MapReduce框架Hadoop应用(一)
Google对其的定义:MapReduce是一种变成模型,用于大规模数据集(以T为级别的数据)的并行运算。用户定义一个map函数来处理一批Key-Value对以生成另一批中间的Key-Value对,再定义一个reduce函数将所有这些中间的有相同Key的value合并起来。“Map”(映射)和“Reduce”(简化)的概念和它们的主要思想都是从函数式编程语言借用而来的,还有从矢量编程语言借来的特性。在实现过程中,需指定一个map函数,用来把一组键值对映射成一组新的键值对,再指定并发的reduce函数,用来保证所有映射的每一个键值对共享相同的键组。在函数式编程中认为,应当保持数据不可变性,避免再多个进程或线程间共享数据,这就意味着,map函数虽然很简单,却可以通过两个或多个线程再同一个列表上同时执行,由于列表本身并没有改变,线程之间互不影响。
MapReduce模型:
Hadoop MapReduce模型主要有Mapper和Reducer两个抽象类。Mapper主要负责对数据的分析处理,最终转化为Key-Value的数据结构;Reducer主要负责获取Mapper出来的结果,对结果进行进一步统计。Hadoop MapReduce 实现存储的均衡,但为实现计算的均衡,这是其天生的缺陷,因此,通常采用规避的办法来解决此问题,由程序员来保证。


MapReduce框架构成:

(注:TaskTracker都运行在HDFS的DataNode上)
1、JobClient
用户编写的MapReduce程序通过JobClient提交到JobTracker端 ;同时,用户可通过Client提供的一些接口查看作业运行状态。在Hadoop内部用“作业” (Job)表示MapReduce程序。一个 MapReduce程序可对应若干个作业,而每个作业会被分解成若干个Map/Reduce任务(Task)。每一个Job都会在用户端通过JobClient类将应用程序以及配置参数Configuration打包成JAR文件存储在HDFS里,并把路径提交到JobTracker的master服务,然后由master创建每一个Task(即MapTask和ReduceTask)并将它们分发到各个TaskTracker服务中去执行。
2、Mapper和Reducer
运行在Hadoop上的MapReduce程序最基本的组成部分包括:一个Mapper和一个Reducer以及创建的JobConf执行程序,其实还可以包括Combiner,Combiner实际上也是Reducer的实现。
3、JobTracker
JobTracker是一个master服务, 主要负责接受Job,并负责资源监控和作业调度。JobTracker 监控所有 TaskTracker 与作业Job的健康状况,一旦发现失败情况后,其会将相应的任务转移到其他节点;同时,JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。一般情况应该把JobTracker部署在单独的机器上。
4、TaskTracker
TaskTracker是运行在多个节点上的slaver服务,会周期性地通过Heartbeat将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker发送过来的命令并执行相应的操作(如启动新任务、杀死 任务等),即接受作业并负责直接执行每一个任务。
5、JobInprogress
JobClient提交Job后,JobTracker会创建一个JobInProgress来跟踪和调度这个Job,并把它添加到Job队列里。JobInProgress会根据提交的任务JAR中定义的数据集来创建对应的一批TaskInProgress用于监控和调度MapTask,同事创建指定数目的TaskInProgress用于监控和调度ReduceTask。
6、TaskInProgress
JobTracker启动任务时通过每一个TaskInProgress来运行Task,这时会把Task对象(即MapTask和ReduceTask)序列化写入相应的TaskTracker服务中,TaskTracker收到后会创建对应的TaskInProgress用于监控和调度该Task。启动具体的Task进程需要通过TaskInProgress管理,通过TaskRunner对象来运行。TaskRunner会自动装载任务JAR文件并设置好环境变量后,启动一个独立的子进程来执行Task,即MapTask或ReduceTask,但它们不一定在同一个TaskTracker上运行。
7、MapTask和ReduceTask
一个完整的Job会自动一次执行Mapper、Combiner(在JonConf指定Combiner时执行)和Reducer。其中,Mapper和Combiner是由MapTask调用执行的,Reducer是由ReduceTask调用执行,Combiner实际上也是Reducer接口类实现的。Mapper会根据Job JAR中定义的输入数据集按<k1,v1>对读入,处理完成生成临时的<k2,v2>对,如果定义了Combiner,MapTask会在Mapper完成调用,该Combiner将相同Key的值做一定的合并处理,以减少输出结果集。MapTask的任务完成即交给ReduceTask进程调用Reducer处理,生成最终结果<k3,v3>对。下面来看无Combiner的简单处理:
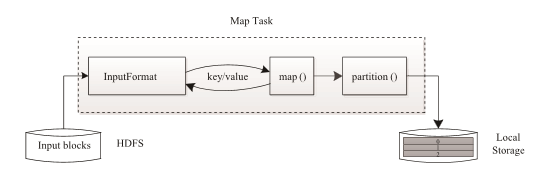
Map Task 执行过程如下图所示。由该图可知,Map Task 先将对应的split (MapReduce处理单元)迭代解析成一 个个 key/value 对,依次调用用户自定义的map() 函数进行处理,最终将临时结果存放到本地磁盘上,其中临时数据被分成若干个partition(分片),每个partition 将被一个Reduce Task处理。
Reduce Task 执行过程如下图所示。该过程分为三个阶段:
①从远程节点上读取Map Task 中间结果(称为“Shuffle阶段”);
②按照key对key/value 对进行排序(称为“Sort阶段”);
③依次读取 <key, value list>,调用用户自定义的 reduce() 函数处理,并将最终结果存到HDFS上(称为“Reduce 阶段”)。

(注:本文参考:Hadoop应用开发技术详解)
MapReduce框架Hadoop应用(一)的更多相关文章
- Hadoop 之 MapReduce 框架演变详解
经典版的MapReduce 所谓的经典版本的MapReduce框架,也是Hadoop第一版成熟的商用框架,简单易用是它的特点,来看一幅图架构图: 上面的这幅图我们暂且可以称谓Hadoop的V1.0版本 ...
- hadoop 学习笔记:mapreduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop学习笔记:MapReduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- 更快、更强——解析Hadoop新一代MapReduce框架Yarn(CSDN)
摘要:本文介绍了Hadoop 自0.23.0版本后新的MapReduce框架(Yarn)原理.优势.运作机制和配置方法等:着重介绍新的Yarn框架相对于原框架的差异及改进. 编者按:对于业界的大数据存 ...
- Hadoop 新 MapReduce 框架 Yarn 详解
Hadoop 新 MapReduce 框架 Yarn 详解: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ Ap ...
- 【Big Data - Hadoop - MapReduce】hadoop 学习笔记:MapReduce框架详解
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop 新 MapReduce 框架 Yarn 详解【转】
[转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/] 简介: 本文介绍了 Hadoop 自 0.23.0 版本 ...
- Hadoop mapreduce框架简介
传统hadoop MapReduce架构(老架构) 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 1.首先用户程序 (JobClient) 提交了一个 job,job ...
- 下一代Apache Hadoop MapReduce框架的架构
背景 随着集群规模和负载增加,MapReduce JobTracker在内存消耗,线程模型和扩展性/可靠性/性能方面暴露出了缺点,为此需要对它进行大整修. 需求 当我们对Hadoop MapReduc ...
随机推荐
- 【知识整理】这可能是最好的RxJava 2.x 入门教程(二)
这可能是最好的RxJava 2.x入门教程系列专栏 文章链接: 这可能是最好的RxJava 2.x 入门教程(一) GitHub 代码同步更新:https://github.com/nanchen22 ...
- [leetcode-557-Reverse Words in a String III]
Given a string, you need to reverse the order of characters in each word within a sentence whilestil ...
- 5.VBS的一些约定,提高可读性
1.变量命名约定 2.变量作用域 1)过程级,在事件中,函数或者子过程中 2)Script级,在head部分 原则,定义尽量小的作用域 3.在某个过程开头应该包括这些注释
- Maven pom.xml配置详解
POM的全称是“ProjectObjectModel(项目对象模型)”. 声明规范 <projectxmlns="http://maven.apache.org/POM/4.0.0&q ...
- Django开发的基于markdown的博客开源
PiperMarkdown Blog for Django1.11,Python 3.6,based on Markdown,网址,希望大家能给个star,谢谢! 什么是PiperMarkdown 这 ...
- Egret index.html设置
<!DOCTYPE HTML> <html> <head> <meta charset="utf-8"> <title> ...
- ArrayList源码浅析(jdk1.8)
ArrayList的实质就是动态数组.所以可以通过下标准确的找到目标元素,因此查找的效率高.但是添加或删除元素会涉及到大量元素的位置移动,所以效率低. 一.构造方法 ArrayList提供了3个构造方 ...
- Oracle批量查询、删除、更新使用BULK COLLECT提高效率
BULK COLLECT(成批聚合类型)和数组集合type类型is table of 表%rowtype index by binary_integer用法笔记 例1: 批量查询项目资金账户号为 &q ...
- ASP.NET Core之跨平台的实时性能监控
前言 前面我们聊了一下一个应用程序 应该监控的8个关键位置. . 嗯..地址如下: 应用程序的8个关键性能指标以及测量方法 最后卖了个小关子,是关于如何监控ASP.NET Core的. 今天我们就来讲 ...
- PHP基础知识1
Php的变量和基本语法 1.变量/常量 2.Php数据类型和基本语法 基本语法 1. html和php混编 2. 一个语句以:(分号)结束 3. 如何定义一个变量.和变量的使用 4. ...