Python 编码错误的本质原因
转载自:https://foofish.net/python-unicode-error.html
不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久的新贵,你一定遇到过UnicodeEncodeError、UnicodeDecodeError 错误,每当遇到错误我们就拿着 encode、decode 函数翻来覆去的转换,有时试着试着问题就解决了,有时候怎么试都没辙,只有借用 Google 大神帮忙,但似乎很少去关心问题的本质是什么,下次遇到类似的问题重蹈覆辙,那么你有没有想过一次性彻底把 Python 字符编码给搞懂呢?
完全理解字符编码 与 Python 的渊源前,我们有必要把一些基础概念弄清楚,虽然有些概念我们每天都在接触甚至在使用它,但并不一定真正理解它。比如:字节、字符、字符集、字符码、字符编码。
字节
字节(Byte)是计算机中数据存储的基本单元,一字节等于一个8位的比特,计算机中的所有数据,不论是保存在磁盘文件上的还是网络上传输的数据(文字、图片、视频、音频文件)都是由字节组成的。
字符
你正在阅读的这篇文章就是由很多个字符(Character)构成的,字符一个信息单位,它是各种文字和符号的统称,比如一个英文字母是一个字符,一个汉字是一个字符,一个标点符号也是一个字符。
字符集
字符集(Character Set)就是某个范围内字符的集合,不同的字符集规定了字符的个数,比如 ASCII 字符集总共有128个字符,包含了英文字母、阿拉伯数字、标点符号和控制符。而 GB2312 字符集定义了7445个字符,包含了绝大部分汉字字符。
字符码
字符码(Code Point)指的是字符集中每个字符的数字编号,例如 ASCII 字符集用 0-127 连续的128个数字分别表示128个字符,例如 "A" 的字符码编号就是65。
字符编码
字符编码(Character Encoding)是将字符集中的字符码映射为字节流的一种具体实现方案,常见的字符编码有 ASCII 编码、UTF-8 编码、GBK 编码等。某种意义上来说,字符集与字符编码有种对应关系,例如 ASCII 字符集对应 有 ASCII 编码。ASCII 字符编码规定使用单字节中低位的7个比特去编码所有的字符。例如"A" 的编号是65,用单字节表示就是0×41,因此写入存储设备的时候就是b'01000001'。
编码、解码
编码的过程是将字符转换成字节流,解码的过程是将字节流解析为字符。
理解了这些基本的术语概念后,我们就可以开始讨论计算机的字符编码的演进过程了。
从 ASCII 码说起
说到字符编码,要从计算机的诞生开始讲起,计算机发明于美国,在英语世界里,常用字符非常有限,26个字母(大小写)、10个数字、标点符号、控制符,这些字符在计算机中用一个字节的存储空间来表示绰绰有余,因为一个字节相当于8个比特位,8个比特位可以表示256个符号。于是美国国家标准协会ANSI制定了一套字符编码的标准叫 ASCII(American Standard Code for Information Interchange),每个字符都对应唯一的一个数字,比如字符 "A" 对应数字是65,"B" 对应 66,以此类推。最早 ASCII 只定义了128个字符编码,包括96个文字和32个控制符号,一共128个字符只需要一个字节的7位就能表示所有的字符,因此 ASCII 只使用了一个字节的后7位,剩下最高位1比特被用作一些通讯系统的奇偶校验。下图就是 ASCII 码字符编码的十进制、二进制和字符的对应关系表

扩展的 ASCII:EASCII(ISO/8859-1)
然而计算机慢慢地普及到其他西欧地区时,发现还有很多西欧字符是 ASCII 字符集中没有的,显然 ASCII 已经没法满足人们的需求了,好在 ASCII 字符只用了字节的7位 0×00~0x7F 共128个字符,于是他们在 ASCII 的基础上把原来的7位扩充到8位,把0×80-0xFF这后面的128个数字利用起来,叫 EASCII ,它完全兼容ASCII,扩展出来的符号包括表格符号、计算符号、希腊字母和特殊的拉丁符号。然而 EASCII 时代是一个混乱的时代,各个厂家都有自己的想法,大家没有统一标准,他们各自把最高位按照自己的标准实现了自己的一套字符编码标准,比较著名的就有 CP437, CP437 是 始祖IBM PC、MS-DOS使用的字符编码,如下图:

众多的 ASCII 扩充字符集之间互不兼容,这样导致人们无法正常交流,例如200在CP437字符集表示的字符是 È ,在 ISO/8859-1 字符集里面显示的就是 ╚,于是国际标准化组织(ISO)及国际电工委员会(IEC)联合制定的一系列8位字符集的标准ISO/8859-1(Latin-1),它继承了 CP437 字符编码的128-159之间的字符,所以它是从160开始定义的,ISO-8859-1在 CP437 的基础上重新定义了 160~255之间的字符。
多字节字符编码 GBK
ASCII 字符编码是单字节编码,计算机进入中国后面临的一个问题是如何处理汉字,对于拉丁语系国家来说通过扩展最高位,单字节表示所有的字符已经绰绰有余,但是对于亚洲国家来说一个字节就显得捉襟见肘了。于是中国人自己弄了一套叫 GB2312 的双字节字符编码,又称GB0,1981 由中国国家标准总局发布。GB2312 编码共收录了6763个汉字,同时他还兼容 ASCII,GB 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率,不过 GB2312 还是不能100%满足中国汉字的需求,对一些罕见的字和繁体字 GB2312 没法处理,后来就在GB2312的基础上创建了一种叫 GBK 的编码,GBK 不仅收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。同样 GBK 也是兼容 ASCII 编码的,对于英文字符用1个字节来表示,汉字用两个字节来标识。
Unicode 的问世
GBK仅仅只是解决了我们自己的问题,但是计算机不止是美国人和中国人用啊,还有欧洲、亚洲其他国家的文字诸如日文、韩文全世界各地的文字加起来估计也有好几十万,这已经大大超出了ASCII 码甚至GBK 所能表示的范围了,虽然各个国家可以制定自己的编码方案,但是数据在不同国家传输就会出现各种各样的乱码问题。如果只用一种字符编码就能表示地球甚至火星上任何一个字符时,问题就迎刃而解了。是它,是它,就是它,我们的小英雄,统一联盟国际组织提出了Unicode 编码,Unicode 的学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。它为世界上每一种语言的每一个字符定义了一个唯一的字符码,Unicode 标准使用十六进制数字表示,数字前面加上前缀 U+,比如字母『A』的Unicode编码是 U+0041,汉字『中』的Unicode 编码是U+4E2D
Unicode有两种格式:UCS-2和UCS-4。UCS-2就是用两个字节编码,一共16个比特位,这样理论上最多可以表示65536个字符,不过要表示全世界所有的字符显示65536个数字还远远不过,因为光汉字就有近10万个,因此Unicode4.0规范定义了一组附加的字符编码,UCS-4就是用4个字节(实际上只用了31位,最高位必须为0)。理论上完全可以涵盖一切语言所用的符号。
Unicode 的局限
但是 Unicode 有一定的局限性,一个 Unicode 字符在网络上传输或者最终存储起来的时候,并不见得每个字符都需要两个字节,比如字符“A“,用一个字节就可以表示的字符,偏偏还要用两个字节,显然太浪费空间了。
第二问题是,一个 Unicode 字符保存到计算机里面时就是一串01数字,那么计算机怎么知道一个2字节的Unicode字符是表示一个2字节的字符呢,例如“汉”字的 Unicode 编码是 U+6C49,我可以用4个ascii数字来传输、保存这个字符;也可以用utf-8编码的3个连续的字节E6 B1 89来表示它。关键在于通信双方都要认可。因此Unicode编码有不同的实现方式,比如:UTF-8、UTF-16等等。Unicode就像英语一样,做为国与国之间交流世界通用的标准,每个国家有自己的语言,他们把标准的英文文档翻译成自己国家的文字,这是实现方式,就像utf-8。
具体实现:UTF-8
UTF-8(Unicode Transformation Format)作为 Unicode 的一种实现方式,广泛应用于互联网,它是一种变长的字符编码,可以根据具体情况用1-4个字节来表示一个字符。比如英文字符这些原本就可以用 ASCII 码表示的字符用UTF-8表示时就只需要一个字节的空间,和 ASCII 是一样的。对于多字节(n个字节)的字符,第一个字节的前n为都设为1,第n+1位设为0,后面字节的前两位都设为10。剩下的二进制位全部用该字符的unicode码填充。

以『好』为例,『好』对应的 Unicode 是597D,对应的区间是 0000 0800--0000 FFFF,因此它用 UTF-8 表示时需要用3个字节来存储,597D用二进制表示是: 0101100101111101,填充到 1110xxxx 10xxxxxx 10xxxxxx 得到 11100101 10100101 10111101,转换成16进制是 e5a5bd,因此『好』的 Unicode 码 U+597D 对应的 UTF-8 编码是 "E5A5BD"。你可以用 Python 代码来验证:
>>> a = u"好"
>>> a
u'\u597d'
>>> b = a.encode('utf-8')
>>> len(b)
3
>>> b
'\xe5\xa5\xbd'
现在总算把理论说完了。再来说说 Python 中的编码问题。Python 的诞生时间比 Unicode 要早很多,Python2 的默认编码是ASCII,正因为如此,才导致很多的编码问题。
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
所以在 Python2 中,源代码文件必须显示地指定编码类型,否则但凡代码中出现有中文就会报语法错误
# coding=utf-8
或者是:
# -*- coding: utf-8 -*-
Python2 字符类型
在 python2 中和字符串相关的数据类型有 str 和 unicode 两种类型,它们继承自 basestring,而 str 类型的字符串的编码格式可以是 ascii、utf-8、gbk等任何一种类型。
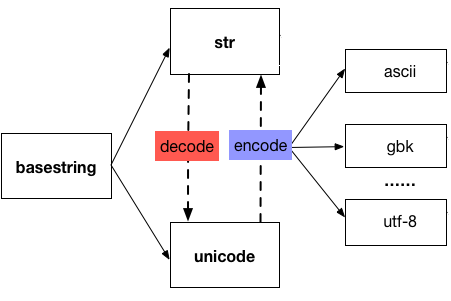
图片来源:http://funhacks.net/2016/11/25/character_encoding/
对于汉字『好』,用 str 表示时,它对应的 utf-8 编码 是'\xe5\xa5\xbd',对应的 gbk 编码是 '\xba\xc3',而用 unicode 表示时,他对应的符号就是u'\u597d',与u"好" 是等同的。
str 与 unicode 的转换
在 Python 中 str 和 unicode 之间是如何转换的呢?这两种类型的字符串之间的转换就是靠decode 和 encode 这两个函数。encode 负责将unicode 编码成指定的字符编码,用于存储到磁盘或传输到网络中。而 decode 方法是根据指定的编码方式解码后在应用程序中使用。
#从unicode转换到str用 encode >>> b = u'好'
>>> c = b.encode('utf-8')
>>> type(c)
<type 'str'>
>>> c
'\xe5\xa5\xbd' #从str类型转换到unicode用decode >>> d = c.decode('utf-8')
>>> type(d)
<type 'unicode'>
>>> d
u'\u597d'
UnicodeXXXError 错误的原因
在字符编码转换操作时,遇到最多的问题就是 UnicodeEncodeError 和 UnicodeDecodeError 错误了,这些错误的根本原因在于 Python2 默认是使用 ascii 编码进行 decode 和 encode 操作,例如:
CASE 1
>>> s = '你好'
>>> s.decode()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
当把 s 转换成 unicode 类型的字符串时,decode 方法默认使用 ascii 编码进行解码,而 ascii 字符集中根本就没有中文字符『你好』,所以就出现了 UnicodeDecodeError,正确的方式是显示地指定 UTF-8 字符编码。
>>> s.decode('utf-8')
u'\u4f60\u597d'
同样地道理,对于 encode 操作,把 unicode字符串转换成 str类型的字符串时,默认也是使用 ascii 编码进行编码转换的,而 ascii 字符集找不到中文字符『你好』,于是就出现了UnicodeEncodeError 错误。
>>> a = u'你好'
>>> a.encode()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
CASE 2
str 类型与 unicode 类型的字符串混合使用时,str 类型的字符串会隐式地将 str 转换成 unicode字符串,如果 str字符串是中文字符,那么就会出现UnicodeDecodeError 错误,因为 python2 默认会使用 ascii 编码来进行 decode 操作。
>>> s = '你好' # str类型
>>> y = u'python' # unicode类型
>>> s + y # 隐式转换,即 s.decode('ascii') + u
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
正确地方式是显示地指定 UTF-8 字符编码进行解码
>>> s.decode('utf-8') +y
u'\u4f60\u597dpython'
乱码
所有出现乱码的原因都可以归结为字符经过不同编码解码在编码的过程中使用的编码格式不一致,比如:
# encoding: utf-8 >>> a='好'
>>> a
'\xe5\xa5\xbd'
>>> b=a.decode("utf-8")
>>> b
u'\u597d'
>>> c=b.encode("gbk")
>>> c
'\xba\xc3'
>>> print c
��
utf-8编码的字符‘好’占用3个字节,解码成Unicode后,如果再用gbk来解码后,只有2个字节的长度了,最后出现了乱码的问题,因此防止乱码的最好方式就是始终坚持使用同一种编码格式对字符进行编码和解码操作。

Python 编码错误的本质原因的更多相关文章
- Python 编码错误解决方案
Python 编码错误解决方案 Python UnicodeDecodeError: 'ascii' codec can't decode byte 0xe5 in position 7: ordin ...
- python编码错误
初学python,遇到的最难忘的坑没有之一.这个问题起码困扰了我一周.在我写了一段代码之后经常遇见这样的报错. 本质原因是我用的python2,在编码流派中python2是比较奇葩的一派,不随大流.所 ...
- 记一次python编码错误
摘要: 断断续续写python一段时间了,让我说python最令我头疼的问题,莫过于编码问题.最近做大论文,使用python再次出现编码报错.错误如下: "UnicodeEncodeErro ...
- Python编码错误的解决办法SyntaxError: Non-ASCII character '\xe5' in file
[现象] 在编写Python时,当使用中文输出或注释时运行脚本,会提示错误信息: SyntaxError: Non-ASCII character '\xe5' in file ******* [原因 ...
- python编码错误的解决办法 SyntaxError: Non-ASCII character '\xe5' in file
[提出问题]. 在编写Python时,当使用中文输出或注释时运行脚本,会提示错误信息: SyntaxError: Non-ASCII character '\xe5' in file ******* ...
- RT-thread 利用Scons 工具编译提示python编码错误解决办法
错误信息: scons: Reading SConscript files ...UnicodeDecodeError: 'ascii' codec can't decode byte 0xbd in ...
- [Python]编译错误:编码错误问题(SyntaxError: (unicode error) )
1 错误信息 python文件 1 #coding:utf-8 2 3 class Clz: 4 def func(filePath): 5 """ 6 func 7 - ...
- python运行显示编码错误
python中运行显示编码错误一般有2种原因: 编码与译码的方式不一致 在编写Python时,当使用中文输出或注释时运行脚本,会提示错误信息: SyntaxError: Non-ASCII chara ...
- Python编码(encode)和解码(Decode)常见的两个错误
项目地址:https://git.io/pytips 0x07 和 0x08 分别介绍了 Python 中的字符串类型(str)和字节类型(byte),以及 Python 编码中最常见也是最顽固的两个 ...
随机推荐
- Elasticsearch中的相似度模型(原文:Similarity in Elasticsearch)
原文链接:https://www.elastic.co/blog/found-similarity-in-elasticsearch 原文 By Konrad Beiske 翻译 By 高家宝 译者按 ...
- 开启MongoDB客户端访问控制
参考官方文档:https://docs.mongodb.org/v2.6/tutorial/enable-authentication/ 基于版本:MongoDB 2.6 概览 在MongoDB数据实 ...
- struts2总体介绍
这篇博客开始将总结一下有关框架的知识,在开发中合适的利用框架会使我们的开发效率大大提高.当今比较流行的开源框架: 关注数据流程的MVC框架 (Struts1/2, WebWork, Spring MV ...
- Brief introduction to Cassandra 【Cassandra简介】
From wikipedia https://en.wikipedia.org/wiki/CAP_theorem In theoretical computer science, the CAP t ...
- 编写自己的一个简单的web容器(二)
昨天我们已经能够确定浏览器的请求能够被我们自己编写的服务类所接收并且我们服务类响应的数据也能够正常发送到浏览器客户端,那么我们今天要解决的问题就是让我们的数据能够被浏览器识别并解析. Http(Htt ...
- Linux学习第三步(Centos7安装mysql5.7数据库)
版本:mysql-5.7.16-1.el7.x86_64.rpm-bundle.tar 前言:在linux下安装mysql不如windows下面那么简单,但是也不是很难.本文向大家讲解了如何在Cent ...
- Jmeter 初学(一)
Jmeter 目前属于比较流行的测试工具,即可做自动化测试也可以做性能测试,而且比较方便. 环境准备: Jmeter 运行环境需要跑在java环境,首先需要安装一下java的环境,由于我目前使用的Jm ...
- 更改maven中央仓库
前言 1.由于原生的中央仓库 http://repo1.maven.org/maven2/,有一些包不在里面,目前流行的仓库有 http://mvnrepository.com/ 2.找出连接 2.1 ...
- org.hibernate.LazyInitializationException...no session or session was closed
org.hibernate.LazyInitializationException:failed to lazily initialize a collection of role:cn.its.oa ...
- poi合并单元格同时导出excel
poi合并单元格同时导出excel POI进行跨行需要用到对象HSSFSheet对象,现在就当我们程序已经定义了一个HSSFSheet对象sheet. 跨第1行第1个到第2个单元格的操作为 sheet ...