Haystack全文检索框架
一、什么是Haystack
Haystack是django的开源全文搜索框架(全文检索不同于特定字段的模糊查询,使用全文检索的效率更高 ),该框架支持Solr,Elasticsearch,Whoosh, **Xapian搜索引擎它是一个可插拔的后端(很像Django的数据库层),所以几乎你所有写的代码都可以在不同搜索引擎之间便捷切换
全文检索不同于特定字段的模糊查询,使用全文检索的效率更高,并且能够对于中文进行分词处理
haystack:django的一个包,可以方便地对model里面的内容进行索引、搜索,设计为支持whoosh,solr,Xapian,Elasticsearc四种全文检索引擎后端,属于一种全文检索的框架
whoosh:纯Python编写的全文搜索引擎,虽然性能比不上sphinx、xapian、Elasticsearc等,但是无二进制包,程序不会莫名其妙的崩溃,对于小型的站点,whoosh已经足够使用
jieba:一款免费的中文分词包,如果觉得不好用可以使用一些收费产品
二、安装
pip install django-haystack # 全文检索框架
pip install whoosh # 全文检索引擎
pip install jieba # 分词工具包
三、配置
1、添加haystack到INSTALLED_APPS中

2、修改settings.py
在你的settings.py中,你需要添加一个设置来指示站点配置文件正在使用的后端,以及其它的后端设置。 HAYSTACK——CONNECTIONS是必需的设置,并且应该至少是以下的一种
①Solr
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'haystack.backends.solr_backend.SolrEngine',
'URL': 'http://127.0.0.1:8983/solr'
# ...or for multicore...
# 'URL': 'http://127.0.0.1:8983/solr/mysite',
},
}
②Elasticsearch
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine',
'URL': 'http://127.0.0.1:9200/',
'INDEX_NAME': 'haystack',
},
}
③Whoosh示例
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
'PATH': os.path.join(os.path.dirname(__file__), 'whoosh_index'),
},
}
④Xapian
#首先安装Xapian后端(http://github.com/notanumber/xapian-haystack/tree/master)
#需要设置PATH到你的Xapian索引的文件系统位置。
import os
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'xapian_backend.XapianEngine',
'PATH': os.path.join(os.path.dirname(__file__), 'xapian_index'),
},
}
四、处理数据
1、创建索引
如果你想针对某个app例如app01做全文检索,则必须在app01的目录下面建立search_indexes.py文件,文件名不能修改。在文件里写入
from haystack import indexes
from app01.models import Article class ArticleIndex(indexes.SearchIndex, indexes.Indexable):
# 类名必须为需要检索的Model_name+Index,这里需要检索Article,所以创建ArticleIndex
text = indexes.CharField(document=True, use_template=True) # 创建一个text字段 def get_model(self): # 重载get_model方法,必须要有!
return Article def index_queryset(self, using=None):
return self.get_model().objects.all()
为什么要创建索引?
索引就像是一本书的目录,可以为读者提供更快速的导航与查找。在这里也是同样的道理,当数据量非常大的时候,若要从这些数据里找出所有的满足搜索条件的几乎是不太可能的,将会给服务器带来极大的负担。
所以我们需要为指定的数据添加一个索引(目录),在这里是为Note创建一个索引,索引的实现细节是我们不需要关心的,至于为它的哪些字段创建索引,怎么指定 ,下面开始讲解。
每个索引里面必须有且只能有一个字段为 document=True,这代表haystack 和搜索引擎将使用此字段的内容作为索引进行检索(primary field)。其他的字段只是附属的属性,方便调用,并不作为检索数据。
注意:如果使用一个字段设置了document=True,则一般约定此字段名为text,这是在ArticleIndex类里面一贯的命名,以防止后台混乱,当然名字你也可以随便改,不建议改。
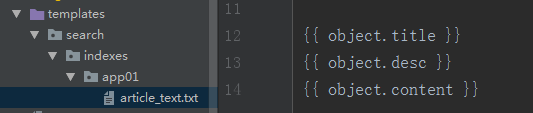
另外,我们在text字段上提供了use_template=True。这允许我们使用一个数据模板(而不是容易出错的级联)来构建文档搜索引擎索引。你应该在模板目录下建立新的模板:'templates/search/indexes/应用名称/' 下创建 '模型类名_text.txt' 文件,并将下面内容放在里面。
{{ object.title }}
{{ object.desc }}
{{ object.content }}
五、设置视图
1、添加SearchView到你的url
在你的urlf中添加下面一行:
url(r'^search/', include('haystack.urls')),
这会拉取Haystack的默认URLconf,它由单独指向SearchView实例的URLconf组成。你可以通过传递几个关键参数或者完全重新它来改变这个类的行为。
2、搜索模板
搜索模板默认在search文件夹下新建search.html文件
<!DOCTYPE html>
<html>
<head>
<title></title>
<style>
span.highlighted {
color: red;
}
</style>
</head>
<body>
{% load highlight %}
{% if query %}
<h3>搜索结果如下:</h3>
{% for result in page.object_list %}
{# <a href="/{{ result.object.id }}/">{{ result.object.title }}</a><br/>#}
<a href="/{{ result.object.id }}/">{% highlight result.object.title with query max_length 2%}</a><br/>
<p>{{ result.object.content|safe }}</p>
<p>{% highlight result.content with query %}</p>
{% empty %}
<p>啥也没找到</p>
{% endfor %} {% if page.has_previous or page.has_next %}
<div>
{% if page.has_previous %}
<a href="?q={{ query }}&page={{ page.previous_page_number }}">{% endif %}« 上一页
{% if page.has_previous %}</a>{% endif %}
|
{% if page.has_next %}<a href="?q={{ query }}&page={{ page.next_page_number }}">{% endif %}下一页 »
{% if page.has_next %}</a>{% endif %}
</div>
{% endif %}
{% endif %}
</body>
</html>
需要注意的是page.object_list实际上是SearchResult对象的列表。这些对象返回索引的所有数据。它们可以通过{{result.object}}来访问。所以{{ result.object.title}}实际使用的是数据库中Article对象来访问title字段的。
3、重建索引
现在已经配置好了所有的事情,是时候把数据库中的数据放入索引了。Haystack附带的一个命令行管理工具使它变得很容易:rebuild_index。你会得到有多少模型进行了处理并放进索引的统计。

六、使用jieba分词
1、新建ChineseAnalyzer.py文件,保存在haystack的安装文件夹下,路径如:D:\python36\Lib\site-packages\haystack\backends,里面写入代码
import jieba
from whoosh.analysis import Tokenizer, Token class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t def ChineseAnalyzer():
return ChineseTokenizer()
2、复制whoosh_backend.py文件,改名为whoosh_cn_backend.py
里面写入from .ChineseAnalyzer import ChineseAnalyzer,这个地方注意:复制出来的文件名,末尾会有一个空格,记得要删除这个空格。
查找 analyzer=StemmingAnalyzer() 改为 analyzer=ChineseAnalyzer()

七、在模板中创建搜索栏
新建index.htm文件写入
<form method='get' action="/search/" target="_blank">
<input type="text" name="q">
<input type="submit" value="查询">
</form>
然后配置路由
url(r'^index/', views.index),
写视图函数,把页面返回
def index(request):
return render(request, 'index.html')
前端展示
八、需要的配置已经配置好了,下面开始检索

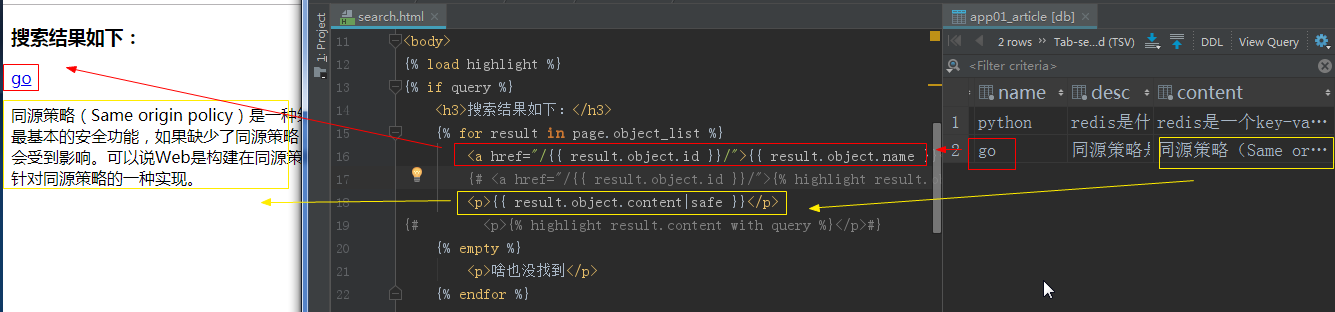
这个是没有用高亮,下面可以用高亮显示(highlight)
高亮:
{% highlight result.summary with query %}
# 这里可以限制最终{{ result.summary }}被高亮处理后的长度
{% highlight result.summary with query max_length 40 %}
# html中
<style>
span.highlighted {
color: red;
}
</style>

总结
用在网站的搜索 django上的haystack框架,底层引擎还是需要第三方
引擎whoosh,solr,es
操作步骤:
1 把haystack 配置到app中
2 配置使用哪个引擎
3 创建索引 :在app下创建一个search_indexes.py 的文件,在里面写一个类
4 创建一个模板:写的是索引:templates/search/indexes/应用名称/”下创建“模型类名称_text.txt,在其中写要创建索引的字段
5 配置一条路由
6 在页面上写form表单
<form method='get' action="/search/" target="_blank">
<input type="text" name="q">
<input type="submit" value="查询">
</form>
7 search.html页面,用户查询结果的展示(highlight标签可以控制查询结果中关键字变红)
8 重建索引 rebuild_index
9 结巴分词,把很长一段文字分成一个个单词
-修改源码
10 增加返回的数据,做成前后端分离,写一个类继承SearchView
项目代码
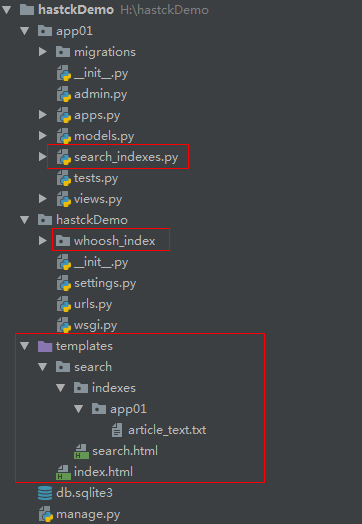
class Article(models.Model):
name = models.CharField(max_length=32)
desc = models.CharField(max_length=128)
content = models.TextField()
models.py
from haystack import indexes
from app01.models import Article class ArticleIndex(indexes.SearchIndex, indexes.Indexable):
# 类名必须为需要检索的Model_name+Index,这里需要检索Article,所以创建ArticleIndex
text = indexes.CharField(document=True, use_template=True) # 创建一个text字段 def get_model(self): # 重载get_model方法,必须要有!
return Article def index_queryset(self, using=None):
return self.get_model().objects.all()
search_indexes.py
def index(request):
return render(request, 'index.html')
views.py
from django.conf.urls import url, include
from django.contrib import admin
from app01 import views urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^search/', include('haystack.urls')),
url(r'^index/', views.index),
]
urls.py
{{ object.title }}
{{ object.desc }}
{{ object.content }}
article_text.txt
<!DOCTYPE html>
<html>
<head>
<title></title>
<style>
span.highlighted {
color: red;
}
</style>
</head>
<body>
{% load highlight %}
{% if query %}
<h3>搜索结果如下:</h3>
{% for result in page.object_list %}
<a href="/{{ result.object.id }}/">{{ result.object.name }}</a><br/>
{# <a href="/{{ result.object.id }}/">{% highlight result.object.name with query max_length 2 %}</a><br/>#}
{# <p>{{ result.object.content|safe }}</p>#}
<p>{% highlight result.object.content with query max_length 4 %}</p>
{% empty %}
<p>啥也没找到</p>
{% endfor %} {% if page.has_previous or page.has_next %}
<div>
{% if page.has_previous %}
<a href="?q={{ query }}&page={{ page.previous_page_number }}">{% endif %}« 上一页
{% if page.has_previous %}</a>{% endif %}
|
{% if page.has_next %}<a href="?q={{ query }}&page={{ page.next_page_number }}">{% endif %}下一页 »
{% if page.has_next %}</a>{% endif %}
</div>
{% endif %}
{% endif %}
</body>
</html>
search.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title> </head>
<body>
<form method='get' action="/search/" target="_blank">
<input type="text" name="q">
<input type="submit" value="查询">
</form>
</body>
</html>
index.html
Haystack全文检索框架的更多相关文章
- 全文检索框架---Lucene
一.什么是全文检索 1.数据分类 我们生活中的数据总体分为两种:结构化数据和非结构化数据. 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等. 非结构化数据:指不定长或无固定格式 ...
- Haystack Python全文检索框架
Haystack 1.什么是Haystack Haystack是django的开源全文搜索框架(全文检索不同于特定字段的模糊查询,使用全文检索的效率更高 ),该框架支持Solr,Elasticsear ...
- Haystack全文检索
1.什么是Haystack Haystack是django的开源全文搜索框架(全文检索不同于特定字段的模糊查询,使用全文检索的效率更高 ),该框架支持Solr,Elasticsearch(java写的 ...
- Django:haystack全文检索详细教程
参考:https://blog.csdn.net/AC_hell/article/details/52875927 一.安装第三方库及配置 1.1 安装插件 pip install whoosh dj ...
- Haystack搜索框架
1.什么是Haystack Haystack是django的开源全文搜索框架(全文检索不同于特定字段的模糊查询,使用全文检索的效率更高 ),该框架支持Solr,Elasticsearch,Whoosh ...
- Haystack--基于Django的全文检索框架
好文章转载自:https://suguangti.cnblogs.com/p/11167097.html 阅读目录 1.什么是Haystack 2.安装 3.配置 4.处理数据 创建索引 5.设置视图 ...
- Django Haystack 全文检索与关键词高亮
Django Haystack 简介 django-haystack 是一个专门提供搜索功能的 django 第三方应用,它支持 Solr.Elasticsearch.Whoosh.Xapian 等多 ...
- Solr全文检索框架
概述: 什么是Solr? Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务.Solr可以独立运行在Jetty.tomcat.webLogic.webSh ...
- Lucene全文检索框架
1.什么时Lucene? 是一个全文搜索框架,而不是应用产品,他只是一种工具让你能实现某些产品,并不像www.baidu.com拿来就能用 是apache组织的一个用java实现的全文搜索引擎的开源项 ...
随机推荐
- 从入门到自闭之Python函数初识
函数初识 定义:def--关键字 将某个功能封装到一个空间中就是一个函数 功能: 减少重复代码 函数的调用 函数名+():调用函数和接收返回值 函数的返回值 return 值 == 返回值 ...
- Python和其他编程语言
Python和其他编程语言 一.Python介绍 Python的创始人为吉多·范罗苏姆(Guido van Rossum),如下图,少数几个不秃头的语言创始人.1989年的圣诞节期间,Guido为了打 ...
- SQL学习(一)之简介
什么是 SQL? SQL 指结构化查询语言(Structured Query Language) SQL 使我们有能力访问数据库 SQL 是一种 ANSI 的标准计算机语言 SQL 能做什么? SQL ...
- opencv中的高维矩阵Mat
本示例程序主要是通过实例演示高维Mat的寻址方式. //3,4分别表示行数.列数,所以3*4是一个页面的元素数,2表示有2个3*4 ,b=,c=; int size[]={a,b,c}; float* ...
- 用SVM处理XSS时,数据清洗打标数据标准化处理的方法和意义
def get_len(url): return len(url) def get_url_count(url): if re.search('(http://)|(https://)', url, ...
- ubuntu - 如何以root身份使用图形界面管理文件?
nautilus 是gnome的文件管理器,但是如果不是root账号下,权限受限,我们可以通过以下方式以root权限使用! 一,快捷键“ctrl+alt+t”,调出shell. 二,在shell中输入 ...
- Python内置函数清单
作者:Vamei 出处:http://www.cnblogs.com/vamei Python内置(built-in)函数随着python解释器的运行而创建.在Python的程序中,你可以随时调用这些 ...
- Ubuntu与centos的区别小用法
给root设置密码 更新软件下载的地址 安装指令apt 使用ssh登录Ubuntu 使用ssh登录Ubuntu必须注意的地方,要先配置 sudo vi /etc/ssh/sshd_config 找到: ...
- 使用QEMU模拟树莓派
QEMU上的树莓派 我们开始设置一个Lab VM.我们将使用Ubuntu并在其中模拟我们所需的ARM版本. 首先,获取最新的Ubuntu版本并在VM中运行它: https://www.ubuntu.c ...
- Linux umask 档案预设权限/touch 建立空档案或修档案件时间
1 建立档案时,权限一般设为-rw-r--r-- 2 建立目录时,权限一般设为drwxr-xr-x 3 touch 选项与参数 -a : 仅修订access time -c :仅修改档案的时间,若该 ...