Java集合框架体系详细梳理,含面试知识点。
一、集合类
集合的由来:
面向对象语言对事物都是以对象的形式来体现,为了方便对多个对象的操作,就需要将对象进行存储,集合就是存储对象最常用的一种方式。
集合特点:
1,用于存储对象的容器。(容器本身就是一个对象,存在于堆内存中,里面存的是对象的地址)
2,集合的长度是可变的。
3,集合中不可以存储基本数据类型值。 (只能存对象)
小问题:想用集合存基本数据类型怎么办?
装箱、拆箱。 例:al.add(5); // 相当于al.add(new Integer(5));
集合和数组的区别:
数组虽然也可以存储对象,但长度是固定的,集合长度是可变的。
数组中可以存储基本数据类型,集合只能存储对象。
集合框架的构成及分类:(虚线为接口)
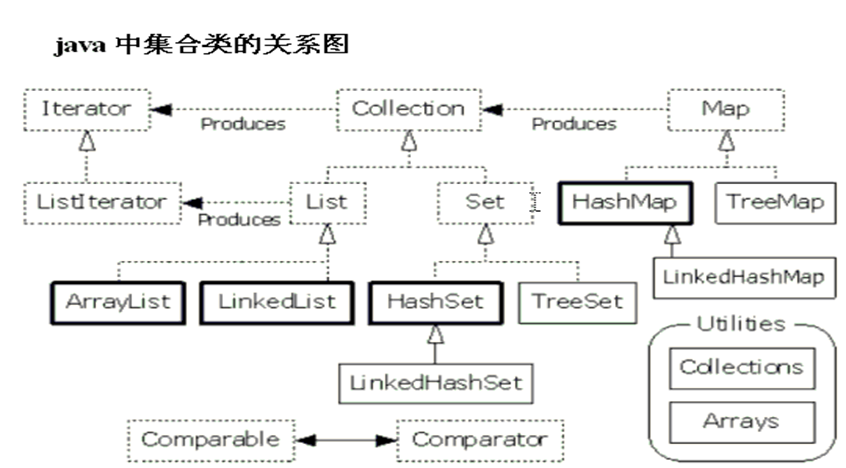
下面分别整理集合框架中的几个顶层接口。
二、 Collection接口
Collection子接口以及常用实现类:
Collection接口
|--List接口:有序(存入和取出的顺序一致),元素都有索引(角标),元素可以重复。
|--Vector:内部是 数组 数据结构,是同步的。增删,查询都很慢!100%延长(几乎不用了)
|--ArrayList:内部是 数组 数据结构,是不同步的。替代了Vector,查询的速度快,增删速度慢。50%延长。(查询时是从容器的第一个元素往后找,由于数组的内存空间是连续的,所以查询快;增删的话所有元素内存地址都要改变,所以增删慢。)
|--LinkedList:内部是 链表 数据结构,是不同步的。增删元素的速度很快。(同理,链表的内存空间是不连续的,所以查询慢;增删时只需改变单个指针的指向,所以快;)
|--Set接口:无序,元素不能重复。Set接口中的方法和Collection一致。
|--HashSet: 内部数据结构是哈希表 ,是不同步的。
|--LinkedHashSet:内部数据结构是哈希表和链表,是有顺序的HashSet。
|--TreeSet:内部数据结构是有序的二叉树,它的作用是提供有序的Set集合,是不同步的。
List接口:
有一个最大的共性特点就是都可以操作角标,所以LinkedList也是有索引的。list集合可以完成对元素的增删改查。
Set和List的区别:
1. Set 接口实例存储的是无序的,不重复的数据。List 接口实例存储的是有序的,可以重复的元素 <最本质区别>。
2. Set检索效率低下,删除和插入效率高,插入和删除不会引起元素位置改变 。
3. List和数组类似,可以动态增长,根据实际存储的数据的长度自动增长List的长度。查找元素效率高,插入删除效率低,因为会引起其他元素位置改变 。
ArryList和Vector可变长度数组的原理:
当默认长度的数组不够存储时,会建立一个新数组。将原来数组的内容拷贝到新的数组当中,并将新增加的元素追加到拷贝完的数组尾,如果仍然不够重复上述动作。其中,ArryList的增加是以原来50%长度进行增加,而Vector是按照100%延长。
ArryList是线程不安全的,Vector是安全的:
由于是否有锁的判断将影响效率,故Arrylist效率远远高于Vector。而且只要是常用的容器就不是同步的,因为同步效率比较低。
ArryList存取对象的一个小例子:
Person p1 = new Person("lisi1",21);
ArrayList al = new ArrayList();
al.add(p1);
al.add(new Person("lisi2",22));
al.add(new Person("lisi3",23));
al.add(new Person("lisi4",24));
Iterator it = al.iterator();
while(it.hasNext()){
// System.out.println(((Person) it.next()).getName()+"::"+((Person) it.next()).getAge());
//错误方式:不能这样取,next()一次指针会移动一次,会输出“lisi1::22 lisi3::24”
// 正确方式:拿到一个Person对象,然后取属性。
Person p = (Person) it.next();
System.out.println(p.getName()+"--"+p.getAge());
}
HashSet之覆盖hashCode方法和equals方法来保证元素唯一性
如何保证HashSet的元素唯一性呢?
是通过对象的hashCode和equals方法来完成对象唯一性的:
->如果对象的hashCode值不同,那么不用判断equals方法,就直接存储到哈希表中。
->如果对象的hashCode值相同,那么要再次判断对象的equals方法是否为true:
如果为true,视为相同元素,不存;如果为false,那么视为不同元素,就进行存储。
记住:如果对象要存储到HashSet集合中,该对象必须覆盖hashCode方法和equals方法。
一般情况下,如果定义的类会产生很多对象,比如人,学生,书,通常都需要覆盖equals,hashCode方法,以建立对象判断是否相同的依据。
例:往HashSet集合中存储Person对象。如果姓名和年龄相同,视为同一个人,视为相同元素。
import java.util.HashSet;
import java.util.Iterator; class Person { private String name;
private int age; public Person(String name, int age) {
this.name = name;
this.age = age;
} @Override
public int hashCode() {
// System.out.println(this+".......hashCode");
return name.hashCode() + age * 27; // 乘以一个任意数,防止加了年龄以后HashCode仍相同
} @Override
public boolean equals(Object obj) {
// 健壮性判断
if (this == obj)
return true;
if (!(obj instanceof Person))
throw new ClassCastException("类型错误");
// System.out.println(this+"....equals....."+obj); Person p = (Person) obj;
return this.name.equals(p.name) && this.age == p.age;
} public String getName() {
return name;
} public void setName(String name) {
this.name = name;
} public int getAge() {
return age;
} public void setAge(int age) {
this.age = age;
} public String toString() {
return name + ":" + age;
}
} public class HashSetTest { public static void main(String[] args) {
HashSet hs = new HashSet();
/*
* HashSet集合数据结构是哈希表,所以存储元素的时候,
* 使用的元素的hashCode方法来确定位置,如果位置相同,在通过元素的equals来确定是否相同。
*
*/
hs.add(new Person("lisi4", 24));
hs.add(new Person("lisi7", 27));
hs.add(new Person("lisi1", 21));
hs.add(new Person("lisi9", 29));
hs.add(new Person("lisi7", 27)); Iterator it = hs.iterator();
while (it.hasNext()) {
Person p = (Person) it.next();
System.out.println(p);
}
}
}
运行结果:
lisi1:21
lisi9:29
lisi4:24
lisi7:27
TreeSet之判断元素唯一性的两种方式(如何排序)
TreeSet默认判断元素唯一性的方式:
根据Conpare接口的比较方法conpareTo的返回结果是否是0,是0,就是相同元素,不存。
下面,我们给出两种自定义判断元素唯一性的方式:
方式一:
让元素自身具备比较功能,即根据元素中的属性来比较。采用这种方式需要元素实现Comparable接口,覆盖compareTo方法。
例:往TreeSet集合中存储Person对象。如果姓名和年龄相同,视为同一个人,视为相同元素。
import java.util.Iterator;
import java.util.TreeSet; class Person implements Comparable { public String name;
public int age; public Person() {
super(); } public Person(String name, int age) {
super();
this.name = name;
this.age = age;
} public String toString() {
return name + ":" + age;
} @Override
public int compareTo(Object o) {
Person p = (Person) o; /* 敲黑板划重点,代码简洁方式 */
int temp = this.age - p.age;
return temp == 0 ? this.name.compareTo(p.name) : temp; // 上面这两句相当于底下这一段的简洁形式
// if (this.age > p.age)
// return 1;
// if (this.age < p.age)
// return -1;
// else {
// return this.name.compareTo(p.name);
// }
} public static void main(String[] args) {
TreeSet<Person> ts = new TreeSet<Person>();
ts.add(new Person("zhangsan", 22));
ts.add(new Person("lisi", 27));
ts.add(new Person("wangermazi", 21));
ts.add(new Person("zhaosi", 25)); Iterator it = ts.iterator();
while (it.hasNext()) {
Person person = (Person) it.next();
System.out.println(person.toString());
}
}
}
运行结果:
wangermazi:21
zhangsan:22
zhaosi:25
lisi:27
可以看到,复写compareTo方法后,元素根据age这个属性进行了排序。
方式二:(开发用这个,掌握比较器的用法)
让集合自身具备比较功能。自己写一个比较器,先定义一个类实现Comparator接口,覆盖compare方法。然后将该类对象作为参数传递给TreeSet集合的构造函数。
不再需要元素实现Conparable接口。
step1-新建比较器类ComparedByName.java,覆盖compare方法:
import java.util.Comparator;
public class ComparedByName implements Comparator {
@Override
public int compare(Object o1, Object o2) {
// TODO Auto-generated method stub
Person p1 = (Person) o1;
Person p2 = (Person) o2;
int temp = p1.name.compareTo(p2.name);
return temp == 0 ? p1.age - p2.age : temp;
}
}
step2-将比较器类类对象作为参数传递给TreeSet集合的构造函数:
import java.util.Iterator;
import java.util.TreeSet; class Person implements Comparable { public String name;
public int age; public Person() {
super(); } public Person(String name, int age) {
super();
this.name = name;
this.age = age;
} public String toString() {
return name + ":" + age;
} @Override
public int compareTo(Object o) {
Person p = (Person) o; /* 敲黑板划重点,代码简洁方式 */
int temp = this.age - p.age;
return temp == 0 ? this.name.compareTo(p.name) : temp; // 上面这两句相当于底下这一段的简洁形式
// if (this.age > p.age)
// return 1;
// if (this.age < p.age)
// return -1;
// else {
// return this.name.compareTo(p.name);
// }
} public static void main(String[] args) {
TreeSet<Person> ts = new TreeSet<Person>(new ComparedByName());
ts.add(new Person("zhangsan", 22));
ts.add(new Person("lisi", 27));
ts.add(new Person("wangermazi", 21));
ts.add(new Person("zhaosi", 25)); Iterator it = ts.iterator();
while (it.hasNext()) {
Person person = (Person) it.next();
System.out.println(person.toString());
}
}
}
运行结果:
lisi:27
wangermazi:21
zhangsan:22
zhaosi:25
这次我们的比较器是根据元素属性name进行排序的,复写的compareTo方法是根据age进行排序的。
可以看到,当两种方法同时存在时,是按照比较器的方法来排序的。
思考:如何通过这种方式实现先进先出和先进后出?
让比较器直接返回1或-1即可。
三、Iterator接口
对 Collection 进行迭代的迭代器,即对所有的Collection容器进行元素取出的公共接口。
该迭代器对象依赖于具体容器,因为每一个容器的数据结构都不同,所以该迭代器对象是在具体容器中进行内部实现的。(内部类,可以看具体容器的源码)
对于使用容器者而言,具体的实现方法不重要,只要通过具体容器获取到该实现的迭代器的对象即可,也就是iterator()方法,而不用new。(Iterator<String> ite=list.iterator();)
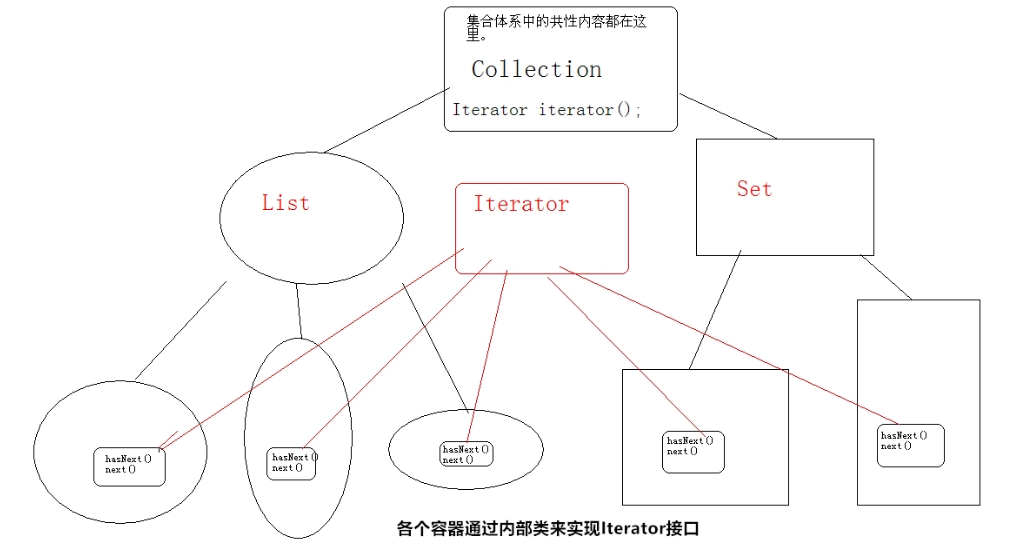
小知识点:使用迭代器过程中while和for的区别
1 第一种
2 Iterator<String> ite=list.iterator();
3 while(ite.hasNext())//判断下一个元素之后有值
4 {
5 System.out.println(ite.next());
6 }
7 第二种
8 Iterator<String> ite=list.iterator();
9 for(Iterator it = coll.iterator(); it.hasNext(); ){
10 System.out.println(it.next());
11 }
第一种方法while循环结束后迭代器对象还在内存中存在,还能继续使用迭代器对象。
第二种方法for循环结束后迭代器对象就消失了,清理了内存,开发中第二种常用。
Iterator的一个子接口
|--ListIterator接口(列表迭代器)
应用场景:
顾名思义,只能用于List的迭代器。
在使用迭代器迭代的过程中需要使用集合中的方法操作元素,出现ConcurrentModificationException异常时,具体看下面的例子。
出现异常情况代码:
Iterator it = list.iterator();
while(it.hasNext()){ Object obj = it.next();//java.util.ConcurrentModificationException
//在使用迭代器的过程中使用集合中的方法add()操作元素,出现异常。
//可以使用Iterator接口的子接口ListIterator来完成在迭代中对元素进行更多的操作。
if(obj.equals("abc2")){
list.add("abc9");
}
else
System.out.println("next:"+obj);
}
System.out.println(list);
解决办法代码:
public static void main(String[] args) {
List list = new ArrayList();
list.add("abc1");
list.add("abc2");
list.add("abc3");
System.out.println("list:"+list);
ListIterator it = list.listIterator();//获取列表迭代器对象
//它可以实现在迭代过程中完成对元素的增删改查。
//注意:只有list集合具备该迭代功能.
while(it.hasNext()){
Object obj = it.next();
if(obj.equals("abc2")){
it.add("abc9"); //ListIterator提供了add方法
}
}
四、Map接口
Map接口与Set类似,可以对照着来学,比如比较器在TreeMap中也适用。
Map: 一次添加一对元素,Collection 一次添加一个元素。
Map也称为双列集合,Collection集合也称为单列集合。
其实map集合中存储的就是键值对,map集合中必须保证键的唯一性。
常用方法:
1,添加
value put(key,value):返回前一个和key关联的值,如果没有返回null.
2,删除
void clear():清空map集合。
value remove(key):根据指定的key翻出这个键值对。
3,判断
boolean containsKey(key):是否包含该key
boolean containsValue(value):是否包含该value
boolean isEmpty();是否为空
4,获取
value get(key):通过键获取值,如果没有该键返回null。当然,可以通过是否返回null,来判断是否包含指定键。
int size(): 获取键值对的个数。
Map常用的子类:(*HashMap与Hashtable的区别,面试常问*,详见这个博客。)
|--Hashtable :内部结构是哈希表,是同步的。不允许null作为键,null作为值。
|--Properties:用来存储键值对型的配置文件的信息,可以和IO技术相结合。
|--HashMap : 内部结构是哈希表,不是同步的。允许null作为键,null作为值。
|--TreeMap : 内部结构是二叉树,不是同步的。可以对Map集合中的键进行排序。
Map的迭代方法:
Map本身没有迭代器。
方法一:利用Map接口的values()方法,返回此映射中包含的值的 Collection (值不唯一),
然后通过Collecion的迭代器进行迭代。(只需要Value,不需要Key的时候)
public class MapDemo {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<Integer,String>();
method_2(map);
}
public static void method_2(Map<Integer,String> map){
map.put(8,"zhaoliu");
map.put(2,"zhaoliu");
map.put(7,"xiaoqiang");
map.put(6,"wangcai");
Collection<String> values = map.values();
Iterator<String> it2 = values.iterator();
while(it2.hasNext()){
System.out.println(it2.next());
}
}
}
方法二:通过keySet方法获取map中所有的键所在的Set集合(Key和Set的都具有唯一性),
再通过Set的迭代器获取到每一个键,再对每一个键通过Map集合的get方法获取其对应的值即可。
Set<Integer> keySet = map.keySet();
Iterator<Integer> it = keySet.iterator(); while(it.hasNext()){
Integer key = it.next();
String value = map.get(key);
System.out.println(key+":"+value);
}
方法三:利用Map的内部接口Map.Entry<K,V>使用iterator。
通过Map的entrySet()方法,将键和值的映射关系作为对象存储到Set集合中。
这个映射关系的类型就是Map.Entry类型(结婚证)。
再通过Map.Entry对象的getKey和getValue获取其中的键和值。
Set<Map.Entry<Integer, String>> entrySet = map.entrySet();
Iterator<Map.Entry<Integer, String>> it = entrySet.iterator();
while(it.hasNext()){
Map.Entry<Integer, String> me = it.next();
Integer key = me.getKey();
String value = me.getValue();
System.out.println(key+":"+value);
}
方法四:通过Map.entrySet()方法遍历key和value(推荐,尤其是容量大时)
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
map中比较器的用法(百度面试题)
百度考到过HashMap中怎么按value来排序。
和Set中比较器的用法类似,这里我们用内部类的形式来实现比较器。简单的例子涵盖了很多知识点。
public class HashMapTest {
// 将内部内修改为静态,直接可以在main函数中创建内部类实例
private static class ValueComparator implements Comparator<Map.Entry<Character, String>> {
@Override
public int compare(Map.Entry<Character, String> entryA, Map.Entry<Character, String> entryB) {
// 复写的方法是compare,String类的方法是compareTo,不要记混。
return entryA.getValue().compareTo(entryB.getValue());
}
}
public static void main(String[] args) {
Map<Character, String> map = new HashMap<>();
map.put('c', "3");
map.put('a', "5");
map.put('b', "1");
map.put('d', "2");
System.out.println("Before Sort:");
for (Map.Entry<Character, String> mapping : map.entrySet()) {
System.out.println(mapping.getKey() + ":" + mapping.getValue());
}
List<Map.Entry<Character, String>> list = new ArrayList<>(map.entrySet());
// 或者list.addAll(map.entrySet());
ValueComparator vc = new ValueComparator();
Collections.sort(list, vc);
System.out.println("After Sort:");
for (Map.Entry<Character, String> mapping : list) {
System.out.println(mapping.getKey() + ":" + mapping.getValue());
}
}
}
map比较器
五、集合框架工具类Collections和Arrays
Collections是集合框架的工具类,里面的方法都是静态的。
例1:根据字符串长度的正序和倒序排序。
用到比较器的地方都可以用Collections.reverseOrder()。
static void |
reverse(List<?> list) 反转指定列表中元素的顺序。 |
|
static
|
reverseOrder() 返回一个比较器,它强行逆转实现了 Comparable 接口的对象 collection 的自然顺序。 |
|
static
|
reverseOrder(Comparator<T> cmp) 返回一个比较器,它强行逆转指定比较器的顺序。 |
比较器ComparatorByLength.java:
import java.util.Comparator;
public class ComparatorByLength implements Comparator<String> {
@Override
public int compare(String o1, String o2) {
int temp = o1.length() - o2.length();
return temp==0?o1.compareTo(o2): temp;
}
}
Demo:
public static void demo_3() {
// reverse实现原理
/*
* TreeSet<String> ts = new TreeSet<String>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
int temp = o2.compareTo(o1);
return temp;
}
});
*/
TreeSet<String> treeset = new TreeSet<String>(new ComparatorByLength());
treeset.add("abc");
treeset.add("hahaha");
treeset.add("zzz");
treeset.add("aa");
treeset.add("cba");
System.out.println(treeset);
TreeSet<String> ts = new TreeSet<String>(Collections.reverseOrder(new ComparatorByLength()));//都是静态方法,直接类名调用
ts.add("abc");
ts.add("hahaha");
ts.add("zzz");
ts.add("aa");
ts.add("cba");
System.out.println("after reverse:\t" + ts);
}
public static void main(String[] args) {
demo_3();
}
[aa, abc, cba, zzz, hahaha]
after reverse: [hahaha, zzz, cba, abc, aa]
运行结果
例2:用工具类Collections.sort()进行排序:
public static void demo_2() {
List<String> list = new ArrayList<String>();
list.add("abcde");
list.add("cba");
list.add("aa");
list.add("zzz");
list.add("cba");
list.add("nbaa");
System.out.println(list);
Collections.sort(list);
System.out.println("after sort:\n" + list);
Collections.sort(list, Collections.reverseOrder());
System.out.println("after reverse sort:\n" + list);
int index = Collections.binarySearch(list, "cba");
System.out.println("index=" + index);
// 获取最大值。
String max = Collections.max(list, new ComparatorByLength());
System.out.println("maxLength=" + max);
}
public static void main(String[] args) {
demo_2();
}
[abcde, cba, aa, zzz, cba, nbaa]
after sort:
[aa, abcde, cba, cba, nbaa, zzz]
after reverse sort:
[zzz, nbaa, cba, cba, abcde, aa]
index=2
maxLength=abcde
运行结果
例3:给非同步的集合加锁,方法太多就不一一列举了,自己查看API。(掌握,面试会问到)
static
|
synchronizedCollection(Collection<T> c) 返回指定 collection 支持的同步(线程安全的)collection。 |
|
static
|
synchronizedList(List<T> list) 返回指定列表支持的同步(线程安全的)列表。 |
|
static
|
synchronizedMap(Map<K,V> m) 返回由指定映射支持的同步(线程安全的)映射。 |
|
static
|
synchronizedSet(Set<T> s) 返回指定 set 支持的同步(线程安全的)set。 |
简单说一下给集合加锁的思想。
List list = new ArrayList();// 非同步的list。
list=MyCollections.synList(list);// 返回一个同步的list.
class MyCollections{
/**
* 返回一个加锁的List
* */
public static List synList(List list){
return new MyList(list);
}
// 内部类
private class MyList implements List{
private List list;
private static final Object lock = new Object();
MyList(List list){
this.list = list;
}
public boolean add(Object obj){
synchronized(lock)
{
return list.add(obj);
}
}
public boolean remove(Object obj){
synchronized(lock)
{
return list.remove(obj);
}
}
}
}
例4:将集合转成数组,Arrays.asList()方法 (掌握)
应用场景:数组方法有限,需要使用集合中的方法操作数组元素时。
注意1:
数组的长度是固定的,所以对于集合的增删方法(add()和remove())是不能使用的。
Demo:
public static void demo_1() {
String[] arr = { "abc", "haha", "xixi" };
List<String> list = Arrays.asList(arr);
boolean b1 = list.contains("xixi");
System.out.println("list contains:" + b1);
// list.add("hiahia");//引发UnsupportedOperationException
System.out.println(list);
}
list contains:true
[abc, haha, xixi]
注意2:
如果数组中的元素是对象(包装器类型),那么转成集合时,直接将数组中的元素作为集合中的元素进行集合存储。(比如上面那个Demo)
如果数组中的元素是基本数据类型,那么会将该*数组*作为集合中的元素进行存储。(比如下面这个Demo)
Demo:
public static void demo_2() {
/*
* 如果数组中的元素是对象,那么转成集合时,直接将数组中的元素作为集合中的元素进行集合存储。
*
* 如果数组中的元素是基本类型数值,那么会将该数组作为集合中的元素进行存储。
*
*/
int[] arr = { 31, 11, 51, 61 };
List<int[]> list = Arrays.asList(arr);
System.out.println(list);
System.out.println("数组的长度为:" + list.size());
}
[[I@659e0bfd]
数组的长度为:1
由结果可以看出,当数组中的元素时int类型时,集合中存的元素是整个数组,集合的长度为1而不是4。
例5:将数组转成集合,List.toArray()方法
Object[] |
toArray()
Returns an array containing all of the elements in this list in proper sequence (from first to last element).
|
<T> T[] |
toArray(T[] a)
Returns an array containing all of the elements in this list in proper sequence (from first to last element); the runtime type of the returned array is that of the specified array.
|
应用场景:对集合中的元素操作的方法进行限定,不允许对其进行增删时。
注意:toArray方法需要传入一个指定类型的数组,数组的长度如何定义呢?
如果定义的数组长度小于集合的size,那么该方法会创建一个同类型并和集合相同size的数组。
如果定义的数组长度大于集合的size,那么该方法就会使用指定的数组,存储集合中的元素,其他位置默认为null。
所以,一般将数组的长度定义为集合的size。
Demo:
public class ToArray {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("abc1");
list.add("abc2");
list.add("abc3");
String[] arr = list.toArray(new String[list.size()]);
System.out.println(Arrays.toString(arr));
}
}
例6:foreach语句
应用场景:遍历数组或Collection单列集合。
对数组的遍历如果仅仅是获取数组中的元素用foreach可以简化代码,如果要对数组的角标进行操作建议使用传统for循环。
格式:
for(类型 变量 :Collection集合|数组)
{}
Demo:
public class ForEachDemo {
public static void main(String[] args) {
// 遍历数组
int[] arr = { 3, 1, 5, 7, 4 };
for (int i : arr) {
System.out.println(i);
}
//遍历List
List<String> list = new ArrayList<String>();
list.add("abc1");
list.add("abc2");
list.add("abc3");
for (String s : list) {
System.out.println(s);
}
// 遍历map
// 可以使用高级for遍历map集合吗?不能直接用,但是将map转成单列的set,就可以用了。
Map<Integer, String> map = new HashMap<Integer, String>();
map.put(3, "zhagsan");
map.put(1, "wangyi");
map.put(7, "wagnwu");
map.put(4, "zhagsansan");
for (Integer key : map.keySet()) {
String value = map.get(key);
System.out.println(key + "::" + value);
}
for (Map.Entry<Integer, String> me : map.entrySet()) {
Integer key = me.getKey();
String value = me.getValue();
System.out.println(key + ":" + value);
}
// 老式的迭代器写法
Iterator<String> it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
Java集合框架体系详细梳理,含面试知识点。的更多相关文章
- Java集合框架体系JCF
Java 集合框架体系作为Java 中十分重要的一环, 在我们的日常开发中扮演者十分重要的角色, 那么什么是Java集合框架体系呢? 在Java语言中,Java语言的设计者对常用的数据结构和算法做了一 ...
- Java 集合框架体系总览
尽人事,听天命.博主东南大学硕士在读,热爱健身和篮球,乐于分享技术相关的所见所得,关注公众号 @ 飞天小牛肉,第一时间获取文章更新,成长的路上我们一起进步 本文已收录于 「CS-Wiki」Gitee ...
- java集合框架体系
Collection接口: 1.单列集合类的根接口. 2.定义了可用于操作List.Set的方法——增删改查: 3.继承自Iterable<E>接口,该接口中提供了iterator() 方 ...
- Java集合框架之Set接口浅析
Java集合框架之Set接口浅析 一.java.util.Set接口综述: 这里只对Set接口做一简单综述,其具体实现类的分析,朋友们可关注我后续的博文 1.1Set接口简介 java.util.se ...
- Java集合框架使用总结
Java集合框架使用总结 前言:本文是对Java集合框架做了一个概括性的解说,目的是对Java集合框架体系有个总体认识,如果你想学习具体的接口和类的使用方法,请参看JavaAPI文档. 一.概述数据结 ...
- Java集合框架总结—超详细-适合面试
Java集合框架总结—超详细-适合面试 一.精简: A.概念汇总 1.Java的集合类主要由两个接口派生而出:Collection和Map,Collection和Map是Java集合框架的根接口, ...
- Java集合框架梳理(含经典面试题)
Java Collections Framework是Java提供的对集合进行定义,操作,和管理的包含一组接口,类的体系结构. 1. 整体框架 Java容器类库一共有两种主要类型:Collection ...
- 【转】Java集合框架面试问题集锦
Java集合框架(例如基本的数据结构)里包含了最常见的Java常见面试问题.很好地理解集合框架,可以帮助你理解和利用Java的一些高级特性.下面是面试Java核心技术的一些很实用的问题. Q:最常见的 ...
- (未完)Java集合框架梳理(基于JDK1.8)
Java集合类主要由两个接口Collection和Map派生出来的,Collection派生出了三个子接口:List.Set.Queue(Java5新增的队列),因此Java集合大致也可分成List. ...
随机推荐
- 201521123055 《Java程序设计》第13周学习总结
1. 本章学习总结 2. 书面作业 1. 网络基础 1.1 比较ping www.baidu.com与ping cec.jmu.edu.cn,分析返回结果有何不同?为什么会有这样的不同? 1.2 te ...
- php数据库操作小要点
保留小数点后两位 $ba = floor(($v[2]/$sum[0][0])*10000); //取整数 $bb = $ba/100; //两位小数 列的值加一可以直接用自身,不用单独查询出来 $s ...
- apache: eclipse的tomcatPluginV插件下载
Sysdeo Eclipse Tomcat Launcher plugin Plugin features Support and contributions Download Installatio ...
- Ansible系列(二):选项和常用模块
html { font-family: sans-serif } body { margin: 0 } article,aside,details,figcaption,figure,footer,h ...
- .NET Core 使用RabbitMQ
RabbitMQ简介 AMQP,即Advanced Message Queuing Protocol,高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计.消息中间件主要用于组件之间的 ...
- Struts 2.5 Filter mapping specifies an unknown filter name [struts2]
问题一:java.util.concurrent.ExecutionException: org.apache.catalina.LifecycleException: Failed to start ...
- Failed to load the JNI shared library "XXXXXXX"
今天启动Eclipse的时候出现了这个问题,经过查找, 一般来说这种问题都是因为eclipse 和Java 的兼容性不一致所导致的. 1) 查看Eclipse 和Java 版本 那么我们需要分别查看下 ...
- Https系列之一:https的简单介绍及SSL证书的生成
Https系列会在下面几篇文章中分别作介绍: 一:https的简单介绍及SSL证书的生成二:https的SSL证书在服务器端的部署,基于tomcat,spring boot三:让服务器同时支持http ...
- [err] 1055
本人mysql安装在ubuntu16.04上,mysql版本是5.7.19:在创建表和插入数据时报了 [Err] 1055 - Expression #1 of ORDER BY clause is ...
- Spring中的Service/DAO/DTO