洗礼灵魂,修炼python(85)-- 知识拾遗篇 —— 深度剖析让人幽怨的编码
编码
这篇博文的主题是,编码问题,老生常谈的问题了对吧?从我这一套的文章来看,前面已经提到好多次编码问题了,的确这个确实很重要,这可是难道了很多能人异士的,当你以为你学懂了,在研究爬虫时你发现你错了,还是没搞懂,爬虫研究完后,你以为你懂了,url编码又把你打回原形,然后你以为你真的懂了,你学到socket的时候,你发现,你还是没有真的理解,真实气人啊,对吧
与编码问题相关的都在这两篇博文中:
洗礼灵魂,修炼python(3)--从一个简单的print代码揭露编码问题,运行原理和语法习惯
洗礼灵魂,修炼python(57)--爬虫篇—知识补充—编码之对比不同python版本获取的数据
(注明:这是我之前的博文,前期对编码问题,可能理解的不够,我个人之前对编码问题也很困惑,所以如果有错,大家请忽略。结合本篇来看,相信你会真的理解编码问题)
那么本篇博文就深度的剖析一下这个最烦的问题
python2与python3不同的编码解码
首先我们都知道python2和python3有不同的编码规格。
在python3中只有两种数据存储类型,str,bytes
str:存储的就是Unicode,即全球都能认的编码类型
bytes:存储的就是十六进制
而由str转成bytes就叫编码
bytes转成str就叫解码
因为计算机能认识的字符集只能是二进制,那么bytes是最接近二进制的字符集,十六进制再转成二进制就方便很多了
在python2里
有两种类型:Unicode和str(bytes)
str和unicode都是类basestring的子类,str其实是字节串,它是unicode经过编码后的字节组成的序列。而unicode是一个字符串,str是unicode这个字符串经过编码(utf8,gbk等)后的字节组成的序列。unicode才是真正意义上的字符串,对字节串str使用正确的字符编码规则进行解码后获得
那么python2中又是什么鬼呢,不急,接着看
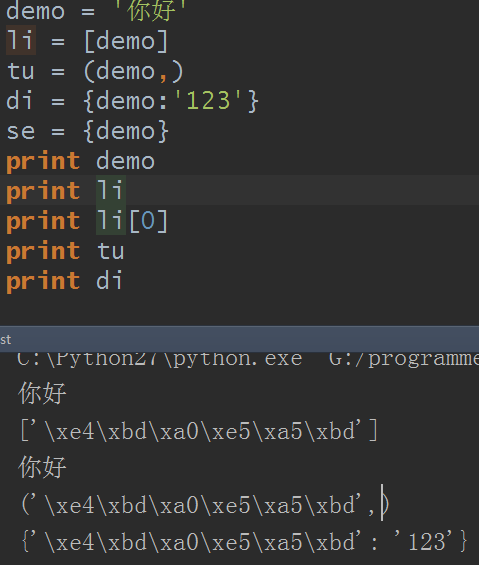
这情况看到了吧?其实我相信,如果你在爬虫方面研究的比较多,并且你是使用python2来爬的话,你早就遇到这个情况了,这是为什么呢?
在python2中,str 存储的就是bytes,首先在Python 2中,print是一个语句(而在Python 3中变成了函数),当直接print时字符串会把数据从IO中读取出来成为有编码规则的数据,所以print打印的正好是我们期待的,而放进容器类型(列表,元组,字典,集合)里时,就会看到存储时的样子。
所以在python2里,str=bytes,换句话python里只存在一种数据存储类型:bytes。Python 2 悄悄掩盖掉了 byte 到 unicode 的转换,让程序在处理 ASCII 的时候更加简单
py2编码的最大特点是Python 2 将会自动的将bytes数据解码成 unicode 字符串,所以在python2中字节数据可以和unicode型进行拼接:

也就是并没有把str和bytes严格的分开,在这一点上,python3就做得更好了,也是正确的,本来就是的,明明就是str,你存储就成了字节类型,这是搞事情啊,请看:
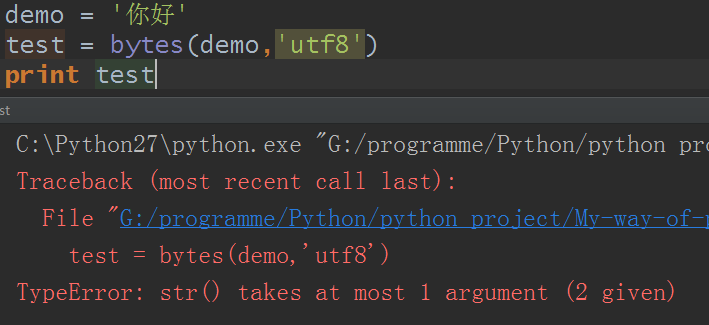
这段代码在python3中是成立的对吧(关于print在python2和3中的不同写法就不再赘述了),但是报错了,提示的是str()允许的参数必须是1个,而却给了两个,这里在上面我们已经知道str和bytes编码解码的功效是一样的了,那么也就是说,当转成字节类型时,python2已经默认为我们设定了一套编码规则,不需要我们手动添加编码规则了。所以这也是为什么使用python2时,时不时会报编码错误了,它已经给我们编码/解码好了,用的什么编码规则我们还要自己去拆解,不然就会出现一堆的错误,很混乱对吧?
还是那句话,在编码问题上,python3很完善,python2一堆小毛病
在python3里
有两种类型,Unicode和byte
现在你从普通文本转换成 “str” 类型后存储的是一个 unicode, “bytes” 类型存储的是 byte 串。你也可以通过一个 b 前缀来制造 byte 串。
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分。文本总是Unicode,由str数据类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。
例如,bytes('你好','utf8')就可以把str为‘你好’编码为十六进制。这里的utf8可以理解为编码规则或者叫编码类型,它并不是固定的,也可以是其他的,比如gbk之类,像这种utf8和gbk,以及台湾的big5,韩国,日本的各种字符类型,这些除了utf8以外,各个国家都有自己各自的编码类型去编码,编出来的都不是不同的类型,虽然最后都是十六进制的bytes。
请看:
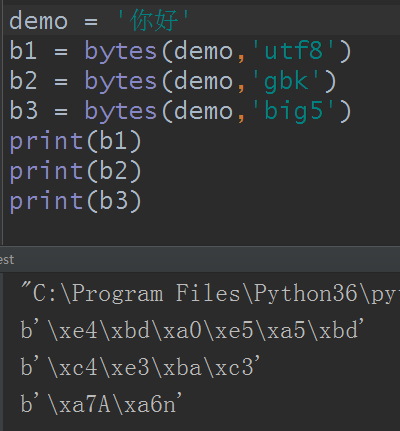
像这种’\xe4\xa0‘啥的就是bytes类型,它也是十六进制的数据
那么有朋友想到了,字符串类型的数据不是自带编码吗?请看:
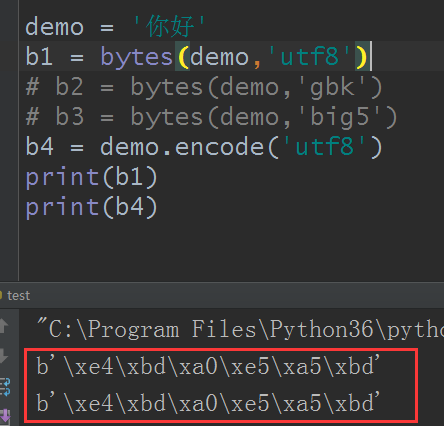
发现b1 和b4是一样的,那么不用说,使用其他编码规则来编码也是一样的
上面是编码,那么解码呢?这里我就同时使用decode和str转码的方法了:
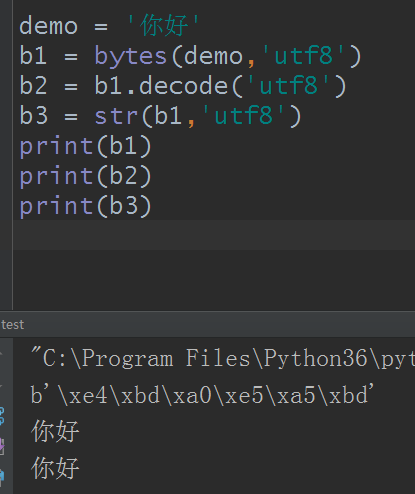
也是一样的对吧?那么有朋友突发奇想了,解码时解码成其他的可以不,试试呢:
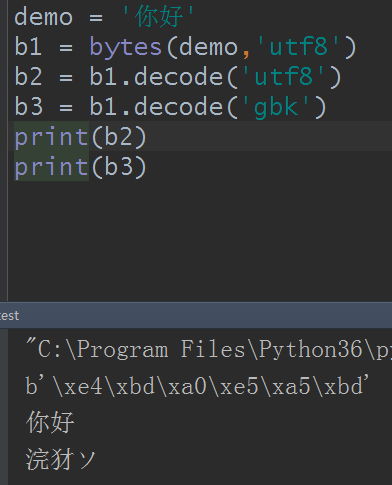
呀,啥字,看不懂啊,其实这已经乱码了,因为编码和解码不统一,这里只是刚好给解码出来了,大部分情况是解码不出来并且会报错的,比如我这解码成big5试试:
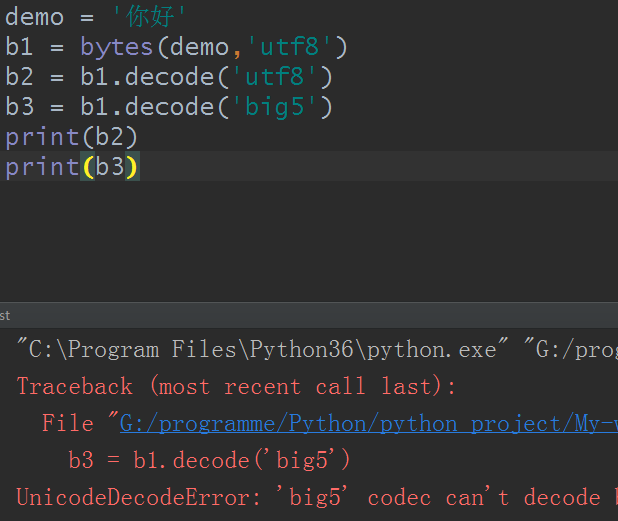
看,报错了吧?
所以要记住,编码和解码必须是同一种编码规则
Python 3 中对 Unicode 支持的最大变化就是将会没有对 byte 字节串的自动解码。如果你想要用一个 byte 字节串和一个 unicode 相链接的话,你将会得到一个错误,不管你包含的内容是什么
url编码
这个问题,在前面的某一篇博文里我已经解析过了,为了统一,放在一起了
首先,Http协议中参数的传输是"key=value"这种键值对形式的,如果要传多个参数就需要用“&”符号对键值对进行分割。如"?key1=value1&key2=value2",这样在服务端在收到这种字符串的时候,会用“&”分割出每一个参数,然后再用“=”来分割出键和值并进行处理。
然后,url只能使用 ASCII 字符集来通过因特网进行发送,也就是说url允许的只能是英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。那么如果url中有汉字,就必须编码成为允许的字符后方可使用。
但是有个问题是,标准的国际组织并没有规定具体的编码方法,而是交给应用程序(浏览器)根据自己的一套编码方式进行编码,有点乱,而每个浏览器对同样的字符解码都是不太一样的。但这里只是指网站子文件的字符编码混乱,比如前面用的百度搜索,编码还是一样的:
火狐浏览器:
https://www.baidu.com/s?wd=%E8%83%A1%E6%AD%8C&rsv_spt=1&rsv_iqid=0xa88a849a000297f1&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&rqlang=cn&tn=monline_3_dg&rsv_enter=1&oq=a&inputT=1164&rsv_t=44f3deAD5ZhHUuZS8qctF8DYdHQl0Jc0fIHprlrxVQPAKhGaI7WQzU0%2BDYkOZ7iFCV9H&rsv_pq=bc5bcce5000040e2&rsv_sug3=10&rsv_sug1=9&rsv_sug7=100&bs=a
谷歌浏览器:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=%E8%83%A1%E6%AD%8C&oq=%25E8%2583%25A1%25E6%25AD%258C&rsv_pq=bc8022d200026160&rsv_t=cf02s%2BKYldDmROy0mQpW7gMikG0rFAkF5WE0KydGdjM1v4PH9wW87XYxuCA&rqlang=cn&rsv_enter=1&rsv_sug3=1&rsv_sug1=1&rsv_sug7=100&rsv_sug2=0&inputT=12&rsv_sug4=439
IE浏览器:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=baidu&wd=%E8%83%A1%E6%AD%8C&rsv_pq=b3b7634b00004749&rsv_t=fa91EE041mGXpmDfMhWtd6QSrm%2F24pXydfxJc%2BPc5W59OuaHKoicHE4Ngwo&rqlang=cn&rsv_enter=1&rsv_sug3=4
(搜索关键词我已经标注出来)
url的编码样式是使用【%】加上代表十六进制为一个字节形式的两位字符—【0-9和A-F】来(比如%EC),详细规则:
- 对于ASCII字符,字母a在ASCII码中对应的字节是0x97,那么Url编码之后得到的就是%97,字母abc, url编码后得到的就是%97%98%99
- 对于非ASCII字符,RFC文档建议使用utf-8对其进行编码得到相应的字节,然后对每个字节执行百分号编码。如前面搜索的"胡歌"使用UTF-8编码规则字符集得到的字节为0xE8 0x83 0xA1 0xE6 0xAD 0x8C,经过Url编码之后得到%E8%83%A1%E6%AD%8C
所以url编码通常也被称为百分号编码(percent-encoding)。
说白了就是ASCII码表里面有的字符,就直接按对应字节,然后把0x改为%。如果ASCII码表里没有的,就用unicode万国码里的utf8编码规则将字符转为字节,然后把0x改为%就行。
洗礼灵魂,修炼python(85)-- 知识拾遗篇 —— 深度剖析让人幽怨的编码的更多相关文章
- 洗礼灵魂,修炼python(3)--从一个简单的print代码揭露编码问题,运行原理和语法习惯
前期工作已经准备好后,可以打开IDE编辑器了,你可以选择python自带的IDLE,也可以选择第三方的,这里我使用pycharm--一个专门为python而生的IDE 按照惯例,第一个python代码 ...
- 洗礼灵魂,修炼python(91)-- 知识拾遗篇 —— pymysql模块之python操作mysql增删改查
首先你得学会基本的mysql操作语句:mysql学习 其次,python要想操作mysql,靠python的内置模块是不行的,而如果通过os模块调用cmd命令虽然原理上是可以的,但是还是不太方便,那么 ...
- 洗礼灵魂,修炼python(87)-- 知识拾遗篇 —— 线程(1)
线程(上) 1.线程含义:一段指令集,也就是一个执行某个程序的代码.不管你执行的是什么,代码量少与多,都会重新翻译为一段指令集.可以理解为轻量级进程 比如,ipconfig,或者, python ...
- 洗礼灵魂,修炼python(84)-- 知识拾遗篇 —— 网络编程之socket
学习本篇文章的前提,你需要了解网络技术基础,请参阅我的另一个分类的博文:网络互联技术(4)——计算机网络常识.原理剖析 网络通信要素 1.IP地址: 用来标识网络上一台独立的终端(PC或者主机) ip ...
- 洗礼灵魂,修炼python(90)-- 知识拾遗篇 —— 协程
协程 1.定义 协程,顾名思义,程序协商着运行,并非像线程那样争抢着运行.协程又叫微线程,一种用户态轻量级线程.协程就是一个单线程(一个脚本运行的都是单线程) 协程拥有自己的寄存器上下文和栈.协程调度 ...
- 洗礼灵魂,修炼python(89)-- 知识拾遗篇 —— 进程
进程 1.含义:计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位.说白了就是一个程序的执行实例. 执行一个程序就是一个进程,比如你打开浏览器看到我的博客,浏览器本身是一 ...
- 洗礼灵魂,修炼python(88)-- 知识拾遗篇 —— 线程(2)/多线程爬虫
线程(下) 7.同步锁 这个例子很经典,实话说,这个例子我是直接照搬前辈的,并不是原创,不过真的也很有意思,请看: #!usr/bin/env python #-*- coding:utf-8 -*- ...
- Python基础知识拾遗
彻底搞清楚python字符编码 python的super函数
- python基础知识第一篇(认识Python)
开发语言: 高级语言:python java php c++ 生成的字节码 字节码转换为机器码 计算机识别运行 低级语言:C 汇编 生成的机器码 PHP语言:适用于网页,局限性 Python,Java ...
随机推荐
- 获取完全一样的数据库,包括表与表之间的外键关系,check,default表结构脚本
今天公司给了一个任务,某一个项目由于数据过大,造成Sql Server 2012 的运行占用很大内存,于是要把之前的不常用的数据分开.要求写个脚本,要求: 1.能获取原来数据库中的表结构,主键一致.表 ...
- Python机器学习笔记 使用sklearn做特征工程和数据挖掘
特征处理是特征工程的核心部分,特征工程是数据分析中最耗时间和精力的一部分工作,它不像算法和模型那样式确定的步骤,更多的是工程上的经验和权衡,因此没有统一的方法,但是sklearn提供了较为完整的特征处 ...
- MyBatis源码解析(二)——Environment环境
原创作品,可以转载,但是请标注出处地址:http://www.cnblogs.com/V1haoge/p/6625612.html 本应该先开始说Configuration配置类的,但是这个类有点过于 ...
- 南大算法设计与分析课程OJ答案代码(5)--割点与桥和任务调度问题
问题 A: 割点与桥 时间限制: 1 Sec 内存限制: 5 MB提交: 475 解决: 34提交 状态 算法问答 题目描述 给出一个无向连通图,找到所有的割点和桥 输入 第一行:点的个数,如果点 ...
- H5调取APP或跳转至下载
来源: 最近在配合移动端做几个详情页h5分享页面,需要调取App并跳转至app详情页, 如果没有安装App,需要判断引导至下载页面. 参考文档: https://juejin.im/post/5b7e ...
- [转]angular使用Md5加密
本文转自:https://www.cnblogs.com/waitingbar/p/7527928.html 一.现象 用户登录时需要记住密码的功能,在前端需要对密码进行加密处理,增加安全性 二解决 ...
- Android Studio 使用Menu
首先在res目录下创建一个文件夹名字随意 在对创建的文件夹下在创建一个菜单 名字随意 参看布局 可以看到你的菜单 可以选择添加是么样的菜单 接着要到主活动中重写 onCreateOptionsMenu ...
- python之isinstance内建函数
语句: isinstance(object,type) 作用: 来判断一个对象是否是一个已知的类型. 解释: 其第一个参数(object)为对象,第二个参数(type)为类型名(int...)或类型名 ...
- Redis 私有云平台 CacheCloud
redis-cachecloud https://github.com/sohutv/cachecloud/wiki/3.%E6%9C%8D%E5%8A%A1%E5%99%A8%E7%AB%AF%E6 ...
- Laravel 数据库操作 Eloquent ORM
laravel 操作数据库一般都使用它的Eloquent ORM才操作 建立模型 <?php namespace App; use Illuminate\Database\Eloquent\Mo ...