python爬虫入门--beautifulsoup
1,beautifulsoup的中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
2,
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
""";
soup = BeautifulSoup(html_doc);
print(soup.prettify())
1)soup.prettify()的作用是把html格式化输出
2)在输出是会发出警告:No parser was explicitly specified, so I'm using the best available HTML parser for this system。这是因为没有解析器。所以需要安装解析器。如下图:
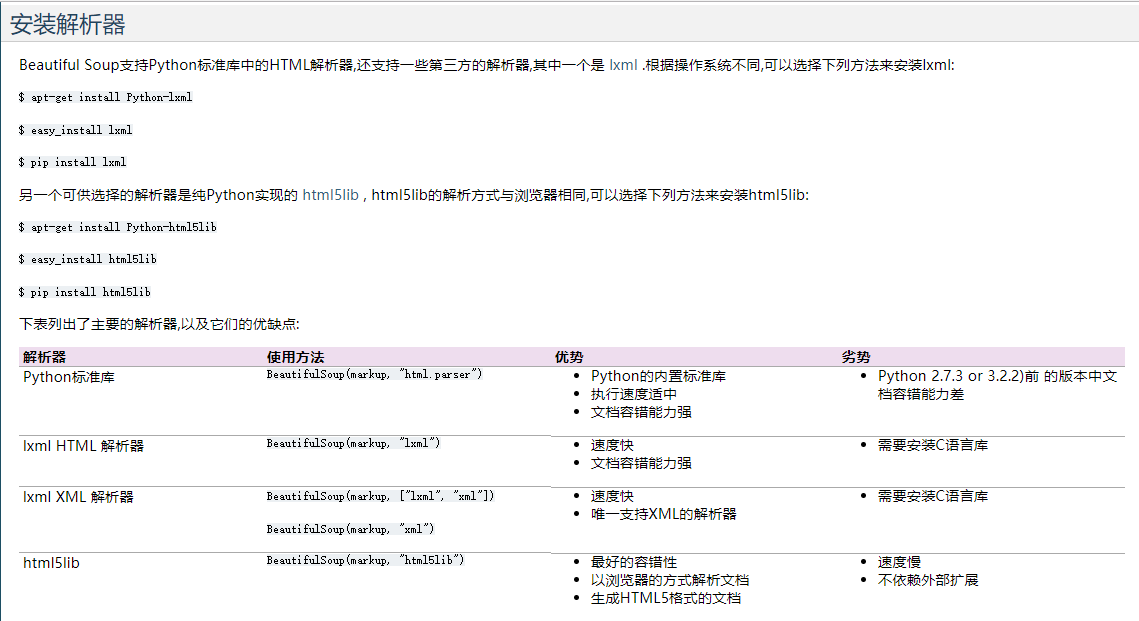
3)soup = BeautifulSoup(html_doc,"html.parser");//这个就可以加入解析器
print(soup.prettify())
4)soup.title #获取title内容<title>The Dormouse's story</title>
soup.标签名 #获取对应的标签。(系统当前第一个)
soup.find_all('a') #打印出所有‘a’标签 返回的是一个数组
soup.find(id="link3") #打印出对应id页面
for link in soup.find_all('a'): #这个用来遍历
print(link.get('id'))
#在遍历class时候返回的是一个数组
print(link.get('class'))
#['sister1']
#['sister2']
#['sister3']
soup.get_text() #这个是用来获取所有的文字
soup.find('p',{'class':'story'})) #这个里面是获取p标签下的class=story所有信息 注:这里因为class是关键字所以不能使用find('class':'story')
soup.find('p',{'class':'story'}).string) # 结果为none
5)可以通过政策表达式来 match() 来匹配内容.下面例子中找出所有以b开头的标签,这表示<body>和<b>标签都应该被找到:
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
(5.1),python的正则表达式
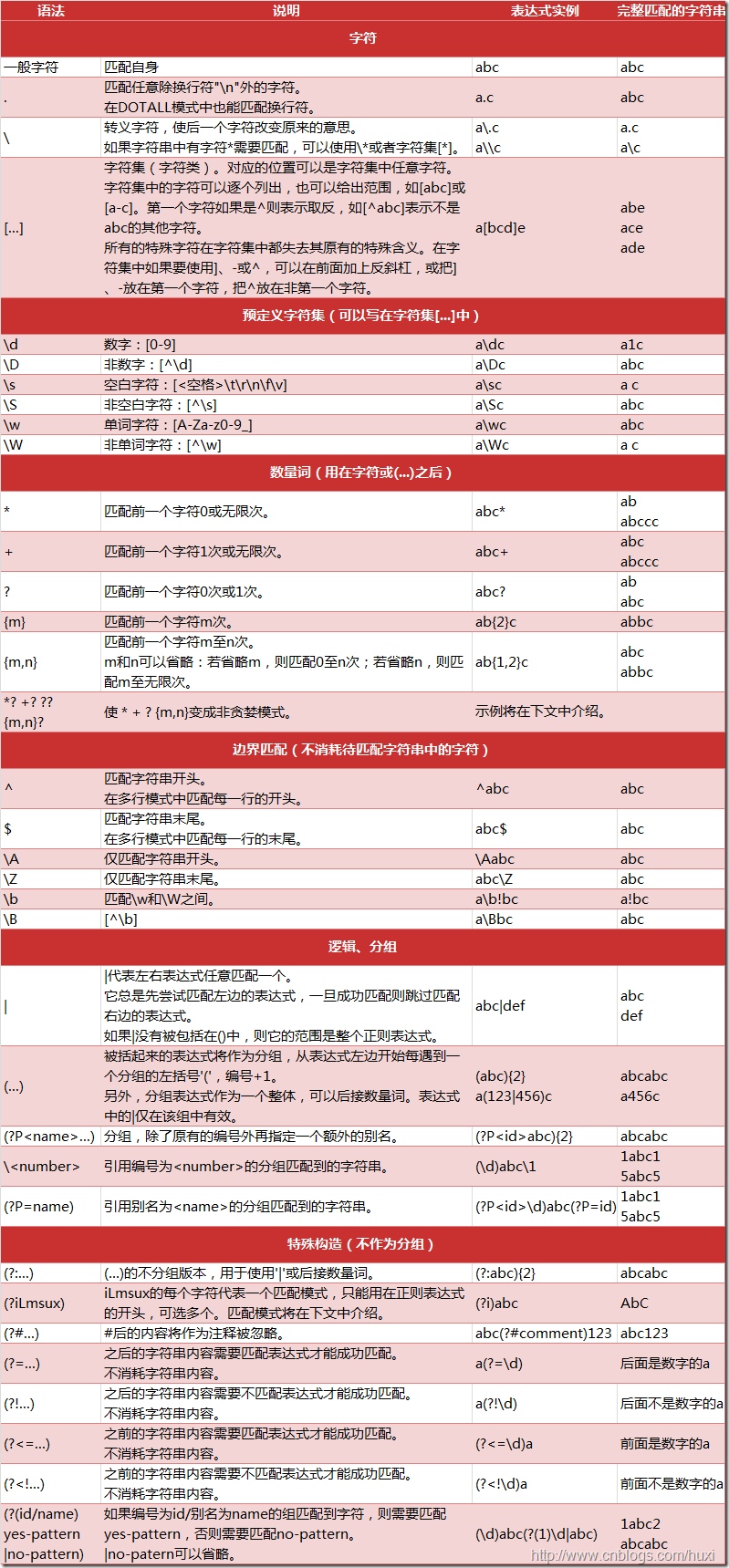
(注:图片来源https://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html)
python爬虫入门--beautifulsoup的更多相关文章
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- python爬虫入门-开发环境与小例子
python爬虫入门 开发环境 ubuntu 16.04 sublime pycharm requests库 requests库安装: sudo pip install requests 第一个例子 ...
- Python爬虫入门教程 48-100 使用mitmdump抓取手机惠农APP-手机APP爬虫部分
1. 爬取前的分析 mitmdump是mitmproxy的命令行接口,比Fiddler.Charles等工具方便的地方是它可以对接Python脚本. 有了它我们可以不用手动截获和分析HTTP请求和响应 ...
- Python爬虫入门教程 43-100 百思不得姐APP数据-手机APP爬虫部分
1. Python爬虫入门教程 爬取背景 2019年1月10日深夜,打开了百思不得姐APP,想了一下是否可以爬呢?不自觉的安装到了夜神模拟器里面.这个APP还是比较有名和有意思的. 下面是百思不得姐的 ...
- Python爬虫入门之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
- Python爬虫入门之Cookie的使用
本节我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密) 比如说有些网站需要 ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
随机推荐
- windows平台安装并使用MongoDB
下载并安装MongoDB,我的安装路径:D:\Program_Files\MongoDB 创建数据库目录,我的目录:D:\mongodb\data\db 命令行下运行MongoDB服务器: 在命令行窗 ...
- LeetCode 110. Balanced Binary Tree (平衡二叉树)
Given a binary tree, determine if it is height-balanced. For this problem, a height-balanced binary ...
- spacemacs 初始安装报错
尝试使用emcas的配置文件spacemacs,第一次安装启动时,界面为纯白色,而且在输入完几个配置选项后,报了一个错误 Symbol's value as variable is void 根据官网 ...
- 给资源文件添加指纹(Gulp版)
至于为什么要费尽心思地给文件添加指纹,请参看前端静态资源缓存控制策略.这次要达到的小目标就是生成的资源文件能够被客户端缓存,而在文件内容变化后,能够请求到最新的文件. 需要用到的 gulp 插件是 g ...
- NFS启动时报错Linux NFS:could not open connection for tcp6
1.1 启动时出现的错误 [root@znix ~]#/etc/init.d/nfs start Shutting down NFS daemon: ...
- CentOS6.8通过yum安装MySQL5.7
Centos6.8通过yum安装mysql5.7 1.安装mysql的yum源 a.下载配置mysql的yum源的rpm包 根据上面3张图片中的操作下载下来的rpm文件可以通过如下命令获取: wget ...
- node调试工具--node-inspector安装
node-inspector安装: npm install --registry=http://r.cnpmjs.org -g cnpm cnpm install -g node-inspector ...
- HDU3045 Picnic Cows (斜率DP优化)(数形结合)
转自PomeCat: "DP的斜率优化--对不必要的状态量进行抛弃,对不优的状态量进行搁置,使得在常数时间内找到最优解成为可能.斜率优化依靠的是数形结合的思想,通过将每个阶段和状态的答案反映 ...
- Three ways to throw exception in C#. Which is your preference?
There are three ways to 'throw' a exception in C# C#中有三种抛出异常的方式 Use the throw keyword without an id ...
- 【2】hadoop搭建准备软件
准备一:VMware虚拟工具: 链接:http://pan.baidu.com/s/1o7F4A6I 密码:w5ti 准备二:CentOS6.8虚拟机(64位):如果64位不允许安装,可能是电脑设置问 ...