paper 157:文章解读--How far are we from solving the 2D & 3D Face Alignment problem?-(and a dataset of 230,000 3D facial landmarks)
作者:诺丁汉大学的Adrian Bulat& Georgios Tzimiropoulos
Github:https://github.com/1adrianb/face-alignment
2D-FAN:https://www.adrianbulat.com/downloads/FaceAlignment/2D-FAN-300W.t7
3D-FAN:https://www.adrianbulat.com/downloads/FaceAlignment/3D-FAN.t7
2D-to-3D FAN:https://www.adrianbulat.com/downloads/FaceAlignment/2D-to-3D-FAN.tar.gz
3D-FAN-depth:https://www.adrianbulat.com/downloads/FaceAlignment/3D-FAN-depth
摘要
在现存2D和3D人脸对齐数据集上,本文研究的这个非常深的神经网络达到接近饱和性能的程度。本文主要做了5个贡献:(1)结合最先进的人脸特征点定位(landmark localization)架构和最先进的残差模块(residual block),首次构建了一个非常强大的基准,在一个超大2D人脸特征点数据集(facial landmark dataset)上训练,并在所有其他人脸特征点数据集上进行评估。(2)我们构建一个将2D特征点标注转换为3D标注,并所有现存数据集进行统一,构建迄今最大、最具有挑战性的3D人脸特征点数据集LS3D-W(约230000张图像)。(3)然后,训练一个神经网络来进行3D人脸对齐(face alignment),并在新的LS3D-W数据集上进行评估。(4)本文进一步研究影响人脸对齐性能的所有“传统”因素,例如大姿态( large pose),初始化和分辨率,并引入一个“新的”因素,即网络的大小。(5)本文的测试结果显示2D和3D人脸对齐网络都实现了非常高的性能,足以证明非常可能接近所使用的数据集的饱和性能。训练和测试代码以及数据集可以从 https://www.adrianbulat.com/face-alignment/%20下载。
引言
随着深度学习和大规模注释数据集的发展,近年的工作已经显示出即使在最具挑战性的计算机视觉任务上也达到前所未有的准确性。在这项工作中,本文专注于特征点定位(landmark localization),尤其是人脸特征点定位,即:人脸对齐(face alignment),“人脸对齐”也可以说是过去几十年来计算机视觉中的研究热点。
目前,关于使用卷积神经网络(CNN)的特征点定位的研究,大大推动了其他领域的界限,例如人体姿态估计,但目前尚不清楚在人脸对齐方面取得怎样的成果。
历史上,根据任务的不同,有不同的技术已被用于特征点定位。例如,在神经网络出现之前,人体姿态估计的工作主要是基于图结构(Pictorial Structure)和各种复杂的扩展(Extension),因为它们能够模拟大的外观变化, 适应广泛的人类姿势。这些方法虽然没有被证明能够实现用于人脸对齐任务的级联回归方法(Cascaded Regression Method)表现出的高精确度,但另一方面,级联回归方法的性能在初始化不准确的情况下,或有大量的自我封闭的特征点或大的平面内旋转时会变差。
最近,基于热图回归(Heatmap Regression)的完全卷积神经网络架构彻底改变了人体姿态估计,即使对于最具挑战性的数据集也得到非常高的准确度。由于它们对端到端训练和人工工程的需求很少,这种方法可以很容易地应用于人脸对齐问题。
使用2D-3D方法构建最大数据集(LS3D-W)
作者表示,按照这个路径,“我们的主要贡献是构建和训练这样一个强大的人脸对齐网络,并首次调查在所有现有的2D人脸对齐数据集和新引入的大型3D数据集上距离达到接近饱和性能(saturating performance)有多远”。
Contributions(具体的贡献):
1. 首次构建了一个非常强大的基准(baseline),结合state-of-the-art的特征点定位架构和state-of-the-art的 残差模块(residual block),并在非常大的综合扩展的2D人脸特征点数据集训练。然后,我们对所有其他2D数据集(约230000张图像)进行评估,分析真正解决2D人脸对齐问题还有多远。
2. 为了解决3D人脸对齐数据集少的问题,本文进一步提出了一种将2D注释转换为3D注释的2D特征点CNN方法,并使用它创建LS3D-W数据集,这是目前最大、最具挑战性的3D人脸特征点数据集(约230000张图像),是通过将现存的所有数据集统一起来得到的。
3. 然后,本文训练了一个3D人脸对齐网络,并在新的大型3D人脸特征点数据集进行评估,实际分析距离解决3D人脸对齐问题尚有多远。
4. 本文进一步研究影响人脸对齐性能的所有“传统”因素,例如大姿态(large pose),初始化和分辨率,并引入“新的”因素,即网络的大小。
5. 本文测试结果显示,2D和3D人脸对齐网络都实现了非常高准确度的性能,这可能是接近了所使用的数据集的饱和性能。
2D-FAN结构:
通过堆叠四个HG(HourGlass)构建的人脸对齐网络(Face Alignment Network, FAN),其中所有的 bottleneck blocks(图中矩形块)被替换为新的分层、并行和多尺度block。
方法及数据:2D、3D标注及2D-3D转换都接近饱和性能
文章首先构建人脸对齐网络“FAN”(Face Alignment Network),然后基于FAN,构建2D-to-3D-FAN,也即将给定图像2D面部标注转换为3D的网络。文章表示,据测试所知,在大规模2D/3D人脸对齐实验中训练且评估FAN这样强大的网络,还尚属首次。
他们基于人体姿态估计最先进的架构之一HourGlass(HG)来构建FAN,并且将HG原有的模块bottleneck block替换为一种新的、分层并行多尺度结构(由其他研究人员提出)。
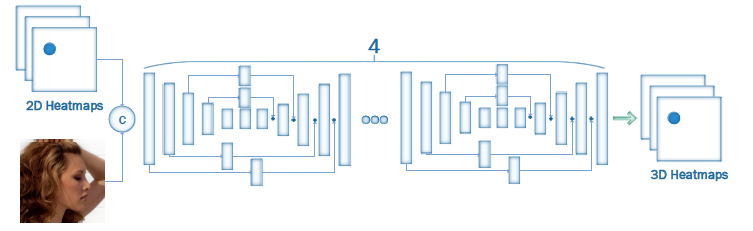
2D-to-3D-FAN网络架构:基于人体姿态估计架构HourGlass,输入是RGB图像和2D面部地标,输出是对应的3D面部地标。

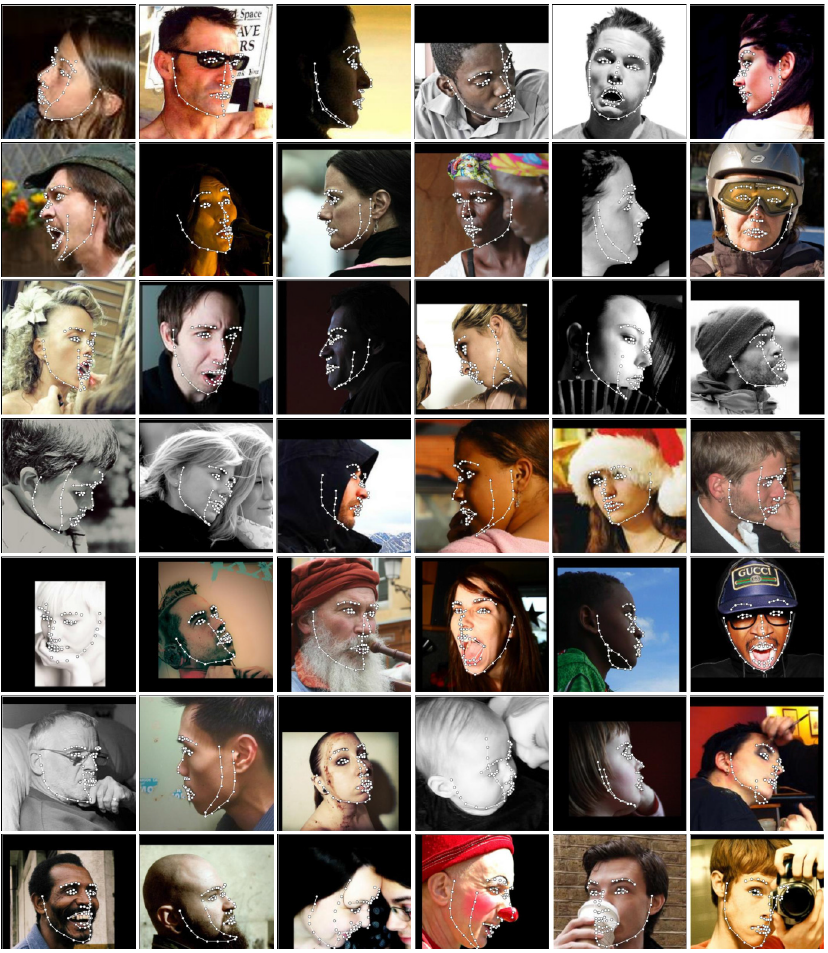
2D-FAN标记结果
3D-FAN标记结果
下面是跟现有方法(红色)的对比,这样看更能明显地看出新方法的精度:
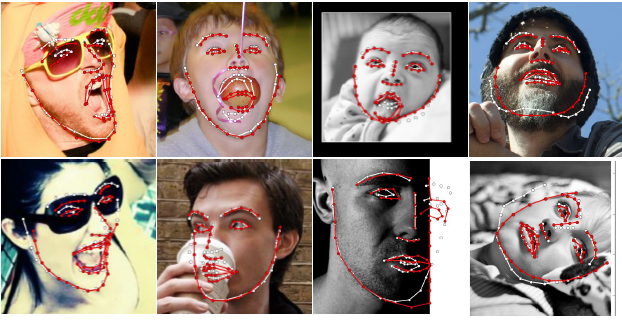
除了构建FAN,作者的目标还包括创建首个超大规模的3D面部地标数据集。目前3D面部地标的数据还十分稀少,因此也让这项工作贡献颇大。鉴于2D-FAN卓越的效果,作者决定使用2D-to-3D-FAN来生成3D面部地标数据集。
但是,这也带来了一个问题,那就是评估2D转3D数据很难。现有的最大同类数据集是AFLW2000-3D。于是,作者先使用2D-FAN,生成2D面部地标标注,再使用2D-to-3D-FAN,将2D数据转换为3D面部地标,最后将生成的3D数据与AFLW2000-3D进行比较。
结果发现,两者确实有差异,下图展示了差异最大的8幅图像标记结果(白色是论文结果):

作者表示,造成差异的最大原因是,以前的方法半自动标记管道对一些复杂姿态没有生成准确的结果。于是,在改进数据后,他们将AFLW2000-3D纳入现有数据集,创建了LS3D-W(Large Scale 3D Faces in-the-Wild dataset),一共包含了大约230,000幅标记图像,也是迄今最大的3D人脸对齐数据集。
作者之后从各个方面评估了LS3D-W数据集的性能。研究结果表明,他们的网络已经达到了数据集的“饱和性能”,在构图、分辨率,初始化以及网络参数数量方面表现出了超高的弹性(resilience)。更多信息参见论文。
作者表示,虽然他们还没有在这些数据集中去探索一些罕见姿态的效果,但只要有足够多的数据,他们确信网络也能够表现得一样好。
作者:南君
出处:http://www.cnblogs.com/molakejin/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
paper 157:文章解读--How far are we from solving the 2D & 3D Face Alignment problem?-(and a dataset of 230,000 3D facial landmarks)的更多相关文章
- paper 159:文章解读:From Facial Parts Responses to Face Detection: A Deep Learning Approach--2015ICCV
文章链接:https://arxiv.org/pdf/1509.06451.pdf 1.关于人脸检测的一些小小总结(Face Detection by Literature) (1)Multi-vie ...
- [转帖]2016年的文章: 解读ASP.NET 5 & MVC6系列教程(1):ASP.NET 5简介
解读ASP.NET 5 & MVC6系列教程(1):ASP.NET 5简介 更新时间:2016年06月23日 11:38:00 作者:汤姆大叔 我要评论 https://www.jb ...
- 陈天奇XGBoost文章解读(未完成)
这个是我下载的原文在看,然后结合一些网上的资料学习,先贴一个网上的资料. 终于有人说清楚了XGBoost算法 XGBoost阅读之Weighted quantile sketch XGBoost论文翻 ...
- Face recognition using Histograms of Oriented Gradients
Face recognition using Histograms of Oriented Gradients 这篇论文的主要内容是将Hog算子应用到人脸识别上. 转载请注明:http://blog. ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- paper 156:专家主页汇总-计算机视觉-computer vision
持续更新ing~ all *.files come from the author:http://www.cnblogs.com/findumars/p/5009003.html 1 牛人Homepa ...
- 人脸识别必读的N篇文章
一,人脸检测/跟踪 人脸检测/跟踪的目的是在图像/视频中找到各个人脸所在的位置和大小:对于跟踪而言,还需要确定帧间不同人脸间的对应关系. 1, Robust Real-time Object Dete ...
- Transformer解析与tensorflow代码解读
本文是针对谷歌Transformer模型的解读,根据我自己的理解顺序记录的. 另外,针对Kyubyong实现的tensorflow代码进行解读,代码地址https://github.com/Kyuby ...
- 解读大内老A的《.NET Core框架本质》
老A说的一句话让我很受启发,想要深入了解框架,你要把精力聚焦在架构设计的层面来思考问题.而透彻了解底层原理,最好的笨办法就是根据原理对框架核心进行重建或者说再造.看起来没有捷径,也是最快的捷径. 题外 ...
随机推荐
- Oralce-资源配置PROFILE
profile:作为用户配置文件,它是密码限制,资源限制的命名集合 在安装数据库时,Oracle自动会建立名为default的默认配置文件 使用profile文件时,要注意以下几点: 建立用户时,如果 ...
- delphi 获取文件的最新修改时间 http://www.delphitop.com/html/wenjian/64.html
delphi 获取文件的最新修改时间 作者:admin 来源:未知 日期:2010/1/28 13:15:22 人气:1054 标签: QQ空间新浪微博腾讯微博腾讯朋友QQ收藏百度空间百度贴吧更多0 ...
- Jetty在idea中运行
文章目录 下载 配置 运行时报错 请求 下载 https://download.csdn.net/download/again_vivi/9796169 解压到任意目录 配置 configuratio ...
- Fedora 的截屏功能
写写博客少不了截图,Windows 上使用微信的快捷键 Ctrl+A 截图并且可以随意编辑是挺方便的,开始在 Linux 上还没有找到这样的软件,只找到了不支持编辑的简单截图软件. 1. 使用 Scr ...
- 16/8/23-jQuery子调用匿名函数
通过创建一个自调用匿名函数,创建一个特殊的函数作用域,该作用域中的代码不会和已有的同名函数.方法和变量以及第三方库冲突. 自调用匿名函数写法 方法一: (function(){ //... })(); ...
- HTML5-新增type属性
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- JSP基础--会话跟踪技术、cookie、session
会话跟踪技术 1 什么是会话跟踪技术 我们需要先了解一下什么是会话!可以把会话理解为客户端与服务器之间的一次会晤,在一次会晤中可能会包含多次请求和响应.例如你给10086打个电话,你就是客户端,而10 ...
- What is one-hot?
SEO: libtorch 如何 OneHot ? torch OneHot 源代码 ? https://www.tensorflow.org/api_docs/python/tf/one_hot 最 ...
- BZOJ1672 Cleaning Shifts 清理牛棚
传送门 显然可以考虑 $dp$ 设 $f[i]$ 表示当前到了时间 $i$,从初始到 $i$ 的时间都安排好打扫了 把所有牛按照区间 $l,r$ 双关键字排序 这样枚举到一头牛 $x$ 时,在 $x. ...
- P5459 [BJOI2016]回转寿司
传送门 暴力怎么搞,维护前缀和 $s[i]$ ,对于每一个 $s[i]$,枚举所有 $j\in[0,i-1]$,看看 $s[i]-s[j]$ 是否属于 $[L,R]$ 如果属于就加入答案 $s[i]- ...