kafka 知识点整理
一个partition只能被同一个消费组内一个消费者消费,所以在同一时间点上,订阅到同一个partition的consumer必然属于不同的Consumer Group.
因此,如果设置的partition的数量小于consumer的数量,就会有消费者消费不到数据。所以,推荐partition的数量一定要大于同时运行的consumer的数量
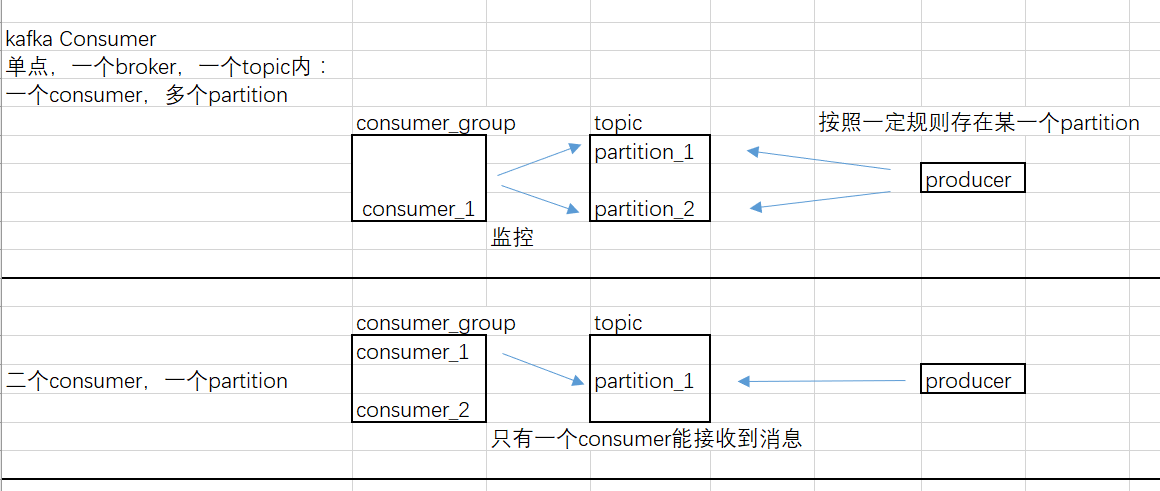
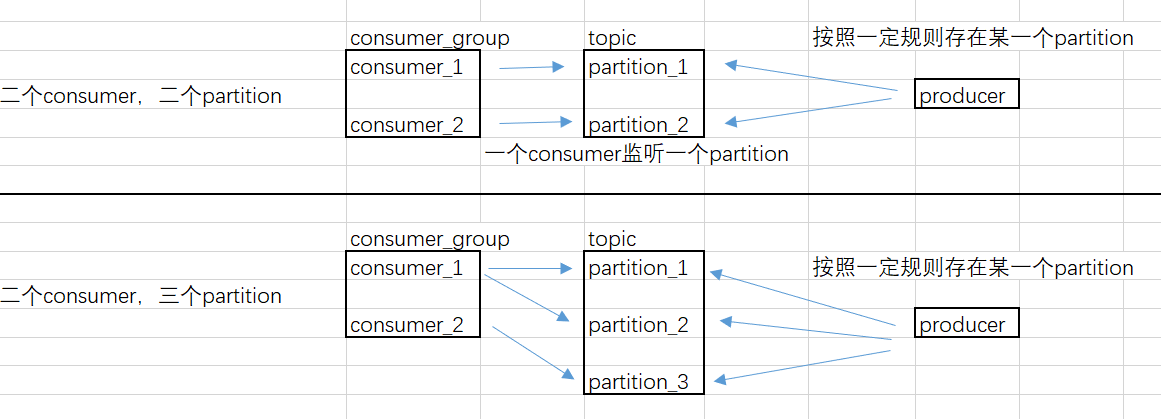
Consumer Group与Consumer的关系是动态维护的:
当一个Consumer 进程挂掉 或者是卡住时,该consumer所订阅的partition会被重新分配到该group内的其它的consumer上。当一个consumer加入到一个consumer group中时,同样会从其它的consumer中分配出一个或者多个partition 到这个新加入的consumer。当启动一个Consumer时,会指定它要加入的group,使用的是配置项:group.id。
为了维持Consumer 与 Consumer Group的关系,需要Consumer周期性的发送heartbeat到coordinator(协调者,在早期版本,以zookeeper作为协调者。后期版本则以某个broker作为协调者)。当Consumer由于某种原因不能发Heartbeat到coordinator时,并且时间超过session.timeout.ms时,就会认为该consumer已退出,它所订阅的partition会分配到同一group 内的其它的consumer上。而这个过程,被称为rebalance。
poll 方法
Consumer读取partition中的数据是通过调用发起一个fetch请求来执行的。而从KafkaConsumer来看,它有一个poll方法。但是这个poll方法只是可能会发起fetch请求。原因是:Consumer每次发起fetch请求时,读取到的数据是有限制的,通过配置项max.partition.fetch.bytes来限制的。而在执行poll方法时,会根据配置项个max.poll.records来限制一次最多pool多少个record.
那么就可能出现这样的情况: 在满足max.partition.fetch.bytes限制的情况下,假如fetch到了100个record,放到本地缓存后,由于max.poll.records限制每次只能poll出15个record。那么KafkaConsumer就需要执行7次才能将这一次通过网络发起的fetch请求所fetch到的这100个record消费完毕。其中前6次是每次pool中15个record,最后一次是poll出10个record。
在consumer中,还有另外一个配置项:max.poll.interval.ms ,它表示最大的poll数据间隔,如果超过这个间隔没有发起pool请求,但heartbeat仍旧在发,就认为该consumer处于 livelock状态。就会将该consumer退出consumer group。所以为了不使Consumer 自己被退出,Consumer 应该不停的发起poll(timeout)操作。而这个动作 KafkaConsumer Client是不会帮我们做的,这就需要自己在程序中不停的调用poll方法了。
offset存储
在kafka 0.9版本之后,kafka为了降低zookeeper的io读写,减少network data transfer,也自己实现了在kafka server上存储consumer,topic,partitions,offset信息将消费的 offset 迁入到了 Kafka 一个名为 __consumer_offsets 的Topic中。
kafka高可用
为了保证kafka的高可用(当leader节点挂了之后,kafka依然能提供服务)kafka提供了备份的功能。这个备份是针对partition的。
每个partition会选举一个Leader,其它Replicas作为Follower,只有Leader负责数据读写,Follower只向Leader顺序Fetch数据(N条通路)
通过kafka manager可以很直观看到,如下:
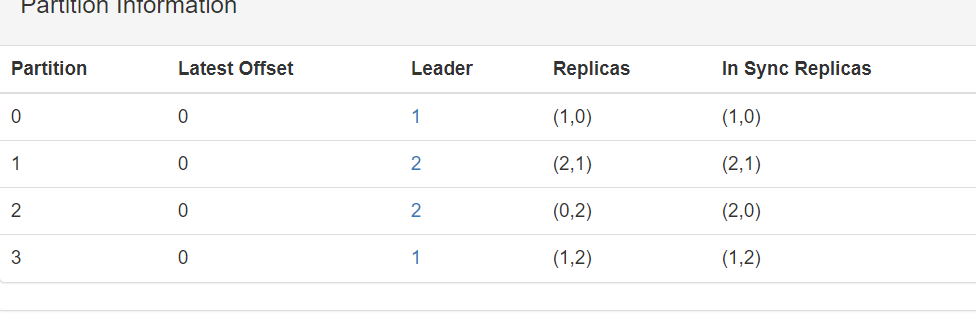
Partition 1,Leader是broker 1,其它Replicas是Follower。
kafka 知识点整理的更多相关文章
- kafka知识点整理总结
kafka知识点整理总结 只不过是敷衍 2017-11-22 21:39:59 kafka知识点整理总结,以备不时之需. 为什么要使用消息系统: 解耦 并行 异步通信:想向队列中放入多少消息就放多少, ...
- 大数据 -- kafka学习笔记:知识点整理(部分转载)
一 为什么需要消息系统 1.解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险.许多 ...
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- [Big Data - Kafka] kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- ACM个人零散知识点整理
ACM个人零散知识点整理 杂项: 1.输入输出外挂 //读入优化 int 整数 inline int read(){ int x=0,f=1; char ch=getchar(); while(ch& ...
- Android 零散知识点整理
Android 零散知识点整理 为什么Android的更新试图操作必须在主线程中进行? 这是因为Android系统中的视图组件并不是线程安全的.通常应该让主线程负责创建.显示和更新UI,启动子线程,停 ...
- vue前端面试题知识点整理
vue前端面试题知识点整理 1. 说一下Vue的双向绑定数据的原理 vue 实现数据双向绑定主要是:采用数据劫持结合发布者-订阅者模式的方式,通过 Object.defineProperty() 来劫 ...
- kafka知识点
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- JSP页面开发知识点整理
刚学JSP页面开发,把知识点整理一下. ----------------------------------------------------------------------- JSP语法htt ...
随机推荐
- hackinglab 基础关 writeup
地址:http://hackinglab.cn/ 基础关 key在哪里? 很简单,点击过关地址,在新打开的网页中查看网页源代码就能在 HTML 注释中发现 key 再加密一次你就得到key啦~ 明文加 ...
- hdu-1281.棋盘游戏(二分图匹配 + 二分图关键点查询)
棋盘游戏 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submis ...
- 推荐 33 个 IDEA 最牛配置,写代码太爽了!
作者:琦彦 blog.csdn.net/fly910905/article/details/77868300 1.设置maven 1.在File->settings->搜索maven 2. ...
- SSM商城系统开发笔记-配置01-web.xml
先占坑 慢慢填, 商城系统使用主体框架:Spring + Spring MVC + Mybatis 其他框架: 日志: slf4j + logback <!DOCTYPE web-app PUB ...
- Handle Refresh Token Using ASP.NET Core 2.0 And JSON Web Token
来源: https://www.c-sharpcorner.com/article/handle-refresh-token-using-asp-net-core-2-0-and-json-web ...
- 使用jQuery实现Socket客户端
摘于抄书web前端开发 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> & ...
- v-cloak解决Vue双大括号闪烁问题
相信不少人和我一样,初次查看一个技术的文档的时候,知识吸收的很慢,因为对这个技术的不熟悉导致不清楚各种操作的应用场景,当我意识到这件事之后,我决定换种学习思路,即以实战为主,卡壳就查文档,会对这个技术 ...
- Hibernate初始化创建SessionFactory,Session,关闭SessonFactory,session
1.hibernate.cfg.xml <?xml version='1.0' encoding='UTF-8'?> <!DOCTYPE hibernate-configuratio ...
- [web 安全]逻辑漏洞之密码重置
原文:http://wooyun.jozxing.cc/static/drops/web-5048.html 密码找回逻辑一.用户凭证(密码找回的凭证太弱,暴力破解)1.当当网任意用户密码修改漏洞(h ...
- Tenka1 Programmer Contest D - Crossing
链接 Tenka1 Programmer Contest D - Crossing 给定\(n\),要求构造\(k\)个集合\({S_k}\),使得\(1\)到\(n\)中每个元素均在集合中出现两次, ...