What is Druid?
Druid is a data store designed for high-performance slice-and-dice analytics ("OLAP"-style) on large data sets. Druid is most often used as a data store for powering GUI analytical applications, or as a backend for highly-concurrent APIs that need fast aggregations. Common application areas for Druid include:
- Clickstream analytics
- Network flow analytics
- Server metrics storage
- Application performance metrics
- Digital marketing analytics
- Business intelligence / OLAP
Druid's key features are:
- Columnar storage format. Druid uses column-oriented storage, meaning it only needs to load the exact columns needed for a particular query. This gives a huge speed boost to queries that only hit a few columns. In addition, each column is stored optimized for its particular data type, which supports fast scans and aggregations.
- Scalable distributed system. Druid is typically deployed in clusters of tens to hundreds of servers, and can offer ingest rates of millions of records/sec, retention of trillions of records, and query latencies of sub-second to a few seconds.
- Massively parallel processing. Druid can process a query in parallel across the entire cluster.
- Realtime or batch ingestion. Druid can ingest data either realtime (ingested data is immediately available for querying) or in batches.
- Self-healing, self-balancing, easy to operate. As an operator, to scale the cluster out or in, simply add or remove servers and the cluster will rebalance itself automatically, in the background, without any downtime. If any Druid servers fail, the system will automatically route around the damage until those servers can be replaced. Druid is designed to run 24/7 with no need for planned downtimes for any reason, including configuration changes and software updates.
- Cloud-native, fault-tolerant architecture that won't lose data. Once Druid has ingested your data, a copy is stored safely in deep storage (typically cloud storage, HDFS, or a shared filesystem). Your data can be recovered from deep storage even if every single Druid server fails. For more limited failures affecting just a few Druid servers, replication ensures that queries are still possible while the system recovers.
- Indexes for quick filtering. Druid uses CONCISE or Roaring compressed bitmap indexes to create indexes that power fast filtering and searching across multiple columns.
- Approximate algorithms. Druid includes algorithms for approximate count-distinct, approximate ranking, and computation of approximate histograms and quantiles. These algorithms offer bounded memory usage and are often substantially faster than exact computations. For situations where accuracy is more important than speed, Druid also offers exact count-distinct and exact ranking.
- Automatic summarization at ingest time. Druid optionally supports data summarization at ingestion time. This summarization partially pre-aggregates your data, and can lead to big costs savings and performance boosts.
When should I use Druid?
Druid is likely a good choice if your use case fits a few of the following descriptors:
- Insert rates are very high, but updates are less common.
- Most of your queries are aggregation and reporting queries ("group by" queries). You may also have searching and scanning queries.
- You are targeting query latencies of 100ms to a few seconds.
- Your data has a time component (Druid includes optimizations and design choices specifically related to time).
- You may have more than one table, but each query hits just one big distributed table. Queries may potentially hit more than one smaller "lookup" table.
- You have high cardinality data columns (e.g. URLs, user IDs) and need fast counting and ranking over them.
- You want to load data from Kafka, HDFS, flat files, or object storage like Amazon S3.
Situations where you would likely not want to use Druid include:
- You need low-latency updates of existing records using a primary key. Druid supports streaming inserts, but not streaming updates (updates are done using background batch jobs).
- You are building an offline reporting system where query latency is not very important.
- You want to do "big" joins (joining one big fact table to another big fact table).
Architecture
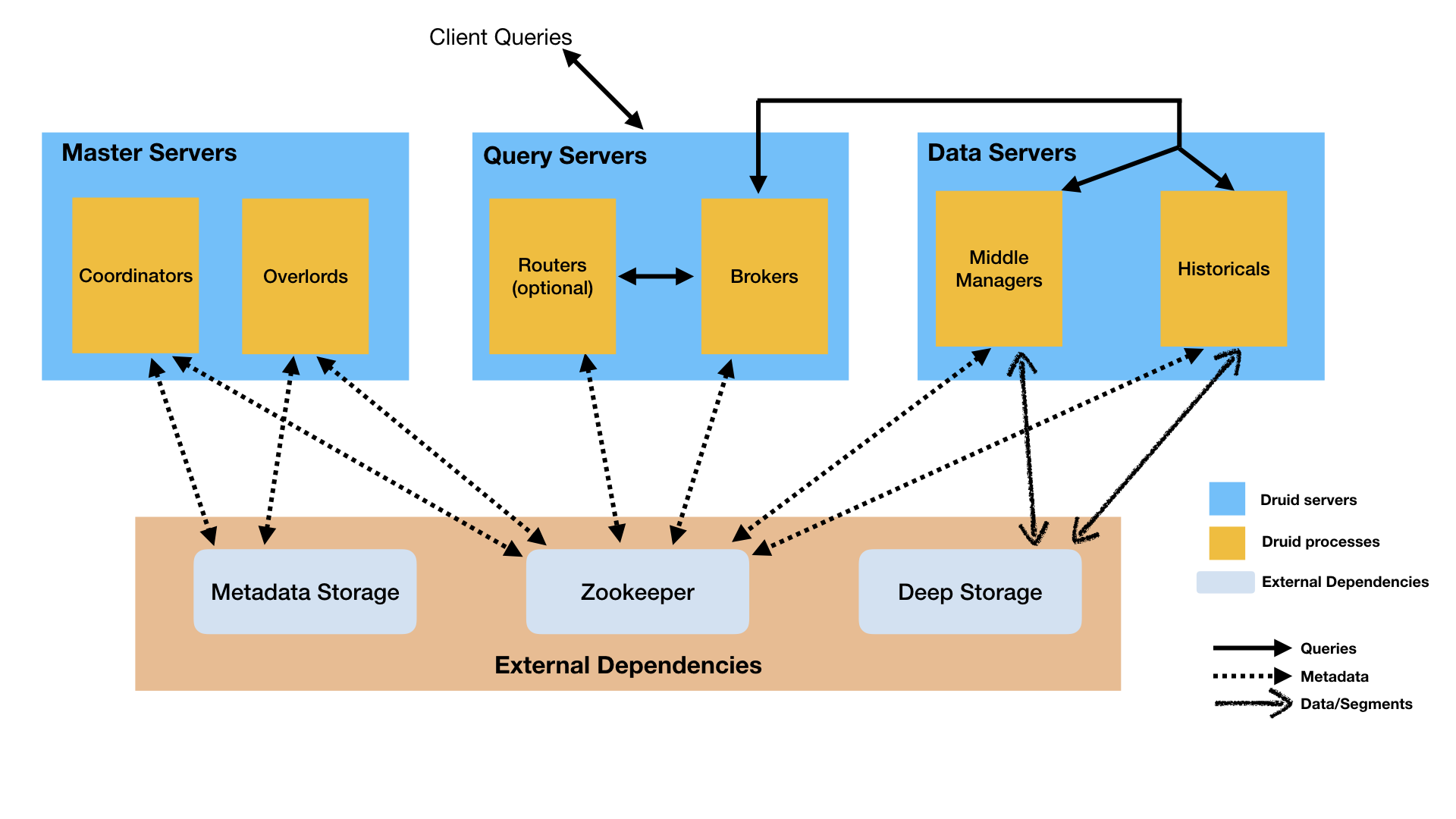
Druid has a multi-process, distributed architecture that is designed to be cloud-friendly and easy to operate. Each Druid process type can be configured and scaled independently, giving you maximum flexibility over your cluster. This design also provides enhanced fault tolerance: an outage of one component will not immediately affect other components.
Druid's process types are:
- Historical processes are the workhorses that handle storage and querying on "historical" data (including any streaming data that has been in the system long enough to be committed). Historical processes download segments from deep storage and respond to queries about these segments. They don't accept writes.
- MiddleManager processes handle ingestion of new data into the cluster. They are responsible for reading from external data sources and publishing new Druid segments.
- Broker processes receive queries from external clients and forward those queries to Historicals and MiddleManagers. When Brokers receive results from those subqueries, they merge those results and return them to the caller. End users typically query Brokers rather than querying Historicals or MiddleManagers directly.
- Coordinator processes watch over the Historical processes. They are responsible for assigning segments to specific servers, and for ensuring segments are well-balanced across Historicals.
- Overlord processes watch over the MiddleManager processes and are the controllers of data ingestion into Druid. They are responsible for assigning ingestion tasks to MiddleManagers and for coordinating segment publishing.
- Router processes are optional processes that provide a unified API gateway in front of Druid Brokers, Overlords, and Coordinators. They are optional since you can also simply contact the Druid Brokers, Overlords, and Coordinators directly.
Druid processes can be deployed individually (one per physical server, virtual server, or container) or can be colocated on shared servers. One common colocation plan is a three-type plan:
- "Data" servers run Historical and MiddleManager processes.
- "Query" servers run Broker and (optionally) Router processes.
- "Master" servers run Coordinator and Overlord processes. They may run ZooKeeper as well.
In addition to these process types, Druid also has three external dependencies. These are intended to be able to leverage existing infrastructure, where present.
- Deep storage, shared file storage accessible by every Druid server. This is typically going to be a distributed object store like S3 or HDFS, or a network mounted filesystem. Druid uses this to store any data that has been ingested into the system.
- Metadata store, shared metadata storage. This is typically going to be a traditional RDBMS like PostgreSQL or MySQL.
- ZooKeeper is used for internal service discovery, coordination, and leader election.
The idea behind this architecture is to make a Druid cluster simple to operate in production at scale. For example, the separation of deep storage and the metadata store from the rest of the cluster means that Druid processes are radically fault tolerant: even if every single Druid server fails, you can still relaunch your cluster from data stored in deep storage and the metadata store.
The following diagram shows how queries and data flow through this architecture:
Datasources and segments
Druid data is stored in "datasources", which are similar to tables in a traditional RDBMS. Each datasource is partitioned by time and, optionally, further partitioned by other attributes. Each time range is called a "chunk" (for example, a single day, if your datasource is partitioned by day). Within a chunk, data is partitioned into one or more "segments". Each segment is a single file, typically comprising up to a few million rows of data. Since segments are organized into time chunks, it's sometimes helpful to think of segments as living on a timeline like the following:
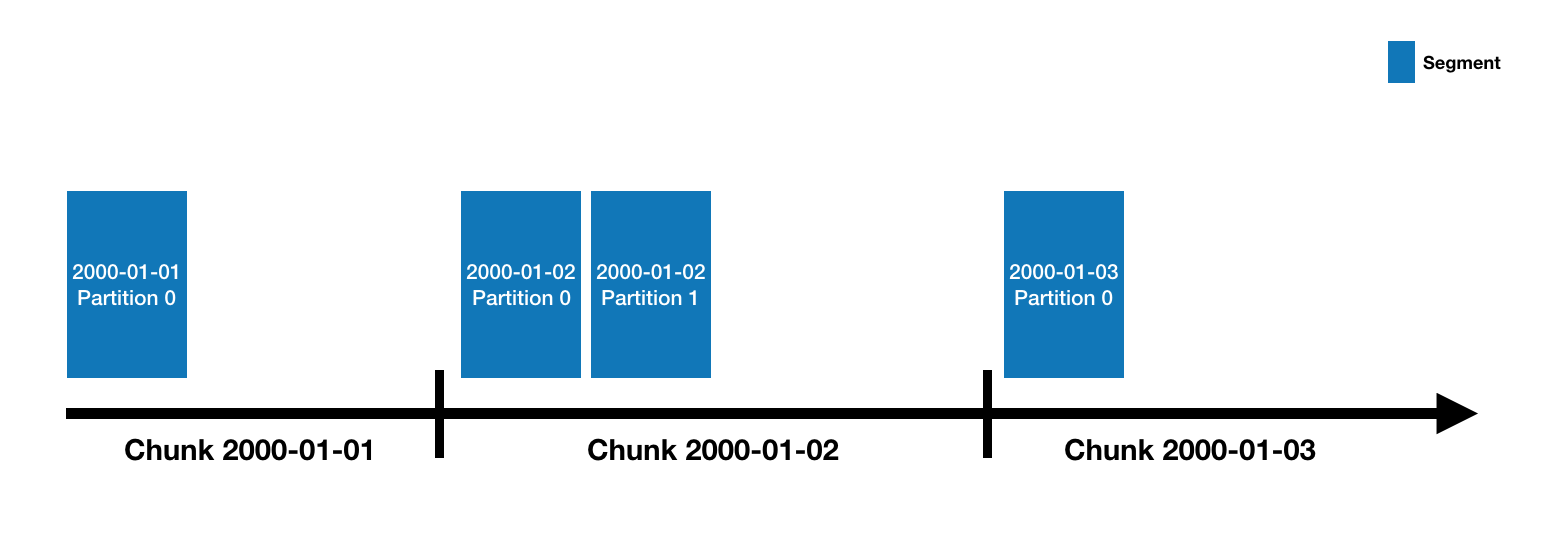
A datasource may have anywhere from just a few segments, up to hundreds of thousands and even millions of segments. Each segment starts life off being created on a MiddleManager, and at that point, is mutable and uncommitted. The segment building process includes the following steps, designed to produce a data file that is compact and supports fast queries:
- Conversion to columnar format
- Indexing with bitmap indexes
- Compression using various algorithms
- Dictionary encoding with id storage minimization for String columns
- Bitmap compression for bitmap indexes
- Type-aware compression for all columns
Periodically, segments are committed and published. At this point, they are written to deep storage, become immutable, and move from MiddleManagers to the Historical processes (see Architecture above for details). An entry about the segment is also written to the metadata store. This entry is a self-describing bit of metadata about the segment, including things like the schema of the segment, its size, and its location on deep storage. These entries are what the Coordinator uses to know what data should be available on the cluster.
Query processing
Queries first enter the Broker, where the Broker will identify which segments have data that may pertain to that query. The list of segments is always pruned by time, and may also be pruned by other attributes depending on how your datasource is partitioned. The Broker will then identify which Historicals and MiddleManagers are serving those segments and send a rewritten subquery to each of those processes. The Historical/MiddleManager processes will take in the queries, process them and return results. The Broker receives results and merges them together to get the final answer, which it returns to the original caller.
Broker pruning is an important way that Druid limits the amount of data that must be scanned for each query, but it is not the only way. For filters at a more granular level than what the Broker can use for pruning, indexing structures inside each segment allow Druid to figure out which (if any) rows match the filter set before looking at any row of data. Once Druid knows which rows match a particular query, it only accesses the specific columns it needs for that query. Within those columns, Druid can skip from row to row, avoiding reading data that doesn't match the query filter.
So Druid uses three different techniques to maximize query performance:
- Pruning which segments are accessed for each query.
- Within each segment, using indexes to identify which rows must be accessed.
- Within each segment, only reading the specific rows and columns that are relevant to a particular query.
External Dependencies
Deep storage
Druid uses deep storage only as a backup of your data and as a way to transfer data in the background between Druid processes. To respond to queries, Historical processes do not read from deep storage, but instead read pre-fetched segments from their local disks before any queries are served. This means that Druid never needs to access deep storage during a query, helping it offer the best query latencies possible. It also means that you must have enough disk space both in deep storage and across your Historical processes for the data you plan to load.
For more details, please see Deep storage dependency.
Metadata storage
The metadata storage holds various system metadata such as segment availability information and task information.
For more details, please see Metadata storage dependency
Zookeeper
Druid uses ZooKeeper (ZK) for management of current cluster state.
For more details, please see Zookeeper dependency.
What is Druid?的更多相关文章
- Spring + SpringMVC + Druid + MyBatis 给你一个灵活的后端解决方案
生命不息,折腾不止. 折腾能遇到很多坑,填坑我理解为成长. 两个月前自己倒腾了一套用开源框架构建的 JavaWeb 后端解决方案. Spring + SpringMVC + Druid + JPA(H ...
- Spring + SpringMVC + Druid + JPA(Hibernate impl) 给你一个稳妥的后端解决方案
最近手头的工作不太繁重,自己试着倒腾了一套用开源框架组建的 JavaWeb 后端解决方案. 感觉还不错的样子,但实践和项目实战还是有很大的落差,这里只做抛砖引玉之用. 项目 git 地址:https: ...
- 学记:spring boot使用官网推荐以外的其他数据源druid
虽然spring boot提供了4种数据源的配置,但是如果要使用其他的数据源怎么办?例如,有人就是喜欢druid可以监控的强大功能,有些人项目的需要使用c3p0,那么,我们就没办法了吗?我们就要编程式 ...
- druid连接池获取不到连接的一种情况
数据源一开始配置: jdbc.initialSize=1jdbc.minIdle=1jdbc.maxActive=5 程序运行一段时间后,执行查询抛如下异常: exception=org.mybati ...
- druid配置数据库连接使用密文密码
spring使用druid配置dataSource片段代码 dataSource配置 <!-- 基于Druid数据库链接池的数据源配置 --> <bean id="data ...
- [转]阿里巴巴数据库连接池 druid配置详解
一.背景 java程序很大一部分要操作数据库,为了提高性能操作数据库的时候,又不得不使用数据库连接池.数据库连接池有很多选择,c3p.dhcp.proxool等,druid作为一名后起之秀,凭借其出色 ...
- 技术杂记-改造具有监控功能的数据库连接池阿里Druid,支持simple-jndi,kettle
kettle内置的jndi管理是simple-jndi,功能确实比较简单,我需要监控kettle性能,druid确实是很不错的选择,但没有提供对应的支持,我改进了druid源码,实现了simple-j ...
- sql 连接数不释放 ,Druid异常:wait millis 40000, active 600, maxActive 600
Hibernate + Spring + Druid 数据库mysql 由于配置如下 <bean id="dataSource" class="com.alibab ...
- druid sql黑名单 报异常 sql injection violation, part alway true condition not allow
最近使用druid,发现阿里这个连接池 真的很好用,可以监控到连接池活跃连接数 开辟到多少个连接数 关闭了多少个,对于我在项目中查看错误 问题,很有帮助, 但是最近发现里面 有条sql语句 被拦截了, ...
- 从零开始学 Java - 数据库连接池的选择 Druid
我先说说数据库连接 数据库大家都不陌生,从名字就能看出来它是「存放数据的仓库」,那我们怎么去「仓库」取东西呢?当然需要钥匙啦!这就是我们的数据库用户名.密码了,然后我们就可以打开门去任意的存取东西了. ...
随机推荐
- JS使用中碰到的一些问题
settimeout: 1.setTimeout(function () {//这个则会在1秒后进行弹出1 alert(1); }, 1000); 2.setTimeout(alert(1), 100 ...
- 【linux】 scrapy : Could not find a version that satisfies the requirement Twisted>=13.1.0 (from Scrapy) (from versions: )
centos7 + python3 安装 scrapy 时候报错,错误信息如下: Could not find a version that satisfies the requirement Twi ...
- stylus--css 框架使用方法
Stylus是一款需要编译的css语言,所以其本身文件不能被html直接调用,需要要编译为css文件后再进行日常的加载. stylus是一款优秀的css编译语言,需要node.js支持,第一步需要 ...
- java基础---->Runtime类的使用(一)
这里面我们对java中的Runtime类做一个简单的了解介绍.若不常想到无常和死,虽有绝顶的聪明,照理说也和呆子一样. Runtimeo类的使用 一.得到系统内存的一些信息 @Test public ...
- 【线程】Thread中的join介绍
因为sleep.wait.join等阻塞,可以使用interrupted exception异常唤醒. 一.作用 Thread类中的join方法的主要作用就是同步,它可以使得线程之间的并行执行变为串行 ...
- 关于array.sort(array,array)
// 基于第一个 System.Array 中的关键字,使用每个关键字的 System.IComparable 实现,对两个一维 System.Array // 对象(一个包含关键字,另一个包含对应的 ...
- 百度编辑器(UEditor)自定义工具栏
百度编辑器(UEditor)自定义工具栏的自定义 百度编辑器默认功能比较齐全,但是不一定是我们所需要的,有的功能可以去掉,用自己想要的就可以了,可以参考百度官方文档! 百度编辑器默认配置展示界面 如何 ...
- Linux 如何开启SFTP
一.SFTP讲解 SFTP 是Secure File Transfer Protocol的缩写,安全文件传送协议.可以为传输文件提供一种安全的加密方法. SFTP 与 FTP有着几乎一样的语法和功能. ...
- VScode首选项
首选项相关的设置: // 将设置放入此文件中以覆盖默认设置 { "workbench.iconTheme": "vscode-icons", "wor ...
- 深入浅出WPF之Binding的使用(一)
在WPF中Binding可以比作数据的桥梁,桥梁的两端分别是Binding的源(Source)和目标(Target).一般情况下,Binding源是逻辑层对象,Binding目标是UI层的控件对象:这 ...