bam文件softclip , hardclip ,markduplicate的探究
测序产生的bam文件,有一些reads在cigar值里显示存在softclip,有一些存在hardclip,究竟softclip和hardclip是怎么判断出来的,还有是怎么标记duplicate的reads的,我怀着这些问题进行了探究。
测试步骤
- 编辑两个bed文件,分别含有我们需要的read1和read2位置,这里每个文件包含两条read1或者两条read2,read1、read2一对作为原始的reads(序列名primer_pri),另一对作为截取的材料(这里取序列名为other)
- 使用bedtools getfasta,从参考基因组获得reads的序列,将read2反向互补。将原始reads放入两个文件,一个test_R1.fa,一个test_R2.fa
在test_R1.fa中添加其它修改过的原始reads,并在test_R2.fa中也添加相应的read2,不过read2不修改
read1名称如下

- primer_pri:原始read
- pimer_duplicate1:primer_pri的重复,一模一样
- pimer_duplicate2:read1 primer_pri去掉5‘两个碱基
- pimer_duplicate3:read1 primer_pri去掉5’两个碱基,再去掉3'两个碱基
- pimer_changeR2Termi5base:read1修改了read2 5‘端的碱基
- primer_halfother:read1截掉后面reads,用other的5‘部分reads补全
- pimer_change3Termi5base_change5Termi5base_sametwo:read1和read2一样,并且5'端和3‘端都改变了5个碱基
pimer_change3Termi5base_change5Termi5base:read1 5'端和3‘端都改变了5个碱基,但是read2保留primer_pri的read2
结果
softclip和hardclip
其中
- primer_halfother read1 82M65S,有SA tag,SA:Z:chr12,5378700,+,79S68M,60,0
- pimer_change3Termi5base_change5Termi5base_sametwo 两条reads均为5S137M5S
- pimer_change3Termi5base_change5Termi5base read1 5S137M5S
- primer_halfother read1 79H68M ,有SA tag,SA:Z:chr12,5378502,+,82M65S,60,0
结论(部分分析参考SAMv1.pdf文件)
- 对于map到一个位置的read,两端map不上的叫做clip ,map到一个位置的情况下以softclip显示(比如 pimer_change3Termi5base_change5Termi5base_sametwo和 pimer_change3Termi5base_change5Termi5base read1)
- 对于嵌合比对的read(可以map到多个区域,并且这比对上的区域很大部分非overlap),比如primer_halfother read1比对上两个位置,一个比对到chr12 : 5378502,一个比对到chr12:5378700,并且两次hit的位置的碱基overlap少,产生的这种情况是因为read前一部分比对到了前者,而后一部分又可以比对到了后者,因此无论比对到任何一个位置都这条read都是部分match(这种叫做Chimeric alignment/嵌合比对)。
- 嵌合比对的read,有一条是最优的read,因为我们map的时候设置了-M参数,因此认为较短的split的reads断定为优,这里是的62 clip 的hit断定为优。因此65个比对不上的显示为softclip,而另外一个hit,79 clip显示为hard clip,序列中不显示,并且存入0x800(supplementary alignment flag)
- 为什么82M65S对应的是79H68M呢,理论上应该是82H65M才对,这是因为这里两个比对有三个碱基的overlap,所以前面有65+3个match,后面有79+3个match(制造reads的时候碰巧截取的primer read 3'端三个碱基和截取的other read 5‘部分read 三个碱基一样)
- 这种嵌合比对的reads含有SA tag
duplicate
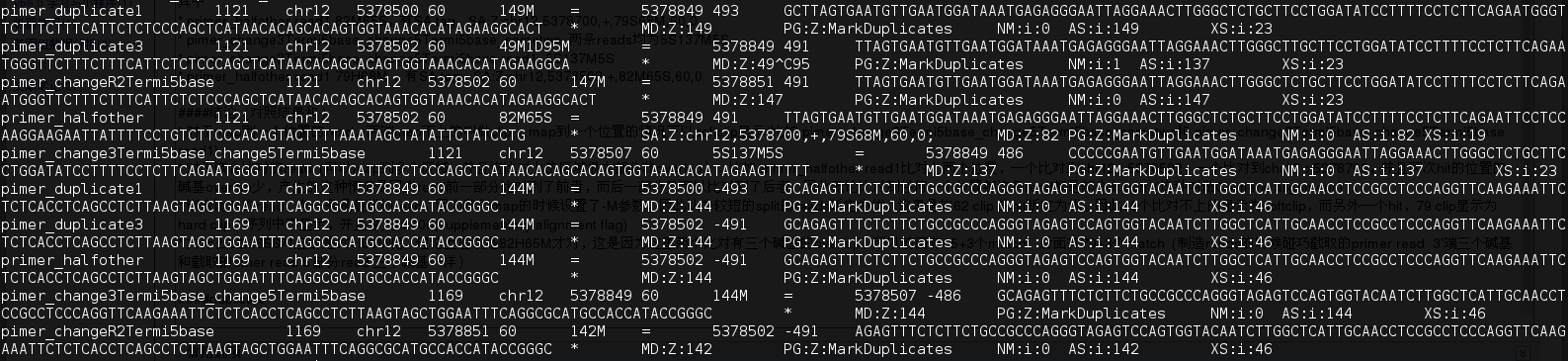
其中mark为duplicate 的reads 对(duplicate 是按fragment算) 有 primer duplicate1,primer_duplicate3,pimer_changeR2Termi5base,primer_halfother(82M65S,144M(未改的read2)),pimer_change3Termi5base_change5Termi5base

不属于duplicate的有
primer_pri,pimer_duplicate2,primer_halfother(79H68M,一条),pimer_change3Termi5basechange5Termi5base_sametwo
结论
- fragment的start和end一样(read1和read2(因为read2是测对链的,reads的5‘端都是fragment的末端)的5’的位置都相同)判断为duplicate,只取最优的不标记为duplicate
- primer_pri的duplicate是 primer duplicate1, primer_halfother
- pimer_duplicate2的duplicate是primer_duplicate3,pimer_changeR2Termi5base,pimer_change3Termi5base_change5Termi5base
- 没有duplicate的是primer_halfother(79H68M,一条),pimer_change3Termi5basechange5Termi5base_sametwo
- pimer_change3Termi5basechange5Termi5base_sametwo 5'有5 softclip,map的位置从M的碱基算起(见图),所以它没有duplicate
bam文件softclip , hardclip ,markduplicate的探究的更多相关文章
- SAMTOOLS使用 SAM BAM文件处理
[怪毛匠子 整理] samtools学习及使用范例,以及官方文档详解 #第一步:把sam文件转换成bam文件,我们得到map.bam文件 system"samtools view -bS m ...
- SAM/BAM文件处理
当测序得到的fastq文件map到基因组之后,我们通常会得到一个sam或者bam为扩展名的文件.SAM的全称是sequence alignment/map format.而BAM就是SAM的二进制文件 ...
- C++使用htslib库读入和写出bam文件
有时候我们需要使用C++处理bam文件,比如取出read1或者read2等符合特定条件的序列,根据cigar值对序列指定位置的碱基进行统计或者对序列进行处理并输出等,这时我们可以使用htslib库 ...
- Vivado约束文件(XDC)的探究(2)
Vivado约束文件(XDC)的探究(2)
- Vivado约束文件(XDC)的探究(1)
Vivado约束文件(XDC)的探究(1) 工程建好之后会出现xdc文件: 注意:active 和 target 生成的约束文件如下:
- bam文件测序深度统计-bamdst
最近接触的数据都是靶向测序,或者全外测序的数据.对数据的覆盖深度及靶向捕获效率的评估成为了数据质量监控中必不可少的一环. 以前都是用samtools depth 算出单碱基的深度后,用perl来进行深 ...
- 文件格式——Sam&bam文件
Sam&bam文件 SAM是一种序列比对格式标准, 由sanger制定,是以TAB为分割符的文本格式.主要应用于测序序列mapping到基因组上的结果表示,当然也可以表示任意的多重比对结果.当 ...
- Pysam 处理bam文件
Pysam可用来处理bam文件 安装: 用 pip 或者 conda即可 使用: Pysam的函数有很多,主要的读取函数有: AlignmentFile:读取BAM/CRAM/SAM文件 Varian ...
- 推荐一个SAM文件或者bam文件中flag含义解释工具
SAM是Sequence Alignment/Map 的缩写.像bwa等软件序列比对结果都会输出这样的文件.samtools网站上有专门的文档介绍SAM文件.具体地址:http://samtools. ...
随机推荐
- (转)mq经验总结-转
场景:学习mq相关的知识,发现这是一篇总结性很强的文章,转过来学习学习! 1 mq经验总结 首先了解什么是mq?mq的作用是什么? mq是通讯中间件.他的作用是省去开发人员开发通讯工具的时间,节省开发 ...
- 线上故障排查——drools规则引擎使用不当导致oom
事件回溯 1.7月26日上午11:34,告警邮件提示:tomcat内存使用率连续多次超过90%: 2.开发人员介入排查问题,11:40定位到存在oom问题,申请运维拉取线上tomcat 内存快照dum ...
- 抓取60000+QQ空间说说做一次数据分析
对于QQ空间的数据一直来是垂涎不已,老早就想偷过来研究研究,这几天闲下来便开始动手... 整个程序的流程为:登录-->获取cookie-->获取所有的好友qq_number-->根据 ...
- 定时任务FluentScheduler 学习笔记 .net
第一步添加引用 GitHub源码地址 与详细用法 https://github.com/fluentscheduler/FluentScheduler 下面开始简单的实现 /// <summar ...
- hexo博客MathJax公式渲染问题
这个问题自己很早以前便碰到了,用MathJax语法写的一些公式,在本地Markdown编译器上渲染是没问题的,可是部署到hexo博客中就出现问题了,之前我是使用图片代替公式应付过去了,今天从网上找了一 ...
- 红帽 Red Hat Linux相关产品iso镜像下载【百度云】(转载)
不为什么,就为了方便搜索,特把红帽EL 5.EL6.EL7 的各版本整理一下,共享出来.正式发布 6.9 :RedHat Enterprise Server 6.9 for x86_64:rhel-s ...
- HAproxy部署配置
HAproxy部署配置 拓扑图 说明: haproxy服务器IP:172.16.253.200/16 (外网).192.168.29.140/24(内网) 博客服务器组IP:192.168.29.13 ...
- Typescript 解构 、展开
什么是解构.展开? 展开与解构作用相反,简单来说: 解构:解构赋值允许你使用数组或对象字面量的语法,将数组和对象的属性付给各种变量. 展开:允许你讲一个数组展开为另一个数组,或一个对象展开为另一个对象 ...
- Spring整合CXF webservice restful 实例
webservice restful接口跟soap协议的接口实现大同小异,只是在提供服务的类/接口的注解上存在差异,具体看下面的代码,然后自己对比下就可以了. 用到的基础类 User.java @Xm ...
- linux 自动备份数据库
首先在你的项目合适的地方建立一个执行备份数据库的脚本 下面我建立一个叫 mysqlBackups.sh 的脚本内人如下: #!/bin/sh # Database info DB_NAME=" ...