Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗
Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗
零、致谢
感谢BOSS直聘相对权威的招聘信息,使本人有了这次比较有意思的研究之旅。
由于爬虫持续爬取 www.zhipin.com 网站,以致产生的服务器压力,本人深感歉意,并没有 DDoS 和危害贵网站的意思。
[2017-12-14更新]在跑了一夜之后,服务器 IP 还是被封了,搞得本人现在家里、公司、云服务器三线作战啊
[2017-12-19更新]后续把拉勾网的数据也爬到,加了进来
一、抓取详细的职位描述信息
1.1 前提数据
这里需要知道页面的 id 才能生成详细的链接,在 Python爬虫框架Scrapy实战 - 抓取BOSS直聘招聘信息 中,我们已经拿到招聘信息的大部分信息,里面有个 pid 字段就是用来唯一区分某条招聘,并用来拼凑详细链接的。
是吧,明眼人一眼就看出来了。
1.2 详情页分析
详情页如下图所示
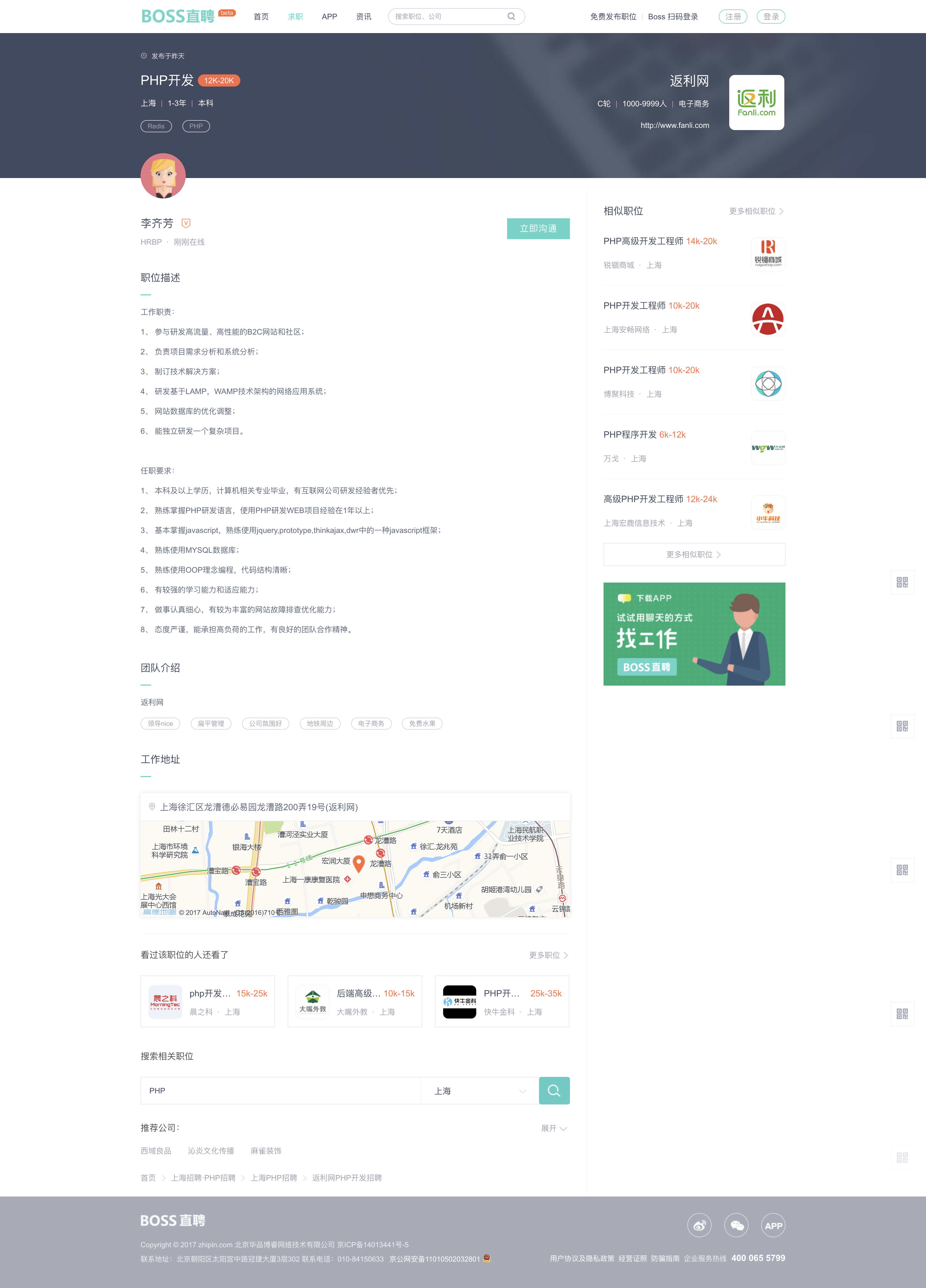
在详情页中,比较重要的就是职位描述和工作地址这两个
由于在页面代码中岗位职责和任职要求是在一个 div 中的,所以在抓的时候就不太好分,后续需要把这个连体婴儿,分开分析。
1.3 爬虫用到的库
使用的库有
- requests
- BeautifulSoup4
- pymongo
对应的安装文档依次如下,就不细说了
1.4 Python 代码
"""
@author: jtahstu
@contact: root@jtahstu.com
@site: http://www.jtahstu.com
@time: 2017/12/10 00:25
"""
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
from pymongo import MongoClient
headers = {
'x-devtools-emulate-network-conditions-client-id': "5f2fc4da-c727-43c0-aad4-37fce8e3ff39",
'upgrade-insecure-requests': "1",
'user-agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36",
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
'dnt': "1",
'accept-encoding': "gzip, deflate",
'accept-language': "zh-CN,zh;q=0.8,en;q=0.6",
'cookie': "__c=1501326829; lastCity=101020100; __g=-; __l=r=https%3A%2F%2Fwww.google.com.hk%2F&l=%2F; __a=38940428.1501326829..1501326829.20.1.20.20; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1501326839; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1502948718; __c=1501326829; lastCity=101020100; __g=-; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1501326839; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1502954829; __l=r=https%3A%2F%2Fwww.google.com.hk%2F&l=%2F; __a=38940428.1501326829..1501326829.21.1.21.21",
'cache-control': "no-cache",
'postman-token': "76554687-c4df-0c17-7cc0-5bf3845c9831"
}
conn = MongoClient('127.0.0.1', 27017)
db = conn.iApp # 连接mydb数据库,没有则自动创建
def init():
items = db.jobs_php.find().sort('pid')
for item in items:
if 'detail' in item.keys(): # 在爬虫挂掉再此爬取时,跳过已爬取的行
continue
detail_url = "https://www.zhipin.com/job_detail/%s.html?ka=search_list_1" % item['pid']
print(detail_url)
html = requests.get(detail_url, headers=headers)
if html.status_code != 200: # 爬的太快网站返回403,这时等待解封吧
print('status_code is %d' % html.status_code)
break
soup = BeautifulSoup(html.text, "html.parser")
job = soup.select(".job-sec .text")
if len(job) < 1:
continue
item['detail'] = job[0].text.strip() # 职位描述
location = soup.select(".job-sec .job-location")
item['location'] = location[0].text.strip() # 工作地点
item['updated_at'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) # 实时爬取时间
res = save(item) # 保存数据
print(res)
time.sleep(40) # 停停停
# 保存数据到 MongoDB 中
def save(item):
return db.jobs_php.update_one({"_id": item['_id']}, {"$set": item})
if __name__ == "__main__":
init()
代码 easy,初学者都能看懂。
1.5 再啰嗦几句
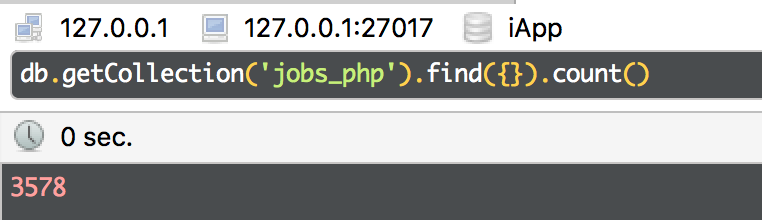
在 上一篇文章 中只是爬了 上海-PHP 近300条数据,后续改了代码,把12个城市的 PHP 相关岗位的数据都抓下来了,有3500+条数据,慢慢爬吧,急不来。
像这样

二、数据清洗
2.1 校正发布日期
"time" : "发布于03月31日",
"time" : "发布于昨天",
"time" : "发布于11:31",
这里拿到的都是这种格式的,所以简单处理下
import datetime
from pymongo import MongoClient
db = MongoClient('127.0.0.1', 27017).iApp
def update(data):
return db.jobs_php.update_one({"_id": data['_id']}, {"$set": data})
# 把时间校正过来
def clear_time():
items = db.jobs_php.find({})
for item in items:
if not item['time'].find('布于'):
continue
item['time'] = item['time'].replace("发布于", "2017-")
item['time'] = item['time'].replace("月", "-")
item['time'] = item['time'].replace("日", "")
if item['time'].find("昨天") > 0:
item['time'] = str(datetime.date.today() - datetime.timedelta(days=1))
elif item['time'].find(":") > 0:
item['time'] = str(datetime.date.today())
update(item)
print('ok')
2.2 校正薪水以数字保存
"salary" : "5K-12K",
#处理成下面的格式
"salary" : {
"low" : 5000,
"high" : 12000,
"avg" : 8500.0
},
# 薪水处理成数字,符合 xk-yk 的数据处理,不符合的跳过
def clear_salary():
items = db.jobs_lagou_php.find({})
for item in items:
if type(item['salary']) == type({}):
continue
salary_list = item['salary'].lower().replace("k", "000").split("-")
if len(salary_list) != 2:
print(salary_list)
continue
try:
salary_list = [int(x) for x in salary_list]
except:
print(salary_list)
continue
item['salary'] = {
'low': salary_list[0],
'high': salary_list[1],
'avg': (salary_list[0] + salary_list[1]) / 2
}
update(item)
print('ok')
[2017-12-19更新]这里在处理 Boss 直聘的数据时,比较简单正常,但是后续抓到拉勾网的数据,拉勾网的数据有些不太规范。比如有‘20k以上’这种描述
2.3 根据 工作经验年限 划分招聘等级
# 校正拉勾网工作年限描述,以 Boss直聘描述为准
def update_lagou_workyear():
items = db.jobs_lagou_php.find({})
for item in items:
if item['workYear'] == '应届毕业生':
item['workYear'] = '应届生'
elif item['workYear'] == '1年以下':
item['workYear'] = '1年以内'
elif item['workYear'] == '不限':
item['workYear'] = '经验不限'
update_lagou(item)
print('ok')
# 设置招聘的水平,分两次执行
def set_level():
items = db.jobs_zhipin_php.find({})
# items = db.jobs_lagou_php.find({})
for item in items:
if item['workYear'] == '应届生':
item['level'] = 1
elif item['workYear'] == '1年以内':
item['level'] = 2
elif item['workYear'] == '1-3年':
item['level'] = 3
elif item['workYear'] == '3-5年':
item['level'] = 4
elif item['workYear'] == '5-10年':
item['level'] = 5
elif item['workYear'] == '10年以上':
item['level'] = 6
elif item['workYear'] == '经验不限':
item['level'] = 10
update(item)
print('ok')
这里有点坑的就是,一般要求经验不限的岗位,需求基本都写在任职要求里了,所以为了统计的准确性,这个等级的数据,后面会被舍弃掉。
[2017-12-14更新]从后续的平均数据来看,这里的经验不限,一般要求的是1-3年左右,但是还是建议舍弃掉。
[2017-12-19更新]拉勾网的职位描述和 Boss直聘稍有不同,需要先校正,然后再设置等级
2.4 区分开<岗位职责>和<任职要求>
对于作者这个初学者来说,这里还没有什么好的方法,知道的同学,请务必联系作者,联系方式在个人博客里
so , i'm sorry.
为什么这两个不好划分出来呢?
因为这里填的并不统一,可以说各种花样,有的要求在前,职责在后,有的又换个名字区分。目前看到的关于要求的有['任职条件', '技术要求', '任职要求', '任职资格', '岗位要求']这么多说法。然后顺序还不一样,有的要求在前,职责在后,有的又反之。
举个栗子
会基本的php编程!能够修改简单的软件!对云服务器和数据库能够运用!懂得微信公众账号对接和开放平台对接!我们不是软件公司,是运营公司!想找好的公司学习的陕西基本没有,要到沿海城市去!但是我们是实用型公司,主要是软件应用和更适合大众!
啥也不说的,这里可以认为这是一条脏数据了。
再举个栗子
PHP中级研发工程师(ERP/MES方向)
1、计算机或相关学科本科或本科以上学历;
2、php和Java script的开发经验。
3、Linux和MySQL数据库的开发经验;
5、有ERP、MES相关开发经验优先;
6、英语的读写能力;
7、文化的开放性;
我们提供
1、有趣的工作任务;
2、多元的工作领域;
3、与能力相关的收入;
4、年轻、开放并具有创造力的团队和工作氛围;
5、不断接触最新科技(尤其是工业4.0相关);
6、可适应短期出差(提供差补);
这个只有要求,没职责,还多了个提供,我乐个趣 ╮(╯▽╰)╭
所以,气的想骂人。
2.5 缺失值分析 [2017-12-19]更新
Boss直聘这里有部分招聘没有industryField、financeStage和companySize值,这个可以看前一篇的爬虫代码,拉勾网的数据基本没问题。
2.6 异常值分析 [2017-12-19] 更新
- 岗位要求工作年限和职位描述里的要求不一致,比如岗位列表里要求的是
1年以内,但是职位描述里却是2年以上工作经验,这是由于 HR 填写不规范引起的误差。 - 由第1点引起的另一个问题,就是与工作年限要求不对应的薪水,使计算的平均薪水偏高。比如一条记录,年限要求是
一年以内,所以等级为2,但是薪水却是20k-30k,实际上这是等级为3的薪水,这里就得校正 level 字段,目前只是手动的把几个较高的记录手动改了,都校正过来很困难,得文本分析招聘要求。
2.7 失效值排除 [2017-12-19] 更新
首先这里需要一个判断某条招聘是否还挂在网站上的方法,这个暂时想到了还没弄
然后对于发布时间在两个月之前的数据,就不进行统计计算
ok ,现在我们的数据基本成这样了
{
"_id" : ObjectId("5a30ad2068504386f47d9a4b"),
"city" : "苏州",
"companyShortName" : "蓝海彤翔",
"companySize" : "100-499人",
"education" : "本科",
"financeStage" : "B轮",
"industryField" : "互联网",
"level" : 3,
"pid" : "11889834",
"positionLables" : [
"PHP",
"ThinkPHP"
],
"positionName" : "php研发工程师",
"salary" : {
"avg" : 7500.0,
"low" : 7000,
"high" : 8000
},
"time" : "2017-06-06",
"updated_at" : "2017-12-13 18:31:15",
"workYear" : "1-3年",
"detail" : "1、处理landcloud云计算相关系统的各类开发和调研工作;2、处理coms高性能计算的各类开发和调研工作岗位要求:1、本科学历,两年以上工作经验,熟悉PHP开发,了解常用的php开发技巧和框架;2、了解C++,python及Java开发;3、有一定的研发能力和钻研精神;4、有主动沟通能力和吃苦耐劳的精神。",
"location" : "苏州市高新区科技城锦峰路158号101park8幢"
}
由于还没到数据展示的时候,所以现在能想到的就是先这样处理了
项目开源地址:http://git.jtahstu.com/jtahstu/Scrapy_zhipin
三、展望和设想
首先这个小玩意数据量并不够多,因为爬取时间短,站点唯一,再者广度局限在 PHP 这一个岗位上,以致存在一定的误差。
所以为了数据的丰富和多样性,这个爬虫是一定要持续跑着的,至少要抓几个月的数据才算可靠吧。
然后准备再去抓下拉勾网的招聘数据,这也是个相对优秀的专业 IT 招聘网站了,数据也相当多,想当初找实习找正式工作,都是在这两个 APP 上找的,其他的网站几乎都没看。
最后,对于科班出身的学弟学妹们,过来人说一句,编程相关的职业就不要去志连、钱尘乌有、five eight桐城了,好吗?那里面都发的啥呀,看那些介绍心里没点数吗?
四、help
这里完全就是作者本人依据个人微薄的见识,主观臆断做的一些事情,所以大家有什么点子和建议,都可以评论一下,多交流交流嘛。
后续会公开所有数据,大家自己可以自己分析分析。
我们太年轻,以致都不知道以后的时光,竟然那么长,长得足够让我们把一门技术研究到顶峰,乱花渐欲迷人眼,请不要忘了根本好吗。
生活总是让我们遍体鳞伤,但到后来,那些受伤的地方一定会变成我们最强壮的地方。 —海明威 《永别了武器》
Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗的更多相关文章
- Scrapy 爬取BOSS直聘关于Python招聘岗位
年前的时候想看下招聘Python的岗位有多少,当时考虑目前比较流行的招聘网站就属于boss直聘,所以使用Scrapy来爬取下boss直聘的Python岗位. 1.首先我们创建一个Scrapy 工程 s ...
- Python的scrapy之爬取boss直聘网站
在我们的项目中,单单分析一个51job网站的工作职位可能爬取结果不太理想,所以我又爬取了boss直聘网的工作,不过boss直聘的网站一次只能展示300个职位,所以我们一次也只能爬取300个职位. jo ...
- python3 爬取boss直聘职业分类数据(未完成)
import reimport urllib.request # 爬取boss直聘职业分类数据def subRule(fileName): result = re.findall(r'<p cl ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- 用BeautifulSoup简单爬取BOSS直聘网岗位
用BeautifulSoup简单爬取BOSS直聘网岗位 爬取python招聘 import requests from bs4 import BeautifulSoup def fun(path): ...
- 打造IP代理池,Python爬取Boss直聘,帮你获取全国各类职业薪酬榜
爬虫面临的问题 不再是单纯的数据一把抓 多数的网站还是请求来了,一把将所有数据塞进去返回,但现在更多的网站使用数据的异步加载,爬虫不再像之前那么方便 很多人说js异步加载与数据解析,爬虫可以做到啊,恩 ...
- Python爬取Boss直聘,帮你获取全国各类职业薪酬榜
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 王翔 清风Python PS:如有需要Python学习资料的小伙伴 ...
- scrapy爬取boss直聘实习生数据
这个..是我最近想找实习单位..结果发现boss上很多实习单位名字就叫‘实习生’.......太不讲究了 == 难怪一直搜不到..咳,其实是我自己水平有限,有些简历根本就投不出去 == 所以就想爬下b ...
- 基于‘BOSS直聘的招聘信息’分析企业到底需要什么样的PHP程序员
原文地址:http://www.jtahstu.com/blog/scrapy_zhipin_php.html 基于'BOSS直聘的招聘信息'分析企业到底需要什么样的PHP程序员 标签(空格分隔): ...
随机推荐
- android开发第一天
今天可以说是我正式投入android怀抱的第一天吧,按着自己的兴趣,努力地吸取知识.听了程老师的课,也觉得收获很多,毕竟以前都是看着书本或者网页教程来学习,第一次有人这么直接地跟你教授着,说着一些你听 ...
- SQL注入技术
TalkTalk的信息泄漏事件导致约15万人的敏感信息被暴露,涉嫌造成这一事件的其中一名黑客使用的并不是很新的技术.事实上,该技术的「年纪」比这名15岁黑客还要大两岁. [译注:TalkTalk是英国 ...
- 【XML】xStream浅录
XStream可以用来转换对象-XML,或者XML-对象. 官网地址:http://x-stream.github.io 小案例: 实体类 FileVo.java package cn.pinnsvi ...
- B树,B+树,B*树
参考资料 http://www.cnblogs.com/Bob-FD/archive/2012/06/20/2556505.html 第一节.B树.B+树.B*树 1.前言: 动态查找树主要有:二叉查 ...
- HDU4027 Can you answer these queries?(线段树 单点修改)
A lot of battleships of evil are arranged in a line before the battle. Our commander decides to use ...
- FatMouse and Cheese
FatMouse and Cheese Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u ...
- Linux系列教程(十三)——Linux软件包管理之源码包、脚本安装包
上篇博客我们讲解了网络yum源和光盘yum源的搭建步骤,然后详细介绍了相关的yum命令,yum 最重要是解决了软件包依赖性问题.在安装软件时,我们使用yum命令将会简单方便很多.我们知道yum命令只能 ...
- 粗略整理的java面试题
1.垃圾回收 是回收的空闲堆空间 只有在cpu空闲并且堆空间不足的情况下才回收 2.threadlocal 就是为线程的变量都提供了一个副本,每个线程运行都只是在更新这个副本. Threadloc ...
- w3wp.exe已附加有调试器,但没有该调试器配置为调试此未经处理的异常,若要调试此异常,必须分离当前的调试器。
之前通过使用VS2010附加进程调试项目后,今天开机发现调试本机的项目报错如下图: 到网上到处查看无果,经过反复实验找到解决方法,我的项目是发布到IIS的 1.首先删除IIS上面的项目 2.在VS右击 ...
- ldap数据库--ODSEE--安装
在安装之前最好查看一下服务器硬件是否满足要求,是否需要更改一些系统配置来达到使用ldap数据库的最有性能.实际使用的ldap数据库是oracle的产品,DS70即ODSEE. 安装环境:solaris ...