能。一句话就是将那些执行时间比较长的命令记录到日志中。
4.4.1 相关数据结构:
每条慢查询日志都以一个slowlog.h/slowlogEntry结构定义:
typedef struct slowlogEntry {
// 命令参数
robj **argv;
// 命令参数数量
int argc;
// 唯一标识符
long long id; /* Unique entry identifier. */
// 执行命令消耗的时间,以纳秒(1 / 1,000,000,000 秒)为单位
long long duration; /* Time spent by the query, in nanoseconds. */
// 命令执行时的时间
time_t time; /* Unix time at which the query was executed. */
} slowlogEntry;
记录服务器状态的redis.h/redisServer 结构里保存了几个和慢查询有关的属性:
struct redisServer {
// ... other fields
// 保存慢查询日志的链表
list *slowlog; /* SLOWLOG list of commands */
// 慢查询日志的当前id 值
long long slowlog_entry_id; /* SLOWLOG current entry ID */
// 慢查询时间限制
long long slowlog_log_slower_than; /* SLOWLOG time limit (to get logged) */
// 慢查询日志的最大条目数量
unsigned long slowlog_max_len; /* SLOWLOG max number of items logged */
// ... other fields
};
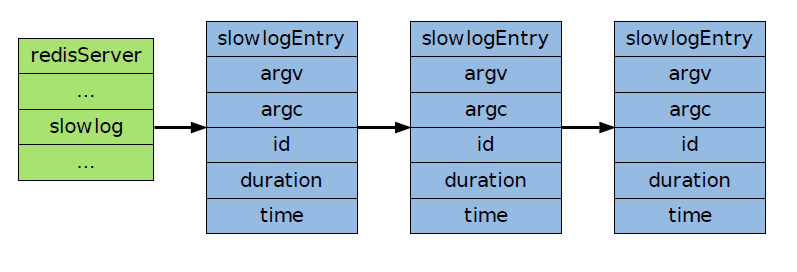
slowlog 属性是一个链表,链表里的每个节点保存了一个慢查询日志结构,所有日志按添加时间从新到旧排序,新的日志在链表的左端,旧的日志在链表的右端。
slowlog_entry_id 在创建每条新的慢查询日志时增一,用于产生慢查询日志的ID (这个ID在执行SLOWLOG RESET 之后会被重置)。slowlog_log_slower_than 是用户指定的命令执行时间上限,执行时间大于等于这个值的命令会被慢查询日志记录。
slowlog_max_len 慢查询日志的最大数量,当日志数量等于这个值时,添加一条新日志会造成最旧的一条日志被删除。
下图展示了一个slowlog 属性的实例:
4.4.2 慢查询日志的记录:
在每次执行命令之前,Redis 都会用一个参数记录命令执行前的时间,在命令执行完之后,再计算一次当前时间,然后将两个时间值相减,得出执行命令所耗费的时间值duration ,并将duration 传给slowlogPushEntryIfNeed 函数。
如果duration 超过服务器设置的执行时间上限server.slowlog_log_slower_than 的话,slowlogPushEntryIfNeed 就会创建一条新的慢查询日志,并将它加入到慢查询日志链表里。
4.4.3 慢查询日志的操作:
针对慢查询日志有三种操作,分别是查看、清空和获取日志数量:
• 查看日志:在日志链表中遍历指定数量的日志节点,复杂度为O(N) 。命令是:slowlog get
• 清空日志:释放日志链表中的所有日志节点,复杂度为O(N) 。命令是:slowlog reset
• 获取日志数量:获取日志的数量等同于获取server.slowlog 链表的数量,复杂度为O(1) 。 命令是:slowlog len
4.4.4 小结:
* redis用一个链表以FIFO的顺序保存着所有慢查询日志;
* 每条慢查询日志以一个慢查询节点表示,节点中记录着执行超时的命令、命令的参数、命令执行时的时间,以及执行命令所消耗的时间等信息。
redis底层设计(四)——功能的实现的更多相关文章
- redis底层设计(五)——内部运作机制
5.1 数据库 5.1.1 数据库的结构: Redis 中的每个数据库,都由一个redis.h/redisDb 结构表示: typedef struct redisDb { // 保存着数据库以整数表 ...
- redis底层设计(一)——内部数据结构
redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorted set ...
- redis底层设计(三)——redis数据类型
今天我们来看一下redis的数据类型.既然redis的键值对可以保存不同类型的值,那么很自然就需要对键值对的类型进行检查以及多态处理.下面我们将对redis所使用的对象系统进行了解,并分别观察字符串. ...
- redis底层设计(二)——内存映射数据结构
我们继续接着上一篇博客,今天来看看内存映射数据结构. 上篇我们讲了内部数据结构,虽然内部数据结构非常强大,但是创建一系列完整的数据结构本身也是一件相当耗费时间的工作,当一个对象包含的元素数量并不多,或 ...
- Redis 详解 (四) redis的底层数据结构
目录 1.演示数据类型的实现 2.简单动态字符串 3.链表 4.字典 5.跳跃表 6.整数集合 7.压缩列表 8.总结 上一篇博客我们介绍了 redis的五大数据类型详细用法,但是在 Redis 中, ...
- Redis核心设计原理(深入底层C源码)
Redis 基本特性 1. 非关系型的键值对数据库,可以根据键以O(1) 的时间复杂度取出或插入关联值 2. Redis 的数据是存在内存中的 3. 键值对中键的类型可以是字符串,整型,浮点型等,且键 ...
- 10w+QPS 的 Redis 真的只是因为单线程和内存?360° 深入底层设计为你揭开 Redis 神秘面纱!
原文链接:10w+QPS 的 Redis 真的只是因为单线程和内存?360° 深入底层设计为你揭开 Redis 神秘面纱! 你以为 Redis 这么快仅仅因为单线程和基于内存? 那么你想得太少了,我个 ...
- redis底层实现的几种数据结构
redis底层数据结构 一.简单动态字符串(SDS) 定义: struct sdshdr{ int len; //SDS所保存的字符串长度 int free //记录buf数组中为使用的字节数量 ...
- 【转】分析Redis架构设计
一.前言 因为近期项目中开始使用Redis,为了更好的理解Redis并应用在适合的业务场景,需要对Redis设计与实现深入的理解. 我分析流程是按照从main进入,逐步深入分析Redis的启动流程.同 ...
随机推荐
- loadrunner 脚本录制-Action分类
脚本录制-Action分类 by:授客 QQ:1033553122 Action分类 l . Vuser_init 2. Vuser_end 3. Action 在lr中用户的初始化操作应该存放在V ...
- c++趣味之变量名,颠覆所有教科书的VisualStudio
GCC不参与这次的趣味. 所有的教程都会告诉你,c++的变量名,类名,函数名都应该是字母或下划线开头的字母.数字.下划线组合,像这样: int _abc123; 实际上,VisualStudio并不遵 ...
- WordCount作业修改
WordCount作业修改 github地址 需求说明 基本需求 功能说明 PSP 代码实现 字符总数查询 单词数查询 行数查询 总结 一.需求说明 1.基本需求 WordCount的需求可以概括为: ...
- robot framework笔记(一):环境配置(基于python3)+在pycharm中编写及运行robot脚本
(一)使用pip安装robotframework框架和seleniumlibrary库 pip install --upgrade robotframework pip install --upgra ...
- VirtualBox网络连接方式
VirtualBox图形界面下有四种网络接入方式,它们分别是: 1.NAT 网络地址转换模式(NAT,Network Address Translation) 2.Bridged Adapter 桥接 ...
- 智能ERP 交接班统计异常的解决方法
请注意,有交接班统计数据不准确的需开启离线统计即可解决,交接班统计是按照结账时间来进行统计的 1.点击左侧导航栏中‘更多’-进入系统设置 2.进入营业设置后-开启离线统计-点击保存
- 自动化测试基础篇--Selenium select下拉框
摘自https://www.cnblogs.com/sanzangTst/p/7681523.html 一.什么是下拉框 下拉框是多项选择项,选择其中一种,类似下面(以百度搜索设置为例) 源代码如下所 ...
- wamp 中安装cakephp Fatal error: You must enable the intl extension to use CakePHP. in XXX
今天在wamp下安装cakephp3.x的时候,报出这么一条错误:Fatal error: You must enable the intl extension to use CakePHP. in ...
- June 2. 2018 Week 22nd Saturday
Try not to become a man of success but rather try to become a man of value. 不要为成功而努力,要为做一个有价值的人而努力. ...
- February 15th, 2018 Week 7th Thursday
Every orientation presupposes a disorientation. 迷失过方向,才能找到方向. Not until we are lost do we begin to u ...