集成学习-组合策略与Stacking
集成学习是如何把多个分类器组合在一起的,不同的集成学习有不同的组合策略,本文做个总结。
平均法
对数值型输出,平均法是最常用的策略,解决回归问题。
简单平均法
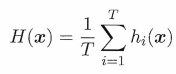 【h(x)表示基学习器的输出】
【h(x)表示基学习器的输出】
加权平均法
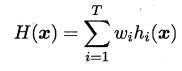 【w是基学习器的权重,w>0】
【w是基学习器的权重,w>0】
基学习器的权重一般是根据训练数据得到,所以不完全可靠,对于规模较大的集成学习来说,容易造成过拟合,所以加权平均不一定优于简单平均。
一般而言,在基学习器性能相差较大时,选择加权平均,在基学习器性能类似时,选择简单平均。
投票法
解决分类问题,假设有N个类别,分类器的输出为一个向量,长度为N。
绝对多数投票法
得票最多的类别的票数要超过50%,否则拒绝预测。
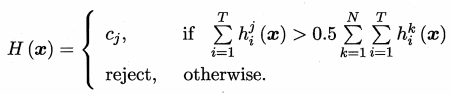
T 表示基学习器的个数,j 表示某类别,N表示类别数
此法提供了拒绝预测的选项,这在准确性要求较高的学习任务中是一个很好地机制,但有可能得不到预测结果。
相对多数投票法
得票最多即可,无需超过50%
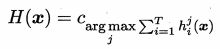
若票数相同,随机选一个即可。
加权投票法

w 是权重,w>0
分类器输出有两种类型
- 类标记:直接输出标签,如{1,0}
- 类概率:输出属于某个类别的概率
1. 不同类型的输出不能混用;
2. 有些分类器在输出类别的同时也输出了分类置信度,可以把置信度作为类概率使用;
3. 虽然分类器估计出的概率值一般不太准确,但对于类概率进行结合往往比对类标签结合效果更好;
4. 若基学习器类型不同,其类概率值不能直接进行比较;此时先把类概率转换成类标记,再进行结合
学习法
当训练数据很多时,一种更为强大的组合策略叫“学习法”,即通过一个学习器来进行组合,这种方法叫 Stacking。
这里把基学习器称为初级学习器,把用来组合的学习器称为次级学习器。
Stacking 先从初始数据集训练出初级学习器,再把初级学习器的输出组合成新的数据集,用于训练次级学习器。
注意初级学习器是不同的。
具体算法如下

注意
次级训练 D’ 是根据初级学习器 ht(xi) 产生的,如果这个 xi 和训练初级学习器 ht 的数据一样,很容易造成过拟合;
所以一般采用交叉验证或者留出法生成多份数据集;
如交叉验证,k-1份用于训练初级学习器,剩下一份用于生成 D‘;
次级学习器的输入和次级学习器的模型对Stacking影响很大,据研究,将类概率作为次级学习器的输入,用多响应线性回归作为次级学习器效果较好。
示例代码
import csv
import random
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cross_validation import StratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
from sklearn import metrics
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier, GradientBoostingClassifier def run(data):
X = np.array([ i[:-1] for i in data ], dtype=float)
Y = np.array([ i[-1] for i in data ]) # We need to transform the string output to numeric
label_encoder = LabelEncoder()
label_encoder.fit(Y)
Y = label_encoder.transform(Y) # The DEV SET will be used for all training and validation purposes
# The TEST SET will never be used for training, it is the unseen set.
dev_cutoff = len(Y) * 4/5
X_dev = X[:dev_cutoff]
Y_dev = Y[:dev_cutoff]
X_test = X[dev_cutoff:]
Y_test = Y[dev_cutoff:] n_trees = 10
n_folds = 5 # Our level 0 classifiers
clfs = [
RandomForestClassifier(n_estimators = n_trees, criterion = 'gini'),
ExtraTreesClassifier(n_estimators = n_trees * 2, criterion = 'gini'),
GradientBoostingClassifier(n_estimators = n_trees),
] # Ready for cross validation
skf = list(StratifiedKFold(Y_dev, n_folds)) # Pre-allocate the data
blend_train = np.zeros((X_dev.shape[0], len(clfs))) # Number of training data x Number of classifiers
blend_test = np.zeros((X_test.shape[0], len(clfs))) # Number of testing data x Number of classifiers print 'X_test.shape = %s' % (str(X_test.shape))
print 'blend_train.shape = %s' % (str(blend_train.shape))
print 'blend_test.shape = %s' % (str(blend_test.shape)) # For each classifier, we train the number of fold times (=len(skf))
for j, clf in enumerate(clfs):
print 'Training classifier [%s]' % (j)
blend_test_j = np.zeros((X_test.shape[0], len(skf))) # Number of testing data x Number of folds , we will take the mean of the predictions later
for i, (train_index, cv_index) in enumerate(skf):
print 'Fold [%s]' % (i) # This is the training and validation set
X_train = X_dev[train_index]
Y_train = Y_dev[train_index]
X_cv = X_dev[cv_index]
Y_cv = Y_dev[cv_index] clf.fit(X_train, Y_train) # This output will be the basis for our blended classifier to train against,
# which is also the output of our classifiers
blend_train[cv_index, j] = clf.predict(X_cv)
blend_test_j[:, i] = clf.predict(X_test)
# Take the mean of the predictions of the cross validation set
blend_test[:, j] = blend_test_j.mean(1) print 'Y_dev.shape = %s' % (Y_dev.shape) # Start blending!
bclf = LogisticRegression()
bclf.fit(blend_train, Y_dev) # Predict now
Y_test_predict = bclf.predict(blend_test)
score = metrics.accuracy_score(Y_test, Y_test_predict)
print 'Accuracy = %s' % (score) return score if __name__ == '__main__':
train_file = 'data/column_3C.dat' data = [ i for i in csv.reader(file(train_file, 'rb'), delimiter=' ') ]
data = data[1:] # remove header best_score = 0.0 # run many times to get a better result, it's not quite stable.
for i in xrange(1):
print 'Iteration [%s]' % (i)
random.shuffle(data)
score = run(data)
best_score = max(best_score, score)
print print 'Best score = %s' % (best_score)
仅供参考。
参考资料:
《机器学习》 周志华
集成学习-组合策略与Stacking的更多相关文章
- 集成学习中的 stacking 以及python实现
集成学习 Ensemble learning 中文名叫做集成学习,它并不是一个单独的机器学习算法,而是将很多的机器学习算法结合在一起,我们把组成集成学习的算法叫做“个体学习器”.在集成学习器当中,个体 ...
- 【集成学习】:Stacking原理以及Python代码实现
Stacking集成学习在各类机器学习竞赛当中得到了广泛的应用,尤其是在结构化的机器学习竞赛当中表现非常好.今天我们就来介绍下stacking这个在机器学习模型融合当中的大杀器的原理.并在博文的后面附 ...
- 机器学习回顾篇(12):集成学习之Bagging与随机森林
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- sklearn中调用集成学习算法
1.集成学习是指对于同一个基础数据集使用不同的机器学习算法进行训练,最后结合不同的算法给出的意见进行决策,这个方法兼顾了许多算法的"意见",比较全面,因此在机器学习领域也使用地非常 ...
- [机器学习]集成学习--bagging、boosting、stacking
集成学习简介 集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务. 如何产生"好而不同"的个体学习器,是集成学习研究的核心. 集成学习的思路是通过 ...
- 集成学习总结 & Stacking方法详解
http://blog.csdn.net/willduan1/article/details/73618677 集成学习主要分为 bagging, boosting 和 stacking方法.本文主要 ...
- 7. 集成学习(Ensemble Learning)Stacking
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- Ensemble_learning 集成学习算法 stacking 算法
原文:https://herbertmj.wikispaces.com/stacking%E7%AE%97%E6%B3%95 stacked 产生方法是一种截然不同的组合多个模型的方法,它讲的是组合学 ...
- 集成学习的不二法门bagging、boosting和三大法宝<结合策略>平均法,投票法和学习法(stacking)
单个学习器要么容易欠拟合要么容易过拟合,为了获得泛化性能优良的学习器,可以训练多个个体学习器,通过一定的结合策略,最终形成一个强学习器.这种集成多个个体学习器的方法称为集成学习(ensemble le ...
随机推荐
- CSP-S2 游记
CSP-S2 游记 & AFO 感想 Day0 早上考了一场式,非常简单,但是懒得写正解.230pts. 晚上听了一下WYQ大神的考前直播,写了一下树上倍增(我是不会告诉你我还写炸了) 与lu ...
- [CSP-S模拟测试]:你相信引力吗(单调栈)
题目传送门(内部题124) 输入格式 第一行一个整数$n$代表环的长度. 第二行$n$个整数表示每个冰锥的高度. 输出格式 一行一个整数表示有多少对冰锥是危险的. 样例 样例输入1: 51 2 4 5 ...
- 暂时跳过的Leetcode题目
963 最小面积矩形 II 有数学几何的味道,感觉这不是笔试面试的重点. 932 漂亮数组 构造题
- HomeBrew安装MongoDB如何启动
1.先安装HomeBrew 安装(需要 Ruby): ruby -e "$(curl -fsSL https://raw.github.com/Homebrew/homebrew/go/in ...
- assertion的用法
一.assertion的语法和语义 在软件开发中,assertion是一种经典的调试.测试方式,本文将深入解析assertion功能的使用以及其设计理念,并给出相关的例子. 清软国际java学 ...
- linux如何查看所有的用户和组信息(转载)
[步骤一]cat /etc/passwdcat /etc/passwd查看所有的用户信息,详情如下图 [步骤二]cat /etc/passwd|grep 用户名 cat /etc/passwd|gre ...
- typescript 函数(定义、参数、重载)
代码: // 本节内容 // 1.函数的定义 // 2.参数(可选参数/默认参数/剩余参数) // 3.方法的重载 // js // function add(x,y){ // return x+y ...
- vue组件化之模板优化及注册组件语法糖
vue组件化之模板优化及注册组件语法糖 vue组件化 模板 优化 在 https://www.cnblogs.com/singledogpro/p/12054895.html 这里我们对vue.js ...
- 一起学vue指令之v-once
一起学vue指令之v-once 一起学 vue指令 v-once 指令可看作标签属性 v-once 口该指令后面不需要跟任何表达式(v-for后面接表达式) 口该指令表示元素和组件只渲染一次,不会随 ...
- 源码编译apache出错
报错信息如下 exports.c:1572: error: redefinition of `ap_hack_apr_allocator_create' exports.c:177: error: ` ...