boost::pool 库速记
Boost::pool
使用示例
#include <iostream>#include <vector>#include <list>#include <boost/pool/object_pool.hpp>#include <boost/pool/pool_alloc.hpp>#include <boost/timer/timer.hpp>using namespace std;using namespace boost;const int MAXLENGTH = 100000;class A{public:A(){cout << "Construct: " << endl;}A ( int a ){cout << "Construct: " << a << endl;}~A(){cout << "Destruct" << endl;}};function<void ( void ) > pool_sample = [](){cout << "==============================\n";boost::object_pool<A> p;A *ptr = p.construct ( 1 );p.destroy ( ptr );};function<void ( void ) > pool_sample_1 = [](){cout << "==============================\n";boost::object_pool<A> p;A *ptr = p.malloc();cout << "malloc doesn't invoke constructor and destructor.\n";ptr = new ( ptr ) A ( 1 );ptr->~A();p.free ( ptr );};auto test_pool_alloc = [](){cout << "==============================\n";vector<int, pool_allocator<int>> vec1;vector<int> vec2;{cout << "USE pool_allocator:\n";boost::timer::auto_cpu_timer t1;for ( int i = 0; i < MAXLENGTH; ++i ){vec1.push_back ( i );vec1.pop_back();}}{cout << "USE STL allocator:\n";boost::timer::auto_cpu_timer t2;for ( int i = 0; i < MAXLENGTH; ++i ){vec2.push_back ( i );vec2.pop_back();}}};auto test_fast_pool_alloc = [](){cout << "==============================\n";list<int, fast_pool_allocator<int>> vec1;list<int> vec2;{cout << "USE fast_pool_allocator:\n";boost::timer::auto_cpu_timer t1;for ( int i = 0; i < MAXLENGTH; ++i ){vec1.push_back ( i );vec1.pop_back();}}{cout << "USE STL allocator:\n";boost::timer::auto_cpu_timer t2;for ( int i = 0; i < MAXLENGTH; ++i ){vec2.push_back ( i );vec2.pop_back();}}};int main(){pool_sample();pool_sample_1();test_pool_alloc();test_fast_pool_alloc();system ( "pause" );}
boost::pool 的实现原理
pool去按照一定的增长规则,从操作系统申请一大块内存,称为block,源码中用PODptr表示。
这个PODptr结构将block分为三块,第一块是大块数据区,第二块只有sizeof(void*) 个字节,即指针大小,保存下一个PODptr的指针,第三块保存下一PODptr的长度。最后一个PODptr指针为空。
PODptr的数据区被simple_segregated_storage格式化为许多个小块,称为chunk。一个chunk的大小是定义boost::object_pool时决定的,即 sizeof(T)>sizeof(void)?sizeof(T):sizeof(void)。任意一个chunk未被占用时,使用其前sizeof(void*)个字节作为一个指针指向下一个未被占用的chunk。是的,单向链表。而从pool::malloc,就执行单向链表的删除节点操作,每次都返回首个chunk,因此未进行重新申请block前,malloc都是O(1)。
pool::free(ptr)操作就是找到ptr属于哪个PODptr,然后把ptr添加到单向链表头。
pool::ordered_free(ptr)找到ptr属于哪个PODptr,然后通过插入排序把ptr添加到单向链表。
部分源码
/*该函数是simple_segregated_storage的成员函数。第一次看到一下懵逼了,不知其何用意。难道不就是得到 *ptr 的功能吗?!事实是,对于一个void*是不能dereference的。因为*ptr你将得到一个void类型,C++不允许void类型。*/static void * & nextof(void * const ptr){return *(static_cast<void **>(ptr));}
simple_segregated_storage
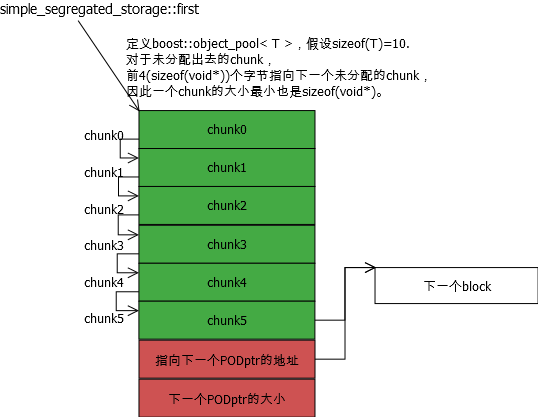
//segregate会把给的一个sz大小的内存块,拆分为每个partition_sz大小的多个chunk单元,//每个chunk的前4字节指向下一个chunk(作为链表的next),而最后一个chunk头指向end。template <typename SizeType>void * simple_segregated_storage<SizeType>::segregate(void * const block,const size_type sz,const size_type partition_sz,void * const end){//找到最后一个chunkchar * old = static_cast<char *>(block)+ ((sz - partition_sz) / partition_sz) * partition_sz;nextof(old) = end;//把最后一个chunk指向endif (old == block)return block;//如果这块内存只有一个chunk就返回//格式化其他的chunk,使每个chunk的前4字节指向下一个chunkfor (char * iter = old - partition_sz; iter != block;old = iter, iter -= partition_sz)nextof(iter) = old;nextof(block) = old;return block;}//添加一个block时,会把这该块分解成chunk,添加到链表的头部。因为无序,所以复杂度O(1)void add_block(void * const block,const size_type nsz, const size_type npartition_sz){first = segregate(block, nsz, npartition_sz, first);}//通过find_prev找到这个内存块对应的位置,然后添加进去。复杂度O(n)void add_ordered_block(void * const block,const size_type nsz, const size_type npartition_sz){void * const loc = find_prev(block);if (loc == 0)add_block(block, nsz, npartition_sz);elsenextof(loc) = segregate(block, nsz, npartition_sz, nextof(loc));}//这个没什么好说的,通过比较地址,找到ptr在当前block中的位置,类似插入排序。template <typename SizeType>void * simple_segregated_storage<SizeType>::find_prev(void * const ptr){if (first == 0 || std::greater<void *>()(first, ptr))return 0;void * iter = first;while (true){if (nextof(iter) == 0 || std::greater<void *>()(nextof(iter), ptr))return iter;iter = nextof(iter);}}//simple_segregated_storage成员变量。 链表头指针。void * first;
下段代码从simple_segregated_storage链表中获取内存:
template <typename SizeType>void * simple_segregated_storage<SizeType>::malloc_n(const size_type n,const size_type partition_size){if(n == 0)return 0;void * start = &first;void * iter;do{if (nextof(start) == 0)return 0;//try_malloc_n会从start开始(不算start)向后申请n个partition_size大小的chunk,返回最后一个chunk的指针iter = try_malloc_n(start, n, partition_size);} while (iter == 0);//此处返回内存chunk头void * const ret = nextof(start);//此处是经典的单向链表移除其中一个节点的操作。把该内存的前面chunk头指向该内存尾部chunk头指向的内存。即把该部分排除出链表。nextof(start) = nextof(iter);return ret;}//start会指向满足条件(连续的n个partition_size大小的chunk内存)的chunk头部,返回最后一个chunk指针。template <typename SizeType>void * simple_segregated_storage<SizeType>::try_malloc_n(void * & start, size_type n, const size_type partition_size){void * iter = nextof(start);//start后面的块是否是连续的n块partition_size大小的内存while (--n != 0){void * next = nextof(iter);//如果next != static_cast<char *>(iter) + partition_size,说明下一块chunk被占用或是到了大块内存(block)的尾部。if (next != static_cast<char *>(iter) + partition_size){// next == 0 (end-of-list) or non-contiguous chunk foundstart = iter;return 0;}iter = next;}return iter;}
class PODptr
.png)
如上图,类PODptr指示了一个block结构,这个block大小不一定相同,但都由 chunk data+ next ptr + next block size三部分组成。
- chunk data部分被构造成一个simple_segregated_storage,切分为多个chunk,是一块连续的内存
- next ptr 指向下一个block结构,next block size指出了下一个block结构的大小。
- 也就是说,多个PODptr结构组成一个链表,而PODptr内部由simple_segregated_storage分成一个顺序表。
- PODptr的大小不固定,增长方式见
void * pool<UserAllocator>::malloc_need_resize(). - 初始化的每个chunk都指向下一个chunk
class pool
//pool 从simple_segregated_storage派生template <typename UserAllocator>class pool: protected simple_segregated_storage < typename UserAllocator::size_type >;//返回父类指针以便调用父类函数,其实就是类型转换simple_segregated_storage<size_type> & store(){ //! \returns pointer to store.return *this;}
在调用pool::malloc只申请一个chunk时,如果有足够空间,使用父类指针调用malloc返回内存,否则就重新申请一个大block。代码简单,就不贴了。
下面代码是申请n个连续的chunk。如果没有连续的n个内存就需要重新分配内存了。分配好的内存,通过add_ordered_block添加到chunks的有序链表,并通过地址大小把刚申请的block放到PODptr链表的排序位置。
template <typename UserAllocator>void * pool<UserAllocator>::ordered_malloc(const size_type n){ //! Gets address of a chunk n, allocating new memory if not already available.//! \returns Address of chunk n if allocated ok.//! \returns 0 if not enough memory for n chunks.const size_type partition_size = alloc_size();const size_type total_req_size = n * requested_size;const size_type num_chunks = total_req_size / partition_size +((total_req_size % partition_size) ? true : false);void * ret = store().malloc_n(num_chunks, partition_size);#ifdef BOOST_POOL_INSTRUMENTstd::cout << "Allocating " << n << " chunks from pool of size " << partition_size << std::endl;#endifif ((ret != 0) || (n == 0))return ret;#ifdef BOOST_POOL_INSTRUMENTstd::cout << "Cache miss, allocating another chunk...\n";#endif// Not enough memory in our storages; make a new storage,BOOST_USING_STD_MAX();//计算下次申请内存的大小,基本就是乘以2.integer::static_lcm是求最小公倍数。next_size = max BOOST_PREVENT_MACRO_SUBSTITUTION(next_size, num_chunks);size_type POD_size = static_cast<size_type>(next_size * partition_size +integer::static_lcm<sizeof(size_type), sizeof(void *)>::value + sizeof(size_type));char * ptr = (UserAllocator::malloc)(POD_size);if (ptr == 0){if(num_chunks < next_size){// Try again with just enough memory to do the job, or at least whatever we// allocated last time:next_size >>= 1;next_size = max BOOST_PREVENT_MACRO_SUBSTITUTION(next_size, num_chunks);POD_size = static_cast<size_type>(next_size * partition_size +integer::static_lcm<sizeof(size_type), sizeof(void *)>::value + sizeof(size_type));ptr = (UserAllocator::malloc)(POD_size);}if(ptr == 0)return 0;}const details::PODptr<size_type> node(ptr, POD_size);// Split up block so we can use what wasn't requested.if (next_size > num_chunks)store().add_ordered_block(node.begin() + num_chunks * partition_size,node.element_size() - num_chunks * partition_size, partition_size);BOOST_USING_STD_MIN();if(!max_size)next_size <<= 1;else if( next_size*partition_size/requested_size < max_size)next_size = min BOOST_PREVENT_MACRO_SUBSTITUTION(next_size << 1, max_size*requested_size/ partition_size);// insert it into the list,// handle border case.//对大块block进行排序if (!list.valid() || std::greater<void *>()(list.begin(), node.begin())){node.next(list);list = node;}else{details::PODptr<size_type> prev = list;while (true){// if we're about to hit the end, or if we've found where "node" goes.if (prev.next_ptr() == 0|| std::greater<void *>()(prev.next_ptr(), node.begin()))break;prev = prev.next();}node.next(prev.next());prev.next(node);}// and return it.return node.begin();}
下面代码是释放未被占用的块。(一个block任何一个chunk被占用就不会释放)
template <typename UserAllocator>bool pool<UserAllocator>::release_memory(){ //! pool must be ordered. Frees every memory block that doesn't have any allocated chunks.//! \returns true if at least one memory block was freed.// ret is the return value: it will be set to true when we actually call// UserAllocator::free(..)bool ret = false;// This is a current & previous iterator pair over the memory block listdetails::PODptr<size_type> ptr = list;details::PODptr<size_type> prev;// This is a current & previous iterator pair over the free memory chunk list// Note that "prev_free" in this case does NOT point to the previous memory// chunk in the free list, but rather the last free memory chunk before the// current block.void * free_p = this->first;void * prev_free_p = 0;const size_type partition_size = alloc_size();// Search through all the all the allocated memory blockswhile (ptr.valid()){// At this point:// ptr points to a valid memory block// free_p points to either:// 0 if there are no more free chunks// the first free chunk in this or some next memory block// prev_free_p points to either:// the last free chunk in some previous memory block// 0 if there is no such free chunk// prev is either:// the PODptr whose next() is ptr// !valid() if there is no such PODptr// If there are no more free memory chunks, then every remaining// block is allocated out to its fullest capacity, and we can't// release any more memoryif (free_p == 0)break;// We have to check all the chunks. If they are *all* free (i.e., present// in the free list), then we can free the block.bool all_chunks_free = true;// Iterate 'i' through all chunks in the memory block// if free starts in the memory block, be careful to keep it therevoid * saved_free = free_p;for (char * i = ptr.begin(); i != ptr.end(); i += partition_size){// If this chunk is not freeif (i != free_p){// We won't be able to free this blockall_chunks_free = false;// free_p might have travelled outside ptrfree_p = saved_free;// Abort searching the chunks; we won't be able to free this// block because a chunk is not free.break;}// We do not increment prev_free_p because we are in the same blockfree_p = nextof(free_p);}// post: if the memory block has any chunks, free_p points to one of them// otherwise, our assertions above are still validconst details::PODptr<size_type> next = ptr.next();if (!all_chunks_free){if (is_from(free_p, ptr.begin(), ptr.element_size())){std::less<void *> lt;void * const end = ptr.end();do{prev_free_p = free_p;free_p = nextof(free_p);} while (free_p && lt(free_p, end));}// This invariant is now restored:// free_p points to the first free chunk in some next memory block, or// 0 if there is no such chunk.// prev_free_p points to the last free chunk in this memory block.// We are just about to advance ptr. Maintain the invariant:// prev is the PODptr whose next() is ptr, or !valid()// if there is no such PODptrprev = ptr;}else{// All chunks from this block are free// Remove block from listif (prev.valid())prev.next(next);elselist = next;// Remove all entries in the free list from this block//关键点在这里,释放了一个block之后,会把上一个chunk头修改。if (prev_free_p != 0)nextof(prev_free_p) = free_p;elsethis->first = free_p;// And release memory(UserAllocator::free)(ptr.begin());ret = true;}// Increment ptrptr = next;}next_size = start_size;return ret;}
pool总结
pool的实现基本就是利用simple_segregated_storage内部实现的维护chunk的链表来实现内存管理的。simple_segregated_storage可以说是pool的核心。pool内部一共维护了两个链表:
- simple_segregated_storage内部的chunk链表。分配单个chunk时,直接从这个链表拿一个chunk,复杂度O(1)。
- pool内部有个成员变量
details::PODptr<size_type> list;用来维护一个大块内存block的链表。可以知道,一个block内部是连续的,但block之间可以认为是不连续的内存。这个链表相当于一个内存地址索引,主要是为了提高查找效率:对于有序排列的内存池,归还内存时,用来快速判断是属于哪个块的。如果没有这个链表,就需要挨个chunk去判断地址大小。
class object_pool
class object_pool: protected pool<UserAllocator>;
object_pool继承自pool,但和pool的区别是,pool用于申请固定大小的内存,而object_pool用于申请固定类型的内存,并会调用构造函数和析构函数。主要的函数就两个:
调用构造函数,用到了一个placement new的方式,老生常谈。
唯一需要注意的是construct和destroy调用的malloc和free,都是调用的 ordered_malloc 和 ordered_free。
elem``ent_type * construct(Arg1&, ... ArgN&){...}element_type * construct(){element_type * const ret = (malloc)();if (ret == 0)return ret;try { new (ret) element_type(); }catch (...) { (free)(ret); throw; }return ret;}element_type * malloc BOOST_PREVENT_MACRO_SUBSTITUTION(){return static_cast<element_type *>(store().ordered_malloc());}
destroy显式调用析构函数去析构,然后把内存还给链表维护。
void destroy(element_type * const chunk){chunk->~T();(free)(chunk);}void free BOOST_PREVENT_MACRO_SUBSTITUTION(element_type * const chunk){store().ordered_free(chunk);}
class singleton_pool
单例内存池的实现,值得注意的有如下几点:
- 单线程使用单例时(保证无同步问题),可以通过定义宏BOOST_POOL_NO_MT来取消同步的损耗。
#if !defined(BOOST_HAS_THREADS) || defined(BOOST_NO_MT) || defined(BOOST_POOL_NO_MT)typedef null_mutex default_mutex;
- 单例内存池的单例实现如下,通过内部类object_creator调用private函数get_pool(),通过create_object.do_nothing();来保证在main之前实例化静态对象
static object_creator create_object;
class singleton_pool{public:...private:typedef boost::aligned_storage<sizeof(pool_type), boost::alignment_of<pool_type>::value> storage_type;static storage_type storage;static pool_type& get_pool(){static bool f = false;if(!f){// This code *must* be called before main() starts,// and when only one thread is executing.f = true;new (&storage) pool_type;}// The following line does nothing else than force the instantiation// of singleton<T>::create_object, whose constructor is// called before main() begins.create_object.do_nothing();return *static_cast<pool_type*>(static_cast<void*>(&storage));}struct object_creator{object_creator(){ // This constructor does nothing more than ensure that instance()// is called before main() begins, thus creating the static// T object before multithreading race issues can come up.singleton_pool<Tag, RequestedSize, UserAllocator, Mutex, NextSize, MaxSize>::get_pool();}inline void do_nothing() const{}};static object_creator create_object;};
总结
- 适用范围:频繁申请释放相同大小的内存,如需要频繁的创建同一个类的对象。
- 优点:可以防止内存碎片、极快,避免频繁申请内存的调用.
boost::pool 的源代码一共就几个文件,简洁明了,读起来也不很难。由于代码时间远早于现代C++(C++11之后)成型,兼容编译器的代码建议忽略。因为重要的是其设计思想:如何通过自构两个链表来提升内存管理效率的。
数据结构很简单。适用场景比较狭窄,跟GC没法比。
boost::pool 库速记的更多相关文章
- 定长内存池之BOOST::pool
内存池可有效降低动态申请内存的次数,减少与内核态的交互,提升系统性能,减少内存碎片,增加内存空间使用率,避免内存泄漏的可能性,这么多的优点,没有理由不在系统中使用该技术. 内存池分类: 1. ...
- boost pool 和 object_pool
内存池(Memory Pool)是一种内存分配方式. 通常我们习惯直接使用new.malloc等API申请分配内存,这样做的缺点在于:由于所申请内存块的大小不定,当频繁使用时会造成大量的 ...
- 如何在WINDOWS下编译BOOST C++库 .
如何在WINDOWS下编译BOOST C++库 cheungmine 2008-6-25 写出来,怕自己以后忘记了,也为初学者参考.使用VC8.0和boost1.35.0. 1)下载boost ...
- Windows下如何使用BOOST C++库 .
Windows下如何使用BOOST C++库 我采用的是VC8.0和boost_1_35_0.自己重新编译boost当然可以,但是我使用了 http://www.boostpro.com/produc ...
- boost::pool与内存池技术
建议看这个链接的内容:http://cpp.winxgui.com/cn:mempool-example-boost-pool Pool分配是一种分配内存方法,用于快速分配同样大小的内存块, ...
- Boost线程库学习笔记
一.创建一个线程 创建线程 boost::thread myThread(threadFun); 需要注意的是:参数可以是函数对象或者函数指针.并且这个函数无参数,并返回void类型. 当一个thre ...
- Boost正则表达式库regex常用search和match示例 - 编程语言 - 开发者第2241727个问答
Boost正则表达式库regex常用search和match示例 - 编程语言 - 开发者第2241727个问答 Boost正则表达式库regex常用search和match示例 发表回复 Boo ...
- Boost::thread库的使用
阅读对象 本文假设读者有几下Skills [1]在C++中至少使用过一种多线程开发库,有Mutex和Lock的概念. [2]熟悉C++开发,在开发工具中,能够编译.设置boost::thread库. ...
- 一起学习Boost标准库--Boost.StringAlgorithms库
概述 在未使用Boost库时,使用STL的std::string处理一些字符串时,总是不顺手,特别是当用了C#/Python等语言后trim/split总要封装一个方法来处理.如果没有形成自己的com ...
随机推荐
- opencv+python3.4的人脸识别----2017-7-19
opencv3.1 + python3.4 第一回合(抄代码,可实现):人脸识别涉及一个级联表,目前能力还无法理解. 流程:1.读取图像---2.转换为灰度图---3.创建级联表---4.对灰度图 ...
- 【JQUERY】插件的写法
1. jquery插件怎么写 $.extend $.fn 2. 写的时候注意些什么
- AC自动机总结及板子(不带指针)
蒟蒻最近想学个AC自动机简直被网上的板子搞疯了,随便点开一个都是带指针的,然而平时用到指针的时候并不多,看到这些代码也完全是看不懂的状态.只好在大概理解后自己脑补(yy)了一下AC自动机的代码,居然还 ...
- MySQL优化 - 所需了解的基础知识
时隔一年半,期间一直想写但却觉得没有实质性的内容可记录,本文为 [高性能MySQL] 的学习日志整理分享(感兴趣建议读原书). 优化应贯穿整个产品开发周期中,开发过程中考虑一些性能问题与影响,总比出问 ...
- 设计模式(二) 策略模式Strategy
策略模式是对算法的包装,是把使用算法的责任和算法本身分割开来,委派给不同的对象管理,我个人的理解是,具有相同行为不同的行为模式,比如走路,有人速度3m/s,有人100m/s,把他们的具体行走和对象本身 ...
- 认真地搞OI
新博客的开头 OI生涯的开始 #include<cstdio> int main() { puts("Hello world!"); ; }
- RabbitMQ入门-Topic模式
上篇<RabbitMQ入门-Routing直连模式>我们介绍了可以定向发送消息,并可以根据自定义规则派发消息.看起来,这个Routing模式已经算灵活的了,但是,这还不够,我们还有更加多样 ...
- Git时光机穿梭之版本回退
现在,你已经学会了修改文件,然后把修改提交到Git版本库,现在,再练习一次,修改readme.txt文件如下: Git is a distributed version control system. ...
- HTTP请求中的Form Data与Request Payload的区别
前端开发中经常会用到AJAX发送异步请求,对于POST类型的请求会附带请求数据.而常用的两种传参方式为:Form Data 和 Request Payload. GET请求 使用get请求时,参数会以 ...
- Vue过渡效果之CSS过渡
前面的话 Vue 在插入.更新或者移除 DOM 时,提供多种不同方式的应用过渡效果.本文将从CSS过渡transition.CSS动画animation及配合使用第三方CSS动画库(如animate. ...