多种方法实现 python 线程池
最近在做一个爬虫相关的项目,单线程的整站爬虫,耗时真的不是一般的巨大,运行一次也是心累,,,所以,要想实现整站爬虫,多线程是不可避免的,那么python多线程又应该怎样实现呢?这里主要要几个问题(关于python多线程的GIL问题就不再说了,网上太多了)。
一、 既然多线程可以缩短程序运行时间,那么,是不是线程数量越多越好呢?
显然,并不是,每一个线程的从生成到消亡也是需要时间和资源的,太多的线程会占用过多的系统资源(内存开销,cpu开销),而且生成太多的线程时间也是可观的,很可能会得不偿失,这里给出一个最佳线程数量的计算方式:
最佳线程数的获取:
1、通过用户慢慢递增来进行性能压测,观察QPS(即每秒的响应请求数,也即是最大吞吐能力。),响应时间
2、根据公式计算:服务器端最佳线程数量=((线程等待时间+线程cpu时间)/线程cpu时间) * cpu数量
3、单用户压测,查看CPU的消耗,然后直接乘以百分比,再进行压测,一般这个值的附近应该就是最佳线程数量。
二、为什么要使用线程池?
对于任务数量不断增加的程序,每有一个任务就生成一个线程,最终会导致线程数量的失控,例如,整站爬虫,假设初始只有一个链接a,那么,这个时候只启动一个线程,运行之后,得到这个链接对应页面上的b,c,d,,,等等新的链接,作为新任务,这个时候,就要为这些新的链接生成新的线程,线程数量暴涨。在之后的运行中,线程数量还会不停的增加,完全无法控制。所以,对于任务数量不端增加的程序,固定线程数量的线程池是必要的。
三、如何实现线程池?
这里,我分别介绍三种实现方式:
1、过去:
使用threadpool模块,这是个python的第三方模块,支持python2和python3,具体使用方式如下:
#! /usr/bin/env python
# -*- coding: utf-8 -*- import threadpool
import time def sayhello (a):
print("hello: "+a)
time.sleep(2) def main():
global result
seed=["a","b","c"]
start=time.time()
task_pool=threadpool.ThreadPool(5)
requests=threadpool.makeRequests(sayhello,seed)
for req in requests:
task_pool.putRequest(req)
task_pool.wait()
end=time.time()
time_m = end-start
print("time: "+str(time_m))
start1=time.time()
for each in seed:
sayhello(each)
end1=time.time()
print("time1: "+str(end1-start1)) if __name__ == '__main__':
main()
运行结果如下:
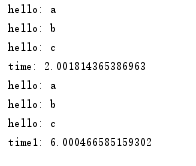
threadpool是一个比较老的模块了,现在虽然还有一些人在用,但已经不再是主流了,关于python多线程,现在已经开始步入未来(future模块)了
2、未来:
使用concurrent.futures模块,这个模块是python3中自带的模块,但是,python2.7以上版本也可以安装使用,具体使用方式如下:
#! /usr/bin/env python
# -*- coding: utf-8 -*- from concurrent.futures import ThreadPoolExecutor
import time def sayhello(a):
print("hello: "+a)
time.sleep(2) def main():
seed=["a","b","c"]
start1=time.time()
for each in seed:
sayhello(each)
end1=time.time()
print("time1: "+str(end1-start1))
start2=time.time()
with ThreadPoolExecutor(3) as executor:
for each in seed:
executor.submit(sayhello,each)
end2=time.time()
print("time2: "+str(end2-start2))
start3=time.time()
with ThreadPoolExecutor(3) as executor1:
executor1.map(sayhello,seed)
end3=time.time()
print("time3: "+str(end3-start3)) if __name__ == '__main__':
main()
运行结果如下:
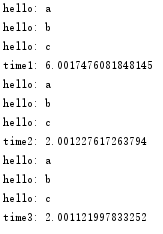
注意到一点:
concurrent.futures.ThreadPoolExecutor,在提交任务的时候,有两种方式,一种是submit()函数,另一种是map()函数,两者的主要区别在于:
2.1、map可以保证输出的顺序, submit输出的顺序是乱的
2.2、如果你要提交的任务的函数是一样的,就可以简化成map。但是假如提交的任务函数是不一样的,或者执行的过程之可能出现异常(使用map执行过程中发现问题会直接抛出错误)就要用到submit()
2.3、submit和map的参数是不同的,submit每次都需要提交一个目标函数和对应的参数,map只需要提交一次目标函数,目标函数的参数放在一个迭代器(列表,字典)里就可以。
3.现在?
这里要考虑一个问题,以上两种线程池的实现都是封装好的,任务只能在线程池初始化的时候添加一次,那么,假设我现在有这样一个需求,需要在线程池运行时,再往里面添加新的任务(注意,是新任务,不是新线程),那么要怎么办?
其实有两种方式:
3.1、重写threadpool或者future的函数:
这个方法需要阅读源模块的源码,必须搞清楚源模块线程池的实现机制才能正确的根据自己的需要重写其中的方法。
3.2、自己构建一个线程池:
这个方法就需要对线程池的有一个清晰的了解了,附上我自己构建的一个线程池:
#! /usr/bin/env python
# -*- coding: utf-8 -*- import threading
import Queue
import hashlib
import logging
from utils.progress import PrintProgress
from utils.save import SaveToSqlite class ThreadPool(object):
def __init__(self, thread_num, args): self.args = args
self.work_queue = Queue.Queue()
self.save_queue = Queue.Queue()
self.threads = []
self.running = 0
self.failure = 0
self.success = 0
self.tasks = {}
self.thread_name = threading.current_thread().getName()
self.__init_thread_pool(thread_num) # 线程池初始化
def __init_thread_pool(self, thread_num):
# 下载线程
for i in range(thread_num):
self.threads.append(WorkThread(self))
# 打印进度信息线程
self.threads.append(PrintProgress(self))
# 保存线程
self.threads.append(SaveToSqlite(self, self.args.dbfile)) # 添加下载任务
def add_task(self, func, url, deep):
# 记录任务,判断是否已经下载过
url_hash = hashlib.new('md5', url.encode("utf8")).hexdigest()
if not url_hash in self.tasks:
self.tasks[url_hash] = url
self.work_queue.put((func, url, deep))
logging.info("{0} add task {1}".format(self.thread_name, url.encode("utf8"))) # 获取下载任务
def get_task(self):
# 从队列里取元素,如果block=True,则一直阻塞到有可用元素为止。
task = self.work_queue.get(block=False) return task def task_done(self):
# 表示队列中的某个元素已经执行完毕。
self.work_queue.task_done() # 开始任务
def start_task(self):
for item in self.threads:
item.start() logging.debug("Work start") def increase_success(self):
self.success += 1 def increase_failure(self):
self.failure += 1 def increase_running(self):
self.running += 1 def decrease_running(self):
self.running -= 1 def get_running(self):
return self.running # 打印执行信息
def get_progress_info(self):
progress_info = {}
progress_info['work_queue_number'] = self.work_queue.qsize()
progress_info['tasks_number'] = len(self.tasks)
progress_info['save_queue_number'] = self.save_queue.qsize()
progress_info['success'] = self.success
progress_info['failure'] = self.failure return progress_info def add_save_task(self, url, html):
self.save_queue.put((url, html)) def get_save_task(self):
save_task = self.save_queue.get(block=False) return save_task def wait_all_complete(self):
for item in self.threads:
if item.isAlive():
# join函数的意义,只有当前执行join函数的线程结束,程序才能接着执行下去
item.join() # WorkThread 继承自threading.Thread
class WorkThread(threading.Thread):
# 这里的thread_pool就是上面的ThreadPool类
def __init__(self, thread_pool):
threading.Thread.__init__(self)
self.thread_pool = thread_pool #定义线程功能方法,即,当thread_1,...,thread_n,调用start()之后,执行的操作。
def run(self):
print (threading.current_thread().getName())
while True:
try:
# get_task()获取从工作队列里获取当前正在下载的线程,格式为func,url,deep
do, url, deep = self.thread_pool.get_task()
self.thread_pool.increase_running() # 判断deep,是否获取新的链接
flag_get_new_link = True
if deep >= self.thread_pool.args.deep:
flag_get_new_link = False # 此处do为工作队列传过来的func,返回值为一个页面内容和这个页面上所有的新链接
html, new_link = do(url, self.thread_pool.args, flag_get_new_link) if html == '':
self.thread_pool.increase_failure()
else:
self.thread_pool.increase_success()
# html添加到待保存队列
self.thread_pool.add_save_task(url, html) # 添加新任务,即,将新页面上的不重复的链接加入工作队列。
if new_link:
for url in new_link:
self.thread_pool.add_task(do, url, deep + 1) self.thread_pool.decrease_running()
# self.thread_pool.task_done()
except Queue.Empty:
if self.thread_pool.get_running() <= 0:
break
except Exception, e:
self.thread_pool.decrease_running()
# print str(e)
break
多种方法实现 python 线程池的更多相关文章
- Python之路(第四十六篇)多种方法实现python线程池(threadpool模块\multiprocessing.dummy模块\concurrent.futures模块)
一.线程池 很久(python2.6)之前python没有官方的线程池模块,只有第三方的threadpool模块, 之后再python2.6加入了multiprocessing.dummy 作为可以使 ...
- Python 线程池的原理和实现及subprocess模块
最近由于项目需要一个与linux shell交互的多线程程序,需要用python实现,之前从没接触过python,这次匆匆忙忙的使用python,发现python确实语法非常简单,功能非常强大,因为自 ...
- Python线程池及其原理和使用(超级详细)
系统启动一个新线程的成本是比较高的,因为它涉及与操作系统的交互.在这种情形下,使用线程池可以很好地提升性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考虑使用线程池. 线程池在系统启动时即 ...
- python线程池ThreadPoolExecutor(上)(38)
在前面的文章中我们已经介绍了很多关于python线程相关的知识点,比如 线程互斥锁Lock / 线程事件Event / 线程条件变量Condition 等等,而今天给大家讲解的是 线程池ThreadP ...
- python线程池示例
使用with方式创建线程池,任务执行完毕之后,会自动关闭资源 , 否则就需要手动关闭线程池资源 import threading, time from concurrent.futures impo ...
- Python线程池与进程池
Python线程池与进程池 前言 前面我们已经将线程并发编程与进程并行编程全部摸了个透,其实我第一次学习他们的时候感觉非常困难甚至是吃力.因为概念实在是太多了,各种锁,数据共享同步,各种方法等等让人十 ...
- 自定义高级版python线程池
基于简单版创建类对象过多,现自定义高级版python线程池,代码如下 #高级线程池 import queue import threading import time StopEvent = obje ...
- 对Python线程池
本文对Python线程池进行详细说明介绍,IDE选择及编码的解决方案进行了一番详细的描述,实为Python初学者必读的Python学习经验心得. AD: 干货来了,不要等!WOT2015 北京站演讲P ...
- Python 线程池(小节)
Python 线程池(小节) from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import os,time, ...
随机推荐
- 处理div 在IE6 IE7 IE8 不居中的问题
具体处理方式如下:1 .html 顶部加入:DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "h ...
- nohup 日志切割
最近遇到日志切割的问题,即程序是通过命令: nohup python *.py & 放到后台执行的,这样程序的日志输出到了nohup自动生成的nohup.out文件. 问题就来了,nohup. ...
- 【Django】【五】开发Web接口
[HTTP协议与JSON] 1. HTTP协议 特点如下: (1)支持客户/服务器模式. 简单快速:客户向服务器请求服务时,只需传送请求方法和路径.请求方法常用的有GET.POST.每种方法规定了客户 ...
- Springboot 编码规范
1.规范的意义和作用 编码规范可以最大限度的提高团队开发的合作效率 编码规范可以尽可能的减少一个软件的维护成本 , 并且几乎没有任何一个软件,在其整个生命周期中,均由最初的开发人员来维护 编码规范可以 ...
- GRASP (职责分配原则)
要学习设计模式,有些基础知识是我们必须要先知道的,设计模式是关于类和对象的一种高效.灵活的使用方式,也就是说,必须先有类和对象,才能有设计模式的用武之地,否则一切都是空谈,那么类和对象是从那冒出来的呢 ...
- QString 编码转换
参考网址:http://blog.csdn.net/lfw19891101/article/details/6641785 (网页保存于:百度云CodeSkill33 --> 全部文件 > ...
- 【Golang 接口自动化01】使用标准库net/http发送Get请求
发送Get请求 使用Golang发送get请求很容易,我们还是使用http://httpbin.org作为服务端来进行演示. package main import ( "bytes&quo ...
- Lua中Table的学习
--table 是 Lua 的一种数据结构,用来帮助我们创建不同的数据类型,如:数组.字典等 --Lua也是通过table来解决模块(module).包(package)和对象(Object)的. 例 ...
- LeetCode--204--计数质数
问题描述: 统计所有小于非负整数 n 的质数的数量. 示例: 输入: 10 输出: 4 解释: 小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 . 方法1:经典的判断是否为质数遍历( ...
- 20170228VBA提取邮件部分信息
Sub 获取OutLook收件箱主题和正文() On Error Resume Next Dim sht As Worksheet Dim olApp As Outlook.Application D ...