大数据学习笔记之初识Hadoop
1、Hadoop概述
1.1 Hadoop名字的由来
- Hadoop项目作者的孩子给一个棕黄色的大象样子的填充玩具的命名
- Hadoop的官网:http://hadoop.apache.org 。
1.2 Hadoop介绍
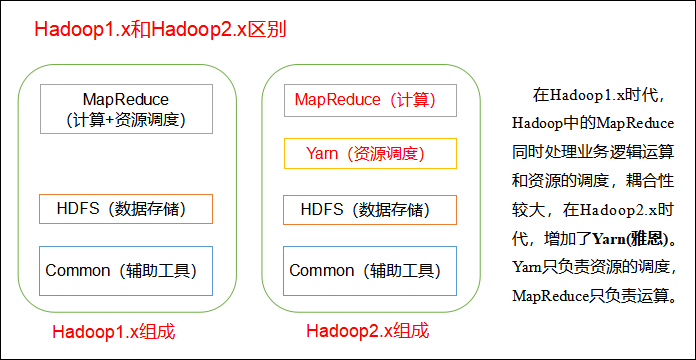
Hadoop是Apache的一个顶级项目、是开源的、分布式存储+分布式计算平台;它由以下几个模块构成:
Hadoop Common: 这是支持hadoop其他模块的通用工具模块
Hadoop Distributed File System(HDFS):分布式文件系统
Hadoop YARN: 统一资源管理和任务调度
Hadoop MapReduce:基于yarn系统的分布式计算框架

1.3 Hadoop能做什么
搭建大型数据仓库,PB级数据的存储、处理、分析、统计等业务,如:智能商业、日志分析、搜索引擎、数据挖掘等场景。
2、Hadoop核心组件
2.1 HDFS(分布式文件系统)
- 源自于Google的GFS论文,论文发表于2003年10月
- HDFS是GFS的克隆版
- HDFS特点:扩展性&容错性&海量数据存储
- 将文件切分成指定大小的数据块并以多副本的存储在多个机器上
- 数据切分、多副本、容错等操作对用户是透明的
2.2 YARN(资源调度系统)
- YARN: Yet Another Resource Negotiator
- 负责整个集群资源的管理和调度
- YARN特点:扩展性&容错性&多框架资源统一调度
2.3 MapReduce(分布式计算框架)
- 源自于Google的MapReduce论文。论文发表于2004年12月
- MapReduce是Google MapReduce的克隆版
- MapReduce特点: 扩展性&容错性&海量数据离线处理
3、Hadoop优势

(1)、高可靠性
- 数据存储:数据块多副本
- 数据计算: 重新调度作业计算
(2)、高扩展性
- 存储/计算资源不够时,可以横向的线性扩展机器
- 一个集群中可以包含数以千计的节点
(3)、其他
- 存储在廉价机器上,降低成本
- 成熟的生态圈
4、Hadoop生态系统
4.1 狭义Hadoop VS 广义Hadoop
- 狭义Hadoop:指的是一个适合大数据分布式存储(HDFS)、分布式计算(MapReduce)和资源调度(YARN)平台,即传统意义上的Hadoop。
- 广义Hadoop:指的是整个Hadoop生态系统,Hadoop生态系统是一个很庞大的概念,Hadoop是其中最重要最基础的一部分;生态系统中的每一个子系统只能解决某一特定的问题域(甚至可能很窄),不搞统一型的一个全能系统,而是小而精的多个小系统。
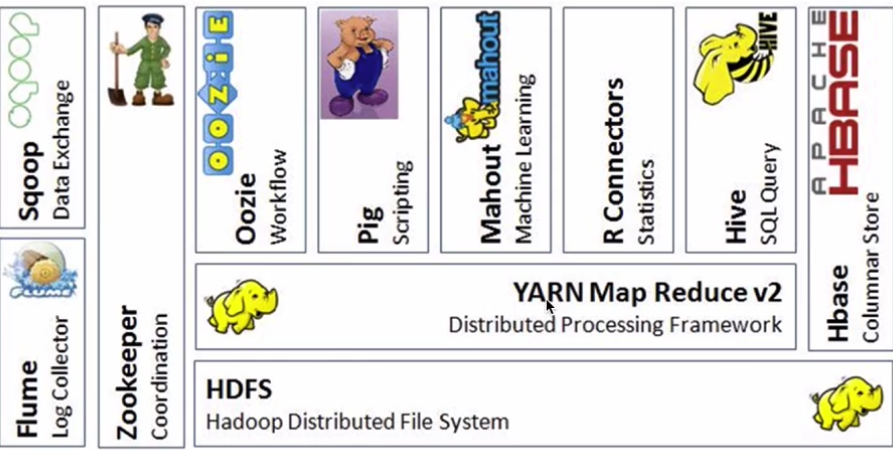
- Hive:数据仓库
- R:数据分析
- Mahout:机器学习库
- pig:脚本语言,跟Hive类似
- Oozie:工作流引擎,管理作业执行顺序
- Zookeeper:用户无感知,主节点挂掉选择从节点作为主的
- Flume:日志收集框架
- Sqoop:数据交换框架,例如:关系型数据库与HDFS之间的数据交换
- Hbase : 海量数据中的查询,相当于分布式文件系统中的数据库
4.2 Hadoop生态系统的特点
- 开源、社区活跃
- 囊括了大数据处理的方方面面
- 成熟的生态圈
5、 Hadoop常用发行版本和和选型
- Apcahe Hadoop:存在jar包冲突的问题,一般只用于学习;
- CDH(Cloudera Distributed Hadoop):商业版,不存在jar冲突问题,配置简单、文档详细,具有容易升级的优点,生产环境中大多选择该版本,缺点是代码不开源,下载地址;
- HDP(Hortonworks Data Platform):存在安装升级和删除节点困难的问题,一般也应用于商业场景。
1、Apache Hadoop
官网地址:http://hadoop.apache.org/releases.html
下载地址:https://archive.apache.org/dist/hadoop/common/2、Cloudera Hadoop
官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/- (1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
- (2)
2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support。 - (3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
- (4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
- (5)Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
3、Hortonworks Hadoop
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform- (1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
- (2)
公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。 - (3)雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
- (4)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
- (5)HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
- (6)Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的Microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
大数据学习笔记之初识Hadoop的更多相关文章
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习笔记——Java篇之集合框架(ArrayList)
Java集合框架学习笔记 1. Java集合框架中各接口或子类的继承以及实现关系图: 2. 数组和集合类的区别整理: 数组: 1. 长度是固定的 2. 既可以存放基本数据类型又可以存放引用数据类型 3 ...
- 大数据学习笔记——Linux完整部署篇(实操部分)
Linux环境搭建完整操作流程(包含mysql的安装步骤) 从现在开始,就正式进入到大数据学习的前置工作了,即Linux的学习以及安装,作为运行大数据框架的基础环境,Linux操作系统的重要性自然不言 ...
- 大数据学习笔记之Hadoop(一):Hadoop入门
文章目录 大数据概论 一.大数据概念 二.大数据的特点 三.大数据能干啥? 四.大数据发展前景 五.企业数据部的业务流程分析 六.企业数据部的一般组织结构 Hadoop(入门) 一 从Hadoop框架 ...
- 大数据学习笔记1-大数据处理架构Hadoop
Hadoop:一个开源的.可运行于大规模集群上的分布式计算平台.实现了MapReduce计算模型和分布式文件系统HDFS等功能,方便用户轻松编写分布式并行程序. Hadoop生态系统: HDFS:Ha ...
- 大数据学习笔记——Hadoop编程实战之Mapreduce
Hadoop编程实战——Mapreduce基本功能实现 此篇博客承接上一篇总结的HDFS编程实战,将会详细地对mapreduce的各种数据分析功能进行一个整理,由于实际工作中并不会过多地涉及原理,因此 ...
- 大数据学习笔记之Hadoop(三):MapReduce&YARN
文章目录 一 MapReduce概念 1.1 为什么要MapReduce 1.2 MapReduce核心思想 1.3 MapReduce进程 1.4 MapReduce编程规范(八股文) 1.5 Ma ...
- 大数据学习笔记——Java篇之IO
IO学习笔记整理 1. File类 1.1 File对象的三种创建方式: File对象是一个抽象的概念,只有被创建出来之后,文件或文件夹才会真正存在 注意:File对象想要创建成功,它的目录必须存在! ...
- 大数据初级笔记二:Hadoop入门之Hadoop集群搭建
Hadoop集群搭建 把环境全部准备好,包括编程环境. JDK安装 版本要求: 强烈建议使用64位的JDK版本,这样的优势在于JVM的能够访问到的最大内存就不受限制,基于后期可能会学习到Spark技术 ...
随机推荐
- pyinstaller-python->exe
pip install pyinstaller. pyinstaller -F /home/base64_decode.py https://www.imooc.com/article/26772 h ...
- Tensorflow 教程系列 | 莫烦Python
Tensorflow 简介 1.1 科普: 人工神经网络 VS 生物神经网络 1.2 什么是神经网络 (Neural Network) 1.3 神经网络 梯度下降 1.4 科普: 神经网络的黑盒不黑 ...
- UUID工具类及使用
1.工具类: package UUIdtest; import java.util.UUID; public class UUIDUtil { public static String getUUID ...
- 学习C++的意义
1,常见的观点: 1,并不是每个应届生都有机会写操作系统和驱动程序: 2,嵌入式系统也是软家系统,只不过是软件在出厂的时候已经被烧写到硬件中了,用户没有办法修改软件而已,因此嵌入式系统也是软件系统,C ...
- Node.js+koa2
const Koa = require('koa') const app = new Koa() const bodyParser = require('koa-bodyparser') app.us ...
- 自我笔记,Rides介绍
Redis是一个key-value存储系统,和Memccached类似,支持存储的value类型相对更多,很大程度上补偿memcached这类key-value存储的不足 他提供了Java,c/c++ ...
- Linux基础命令四
iptables iptables -F:关闭防火墙 crontab -l查看定时任务 crontab -e :编辑定时任务 log日志相关: ls /var/log:查看日志 du -sh /v ...
- 【 React - 1/100 】React绑定事件this指向问题--改变state中的值
/** * 报错: * Cannot read property 'setState' of undefined * 原因: this指向不一致.btnAddCount中的this 和render中的 ...
- es6 generator函数的异步编程
es6 generator函数,我们都知道asycn和await是generator函数的语法糖,那么genertaor怎么样才能实现asycn和await的功能呢? 1.thunk函数 将函数 ...
- 防抖&节流
使用的原因 在前端开发当中有一部分的用户行为会频繁操作触发事件执行,而对于DOM操作,资源加载等耗费性能的处理,很可能导致页面卡顿,甚至浏览器崩溃,函数节流和防抖就是解决类似需求应运而生的 节流 预定 ...