python学习之-用scrapy框架来创建爬虫(spider)
scrapy简单说明
scrapy 为一个框架
框架和第三方库的区别:
库可以直接拿来就用,
框架是用来运行,自动帮助开发人员做很多的事,我们只需要填写逻辑就好
命令: 创建一个 项目 : cd 到需要创建工程的目录中, scrapy startproject stock_spider 其中 stock_spider 为一个项目名称 创建一个爬虫 cd ./stock_spider/spiders scrapy genspider tonghuashun "http://basic.10jqka.com.cn/600004/company.html" 其中 tonghuashun 为一个爬虫名称 "http://basic.10jqka.com.cn/600004/company.html" 为爬虫的地址
执行命令
1,创建一个工程:
cd 到需要创建工程的目录 scrapy startproject my_spide
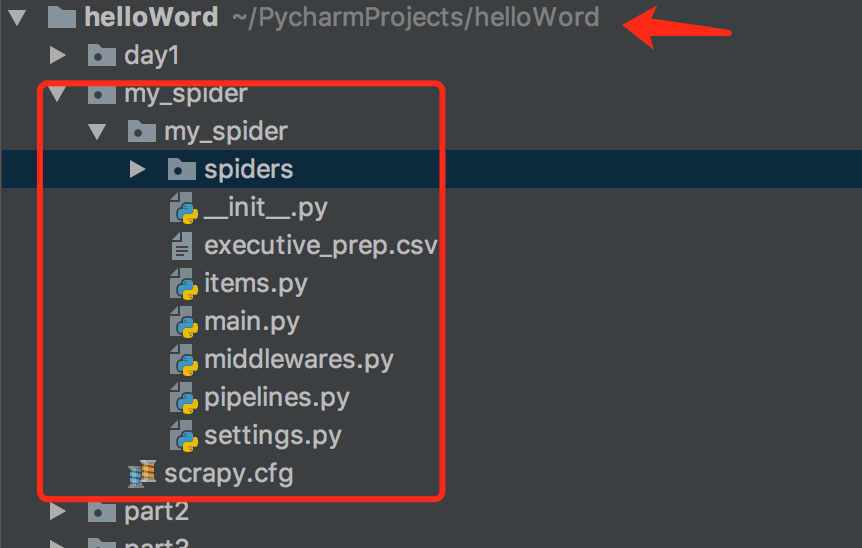
2,创建一个简单的爬虫
cd ./stock_spider/spiders scrapy genspider tonghuashun "http://basic.10jqka.com.cn/600004/company.html" 其中 tonghuashun 为一个爬虫名称 "http://basic.10jqka.com.cn/600004/company.html" 为爬虫的地址
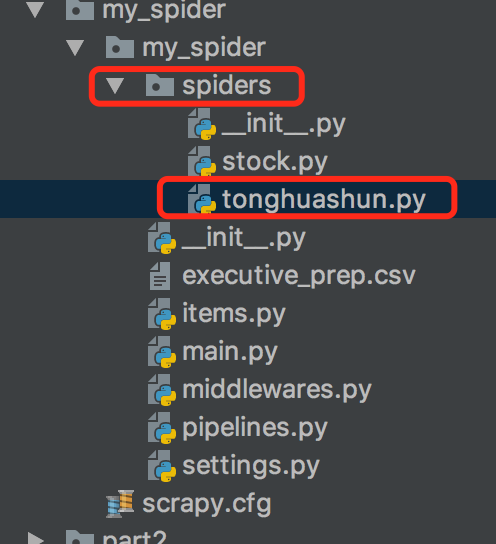
tonghuashun.py代码
import scrapy class TonghuashunSpider(scrapy.Spider):
name = 'tonghuashun'
allowed_domains = ['http://basic.10jqka.com.cn/600004/company.html']
start_urls = ['http://basic.10jqka.com.cn/600004/company.html'] def parse(self, response): # //*[@id="maintable"]/tbody/tr[1]/td[2]/a
# res_selector = response.xpath("//*[@id=\"maintable\"]/tbody/tr[1]/td[2]/a")
# print(res_selector) # /Users/eddy/PycharmProjects/helloWord/stock_spider/stock_spider/spiders res_selector = response.xpath("//*[@id=\"ml_001\"]/table/tbody/tr[1]/td[1]/a/text()") name = res_selector.extract() print(name) tc_names = response.xpath("//*[@class=\"tc name\"]/a/text()").extract() for tc_name in tc_names:
print(tc_name) positions = response.xpath("//*[@class=\"tl\"]/text()").extract() for position in positions:
print(position) pass
xpath :
'''
xpath
/ 从根节点来进行选择元素
// 从匹配选择的当前节点来对文档中的节点进行选择
. 选择当前的节点
.. 选择当前节点的父节点
@ 选择属性 body/div 选取属于body的子元素中的所有div元素
//div 选取所有div标签的子元素,不管它们在html中的位置 @lang 选取名称为lang的所有属性 通配符 * 匹配任意元素节点
@* 匹配任何属性节点 //* 选取文档中的所有元素 //title[@*] 选取所有带有属性的title元素 |
在xpath中 | 是代表和的意思 //body/div | //body/li 选取body元素中的所有div元素和li元素 '''
scrapy shell 的使用过程:
'''
scrapy shell 的使用过程 可以很直观的看到自己选择元素的打印 命令:
scrapy shell http://basic.10jqka.com.cn/600004/company.html 查看指定元素命令:
response.xpath("//*[@id=\"ml_001\"]/table/tbody/tr[1]/td[1]/a/text()").extract() 查看 class="tc name" 的所有元素
response.xpath("//*[@class=\"tc name\"]").extract() 查看 class="tc name" 的所有元素 下a标签的text
response.xpath("//*[@class=\"tc name\"]/a/text()").extract() ['邱嘉臣', '刘建强', '马心航', '张克俭', '关易波', '许汉忠', '毕井双', '饶品贵', '谢泽煌', '梁慧', '袁海文', '邱嘉臣', '戚耀明', '武宇', '黄浩', '王晓勇', '于洪才', '莫名贞', '谢冰心'] '''
scrapy框架在爬虫中的应用
在上个工程项目中cd 到 spidders 目录中,此处为存放爬虫类的包
栗子2:
cd ./stock_spider/spiders scrapy genspider stock "pycs.greedyai.com"
stock.py
# -*- coding: utf-8 -*-
import scrapy
import re from urllib import parse
from ..items import MySpiderItem2 class StockSpider(scrapy.Spider):
name = 'stock'
allowed_domains = ['pycs.greedyai.com']
start_urls = ['http://pycs.greedyai.com'] def parse(self, response):
hrefs = response.xpath("//a/@href").extract() for href in hrefs:
yield scrapy.Request(url= parse.urljoin(response.url, href), callback=self.parse_detail, dont_filter=True) def parse_detail(self,response): stock_item = MySpiderItem2() # 董事会成员信息
stock_item["names"] = self.get_tc(response) # 抓取性别信息
stock_item["sexes"] = self.get_sex(response) # 抓取年龄信息
stock_item["ages"] = self.get_age(response) # 股票代码
stock_item["codes"] = self.get_cod(response) # 职位信息
stock_item["leaders"] = self.get_leader(response,len(stock_item["names"])) yield stock_item
# 处理信息 def get_tc(self, response):
names = response.xpath("//*[@class=\"tc name\"]/a/text()").extract()
return names def get_sex(self, response):
# //*[@id="ml_001"]/table/tbody/tr[1]/td[1]/div/table/thead/tr[2]/td[1]
infos = response.xpath("//*[@class=\"intro\"]/text()").extract()
sex_list = []
for info in infos:
try:
sex = re.findall("[男|女]", info)[0]
sex_list.append(sex)
except(IndexError):
continue return sex_list def get_age(self, response):
infos = response.xpath("//*[@class=\"intro\"]/text()").extract()
age_list = []
for info in infos:
try:
age = re.findall("\d+", info)[0]
age_list.append(age)
except(IndexError):
continue return age_list def get_cod(self, response):
codes = response.xpath("/html/body/div[3]/div[1]/div[2]/div[1]/h1/a/@title").extract()
code_list = []
for info in codes:
code = re.findall("\d+", info)[0]
code_list.append(code) return code_list def get_leader(self, response, length):
tc_leaders = response.xpath("//*[@class=\"tl\"]/text()").extract()
tc_leaders = tc_leaders[0 : length]
return tc_leaders
items.py:
import scrapy class MySpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass class MySpiderItem2(scrapy.Item):
names = scrapy.Field()
sexes = scrapy.Field()
ages = scrapy.Field()
codes = scrapy.Field()
leaders = scrapy.Field()
说明:
items.py中的MySpiderItem2 类中的字段用于存储在stock.py的StockSpider类中爬到的字段,交给pipelines.py中的MySpiderPipeline2处理,
需要到settings.py中设置
# -*- coding: utf-8 -*- # Scrapy settings for my_spider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'my_spider' SPIDER_MODULES = ['my_spider.spiders']
NEWSPIDER_MODULE = 'my_spider.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'my_spider (+http://www.yourdomain.com)' # Obey robots.txt rules
ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'my_spider.middlewares.MySpiderSpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'my_spider.middlewares.MySpiderDownloaderMiddleware': 543,
#} # Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'my_spider.pipelines.MySpiderPipeline': 300,
'my_spider.pipelines.MySpiderPipeline2': 1,
} # Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import os class MySpiderPipeline(object):
def process_item(self, item, spider):
return item class MySpiderPipeline2(object): '''
# 类被加载时需要创建一个文件 # 判断文件是否为空
为空写:高管姓名,性别,年龄,股票代码,职位
不为空:追加文件写数据 ''' def __init__(self): self.file = open("executive_prep.csv","a+") def process_item(self, item, spider): if os.path.getsize("executive_prep.csv"):
# 写数据
self.write_content(item)
else:
self.file.write("高管姓名,性别,年龄,股票代码,职位\n") self.file.flush()
return item def write_content(self,item): names = item["names"]
sexes = item["sexes"]
ages = item["ages"]
codes = item["codes"]
leaders = item["leaders"] # print(names + sexes + ages + codes + leaders) line = ""
for i in range(len(names)):
line = names[i] + "," + sexes[i] + "," + ages[i] + "," + codes[0] + "," + leaders[i] + "\n"
self.file.write(line)
文件可以在同级目录中查看
python学习之-用scrapy框架来创建爬虫(spider)的更多相关文章
- Python多线程爬图&Scrapy框架爬图
一.背景 对于日常Python爬虫由于效率问题,本次测试使用多线程和Scrapy框架来实现抓取斗图啦表情.由于IO操作不使用CPU,对于IO密集(磁盘IO/网络IO/人机交互IO)型适合用多线程,对于 ...
- Scrapy学习(一)、Scrapy框架和数据流
Scrapy是用python写的爬虫框架,架构图如下: 它可以分为如下七个部分: 1.Scrapy Engine:引擎,负责控制数据流在系统的所有组件中流动,并在相应动作发生时触发时间. 2.Sche ...
- Python学习总结 13 Scrapy
当前环境是 Win8 64位的,使用的Python 3.5 版本. 一 安装Scrapy 1,安装 lxml pip install lxml -i https://pypi.douban.com/s ...
- python学习笔记之——unittest框架
unittest是python自带的单元测试框架,尽管其主要是为单元测试服务的,但我们也可以用它来做UI自动化测试和接口的自动化测试. unittest框架为我们编写用例提供了如下的能力 定义用例的能 ...
- 如何使用Scrapy框架实现网络爬虫
现在用下面这个案例来演示如果爬取安居客上面深圳的租房信息,我们采取这样策略,首先爬取所有租房信息的链接地址,然后再根据爬取的地址获取我们所需要的页面信息.访问次数多了,会被重定向到输入验证码页面,这个 ...
- Scrapy框架——CrawlSpider类爬虫案例
Scrapy--CrawlSpider Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 此案例采用的是CrawlSpider类实现爬虫. 它是Spider的派生类,Spide ...
- 爬虫(十五):Scrapy框架(二) Selector、Spider、Downloader Middleware
1. Scrapy框架 1.1 Selector的用法 我们之前介绍了利用Beautiful Soup.正则表达式来提取网页数据,这确实非常方便.而Scrapy还提供了自己的数据提取方法,即Selec ...
- Python学习笔记_04:Django框架简介
目录 1 什么是Django? 2 Django框架的开发环境搭建 3 Django操作MySql数据库简介 4 功能强大的Django管理工具应用 1 什么是Django? Django是应用于We ...
- python学习之路web框架续
中间件 django 中的中间件(middleware),在django中,中间件其实就是一个类,在请求到来和结束后,django会根据自己的规则在合适的时机执行中间件中相应的方法. 在django项 ...
随机推荐
- 在java中,异常抛出点后程序的执行情况
1.在throw语句,即自定义的抛出异常语句后面的代码并不会执行,会提示错误,编译器并不可以正常编译. 2.若在一个条件语句中抛出一个异常,程序可以编译,但不会运行(dead code). 3.若在一 ...
- git 恢复本地误删文件
git status git reset HEAD 路径(git status 会显示的路径) git checkout 路径
- 1px和backgroudImage
https://blog.csdn.net/leadn/article/details/78560786 .setTopLine(@c: #C7C7C7) { & { position: re ...
- NSURLConnectionDataDelegate
#pragma mark-NSURLConnectionDataDelegate //收到回应 - (void)connection:(NSURLConnection *)connection did ...
- 简述osi七层模型和TCP/IP五层模型
OSI七层模型 OSI七层模型的划分 应用层(Application).表示层(presentation).会话层(session).传输层(Transport).网络层(Network).数据链路层 ...
- python之 类对象 类方法 实例对象 实例方法 静态方法
实例对象1. 创建的时间:使用 类名()的时候,就创建一个实例对象2. 实例属性:怎样添加 只要是一个变量能够指向这个实例对象,那么这个变量.xxxx = 111就是给其添加一个实例属性 特点: 跟着 ...
- QT * 使用VS2013+QT5.7.0实现简单计算器
第一次用QT,配置环境变量和VS中添加QT路径自己找找 源代码连接:https://blog.csdn.net/bjailihong/article/details/77508615 做一个简单的计算 ...
- P1181 数列分段Section I
题目描述(跳转) 对于给定的一个长度为NN的正整数数列A_iAi,现要将其分成连续的若干段,并且每段和不超过MM(可以等于MM),问最少能将其分成多少段使得满足要求. 输入输出格式 输入格式: 第1 ...
- Alpha阶段个人心得
在一个学期的学习中,我从一个只会一个人打打小规模代码的初学者也变成了一个能参与到团队做项目的“入门码农”,而我们团队从一开始对大型项目的望而生畏无从下手变成细分任务各司其职,也了解并感受到github ...
- TLS1.2 only
客户有个特殊需求,只能使用TLS1.2,其余的都不行. google了一下,发现要Enable/Disable TLS倒也不难 Windows Registry Editor Version 5.00 ...