【LeetCode题解】排序
1. 排序
排序(sort)是一种常见的算法,把数据根据特定的顺序进行排列。经典的排序算法如下:
- 冒泡排序(bubble sort)
- 插入排序(insertion sort)
- 选择排序(selection sort)
- 快速排序(quick sort)
- 堆排序(heap sort)
- 归并排序(merge sort)
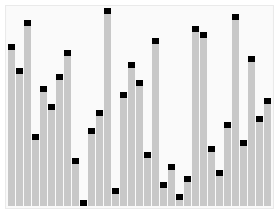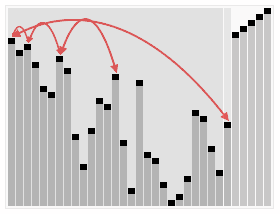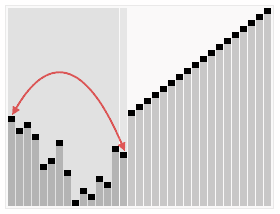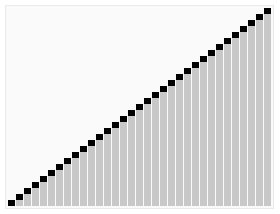
冒泡排序依次比较相邻的两个元素,若逆序则交换;如此走访数列重复n次,即不再发生交换,排序完成。(以下图片均来自于Wikipedia)

但是,冒泡排序存在着许多无意义的交换,比如:对于基本有序的数组(最好情况),冒泡排序仍旧有\(O(n^2)\)次交换。我们可以标记需要交换的可能,从而降低交换次数到\(O(n)\):
void bubble_sort(int a[], int n) {int i, bound;int exchange = n - 1; // 初始化while (exchange) {bound = exchange; // 记录上一次的交换位置exchange = 0; // 假定这一次没发生交换for (i = 0; i < bound; i++)if (a[i] > a[i + 1]) {swap(&a[i], &a[i + 1]);exchange = i;}}}
插入排序能很好地避免部分无意义的交换,其核心思想:从前往后扫描序列,已扫描的元素构成一个已排序的有序序列,当前扫描的元素作为待插入元素,从有序序列中找到其适合的位置进行插入。

选择排序是一种直观的排序算法,其基本思想:从前往后走访待排序序列,找出最小的元素置于待排序序列的首端;如此往复,直到待排序序列只包含一个元素。
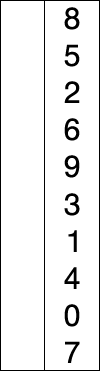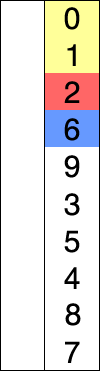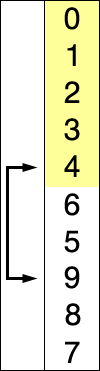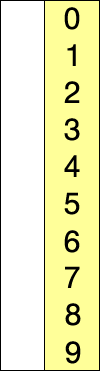
快速排序是由Hoare提出,采用了分治(divide and conquer)策略:选取一个基准pivot,将序列划分为两个子序列,比pivot小的元素归为左子序列,比pivot大(或等于)归于右子序列;如此递归地划分子序列直到无需划分(即整体有序)。此划分操作也被称为partition;下图给出以元素5为pivot的partition操作:

堆排序是指利用大顶堆(max heap)进行排序的算法,基本思想:依次删除堆顶元素(待排序序列的最大值),将其置于待排序序列的末端;如此往复,直至堆为空。
归并排序也是采用分治策略:将相邻两个有序的子序列进行归并(merge)操作,如此往复,直到归并成一个完整序列(排序完成)。初始时,子序列对应于每一个元素。
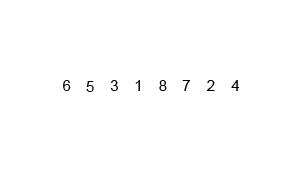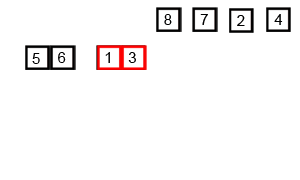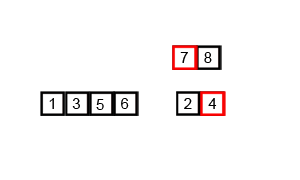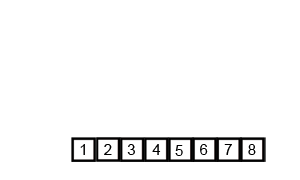
稳定性是衡量排序算法是否改变相等键值的次序的指标。典型地,比如快排因pivot的选取可能会改变相等键值的次序。各种排序算法的比较如下:
| 排序算法 | 时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|
| 冒泡排序 | \(O(n^2)\) | \(T(1)\) | 稳定 |
| 插入排序 | \(O(n^2)\) | \(T(1)\) | 稳定 |
| 选择排序 | \(O(n^2)\) | \(T(1)\) | 不稳定 |
| 快速排序 | \(O(n \log n)\) | \(T(1)\) | 不稳定 |
| 堆排序 | \(O(n \log n)\) | \(T(1)\) | 不稳定 |
| 归并排序 | \(O(n \log n)\) | \(T(\log n)\) | 稳定 |
2. 题解
| LeetCode题目 | 归类 |
|---|---|
| 75. Sort Colors | |
| 349. Intersection of Two Arrays | 插入 |
| 148. Sort List | 归并 |
| 242. Valid Anagram | |
| 56. Merge Intervals | |
| 57. Insert Interval | |
| 274. H-Index | |
| 275. H-Index II | |
| 179. Largest Number | |
| 349. Intersection of Two Arrays | |
| 350. Intersection of Two Arrays II |
75. Sort Colors
数字0、1、2排序,采取类似选择排序的思路,数字0放在首端,数字2放在尾端。
public void sortColors(int[] nums) {int low = 0, high = nums.length - 1;for (int k = 0; k <= high; k++) {if (nums[k] == 0)swap(nums, k, low++);else if (nums[k] == 2)swap(nums, k--, high--);}}private void swap(int[] A, int a, int b) {int temp = A[a];A[a] = A[b];A[b] = temp;}
349. Intersection of Two Arrays
链表的插入排序。
public ListNode insertionSortList(ListNode head) {ListNode nHead = new ListNode(0), p = head, pNext, np, nPre;while (p != null) {// find the suitable position to insertfor (np = nHead.next, nPre = nHead; np != null && np.val < p.val; ) {np = np.next;nPre = nPre.next;}nPre.next = p;pNext = p.next;p.next = np;p = pNext;}return nHead.next;}
148. Sort List
排序链表,要求时间复杂度\(O(n \log n)\)、空间复杂度\(T(1)\),所以使用归并排序。其中,合并两个有序链表复用了问题21. Merge Two Sorted Lists的代码。
public ListNode sortList(ListNode head) {if (head == null || head.next == null) return head;ListNode pre = head, slow = head, fast = head;// cut the list into two halveswhile (fast != null && fast.next != null) {pre = slow;slow = slow.next;fast = fast.next.next;}pre.next = null;// sort the two halvesListNode l1 = sortList(head);ListNode l2 = sortList(slow);// merge the two sorted halvesreturn mergeTwoLists(l1, l2);}
242. Valid Anagram
判断两个字符串是否同构(变位词)。将values数组排序后,判断是否相等。
public boolean isAnagram(String s, String t) {char[] sValues = s.toCharArray();char[] tValues = t.toCharArray();Arrays.sort(sValues);Arrays.sort(tValues);return Arrays.equals(sValues, tValues);}
56. Merge Intervals
合并重复的区间段。思路:排序区间,然后根据条件进行合并。
public List<Interval> merge(List<Interval> intervals) {if (intervals.size() <= 1) return intervals;intervals.sort((i1, i2) -> {if (i1.start == i2.start) return i1.end - i2.end;return i1.start - i2.start;});List<Interval> result = new ArrayList<>();for (int i = 0; i < intervals.size(); ) {int j, margin = intervals.get(i).end;for (j = i + 1; j < intervals.size(); j++) {if (intervals.get(j).start > margin)break;margin = Math.max(margin, intervals.get(j).end);}result.add(new Interval(intervals.get(i).start, margin));i = j;}return result;}
57. Insert Interval
将一个区间插入到有序区间列表中,若有重复区间则需要做合并。
public List<Interval> insert(List<Interval> intervals, Interval newInterval) {LinkedList<Interval> result = new LinkedList<>();if (intervals == null || intervals.isEmpty()) {result.add(newInterval);return result;}int len = intervals.size(), start, end, j;Interval interval;boolean hasAdded = false;for (int i = 0; i < len; ) {interval = intervals.get(i);if (interval.end < newInterval.start) { // newInterval is right-outsideresult.add(interval);i++;} else if (interval.start > newInterval.end) { // newInterval is left-outsideif (!hasAdded) {result.add(newInterval);hasAdded = true;}result.add(interval);i++;} else {start = Math.min(interval.start, newInterval.start);end = Math.max(interval.end, newInterval.end);for (j = i + 1; j < len; j++) {interval = intervals.get(j);if (interval.start > end) break;end = Math.max(end, interval.end);}result.add(new Interval(start, end));hasAdded = true;i = j;}}if (!hasAdded) result.add(newInterval);return result;}
274. H-Index
计算作者的h-index。思路:对引用次数数组排序,找出至少有h篇论文的引用次数>=h。
public int hIndex(int[] citations) {Arrays.sort(citations);int h = 0;for (int i = citations.length - 1; i >= 0; i--) {if (citations[i] < h + 1) break;h++;}return h;}
275. H-Index II
与上类似,不同在于citations已排序,且是升序。
179. Largest Number
从一串数字中,找出能拼成的最大整数;相当于对整数字符串的排序。
public String largestNumber(int[] nums) {int len = nums.length;String[] strs = new String[len];for (int i = 0; i < len; i++) {strs[i] = String.valueOf(nums[i]);}Arrays.sort(strs, this::compareNum);// special caseif (strs[0].charAt(0) == '0') return "0";StringBuilder builder = new StringBuilder();for (String str : strs) {builder.append(str);}return builder.toString();}// compare two number-stringsprivate int compareNum(String num1, String num2) {String cat1 = num1 + num2;String cat2 = num2 + num1;return cat2.compareTo(cat1);}
349. Intersection of Two Arrays
求解两个数组的交集,并去重。思路:排序两个数组,然后做依次比较,用pre保存上一次添加元素(用于去重)。
public int[] intersection(int[] nums1, int[] nums2) {if (nums1 == null || nums2 == null) return null;Arrays.sort(nums1);Arrays.sort(nums2);int len1 = nums1.length, len2 = nums2.length, pre = 0;boolean hasAdded = false;ArrayList<Integer> common = new ArrayList<>();for (int i = 0, j = 0; i < len1 && j < len2; ) {if (nums1[i] < nums2[j])i++;else if (nums1[i] > nums2[j])j++;else {if (nums1[i] != pre || !hasAdded) {common.add(nums1[i]);pre = nums1[i];hasAdded = true;}i++;j++;}}int[] result = new int[common.size()];for (int i = 0; i < common.size(); i++) {result[i] = common.get(i);}return result;}
350. Intersection of Two Arrays II
同上求交集,不需要做去重。
【LeetCode题解】排序的更多相关文章
- 【LeetCode题解】347_前K个高频元素(Top-K-Frequent-Elements)
目录 描述 解法一:排序算法(不满足时间复杂度要求) Java 实现 Python 实现 复杂度分析 解法二:最小堆 思路 Java 实现 Python 实现 复杂度分析 解法三:桶排序(bucket ...
- [LeetCode 题解] Combination Sum
前言 [LeetCode 题解]系列传送门: http://www.cnblogs.com/double-win/category/573499.html 1.题目描述 Given a se ...
- [LeetCode题解]: Sort Colors
前言 [LeetCode 题解]系列传送门: http://www.cnblogs.com/double-win/category/573499.html 1.题目描述 Given an a ...
- LeetCode:删除排序数组中的重复项||【80】
LeetCode:删除排序数组中的重复项||[80] 题目描述 给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素最多出现两次,返回移除后数组的新长度. 不要使用额外的数组空间,你必须在原 ...
- 【LeetCode题解】二叉树的遍历
我准备开始一个新系列[LeetCode题解],用来记录刷LeetCode题,顺便复习一下数据结构与算法. 1. 二叉树 二叉树(binary tree)是一种极为普遍的数据结构,树的每一个节点最多只有 ...
- leetcode题解-122买卖股票的最佳时期
题目 leetcode题解-122.买卖股票的最佳时机:https://www.yanbinghu.com/2019/03/14/30893.html 题目详情 给定一个数组,它的第 i 个元素是一支 ...
- 【LeetCode题解】3_无重复字符的最长子串(Longest-Substring-Without-Repeating-Characters)
目录 描述 解法一:暴力枚举法(Time Limit Exceeded) 思路 Java 实现 Python 实现 复杂度分析 解法二:滑动窗口(双指针) 思路 Java 实现 Python 实现 复 ...
- 【LeetCode题解】225_用队列实现栈(Implement-Stack-using-Queues)
目录 描述 解法一:双队列,入快出慢 思路 入栈(push) 出栈(pop) 查看栈顶元素(peek) 是否为空(empty) Java 实现 Python 实现 解法二:双队列,入慢出快 思路 入栈 ...
- 【LeetCode题解】232_用栈实现队列(Implement-Queue-using-Stacks)
目录 描述 解法一:在一个栈中维持所有元素的出队顺序 思路 入队(push) 出队(pop) 查看队首(peek) 是否为空(empty) Java 实现 Python 实现 解法二:一个栈入,一个栈 ...
- 【LeetCode题解】844_比较含退格的字符串(Backspace-String-Compare)
目录 描述 解法一:字符串比较 思路 Java 实现 Python 实现 复杂度分析 解法二:双指针(推荐) 思路 Java 实现 Python 实现 复杂度分析 更多 LeetCode 题解笔记可以 ...
随机推荐
- 从源码看集合ArrayList
可能大家都知道,java中的ArrayList类,是一个泛型集合类,可以存储指定类型的数据集合,也知道可以使用get(index)方法通过索引来获取数据,或者使用for each 遍历输出集合中的内容 ...
- CSS 3 过渡效果之jquery 的fadeIn ,fadeOut
.div { visibility: hidden; opacity: 0; transition: visibility 0s linear 0.5s,opacity 0.5s linear; } ...
- 用OC和Swift一起说说二叉树
前言: 一:在计算机科学中,二叉树是每个节点最多有两个子树的树结构.通常子树被称作"左子树"(left subtree)和"右子树"(right subt ...
- Redis从入门到精通
什么是Redis? Redis是非关系型数据库,是一个高性能的key-value数据库,它是开源的,更是免费的. Redis能做什么? 存储数据 Redis的优点有哪些? 1.它支持存储丰富的数据类型 ...
- centOS7 mini配置linux服务器(一)安装centOs7
1. 准备centos-7 (minni镜像) 官网地址http://isoredirect.centos.org/centos/7/isos/x86_64/CentOS-7-x86_64-Minim ...
- Java I/O之NIO概念理解
JDK1.4的java.nio.*包引入了新的Java I/O新类库,其目的在于提高速度.实际上,旧的I/O包已经使用nio重新实现过,以便充分利用这种速度提高,因此即使我们不显式地用nio编码,也能 ...
- Gradle之恋-任务2
由于任务作为Gradle的核心功能模块,多花点精力是值得的,本文继上一篇主要涉及到:任务的执行顺序.为任务添加组和描述.跳过任务.扩展任务属性.定义默认任务. 任务顺序 如果构建(build)不能在清 ...
- mybatis基础,mybatis核心配置文件properties元素
peroperties元素 可外部配置且可动态替换的,既可以在典型的 Java 属性文件中配置,亦可通过 properties 元素的子元素来传递 为dataSource元素配置 <proper ...
- 1011: [HNOI2008]遥远的行星
1011: [HNOI2008]遥远的行星 Time Limit: 10 Sec Memory Limit: 162 MBSec Special JudgeSubmit: 2241 Solved ...
- 基于C#的UDP通信(使用UdpClient实现,包含发送端和接收端)
UDP不属于面向连接的通信,在选择使用协议的时候,选择UDP必须要谨慎.在网络质量令人十分不满意的环境下,UDP协议数据包丢失会比较严重.但是由于UDP的特性:它不属于连接型协议,因而具有资源消耗小, ...