hashmap源码研究
概述
在官方文档中是这样描述HashMap的:
Hash table based implementation of the Map interface. This implementation provides all of the optional map operations, and permits null values and the null key. (The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls.) This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time.
基于Map接口实现、允许null键/值、非同步、不保证有序(比如插入的顺序)、也不保证顺序不随时间变化。
数据结构
数组 + 链表 + 红黑树

源码实现
1. 类的继承关系
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, SerializableHashMap继承自父类(AbstractMap),实现了Map、Cloneable、Serializable接口
2. 类的属性
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// 序列号
private static final long serialVersionUID = 362498820763181265L;
// 默认的初始容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的填充因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当桶(bucket)上的结点数大于这个值时会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 当桶(bucket)上的结点数小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
// 桶中结构转化为红黑树对应的数组的最小大小,如果当前容量小于它,就不会将链表转化为红黑树,而是用resize()代替
static final int MIN_TREEIFY_CAPACITY = 64;
// 存储元素的数组,总是2的幂
transient Node<k,v>[] table;
// 存放具体元素的集
transient Set<map.entry<k,v>> entrySet;
// 存放元素的个数,注意这个不等于数组的长度。
transient int size;
// 每次扩容和更改map结构的计数器
transient int modCount;
// 临界值 当实际节点个数超过临界值(容量*填充因子)时,会进行扩容
int threshold;
// 填充因子
final float loadFactor;
}3. 类的构造函数
在HashMap的构造函数中并没有对数组Node<K,V>[] table初始化,而是简单的设置参数,在首次put时调用resize()分配内存
//制定初始容量和填充因子
public HashMap(int initialCapacity, float loadFactor) {
// 初始容量不能小于0,否则报错
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 初始容量不能大于最大值,否则为最大值
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 填充因子不能小于或等于0,不能为非数字
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// 初始化填充因子
this.loadFactor = loadFactor;
// 通过tableSizeFor(cap)计算出不小于initialCapacity的最近的2的幂作为初始容量,将其先保存在threshold里,当put时判断数组为空会调用resize分配内存,并重新计算正确的threshold
this.threshold = tableSizeFor(initialCapacity);
}
//指定初始容量
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//默认构造函数
public HashMap() {
// 初始化填充因子
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
//HashMap(Map<? extends K>)型构造函数
public HashMap(Map<? extends K, ? extends V> m) {
// 初始化填充因子
this.loadFactor = DEFAULT_LOAD_FACTOR;
// 将m中的所有元素添加至HashMap中
putMapEntries(m, false);
}其中tableSizeFor(initialCapacity)返回最近的不小于输入参数的2的整数次幂。比如10,则返回16。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}原理如下:
先说5个移位操作,会使cap的二进制从最高位的1到末尾全部置为1。
假设cap的二进制为01xx…xx。
对cap右移1位:01xx…xx,位或:011xx…xx,使得与最高位的1紧邻的右边一位为1,
对cap右移2位:00011x..xx,位或:01111x..xx,使得从最高位的1开始的四位也为1,
以此类推,int为32位,所以在右移16位后异或最多得到32个连续的1,保证从最高位的1到末尾全部为1。
最后让结果+1,就得到了最近的大于cap的2的整数次幂。
再看第一条语句:
int n = cap - 1;让cap-1再赋值给n的目的是令找到的目标值大于或等于原值。如果cap本身是2的幂,如8(1000(2)),不对它减1而直接操作,将得到16。
通过tableSizeFor(),保证了HashMap容量始终是2的次方,在通过hash寻找index时就可以用逻辑运算来替代取余,即hash%n用hash&(n -1)替代
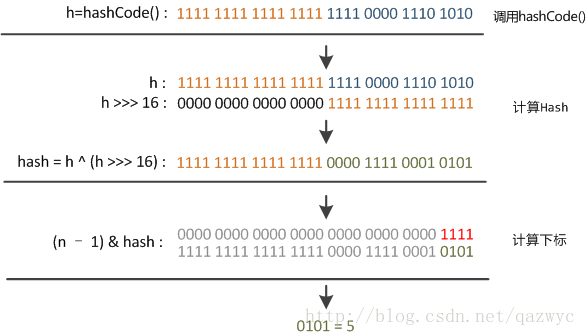
4. hash实现
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}没有直接使用key的hashcode(),而是使key的hashcode()高16位不变,低16位与高16位异或作为最终hash值。
官方文档的注释如下:
Computes key.hashCode() and spreads (XORs) higher bits of hash to lower. Because the table uses power-of-two masking, sets of hashes that vary only in bits above the current mask will always collide. (Among known examples are sets of Float keys holding consecutive whole numbers in small tables.) So we apply a transform that spreads the impact of higher bits downward. There is a tradeoff between speed, utility, and quality of bit-spreading. Because many common sets of hashes are already reasonably distributed (so don’t benefit from spreading), and because we use trees to handle large sets of collisions in bins, we just XOR some shifted bits in the cheapest possible way to reduce systematic lossage, as well as to incorporate impact of the highest bits that would otherwise never be used in index calculations because of table bounds.
大意是,如果直接使用key的hashcode()作为hash很容易发生碰撞。比如,在n - 1为15(0x1111)时,散列值真正生效的只是低4位。当新增的键的hashcode()是2,18,34这样恰好以16的倍数为差的等差数列,就产生了大量碰撞。
因此,设计者综合考虑了速度、作用、质量,把高16bit和低16bit进行了异或。因为现在大多数的hashCode的分布已经很不错了,就算是发生了较多碰撞也用O(logn)的红黑树去优化了。仅仅异或一下,既减少了系统的开销,也不会造成因为高位没有参与下标的计算(table长度比较小时),从而引起的碰撞。
5. resize
resize的注释是这样描述的
Initializes or doubles table size. If null, allocates in accord with initial capacity target held in field threshold. Otherwise, because we are using power-of-two expansion, the elements from each bin must either stay at same index, or move with a power of two offset in the new table.
resize用来重新分配内存
+ 当数组未初始化,按照之前在threashold中保存的初始容量分配内存,没有就使用缺省值
+ 当超过限制时,就扩充两倍,因为我们使用的是2次幂的扩展,所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置
如oldCap为16时,如图
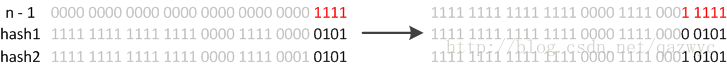
因此,我们在扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值高位新增的那个bit是1还是0,是0的话索引不变,是1的话索引变成“原索引+oldCap”, 直接拆分原链表为高低链表相比先保存数据再寻址追加效率更好。
final Node<K,V>[] resize() {
// 当前table保存
Node<K,V>[] oldTab = table;
// 保存table大小
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 保存当前阈值
int oldThr = threshold;
int newCap, newThr = 0;
// 之前table大小大于0,即已初始化
if (oldCap > 0) {
// 超过最大值就不再扩充了,只设置阈值
if (oldCap >= MAXIMUM_CAPACITY) {
// 阈值为最大整形
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 容量翻倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 阈值翻倍
newThr = oldThr << 1; // double threshold
}
// 初始容量已存在threshold中
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
// 使用缺省值(使用默认构造函数初始化)
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新阈值
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 初始化table
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// 之前的table已经初始化过
if (oldTab != null) {
// 复制元素,重新进行hash
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null) //桶中只有一个结点
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode) //红黑树
//根据(e.hash & oldCap)分为两个,如果哪个数目不大于UNTREEIFY_THRESHOLD,就转为链表
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
// 将同一桶中的元素根据(e.hash & oldCap)是否为0进行分割成两个不同的链表,完成rehash
do {
next = e.next;//保存下一个节点
if ((e.hash & oldCap) == 0) { //保留在低部分即原索引
if (loTail == null)//第一个结点让loTail和loHead都指向它
loHead = e;
else
loTail.next = e;
loTail = e;
}
else { //hash到高部分即原索引+oldCap
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}进行扩容,会重新进行内存分配,并且会遍历hash表中所有的元素,是非常耗时的。在编写程序中,要尽量避免resize。
6. put
put函数大致的思路为:
- 对key的hashCode()做hash,然后再计算桶的index;
- 如果没碰撞直接放到桶bucket里;
- 如果碰撞了,以链表的形式存在buckets后;
- 如果碰撞导致链表过长(大于等于TREEIFY_THRESHOLD),就把链表转换成红黑树(若数组容量小于MIN_TREEIFY_CAPACITY,不进行转换而是进行resize操作)
- 如果节点已经存在就替换old value(保证key的唯一性)
- 如果表中实际元素个数超过阈值(超过load factor*current capacity),就要resize
public V put(K key, V value) {
// 对key的hashCode()做hash
return putVal(hash(key), key, value, false, true);
}
/**
* 用于实现put()方法和其他相关的方法
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// table未初始化或者长度为0,进行扩容,n为桶的个数
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素
else {
Node<K,V> e; K k;
// 比较桶中第一个元素的hash值相等,key相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 将第一个元素赋值给e,用e来记录
e = p;
// hash值不相等或key不相等
else if (p instanceof TreeNode) //红黑树
// 放入树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 为链表结点
else {
for (int binCount = 0; ; ++binCount) {
// 到达链表的尾部
if ((e = p.next) == null) {
// 在尾部插入新结点
p.next = newNode(hash, key, value, null);
// 结点数量达到阈值,调用treeifyBin()做进一步判断是否转为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// 跳出循环
break;
}
// 判断链表中结点的key值与插入的元素的key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出循环
break;
// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
p = e;
}
}
// 表示在桶中找到key值、hash值与插入元素相等的结点
if (e != null) {
// 记录e的value
V oldValue = e.value;
// onlyIfAbsent为false或者旧值为null
if (!onlyIfAbsent || oldValue == null)
//用新值替换旧值
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 结构性修改
++modCount;
// 实际大小大于阈值则扩容
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}
//将指定映射的所有映射关系复制到此映射中
public void putAll(Map<? extends K, ? extends V> m) {
putMapEntries(m, true);
}
//将m的所有元素存入本HashMap实例中,evict为false时表示构造初始HashMap
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
// table未初始化
if (table == null) { // pre-size
//计算初始容量
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);//同样先保存容量到threshold
}
// 已初始化,并且m元素个数大于阈值,进行扩容处理
else if (s > threshold)
resize();
// 将m中的所有元素添加至HashMap中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
//将链表转换为红黑树
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//若数组容量小于MIN_TREEIFY_CAPACITY,不进行转换而是进行resize操作
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);//将Node转换为TreeNode
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);//重新排序形成红黑树
}
}
7. get
get函数大致思路如下:
1. bucket里的第一个节点,直接命中;
2. 如果有冲突,则通过key.equals(k)去查找对应的entry,若为树,复杂度O(logn), 若为链表,O(n)
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// table已经初始化,长度大于0,且根据hash寻找table中的项也不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 比较桶中第一个节点
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 桶中不止一个结点
if ((e = first.next) != null) {
// 为红黑树结点
if (first instanceof TreeNode)
// 在红黑树中查找
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 否则,在链表中查找
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
public boolean containsValue(Object value) {
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0) {
//外层循环搜索数组
for (int i = 0; i < tab.length; ++i) {
//内层循环搜索链表
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
}
}
}
return false;
}8. remove
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
/**
* 用于实现 remove()方法和其他相关的方法
*
* @param hash 键的hash值
* @param key 键
* @param value the value to match if matchValue, else ignored
* @param matchValue if true only remove if value is equal
* @param movable if false do not move other nodes while removing
* @return the node, or null if none
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//table数组非空,键的hash值所指向的数组中的元素非空
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v; //node指向最终的结果结点,e为链表中的遍历指针
if (p.hash == hash && //检查第一个节点
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
//如果第一个节点不匹配
else if ((e = p.next) != null) {
if (p instanceof TreeNode) //树
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;//保存上个节点
} while ((e = e.next) != null);
}
}
//判断是否存在,如果matchValue为true,需要比较值是否相等
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode) //树
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p) //匹配第一个节点
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
public void clear() {
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
}
}总结
- Java8中hash计算是通过key的hashCode()的高16位异或低16位实现的,既保证高低bit都能参与到hash的计算中,又不会有太大的开销。
- 数组大小n总是2的整数次幂,计算下标时直接( hash & n-1)
- 分配内存统一放在resize()中,包括创建后首次put时初始化数组和存放元素个数超过阈值时扩容。
- Java8引入红黑树,当链表长度达到8, 执行treeifyBin,当桶数量达到64时,将链表转为红黑树,否则,执行resize()。
- 判断Node是否符合,首先判断哈希值要相等,但因为哈希值不是唯一的,所以还要对比key是否相等,最好是同一个对象,能用==对比,否则要用equals()
建议
- String类型的key,不能用==判断或者可能有哈希冲突时,尽量减少长度
- 在集合视图迭代的时间与桶的数量加上映射的数量成正比,若迭代性能很重要,不要设置太高的初始容量或过小的负载因子
- 如果映射很多,创建HashMap时设置充足的初始容量(预计大小/负载因子 + 1)会比让其自动扩容获得更好的效率,一方面减少了碰撞可能,另一方面减少了resize的损耗
- 迭代器是fail-fast的,迭代器创建后如果进行了结构修改(增加或删除一个映射)且不是使用iterator的remove方法,会努力抛出ConcurrentModificationException,所以不能依赖该异常保证程序运行正确,而只可用于检测bug
hashmap源码研究的更多相关文章
- 【Java深入研究】9、HashMap源码解析(jdk 1.8)
一.HashMap概述 HashMap是常用的Java集合之一,是基于哈希表的Map接口的实现.与HashTable主要区别为不支持同步和允许null作为key和value.由于HashMap不是线程 ...
- Android开源项目 Universal imageloader 源码研究之Lru算法
https://github.com/nostra13/Android-Universal-Image-Loader universal imageloader 源码研究之Lru算法 LRU - Le ...
- HashMap源码剖析
HashMap源码剖析 无论是在平时的练习还是项目当中,HashMap用的是非常的广,真可谓无处不在.平时用的时候只知道HashMap是用来存储键值对的,却不知道它的底层是如何实现的. 一.HashM ...
- 自学Java HashMap源码
自学Java HashMap源码 参考:http://zhangshixi.iteye.com/blog/672697 HashMap概述 HashMap是基于哈希表的Map接口的非同步实现.此实现提 ...
- JDK 1.6 HashMap 源码分析
前言 前段时间研究了一下JDK 1.6 的 HashMap 源码,把部份重要的方法分析一下,当然HashMap中还有一些值得研究得就交给读者了,如有不正确之处还望留言指正. 准备 需要熟悉数组 ...
- 基于jdk1.8的HashMap源码学习笔记
作为一种最为常用的容器,同时也是效率比较高的容器,HashMap当之无愧.所以自己这次jdk源码学习,就从HashMap开始吧,当然水平有限,有不正确的地方,欢迎指正,促进共同学习进步,就是喜欢程序员 ...
- Mybatis源码研究7:缓存的设计和实现
Mybatis源码研究7:缓存的设计和实现 2014年11月19日 21:02:14 酷酷的糖先森 阅读数:1020 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog ...
- Java8集合框架——HashMap源码分析
java.util.HashMap 本文目录: 一.HashMap 的特点概述和说明 二.HashMap 的内部实现:从内部属性和构造函数说起 三.HashMap 的 put 操作 四.HashMap ...
- HashMap源码解析和设计解读
HashMap源码解析 想要理解HashMap底层数据的存储形式,底层原理,最好的形式就是读它的源码,但是说实话,源码的注释说明全是英文,英文不是非常好的朋友读起来真的非常吃力,我基本上看了差不多 ...
随机推荐
- linux下导入、导出mysql数据库命令的实现方法
首先建空数据库 mysql>create database abc; 导入数据库 mysql>use abc; 设置数据库编码 mysql>set names utf8; 导入数据( ...
- Exp6 信息搜集与漏洞扫描 20164313 杜桂鑫
1.实践目标 掌握信息搜集的最基础技能与常用工具的使用方法. 2.实践内容 (1)各种搜索技巧的应用 1.使用搜索引擎 在百度搜索栏内输入 site:com filetype:doc 北京电子科技学院 ...
- 使用Python+turtle绘制同心圆
问题描述:数学定义上是指:同一平面上同一圆心而半径不同的圆.简单来说就是:圆心相同半径不同的圆,如果几个圆的圆心是同一点,那么这几个圆就叫做同心圆. 本文使用turtle绘制一个类似“箭靶”的同心圆. ...
- 艾奇学院:66个信息流广告和SEM学习网址资源大放送!
01.CNZZ-UDplus 网址:udplus.umeng.com 说明:基于用户行为的精细化分析.运营平台,去研究研究,很多料! 02.黑眼圈管理后台 网址:www.not3.com 说明:二类电 ...
- django 创建视图和APP
.创建视图views 1.在项目目录下创建views.py文件 2.from django.http import HttpResponse 3.在urls 导入模板: from django.con ...
- Oracle :多表更新多个字段
https://blog.csdn.net/funnyfu0101/article/details/52765235 总体原则:1)更新的时候一定要加where条件,否则必然引起该字段的所有记录更新 ...
- Tomcat Server处理一个http请求的过程
Tomcat Server处理一个http请求的过程 假设来自客户的请求为: http://localhost:8080/wsota/wsota_index.jsp 1) 请求被发送到本机端口8080 ...
- HTTP请求方式
HTTP协议中请求的8中方法 OPTIONS获取服务器支持的HTTP请求方法: HEAD跟get很像,但是不返回响应体信息,用于检查对象是否存在,并获取包含在响应消息头中的信息. GET向特定的资源发 ...
- 7、...arg ...[1,2,3] 数组扩展
1.将离散的参数转成数组 2.将数组拆成单个离散的值 https://blog.csdn.net/qq_30100043/article/details/53391308 箭头函数写法 函数名 -&g ...
- Mysql 视图,触发器,存储过程,函数,事务
视图 视图虚拟表,是一个我们真实查询结果表,我们希望将某次查询出来的结果作为单独的一个表,就叫视图,无法对图字段内容进行增删改. --格式: CREATE VIEW 视图名字 AS 操作; --比如: ...