Kylin安装部署
一、安装准备
1、操作系统 Centos 7.x
2、时间问题
集群内所有节点时间一定要同步。 NTP、Chrony
3、用户
创建hadoop组和hadoop用户,并做ssh免密码登录
4、Hadoop HA集群
Hadoop 2.7.
5、HBase
hbase .x
6、Hive
Hive 1.2.,使用 mysql 存放元数据
7、准备目录
# mkdir /install # cd /install # chown -R hadoop:hadoop /install
8、kylin
kylin 1.6. 这个版本支持hbase1.x版本 apache-kylin-1.6.-HBase1.1.3-bin.tar.gz $ tar xf apache-kylin-1.6.-hbase1.x-bin.tar.gz -C /install $ cd /install $ mv apache-kylin-1.6.-bin/ kylin
#代表在root用户下
$代表普通用户
二、环境变量配置
部署每个节点 hadoop用户的 .bashrc export HADOOPROOT=/install export HADOOP_HOME=$HADOOPROOT/hadoop export ZOOKEEPER_HOME=$HADOOPROOT/zookeeper export HBASE_HOME=$HADOOPROOT/hbase export HIVE_HOME=$HADOOPROOT/hive1. export HCAT_HOME=$HIVE_HOME/hcatalog export KYLIN_HOME=$HADOOPROOT/kylin export CATALINA_HOME=$KYLIN_HOME/tomcat export hive_dependency=$HIVE_HOME/conf:$HIVE_HOME/lib/*:$HCAT_HOME/share/hcatalog/hive-hcatalog-core-1.2.1.jar PATH=$PATH:$HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin PATH=$PATH:$HBASE_HOME/bin:$FLUME_HOME/bin:$HIVE_HOME/bin:$HCAT_HOME/bin PATH=$PATH:$CATALINA_HOME/bin:$KYLIN_HOME/bin export PATH
基本的配置已经做好了,安装从以下步骤开始
三、配置kylin
修改bin/kylin.sh
export KYLIN_HOME=/install/kylin
export HBASE_CLASSPATH_PREFIX=${tomcat_root}/bin/bootstrap.jar:${tomcat_root}/bin/tomcat-juli.jar:${tomcat_root}/lib/*:$hive_dependency:$HBASE_CLASSPATH_PREFIX
压缩问题
关于压缩的问题
本次不是用snappy,如果需要事先重新编译Hadoop源码,使得native库支持snappy
使用snappy能够实现一个适合的压缩比,使得这个运算的中间结果和最终结果都能占用较小的存储空间
1、 kylin.properties
)设置Rest Server kylin.rest.servers=192.168.56.201: 默认为PST,修改为中国时间 kylin.rest.timezone=GMT+
2)不启用压缩,注释即可
#kylin.hbase.default.compression.codec=snappy(注释掉或者设置为None)
3)定义kylin用于MR jobs的job.jar包和hbase的协处理jar包,用于提升性能(添加项)。
kylin.job.jar=/installsoftware/ kylin-1.6./lib /kylin-job-1.6..jar kylin.coprocessor.local.jar=/installsoftware/ kylin-1.6./lib/kylin-coprocessor-1.6..jar
2、kylin_job_conf.xml
不使用压缩 mapreduce.map.output.compress设置为false mapreduce.output.fileoutputformat.compress 设置为false
3、kylin_hive_conf.xml
不使用压缩 hive.exec.compress.output 设置为false
四、启动服务
Kylin工作原理图

支撑服务启动
1、首先看一下时间是否同步
、启动3个节点的ZooKeeper zkServer.sh start start-dfs.sh start-yarn.sh 或者start-all.sh mr-jobhistory-daemon.sh start historyserver要到所有NM上启动,可以写成脚本 start-hbase.sh
> list
这里可以启动hive客户端看看
$ hive
> show tables;
检查
1、检查基础的服务
Hadoop、HBase、Hive、环境变量、工作目录
2、hive依赖检查
find-hive-dependency.sh
3、hbase依赖检查
find-hbase-dependency.sh 启动kylin bin/kylin.sh start 停止过程 bin/kylin.sh stop stop-hbase.sh mr-jobhistory-daemon.sh stop historyserver stop-yarn.sh stop-dfs.sh zkServer.sh stop 可以写成脚本
五、登录
http://node1:7070/kylin
ADMIN/KYLIN登录
六、样例数据测试
启动kylin后,运行bin/sample.sh
查看sample.sh脚本内容
实际上操作的是sample_cube目录下的数据和脚本

重启kylin服务
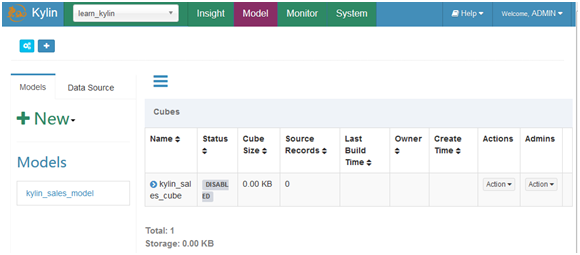
看看hive和hbase
Hive中kylin的元数据信息


默认有一个Cube定义,需要Build。
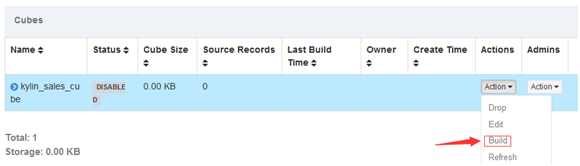

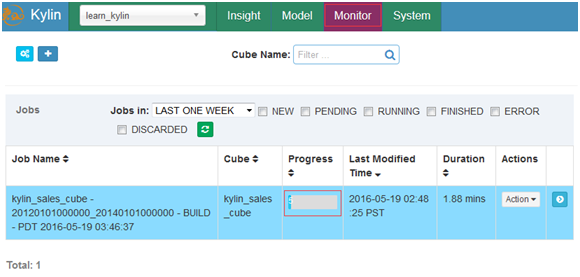
Monitor中监视整个构建过程
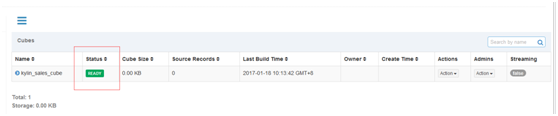
Cube构建成功后状态会变成Ready状态
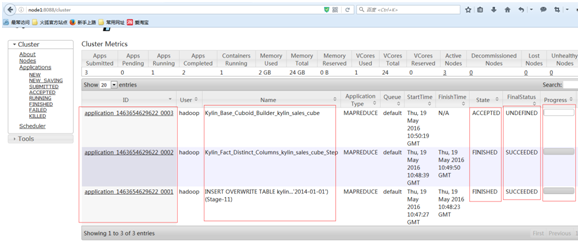
构建Cube过程根据集群性能的不同而不同
七、查询时间对比
测试语句 select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt; select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers from kylin_sales where part_dt<'2013-01-01' group by part_dt order by part_dt; hive执行时间 Time taken: 168.643 seconds, Fetched: row(s) kylin中 第一次 .33S 第二次 .38s 第三次 .33s 第四次 .34s 看来有缓存 select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers from kylin_sales group by part_dt having sum(price)> order by part_dt
到此Kylin的前期安装部署已经完毕
Kylin安装部署的更多相关文章
- Apache Kylin安装部署
0x01 Kylin安装环境 Kylin依赖于hadoop大数据平台,安装部署之前确认,大数据平台已经安装Hadoop, HBase, Hive. 1.1 了解kylin的两种二进制包 预打包的二进制 ...
- 分布式大数据多维分析(OLAP)引擎Apache Kylin安装配置及使用示例【转】
Kylin 麒麟官网:http://kylin.apache.org/cn/download/ 关键字:olap.Kylin Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的 ...
- kylin 系列(一)安装部署
kylin 系列(一)安装部署 一.环境说明 1.1 版本选择 cdh 版本下载地址:http://archive.cloudera.com/cdh5/cdh/5/ 软件名称 版本 JDK 1.8 H ...
- Ranger安装部署
1. 概述 Apache Ranger是大数据领域的一个集中式安全管理框架,目的是通过制定策略(policies)实现对Hadoop组件的集中式安全管理.用户可以通过Ranger实现对集群中数据的安全 ...
- Apache Ranger 编译安装部署
1. 概述 Apache Ranger是大数据领域的一个集中式安全管理框架,目的是通过制定策略(policies)实现对Hadoop组件的集中式安全管理.用户可以通过Ranger实现对集群中数据的安全 ...
- Oracle安装部署,版本升级,应用补丁快速参考
一.Oracle安装部署 1.1 单机环境 1.2 Oracle RAC环境 1.3 Oracle DataGuard环境 1.4 主机双机 1.5 客户端部署 二.Oracle版本升级 2.1 单机 ...
- KVM安装部署
KVM安装部署 公司开始部署KVM,KVM的全称是kernel base virtual machine,对KVM虚拟化技术研究了一段时间, KVM是基于硬件的完全虚拟化,跟vmware.xen.hy ...
- Linux平台oracle 11g单实例 + ASM存储 安装部署 快速参考
操作环境:Citrix虚拟化环境中申请一个Linux6.4主机(模板)目标:创建单机11g + ASM存储 数据库 1. 主机准备 2. 创建ORACLE 用户和组成员 3. 创建以下目录并赋予对应权 ...
- 分布式文件系统 - FastDFS 在 CentOS 下配置安装部署
少啰嗦,直接装 看过上一篇分布式文件系统 - FastDFS 简单了解一下的朋友应该知道,本次安装是使用目前余庆老师开源的最新 V5.05 版本,是余庆老师放在 Github 上的,和目前你能在网络上 ...
随机推荐
- 删除sql注入
), );--过滤字符串 字符串及之后的数据将被替换为空 set @FilterStr='</title><style>.alx2{'; set @curTable='user ...
- 给Repeater控件里添加序号的5种方法
Repeater是我们经常用的一个显示数据集的数据控件,经常我们希望在数据前显示数据的序号,那么我们该怎么为Repeater控件添加序号呢?下面编辑为大家介绍几种常用的为Repeater控件添加序号的 ...
- Sencha Touch 实战开发培训 视频教程 第二期 第四节
2014.4.14 晚上8:10分开课. 本节课耗时没有超出一个小时,主要讲解了list的一些扩展用法. 本期培训一共八节,前两节免费,后面的课程需要付费才可以观看. 本节内容: List的高级应用 ...
- WIN7开启wifi热点
1.首先,先确定自己的笔记本网卡支持“启动承载网络”的功能,使用管理员运行cmd命令.启用管理员运行CMD的方法Windows-所有程序-附件-运行(右键,以管理员身份运行)在弹出的CMD窗口里面敲击 ...
- 【CF873F】Forbidden Indices 后缀自动机
[CF873F]Forbidden Indices 题意:给你一个串s,其中一些位置是危险的.定义一个子串的出现次数为:它的所有出现位置中,不是危险位置的个数.求s的所有子串中,长度*出现次数的最大值 ...
- Spring Cloud Eureka 高可用注册中心
参考:<<spring cloud 微服务实战>> 在微服务架构这样的分布式环境中,各个组件需要进行高可用部署. Eureka Server 高可用实际上就是将自己作为服务向其 ...
- Adobe edge animate制作HTML5动画可视化工具(一)
Edge Animate for mac是Adobe最新出品的制作HTML5动画的可视化工具,简单的可以理解为HTML5版本的Flash Pro.在之后的文章中,我会逐一的介绍这款新的HTML5动画神 ...
- SQL已存在则更新不存在则插入
不废话,下代码. replace into T_Life_UMessage(message_id,account,isread,isdelete)values(?,?,1,1) 意思是若不存在则插入要 ...
- Java 多线程 ---- 线程中this与 Thread.currentThread()线程的区别
总结起来一句话:在Thread中调用this其实就是调用Thread私有Runnable类型的target,target是Thread类的一个属性,而Thread.currentThread()是指新 ...
- 转Python SciPy库——拟合与插值
1.最小二乘拟合 实例1 import numpy as np import matplotlib.pyplot as plt from scipy.optimize import leastsq p ...