[小试牛刀]部署在IDEA的JFinal 3.0 demo
- 进入JFinal 极速开发市区:http://www.jfinal.com/
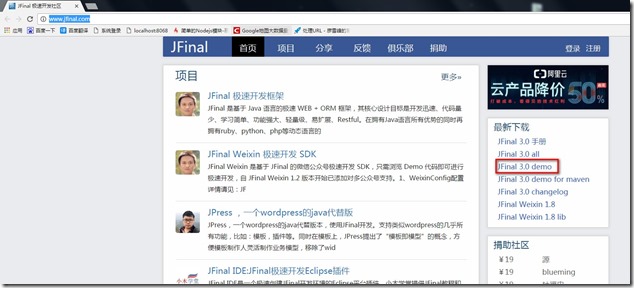
- 如上图,点击右边的最新下载:JFinal 3.0 demo - 此过程跳过注册\登录过程, 进入到如下,下载
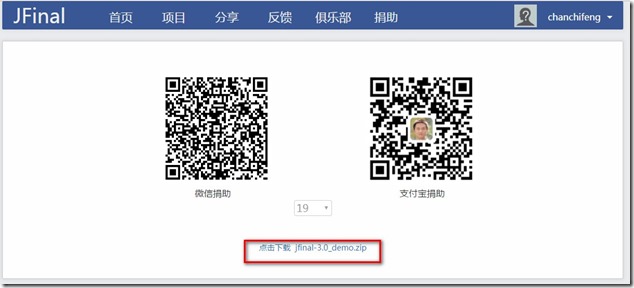
- 下载并解压到自己指定的目录下,如下

- 打开IDEA ,进入如下界面:
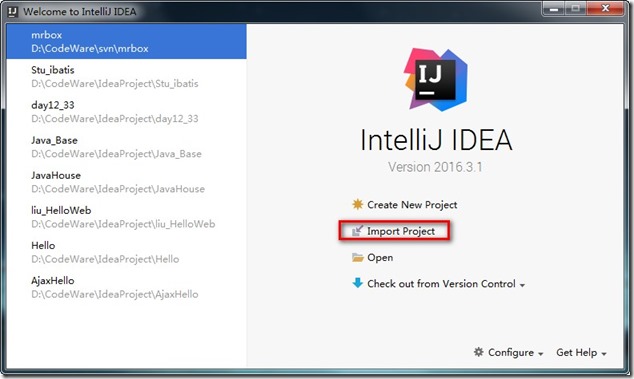
- 点击Import Project
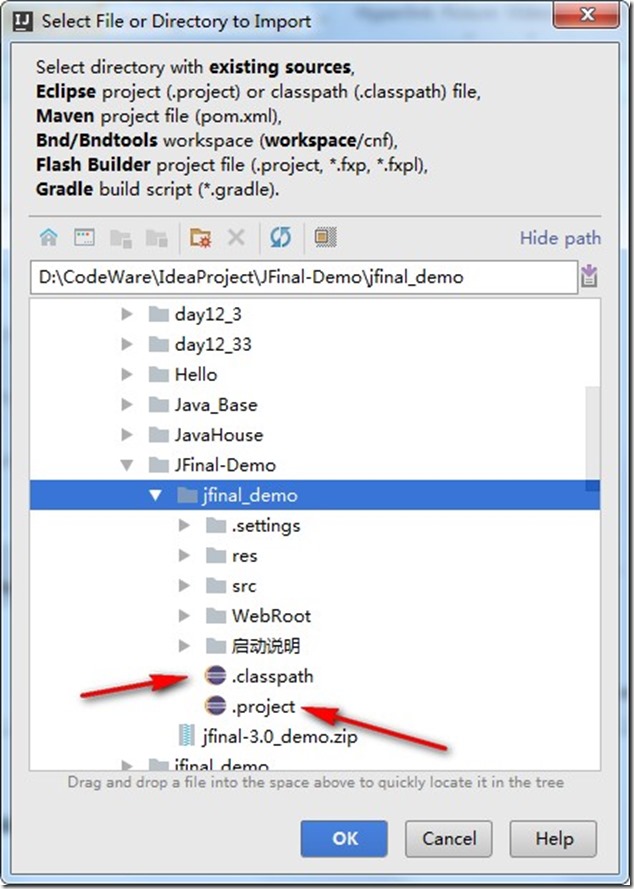
- 在导入项目的路径的时候,IDEA自动帮我们识别到该项目是在Eclipse下创作的。此时选中jfinal_demo 文件夹则可。点击OK。
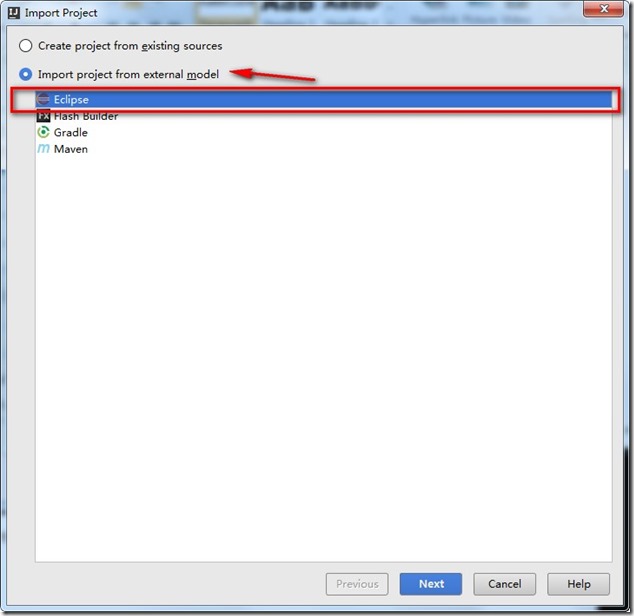
- 点击Import project from external model – Eclipse (这一步很主要!),点击next.
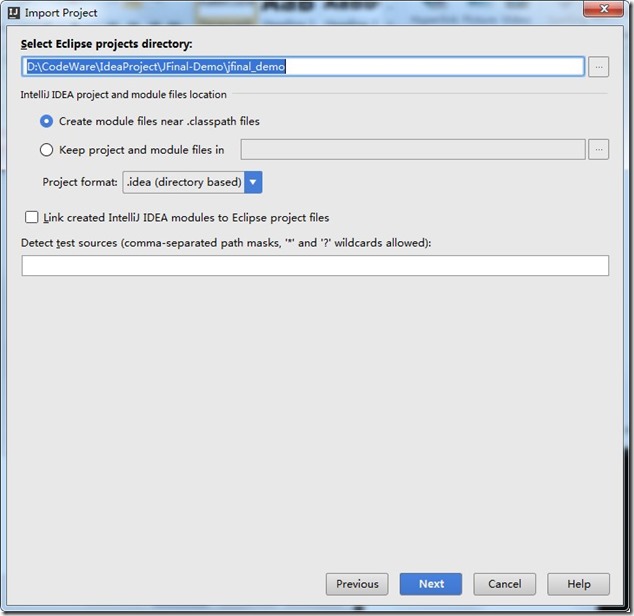
- 再点击next .
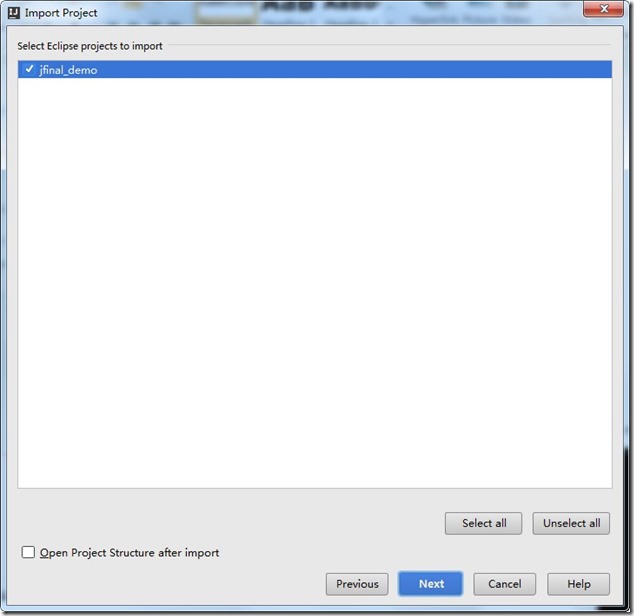
- 再点击next.
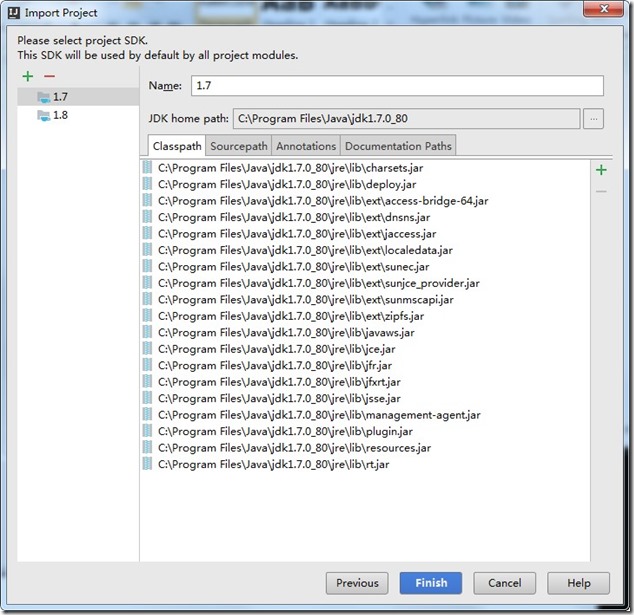
- 选择jdk版本,点击Finish.
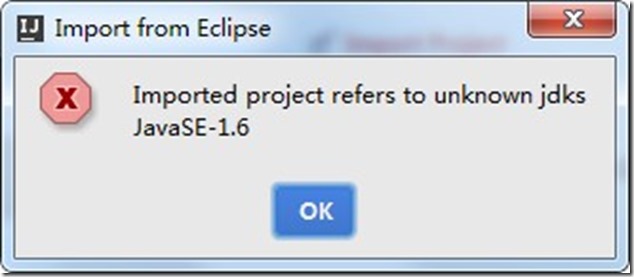
- 然后会弹出一个错误,这报错是我选择jdk1.7与项目1.6不一致而出现的,点击OK。
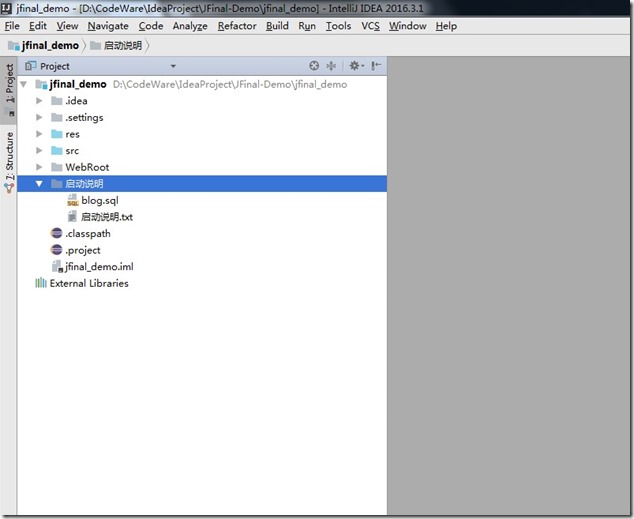
- 进入了熟悉的界面,我们看到项目有”启动说明”,如果你按照”启动说明.txt”,来启动的,就忽略下面所有步骤。
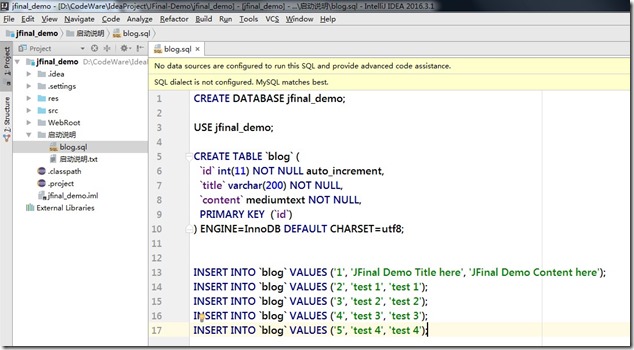
- 先打开 启动说明 下的blog.sql,文件内容如上:

- 把SQL语句拉到Navicat上来,执行,完成后,就创建好jfinal_demo的数据库。
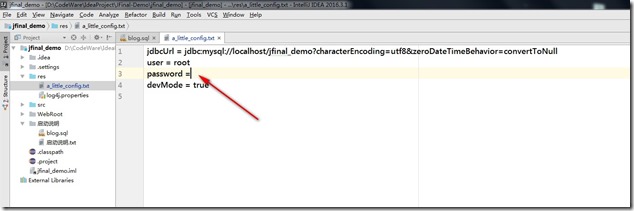
- 打开 res 下的 a_little_config.txt文件,添加到自己数据库的密码
- 点击上图的
 的图标。
的图标。
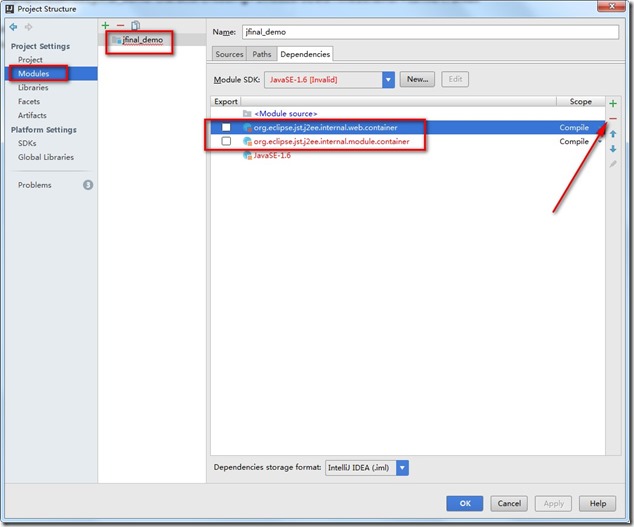
- 在Projcet Structure窗口中,点击Modules – jfinal_demo – Dependencies 中的org.eclipse.jst.j2ee.internal.web.container 和org.eclipse.jst.j2ee.internal.module.container 去掉(去掉按钮在右边的“-”号)
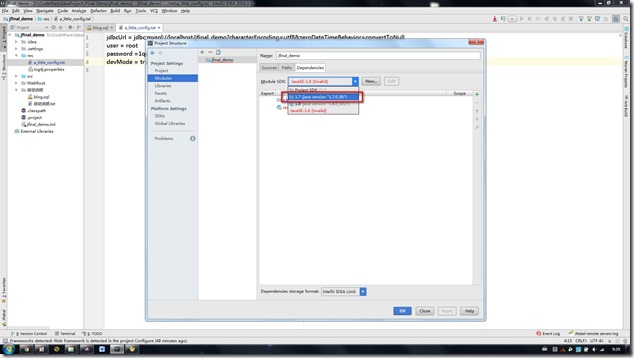
- 修改自己在idea上的jdk,点击Apply,再点击ok.
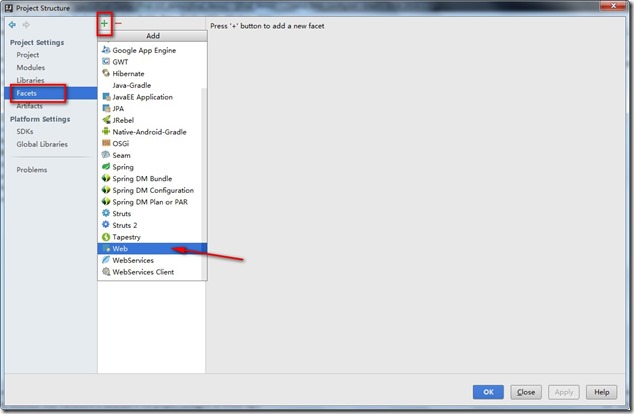
- 点击右边的Facets,然后点击“+”号,选择Web。
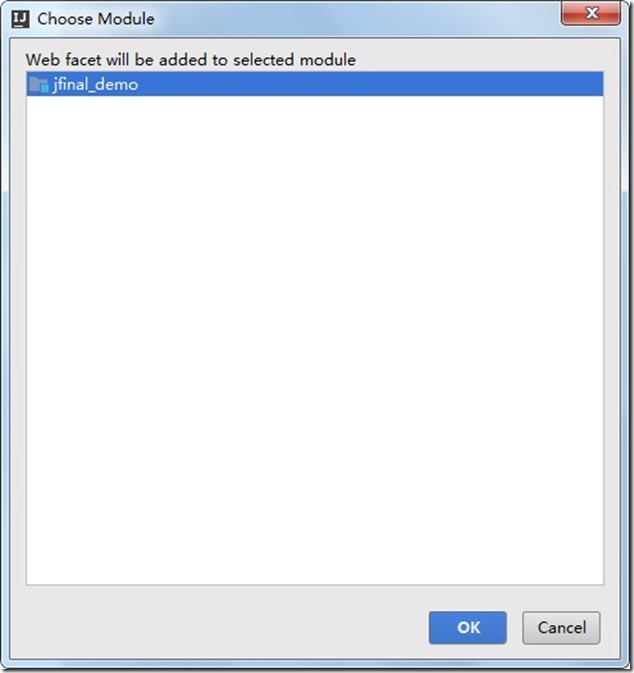
- 选中项目,点击OK。
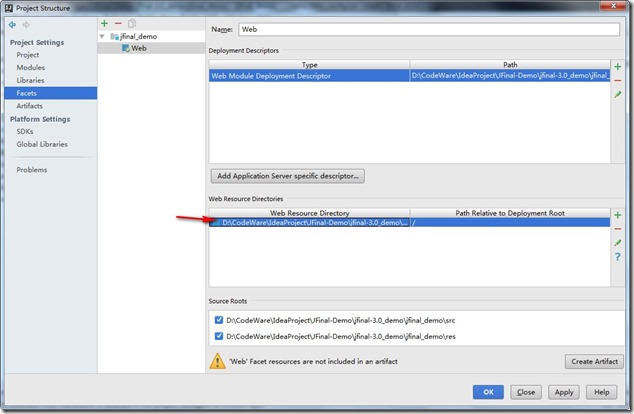
- 然后双击上图的红色箭头的地方。
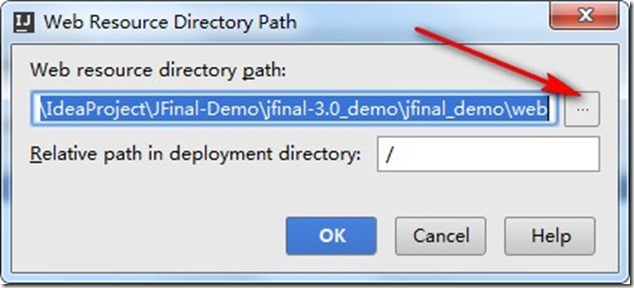
- 在Web Resource Directory Path 窗口中,点击红色箭头的按钮。
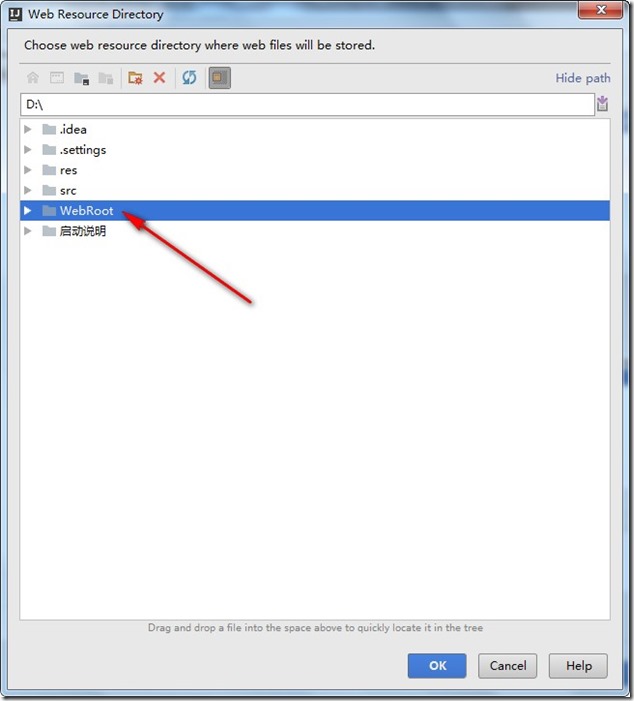
- 选中WebRoot,点击OK。

- 然后点击Create Artifact。
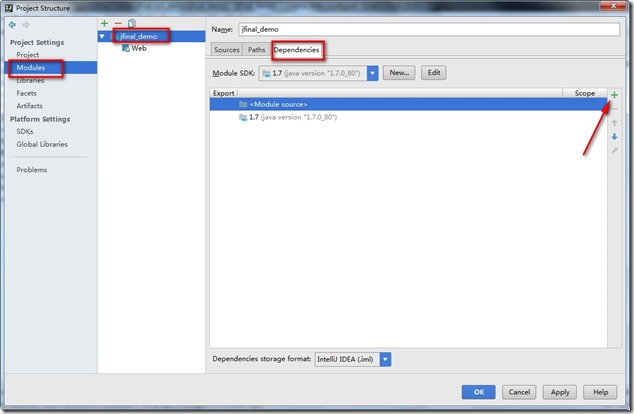
- 窗口进入如上图,点击Deployment中的“+”号。
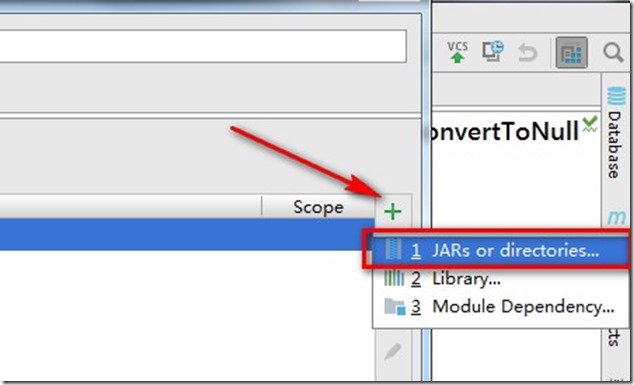
- 点击JARs or directories..
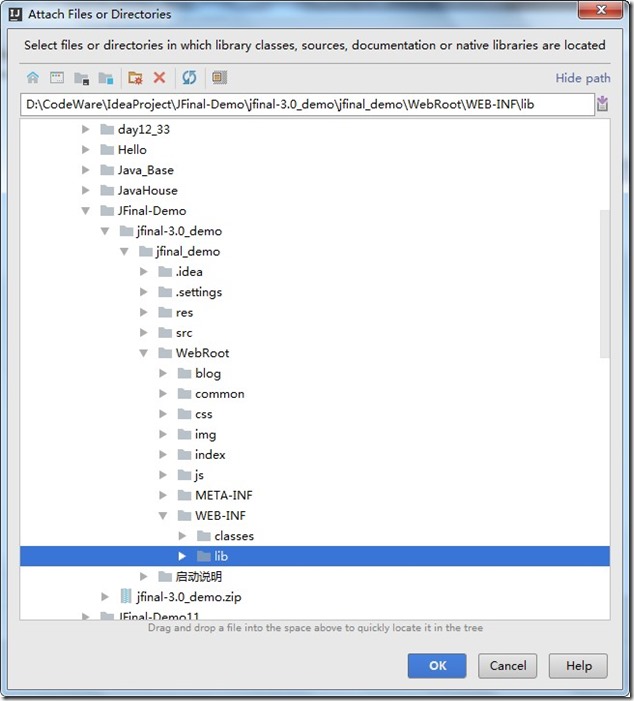
- 选择项目中WebRoot 下的WEB-INF下的lib的文件夹。
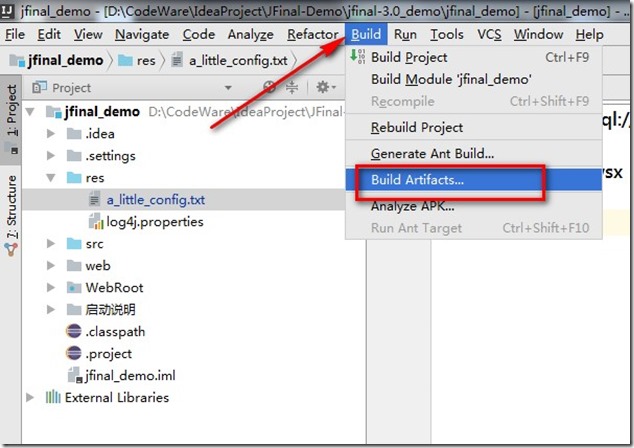
- 点击导航栏的Build 的Build Artifacts。
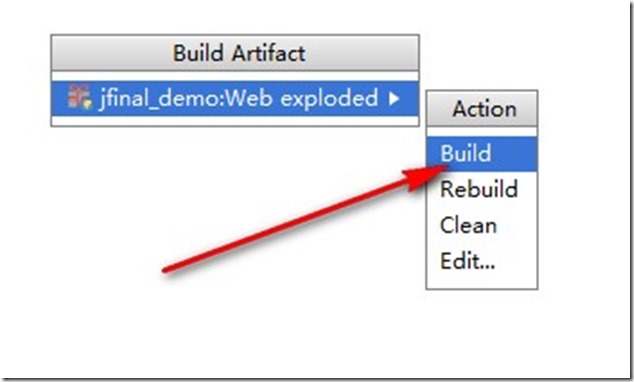
- 再点击Build,项目会自动生成out文件夹。
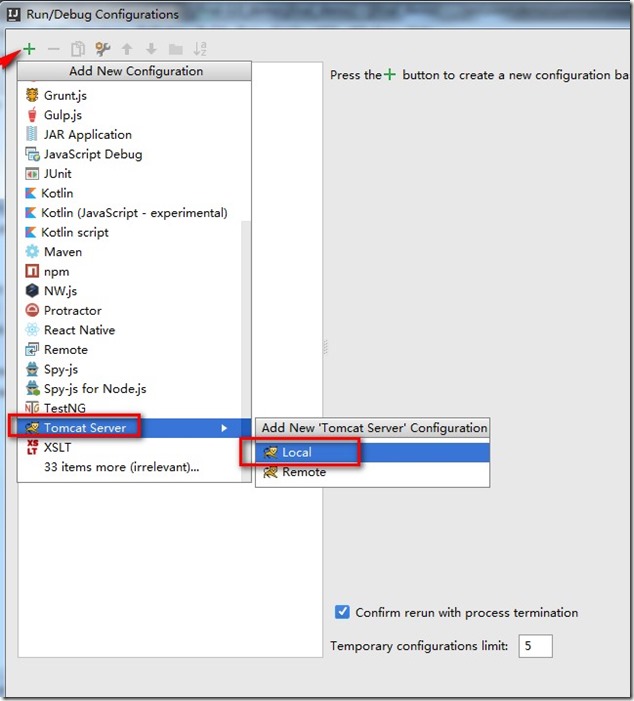
- 配置Tomcat。
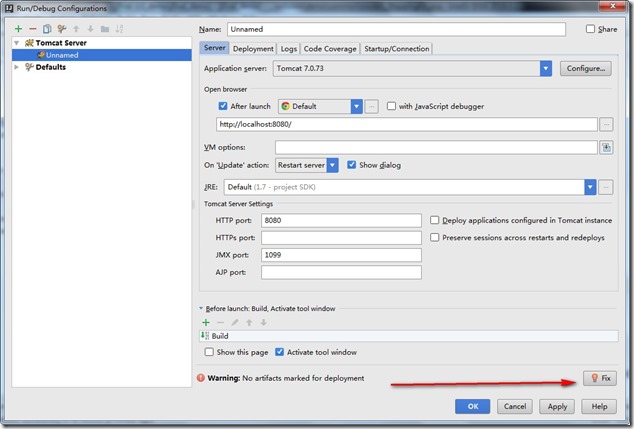
- 再点击红色箭头的Fix按钮。
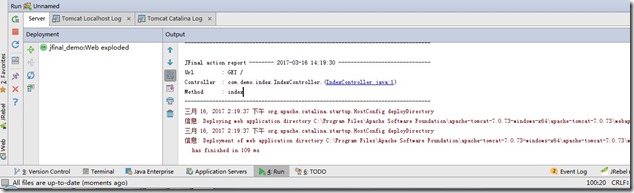
- 启动Tomcat。
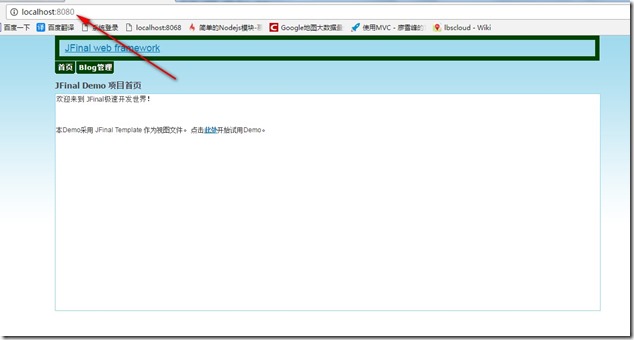
- JFinal-Demo的导入到IDEA就完成了。
[小试牛刀]部署在IDEA的JFinal 3.0 demo的更多相关文章
- Hadoop生态圈-通过CDH5.15.1部署spark1.6与spark2.3.0的版本兼容运行
Hadoop生态圈-通过CDH5.15.1部署spark1.6与spark2.3.0的版本兼容运行 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在我的CDH5.15.1集群中,默 ...
- docker并不能把部署的工作「减少为0」,比较好的情况下是「基本减少为1」
很多人说docker改变了运维世界,这句话是从群体角度来说的,是统计学意义上的改变,像mysql,python这样被大规模使用的基础应用,docker化之后为整个群体所节省的时间是非常巨大的. 有人可 ...
- CentOs7 +Jexus 5.8.2部署Asp.Net Core WebApi 1.0生产环境
Jexus 是一款运行于 Linux 平台,以支持 ASP.NET.PHP 为特色的集高安全性和高性能为一体的 WEB 服务器和反向代理服务器.最新版 5.8.2 已经发布,有如下更新: 1,现在大 ...
- 第一款支持容器和云部署的开源数据库Neo4j 3.0
导读 Neo4j 3.0.0 正式发布,这是 Neo4j 3.0 系列的第一个版本.此版本对内部架构进行了全新的设计:提供给开发者更强大的生产力:提供更广阔的部署选择.Neo4j 3.0 被认为是世界 ...
- CentOS下SparkR安装部署:hadoop2.7.3+spark2.0.0+scale2.11.8+hive2.1.0
注:之前本人写了一篇SparkR的安装部署文章:SparkR安装部署及数据分析实例,当时SparkR项目还没正式入主Spark,需要自己下载SparkR安装包,但现在spark已经支持R接口,so更新 ...
- nodejs部署智能合约的方法-web3 0.20版本
参考:https://www.jianshu.com/p/7e541cd67be2 部署智能合约的方法有很多,比如使用truffle框架,使用remix-ide等,在这里的部署方法是使用nodejs一 ...
- centos7 部署 汉化版 gitlab 10.0.2
更新说明: 20171009:增加3.5的内容 20171008:整理出gitlab部署手册 =============================================== gitla ...
- 在IIS上部署Asp.Net Core 2.2.0
1. .NET Core与Windows环境 Asp.Net Core 2.2.0 Windows 10 2. 先决条件 下载并安装.Net Core Hosting Bundle. 3. 部署过 ...
- IIS部署ASP.NET MVC (4.0)网站出现的错误
(1)无法读取配置节“system.web.extensions”,因为它缺少节声明 在IIS中,在基本设置中,将程序池选择为ASP.NET 4.0即OK! (2)由于 Web 服务器上的“ISAPI ...
随机推荐
- SQL Server死锁问题:事务(进程 ID x)与另一个进程被死锁在 锁 | 通信缓冲区资源上并且已被选作死锁牺牲品。请重新运行该事务。
### The error occurred while setting parameters### SQL: update ERP_SCjh_zzc_pl set IF_TONGBU=1 where ...
- 放一道比较基础的LCA 的题目把 :CODEVS 2370 小机房的树
题目描述 Description 小机房有棵焕狗种的树,树上有N个节点,节点标号为0到N-1,有两只虫子名叫飘狗和大吉狗,分居在两个不同的节点上.有一天,他们想爬到一个节点上去搞基,但是作为两只虫子, ...
- JavaScript实现Tab标签页切换的最简便方式
转载请注明出处:http://www.cnblogs.com/-867259206/p/5664896.html 先说一下最土的一种方法: Html: <div class="tab- ...
- bootstrap中selectpicker下拉框使用方法实例
最近一直在用bootstrap 的一些东西,写几篇博客记录下.... bootstrap selectpicker是bootstrap里比较简单的一个下拉框的组件,先看效果如下: 附上官网api链接, ...
- oracle 11g不能导出空表的解决方法
在oracle 11g r2中,发现传统的exp居然不能导出空的表,然后查询一下, 发现需要如下的步骤去搞,笔记之. oracle 11g 新增了一个参数:deferred_segment_c ...
- 分布式ID生成 - 雪花算法
雪花算法是一种生成分布式全局唯一ID的经典算法,关于雪花算法的解读网上多如牛毛,大多抄来抄去,这里请参考耕耘的小象大神的博客ID生成器,Twitter的雪花算法(Java) 网上的教程一般存在两个问题 ...
- shell命令传参数(参数长度不定)
脚本 sudo echo "[mysqlMaster<$1>]" >> /home/admin/hostrecord count= ];do >> ...
- git篇之二----团体项目中使用git
上篇说了git的简单入门,本篇来说一下在团体项目中我们该如何简单使用git 一般来说,当我们进入公司之后,就前端项目而言,若是有多个同事共同开发一个系统,我们可能会每个人去负责各自的模块. 若是人员较 ...
- xml与Properties的区别
1.properties配置文件,是一个属性对应于一个值(key = value)这样的键值匹对模式: 每一行properties配置文件的键值,对应着一次赋值: 特殊点: 在前后两行properti ...
- mysql修改库、表、字段 字符集,中文排序
查看字段编码: show full columns from t2;show variables like '%character%';show variables like 'collation_% ...