hashmap引起死循环
今天开发环境压测的时候出现cpu用满了情况,看线程堆栈,一堆线程都停留在org.apache.commons.collections4.map.AbstractHashedMap.put(AbstractHashedMap.java:285),查看google源代码
public Object put(Object key, Object value) {
key = convertKey(key);
int hashCode = hash(key);
int index = hashIndex(hashCode, data.length);
HashEntry entry = data[index];
while (entry != null) {
if (entry.hashCode == hashCode && isEqualKey(key, entry.key)) {
Object oldValue = entry.getValue();
updateEntry(entry, value);
return oldValue;
}
entry = entry.next;
}
addMapping(index, hashCode, key, value);
return null;
}
方法是非线程安全的,而addMapping方法会触发ensureCapacity扩容,而并发扩容就会容易导致死循环, 具体原因参考文章https://www.cnblogs.com/dongguacai/p/5599100.html
解决方法:
1、使用ConcurrentHashMap。
2、使用Collections.synchronizedMap(Mao<K,V> m)方法把HashMap变成一个线程安全的Map。
我copy了部分文章内容
正常的扩容过程
我们先来看下单线程情况下,正常的rehash过程
1、假设我们的hash算法是简单的key mod一下表的大小(即数组的长度)。
2、最上面是old hash表,其中HASH表的size=2,所以key=3,5,7在mod 2 以后都冲突在table[1]这个位置上了。
3、接下来HASH表扩容,resize=4,然后所有的<key,value>重新进行散列分布,过程如下:
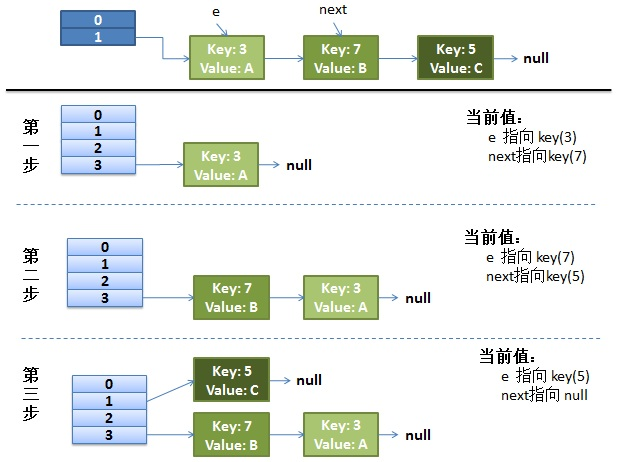
在单线程情况下,一切看起来都很美妙,扩容过程也相当顺利。接下来看下并发情况下的扩容。
并发情况下的扩容
1、首先假设我们有两个线程,分别用红色和蓝色标注了。
2、扩容部分的源代码:

1 void transfer(Entry[] newTable) {
2 Entry[] src = table;
3 int newCapacity = newTable.length;
4 for (int j = 0; j < src.length; j++) {
5 Entry<K,V> e = src[j];
6 if (e != null) {
7 src[j] = null;
8 do {
9 Entry<K,V> next = e.next;
10 int i = indexFor(e.hash, newCapacity);
11 e.next = newTable[i];
12 newTable[i] = e;
13 e = next;
14 } while (e != null);
15 }
16 }
17 }
3、如果在线程一执行到第9行代码就被CPU调度挂起,去执行线程2,且线程2把上面代码都执行完毕。我们来看看这个时候的状态:
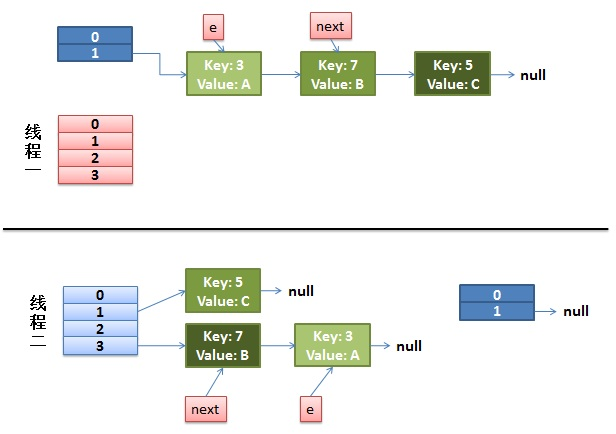
4、接着CPU切换到线程一上来,执行8-14行代码,首先安置3这个Entry:
这里需要注意的是:线程二已经完成执行完成,现在table里面所有的Entry都是最新的,就是说7的next是3,3的next是null;现在第一次循环已经结束,3已经安置妥当。看看接下来会发生什么事情:
1、e=next=7;
2、e!=null,循环继续
3、next=e.next=3
4、e.next 7的next指向3
5、放置7这个Entry,现在如图所示:

放置7之后,接着运行代码:
1、e=next=3;
2、判断不为空,继续循环
3、next= e.next 这里也就是3的next 为null
4、e.next=7,就3的next指向7.
5、放置3这个Entry,此时的状态如图:
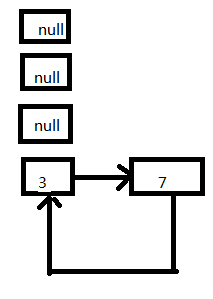
这个时候其实就出现了死循环了,3移动节点头的位置,指向7这个Entry;在这之前7的next同时也指向了3这个Entry。
代码接着往下执行,e=next=null,此时条件判断会终止循环。这次扩容结束了。但是后续如果有查询(无论是查询的迭代还是扩容),都会hang死在table【3】这个位置上。现在回过来看文章开头的那个Demo,就是挂死在扩容阶段的transfer这个方法上面。
出现上面这种情况绝不是我要在测试环境弄一批数据专门为了演示这种问题。我们仔细思考一下就会得出这样一个结论:如果扩容前相邻的两个Entry在扩容后还是分配到相同的table位置上,就会出现死循环的BUG。在复杂的生产环境中,这种情况尽管不常见,但是可能会碰到。
hashmap引起死循环的更多相关文章
- 图解集合5:不正确地使用HashMap引发死循环及元素丢失
问题引出 前一篇文章讲解了HashMap的实现原理,讲到了HashMap不是线程安全的.那么HashMap在多线程环境下又会有什么问题呢? 几个月前,公司项目的一个模块在线上运行的时候出现了死循环,死 ...
- 多线程下HashMap的死循环问题
多线程下[HashMap]的问题: 1.多线程put操作后,get操作导致死循环.2.多线程put非NULL元素后,get操作得到NULL值.3.多线程put操作,导致元素丢失. 本次主要关注[Has ...
- HashMap的原理与实 无锁队列的实现Java HashMap的死循环 red black tree
http://www.cnblogs.com/fornever/archive/2011/12/02/2270692.html https://zh.wikipedia.org/wiki/%E7%BA ...
- HashMap陷入死循环的例子
//使用这个例子可以模拟HashMap陷入死循环的效果,可能需要执行多次才会出现. 1 package com.hanzi; import java.util.HashMap; public clas ...
- 【转】Java HashMap的死循环
问题的症状 从前我们的Java代码因为一些原因使用了HashMap这个东西,但是当时的程序是单线程的,一切都没有问题.后来,我们的程序性能有问题,所以需要变成多线程的,于是,变成多线程后到了线上,发现 ...
- 集合(五)不正确地使用HashMap引发死循环及元素丢失
前一篇文章讲解了HashMap的实现原理,讲到了HashMap不是线程安全的.那么HashMap在多线程环境下又会有什么问题呢? 几个月前,公司项目的一个模块在线上运行的时候出现了死循环,死循环的代码 ...
- JDK(九)JDK1.7源码分析【集合】HashMap的死循环
前言 在JDK1.7&1.8源码对比分析[集合]HashMap中我们遗留了一个问题:为什么HashMap在调用resize() 方法时会出现死循环?这篇文章就通过JDK1.7的源码来分析并解释 ...
- 面试突击17:HashMap除了死循环还有什么问题?
面试合集:https://gitee.com/mydb/interview 本篇的这个问题是一个开放性问题,HashMap 除了死循环之外,还有其他什么问题?总体来说 HashMap 的所有" ...
- Java HashMap的死循环
在淘宝内网里看到同事发了贴说了一个CPU被100%的线上故障,并且这个事发生了很多次,原因是在Java语言在并发情况下使用HashMap造 成Race Condition,从而导致死循环.这个事情我4 ...
- HashMap多线程死循环问题
HashMap通常会用一个指针数组(假设为table[])来做分散所有的key,当一个key被加入时,会通过Hash算法通过key算出这个数组的下标i,然后就把这个<key, value> ...
随机推荐
- Maven入门-3.pom文件和settings文件
1.pom.xml文件介绍2.settings.xml文件介绍 1.pom.xml文件介绍 Maven项目的核心是pom.xml,pom(Project Object Model项目对象模型) pom ...
- UITableView简述
原帖:http://blog.csdn.net/totogo2010/article/details/7642908 Table View简单描述: 在iPhone和其他iOS的很多程序中都会看到Ta ...
- 公告:《那些年,追寻Jmeter的足迹》上线
在我们团队的努力下,我们<那些年,追寻Jmeter的足迹>手册第1版本工作完成(后面还会有第2版本),比较偏基础,这是汇集我们团队的经验和团队需要用到的知识点来整理的,在第2个版本,我们整 ...
- shell 脚本实战笔记(4)--linux磁盘分区重新挂载
背景: Hadoop的HDFS文件系统的挂载, 默认指定的文件目录是/mnt/disk{N}. 当运维人员, 不小心把磁盘挂载于其他目录, 比如/mnt/data, /mnt/disk01, /mnt ...
- Vec3b类型数据确定颜色通道
前言 这几天实习生测试一张图像的三个通道分别是什么颜色,使用的是Vec3b类型,然后发现了一个有意思的点.. 测试过程 先创建了一定大小的数据, Mat test( , , CV_8UC3, Scal ...
- Softmax回归介绍
把输入值当成幂指数求值,再正则化这些结果值.这个幂运算表示,更大的证据对应更大的假设模型(hypothesis)里面的乘数权重值.反之,拥有更少的证据意味着在假设模型里面拥有更小的乘数系数.假设模型里 ...
- 数组Arry的随机排序
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...
- elasticsearch问题解决之分片副本UNASSIGNED
在上一篇文章中,我记录了在windows下同一台机器上搭建es集群的步骤,第二天在向集群中创建索引的时候,出现了分片副本未分配的情况(UNASSIGNED). 虽然并不影响数据的插入和查询,但是有问题 ...
- Microsoft - Find Biggest Node
public Node findBiggest (Node n1, Node n2){ Node c1 = n1; Node c2 = n2; boolean isPositive = false; ...
- Linux下软件包安装
编译dbus下载地址 :http://dbus.freedesktop.org/releases/dbus/tar zxvf dbus-1.10.0echo ac_cv_have_abstract_s ...