es之主分片和复制分片的交互过程
1:索引(创建或者删除)一个文档
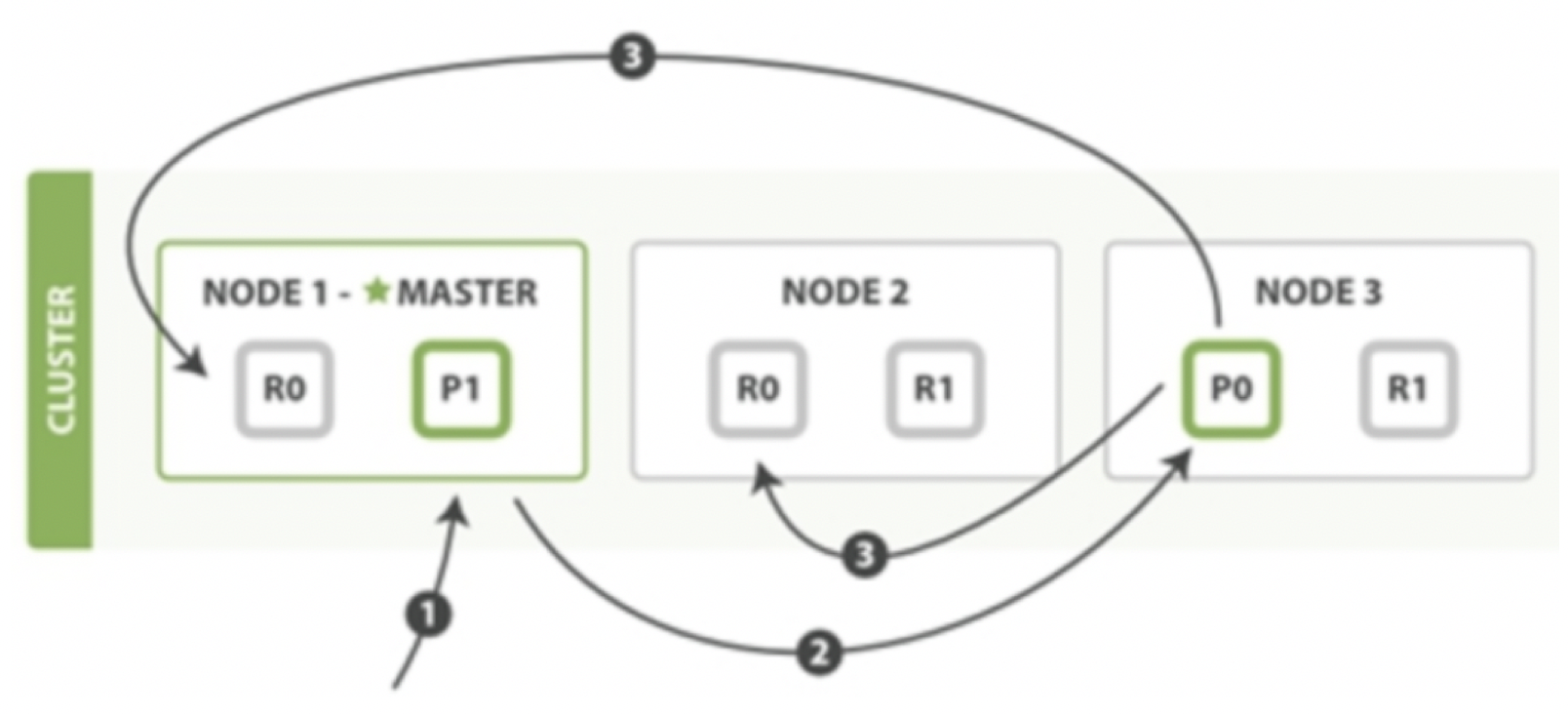
首先:发送一个索引或者删除的请求给node1
其次:node1接收到请求之后,会根据请求中携带的参数“文档id”判断出该文档应该存储在具体哪一个shard中
shard = hash(routing) % number_of_primary_shards
,比如shard0;其次就是node1通过元数据信息可以知道shard0在具体哪一个节点,于是node1会把请求转发给node3
最后:node3接收到请求之后会将请求并行的分发给shard0的所有replica shard之上,也就是存在于node 1和node 2中的replica shard;如果所有的replica shard都成功地执行了请求,那么将会向node 3回复一个成功确认,当node 3收到了所有replica shard的确认信息后,则最后向用户返回一个Success的消息。
2:删除一个文档

该过程可以分为四个阶段来描述: 阶段1:客户端向node 1发送一个文档删除的请求。 阶段2:同样的node 1通过请求中文档的 _id 值判断出该文档应该被存储在shard 0 这个分片中,并且node 1知道shard 0的primary shard位于node 3这个节点上。因此node 1会把这个请求转发到node 3。 阶段3:node 3接收到请求后,在主分片上面执行删除请求 阶段4:如果node 3成功地删除了文档,node 3将会请求并行地发给其余所有的replica shard所在node中。这些node也同样操作删除,执行后则向node 3确认成功,当node 3接收到所有的成功确认之后,再向客户端发送一个删除成功的信息。
3:检索文档

检索文档的时候,我们并不知道文档在集群中的哪个位置,所以一般情况下不得不去询问index中的每一个shard,然后将结果拼接成一个大的已排好序的汇总结果列表;
(1):客户端发送一个检索请求给node3,此时node3会创建一个空的优先级队列并且配置好分页参数from与size。
(2):node3将检所请求发送给index中的每一个shard(primary 和 replica),每一个在本地执行检索,并将结果添加到本地的优先级队列中;
(3):每个shard返回本地优先级序列中所记录的_id与score值,并发送node3。Node3将这些值合并到自己的本地的优先级队列中,并做全局的排序(node 3将它们合并成一条汇总的结果),返回给客户端。
列子:
1):构建测试数据:
PUT website/blog/1
{
"title" : "this is title",
"conteng" : "this is content"
}
PUT website/blog/2
{
"title" : "thi title",
"conteng" : "thi content"
}
PUT website/blog/3
{
"title" : "thitle",
"conteng" : "thontent"
}
PUT website/blog/4
{
"title" : "aaa",
"conteng" : "aaaaa"
}
PUT website/blog/5
{
"title" : "bbbbb",
"conteng" : "cccccc"
}
PUT website/blog/6
{
"title" : "e",
"conteng" : "ssss"
}
PUT website/blog/7
{
"title" : "this title",
"conteng" : "thi content"
}
在最初的查询过程中,查询请求会广播到index中的每一个primary shard和replica shard中,每一个shard会在本地执行检索,并建立一个优先级队列(priority queue)。这个优先级队列是一个根据文档匹配度这个指标所排序列表,列表的长度由分页参数from和size两个参数所决定
GET website/_search
{
"query": {
"match": {
"title": "this"
}
}
}
es之主分片和复制分片的交互过程的更多相关文章
- Es官方文档整理-2.分片内部原理
Es官方文档整理-2.分片内部原理 1.集群 一个运行的Elasticsearch实例被称为一个节点,而集群是有一个或多个拥有相同claster.name配置的节点组成,他们共同承担数据和负 ...
- mongodb复制+分片集原理
----------------------------------------复制集---------------------------------------- 一.复制集概述: Mongodb ...
- Mongodb 笔记07 分片、配置分片、选择片键、分片管理
分片 1. 分片(sharding)是指将数据拆分,将其分散存放在不同的机器上的过程.有时也用分区(partitioning)来表示这个概念.将数据分散到不同的机器上,不需要功能强大的大型计算机就可以 ...
- MyCat 学习笔记 第十篇.数据分片 之 ER分片
1 应用场景 这篇来说下mycat中自带的er关系分片,所谓er关系分片即可以理解为有关联关系表之间数据分片.类似于订单主表与订单详情表间的分片存储规则. 本文所说的er分片分为两种: a. 依据主键 ...
- shuffle机制和TextInputFormat分片和读取分片数据(九)
shuffle机制 1:每个map有一个环形内存缓冲区,用于存储任务的输出.默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线 ...
- KingbaseES V8R6集群部署案例之---Windows环境配置主备流复制(异机复制)
案例说明: 目前KingbaseES V8R6的Windows版本不支持数据库sys_rman的物理备份,可以考虑通过建立主备流复制实现数据库的异机物理备份.本案例详细介绍了,在Windows环境下建 ...
- KingbaseES V8R6集群部署案例之---Windows环境配置主备流复制(同一主机)
案例说明: 目前KingbaseES V8R6的Windows版本不支持数据库sys_rman的物理备份,可以考虑通过建立主备流复制实现数据库的异机物理备份.本案例详细介绍了,在Windows环境下建 ...
- mango框架中表分片与数据库分片(分表与分库)
表分片 表分片通常也被称为分表,散表. 当某张表的数据量很大时,sql执行效率都会变低,这时通常会把大表拆分成多个小表,以提高sql执行效率. 我们将这种大表拆分成多个小表的策略称之为表分片. 先来看 ...
- NoSQL生态系统——hash分片和范围分片两种分片
13.4 横向扩展带来性能提升 很多NoSQL系统都是基于键值模型的,因此其查询条件也基本上是基于键值的查询,基本不会有对整个数据进行查询的时候.由于基本上所有的查询操作都是基本键值形式的,因此分片通 ...
随机推荐
- 小记------mongodb数据库如何进行模糊查询
// 模糊匹配createTime 是以 2019-07-23 开头 db.getCollection('driver_online_record').find({"createTime ...
- java springmvc poi 导出Excel,先简单记录,后期会详细描写
POI jar包下载 : http://poi.apache.org/download.html jsp代码 <%@ page language="java" content ...
- 定义一个接口CanFly,描述会飞的方法public void fly();
1.使用类与接口的知识完成如下要求:(1)定义一个接口CanFly,描述会飞的方法public void fly();(2)分别定义类飞机和鸟,实现CanFly接口.(3)定义一个测试类,测试飞机和鸟 ...
- 21个CSS3 / JS 时钟
收集了21个酷炫的CSS / JS实现的时钟效果https://oktools.net/clocks 预览 :https://clocks.oktools.net/0/ 源码 :https://cod ...
- python之堆排序算法代码
以下是个人写的堆排序代码,原理我就不解释了(简单来说就是先建立一个大顶堆,然后进行顶点和最后节点的互换,互换之后需要重新建堆,两两比对,具体的话可以参照其他的,不过代码还是会于注释的. #根据问题进行 ...
- bootloader架构设计
G-boot架构设计 第一阶段程序设计 1.0.核心初始化: 1.设置中断向量表 2.设置处理器为svc模式 3.关闭看门狗 4.关闭所有中断 5.关闭mmu和cache 6.外设基地址初始化 ...
- django笔记三之admin的管理
django笔记三之admin的管理 设置自动admin应用 vim todos/settings.py INSTALLED_APPS = ( 'django.contrib.admin', 新版本已 ...
- 001-cut 的用法
[root@zabbix ~]# , /etc/passwd root: bin: daemon: adm: shutdown: halt: mail: operator: games: nobody ...
- Jsoup抓取网页数据完成一个简易的Android新闻APP
前言:作为一个篮球迷,每天必刷NBA新闻.用了那么多新闻APP,就想自己能不能也做个简易的新闻APP.于是便使用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简易的新闻APP.虽然没什么技术含量,但 ...
- Maven搭建简单的SPring+SpringMVC+Hibernate框架
公司的项目用到的框架是Spring+SpringMVC+Hibernate 以前没有用过,所以要系统的学习一下,首先要学会怎么搭建 第一步 创建一个Maven的web项目 创建方法以前的博客中有提 ...