记一次wiki数据爬取过程
最近有个爬取各国领导人信息的奇怪需求,要求百度和维基两种版本的数据,最要命的还要保持数据的结构不变。正好印象中隐约记得维基有专门的领导人列表页,不考虑爬取下来的格式不变的话应该很好爬的样子。
首先思路是通过列表页把每个领导人的信息页链接爬取下来,然后再逐个去解析信息页就OK了,思路很简单。
那么准备好爬取入口,在wiki上有一个各国领导人信息的列表页:https://zh.wikipedia.org/wiki/各国领导人列表
打开这个页面是这样的:
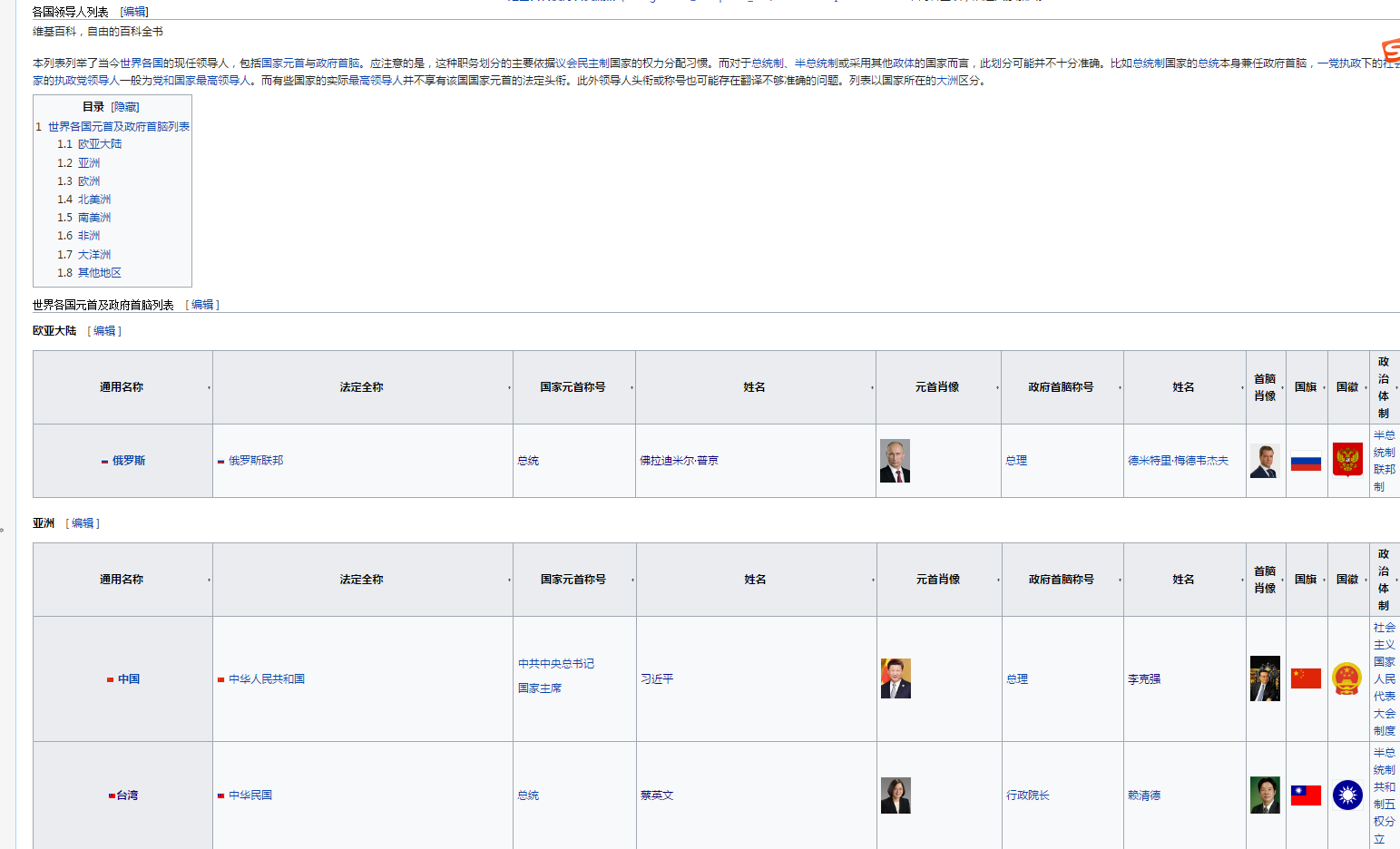
简直就是专为爬取设计的入口页,看了下页面代码结构,也是好爬的不行,查看具体的人物信息页链接是这样的格式:
https://zh.wikipedia.org/wiki/+名字
也就是这一页爬名字统统爬取下来,再凑好链接,加入任务列表就好了。
这是爬取列表页生成任务队列的代码:
/**
* 1.拿到列表页,得到所有领导人的姓名
* 2.用姓名拼凑出链接,加入爬取队列
*/
//得到信息列表并遍历列表
List<Selectable> peopleTable = page.getHtml().xpath("//div[@id='mw-content-text']/div/table").nodes();
for (Selectable table : peopleTable) {
if (count != 0) {
break;
}
//拼凑链接加入爬取队列
List<Selectable> peopleLine = table.xpath("//tr").nodes();
for (Selectable line : peopleLine) {
String name = line.xpath("//td[3]/a/text()").get();
if (null == name || "".equals(name)) {
continue;
}
String country = line.xpath("//td[1]/a/text()").get();
//System.out.println("名字:"+name+"-------------"+"链接:"+url);
countrys.put(name, country);
String url = "https://zh.wikipedia.org/wiki/" + name;
page.addTargetRequest(url);
}
}
接下来就去人物信息页查看页面结构,发现人物信息页的数据结构不太好爬,是这样子的:
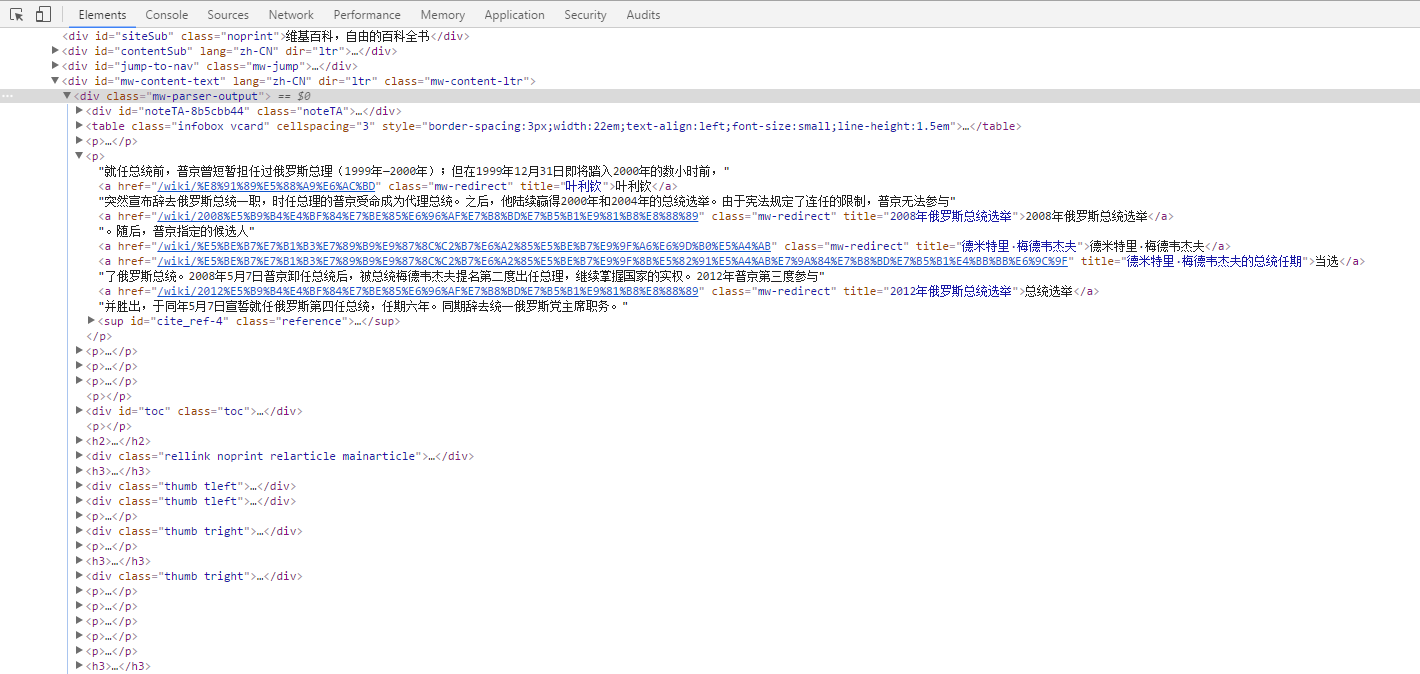
全是p标签和h标签的结构,看着脑袋疼,不过发现了一个有意思的东西,就是页面中有个这样的目录:
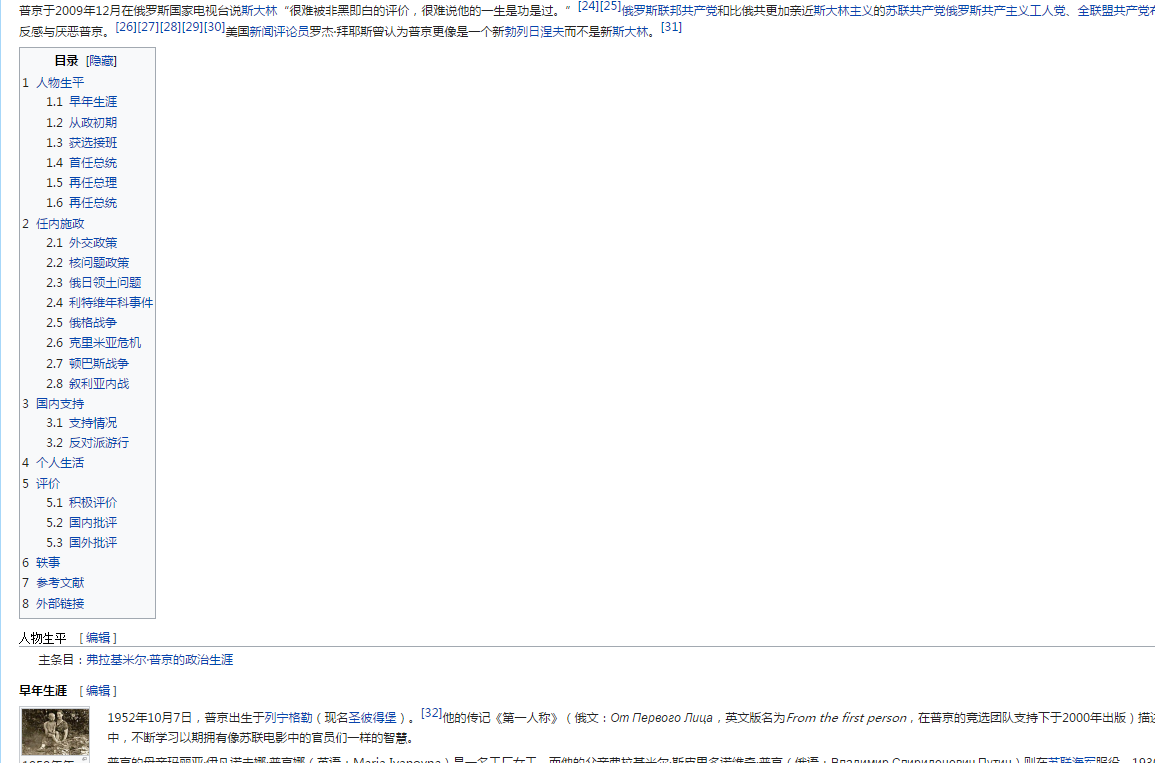
那么就根据目录来定位内容进行爬取,正好保证了数据的结构不变。
仔细查看目录发现目录跟后面的内容还是有联系点的:
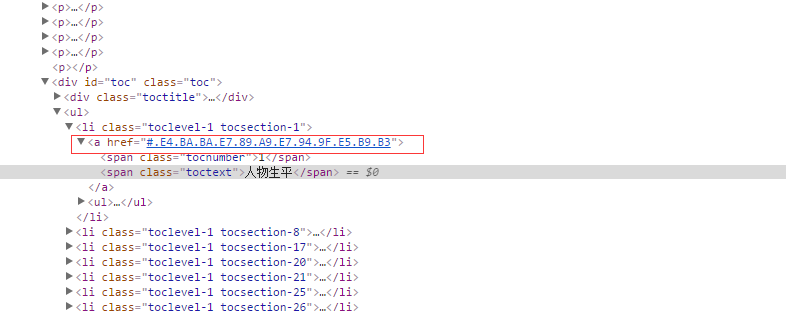
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
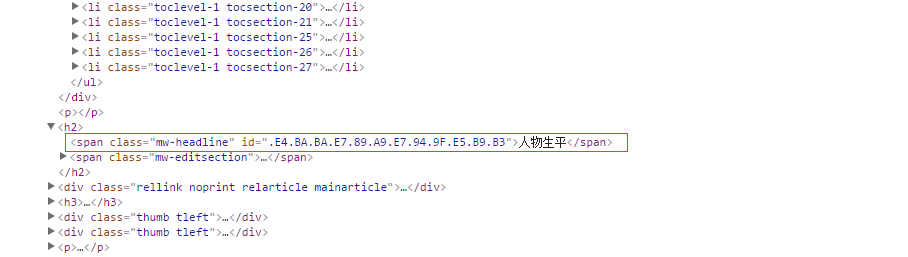
很明显的联系,那就根据目录来爬取了。
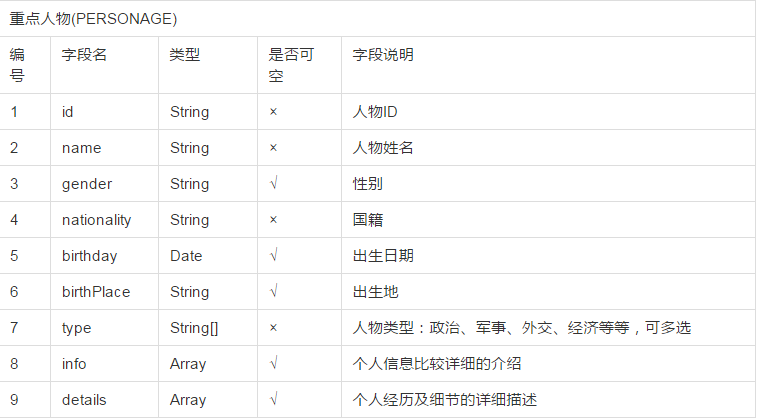
在这之前需要先设计好数据,考虑到之后可能不止存领导人的信息而且每个人物的目录层次变动性很大,所以使用mongodb存数据
设计表如下,尽可能把页面上的数据都朗阔进去,虽然不一定都爬下来:
接下来就开始写解析代码将数据抽取出来了,这一步需要用到jsoup来解析页面,里面有个很好用的方法就是定位到标签后可以拿到它的前一个或后一个兄弟标签,非常适用于这种文本段落没明显分层的页面。下面的是解析代码:
/**
* 1.解析详细人物信息页
* 2.编写抽取规则,进行数据抽取
*/
leader = new Leader();
//从链接得到所解析人物的姓名,再得到国籍
String leaderUrl = page.getUrl().get();
String leaderName = leaderUrl.replace("https://zh.wikipedia.org/wiki/", "");
String leaderCountry = countrys.get(leaderName);
System.out.println(leaderName + "--------" + leaderCountry);
leader.setId("" + count);
leader.setName(leaderName);
leader.setNationality(leaderCountry);
leader.setType(new String[] { "军事", "政治" });
// testa = leaderName;
//解析页面,得到页面的导航目录,通过目录爬取具体内容
List<Selectable> lists = page.getHtml().xpath("//div[@id='toc']/ul/li").nodes();
List<Item> leaderDetail = new ArrayList<>();
for (Selectable list : lists) {
Item item = new Item();//一级目录
List<SubItems> subItems = new ArrayList<SubItems>();//二级目录
List<Selectable> secondLists = list.xpath("//ul//li").nodes();
//如果一级目录下记录不为0,说明当前目录下存在二级标题。否则只存在一级标题
if (secondLists.size() != 0) {
String firstItem = list.xpath("//span[2]/text()").get();
//抽取二级目录数据
for (Selectable secondList : secondLists) {
SubItems subItem = new SubItems();
String[] secondItem = getText(secondList, page);
subItem.setName(secondItem[0]);
subItem.setValue(secondItem[1]);
subItems.add(subItem);
}
item.setName(firstItem);
item.setValue("");
item.setSubItems(subItems);
leaderDetail.add(item);
} else {
//抽取一级目录数据
String[] secondItem = getText(list, page);
item.setName(secondItem[0]);
item.setValue(secondItem[1]);
leaderDetail.add(item);
}
}
其中的二级目录内容获取方法:
public String[] getText(Selectable select, Page page) {
String itemId = select.xpath("//a/@href").get();
itemId = itemId.replace("#", "");
Document doc = Jsoup.parse(page.getHtml().get());
String citiao = doc.getElementById(itemId).text();
Element elt = doc.getElementById(itemId).parent();
StringBuffer sb = new StringBuffer();
while (true) {
elt = elt.nextElementSibling();
if (elt == null || "h2".equals(elt.tagName()) || "h3".equals(elt.tagName())) {
break;
}
sb.append(elt.text()).append("\r\n");
}
return new String[] { citiao, sb.toString() };
}
这里面主要的就是要保持爬取下来的数据要按目录结构存储,一级目录包含二级目录,对应关系要把持住,在设计数据库的时候就需要考虑到。
然后是一些相关bean:
public class Leader {
private String id;
private String name;
private String gender;
private String nationality;
private Date birthday;
private String birthPlace;
private String[] type;
private List<Item> info;
private List<Item> details;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public class Item {
private String name;
private String value;
private List<SubItems> subItem;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
public List<SubItems> getSubItems() {
return subItem;
}
public void setSubItems(List<SubItems> subItem) {
this.subItem = subItem;
}
}
public class SubItems {
private String name;
private String value;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}
最后测试的时候,发现一个很严重的问题,就是有些叫不出名字的国家,他们的领导人页面没有目录(就寥寥几句简介)。。。。。。导致信息爬取不出。
这是最后无目录的领导人个数:

这是数据库的数据:
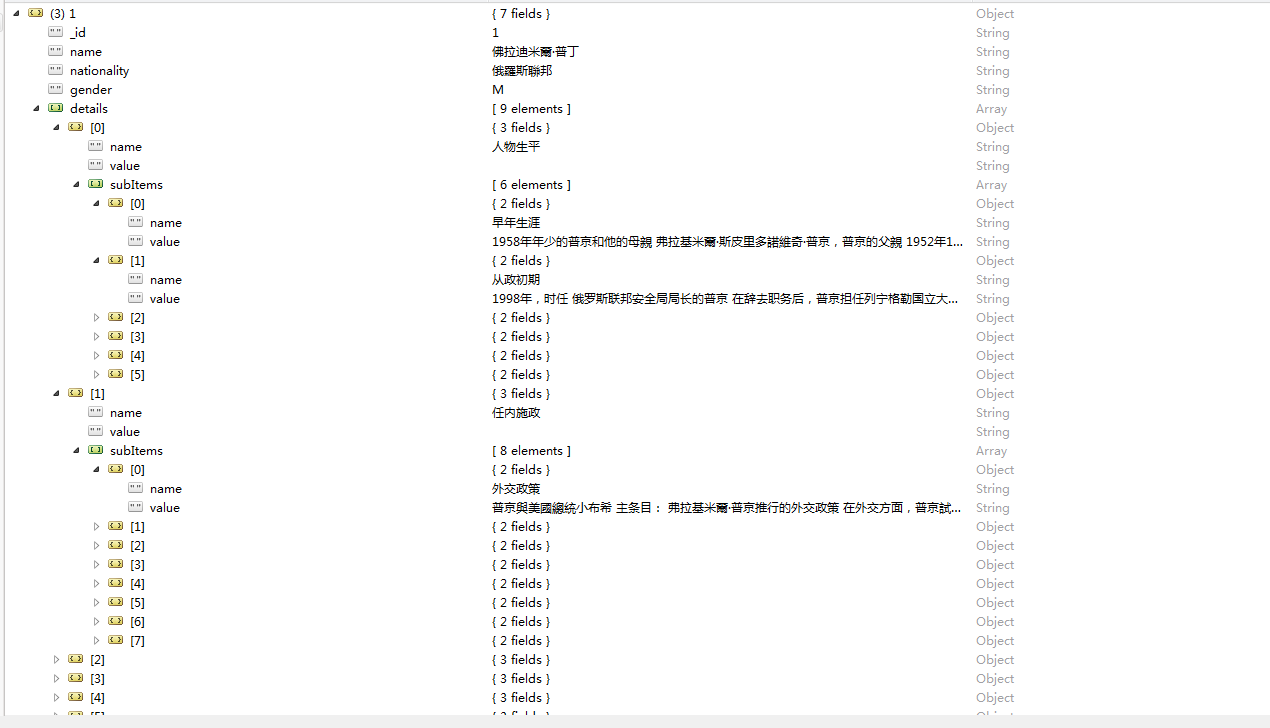
只能说成功了一半。~~|
记一次wiki数据爬取过程的更多相关文章
- 一个免费ss网站的数据爬取过程
一个免费ss网站的数据爬取过程 Apr 14, 2019 引言 爬虫整体概况 主要功能方法 绕过DDOS保护(Cloudflare) post中参数a,b,c的解析 post中参数a,b,c的解析 p ...
- 芝麻HTTP:JavaScript加密逻辑分析与Python模拟执行实现数据爬取
本节来说明一下 JavaScript 加密逻辑分析并利用 Python 模拟执行 JavaScript 实现数据爬取的过程.在这里以中国空气质量在线监测分析平台为例来进行分析,主要分析其加密逻辑及破解 ...
- Python爬虫入门教程 15-100 石家庄政民互动数据爬取
石家庄政民互动数据爬取-写在前面 今天,咱抓取一个网站,这个网站呢,涉及的内容就是 网友留言和回复,特别简单,但是网站是gov的.网址为 http://www.sjz.gov.cn/col/14900 ...
- python3编写网络爬虫13-Ajax数据爬取
一.Ajax数据爬取 1. 简介:Ajax 全称Asynchronous JavaScript and XML 异步的Javascript和XML. 它不是一门编程语言,而是利用JavaScript在 ...
- requests模块session处理cookie 与基于线程池的数据爬取
引入 有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们想要的目的,例如: #!/usr/bin/ ...
- 爬虫—Ajax数据爬取
一.什么是Ajax 有时候我们使用浏览器查看页面正常显示的数据与使用requests抓取页面得到的数据不一致,这是因为requests获取的是原始的HTML文档,而浏览器中的页面是经过JavaScri ...
- scrapy 在爬取过程中抓取下载图片
先说前提,我不推荐在sarapy爬取过程中使用scrapy自带的 ImagesPipeline 进行下载,是在是太耗时间了 最好是保存,在使用其他方法下载 我这个是在 https://blog.csd ...
- 用Python介绍了企业资产情况的数据爬取、分析与展示。
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:张耀杰 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自 ...
- Web Scraper——轻量数据爬取利器
日常学习工作中,我们多多少少都会遇到一些数据爬取的需求,比如说写论文时要收集相关课题下的论文列表,运营活动时收集用户评价,竞品分析时收集友商数据. 当我们着手准备收集数据时,面对低效的复制黏贴工作,一 ...
随机推荐
- python-快速排序,两种方法→易理解
快速排序(Quicksort)是对冒泡排序的一种改进. 快速排序由C. A. R. Hoare在1962年提出.它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另 ...
- POJ3268 Silver Cow Party Dijkstra最短路
Description One cow from each of N farms (1 ≤ N ≤ 1000) conveniently numbered 1..N is going to atten ...
- iOS上机题(附个人见解)
##机试题目如下 用命令行创建一个以CocoaPods管理的项目[Test-你的姓名拼音],新建3个ViewController,完成以下题目 将下面的问题在一个UITabView里面列出所有问题,单 ...
- Nagios部署与配置
Nagos是一款开源电脑系统和网络监视工具,能够有效监控windows,linux,Uninx的主机状态,交换机路由器等网络设置,打印机等.在系统或服务状态异常时发出邮件或短信报警第一时间通知运维人员 ...
- Cocoapods 应用第一部分 - Xcode 创建 .framework 相关
问题的提出: 随着项目的越来越大,可能会出现好几个团队共同维护一个项目的情况,例如:项目组A负责其中的A块,项目组B负责其中的B块.....这几块彼此之间既独立,也相互联系.对于这种情况,可以采用约定 ...
- Linux - 简明Shell编程08 - 函数(Function)
脚本地址 https://github.com/anliven/L-Shell/tree/master/Shell-Basics 示例脚本及注释 #!/bin/bash function Check( ...
- 基于 Laravel、Vue.js开发的全新社交系统----ThinkSNS+
什么是ThinkSNS+ ThinkSNS(简称TS)始于2008年,一款全平台综合性社交系统,为国内外大中小企业和创业者提供社会化软件研发及技术解决方案,目前最新版本为ThinkSNS+.新的产品名 ...
- Swoole笔记(四)
Process Process是swoole内置的进程管理模块,用来替代PHP的pcntl扩展. swoole_process支持重定向标准输入和输出,在子进程内echo不会打印屏幕,而是写入管道,读 ...
- vue中使用cropperjs进行图片裁剪上传
下面代码直接就可以复制使用了,但是需要在本地下个cropperjs,下载命令:npm install cropperjs --save-dev <template> <div id= ...
- 解决火狐中用JQUERY .removeAttr()无法去除元素属性的方法
//为元素添加只读属性 $("#test").attr("readonly","readonly") //去除元素的只读属性 $(" ...