模型层ORM操作
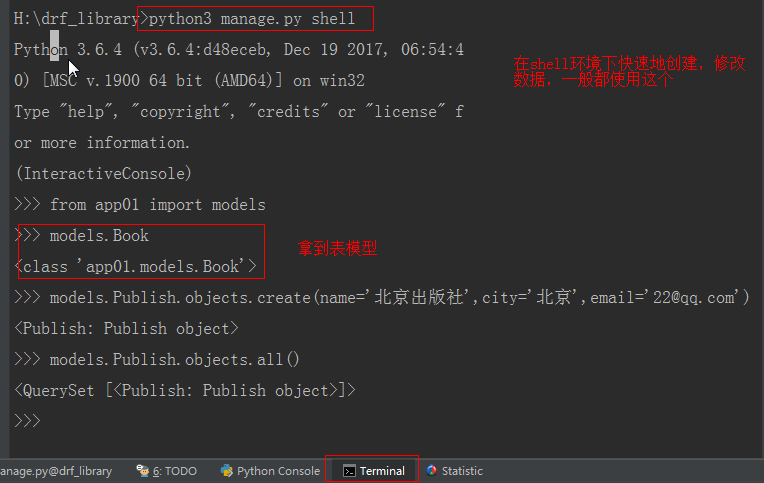
shell环境使用
新增:
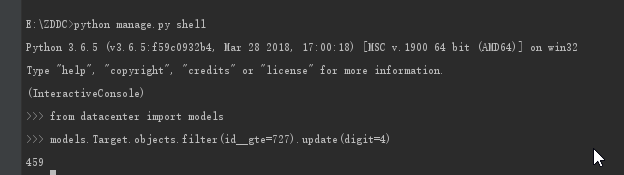
修改:

一、ORM操作
1、关键性字段及参数
DateField 年月日
DateTimeField 年月日时分秒
auto_now: 每次操作改数据都会自动更新时间
auto_now_add: 新增数据的时候会将当前时间自动添加,后续的修改该字段不会自动更新
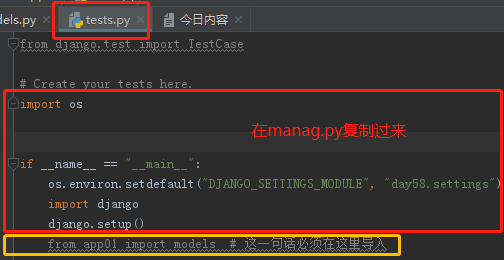
2、单独的py文件测试ORM操作需要配置的参数
在Python脚本中调用Django环境
3、django终端打印sql语句配置的参数
# 如果你想知道你对数据库进行操作时,Django内部到底是怎么执行它的sql语句时可以加下面的配置来查看
# 在Django项目的settings.py文件中,在最后复制粘贴如下代码: LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
} # 配置好之后,再执行任何对数据库进行操作的语句时,会自动将Django执行的sql语句打印到pycharm终端上 # 补充:除了配置外,还可以通过一点.query即可查看查询语句:
user_obj = models.User.objects.all()
print(user_obj.query)
二、ORM单表操作
from django.db import models # Create your models here. # 单表查询
# class User(models.Model):
# name = models.CharField(max_length=32)
# age = models.IntegerField()
# register_time = models.DateField()
# def __str__(self):
# return '对象的名字:%s' % self.name # 多表查询
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8, decimal_places=2)
publish_date = models.DateField(auto_now_add=True)
# 外键关系
publish = models.ForeignKey(to='Publish') # 书籍和出版社是一对多的关系
authors = models.ManyToManyField(to='Author') # 书籍和作者是多对多的关系 def __str__(self):
return '书籍对象的名字:%s' % self.title class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=32)
email = models.EmailField() # 对应就是varchar类型 def __str__(self):
return '出版社对象的名字:%s' % self.name class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
# 外键关系
authordetail = models.OneToOneField(to='AuthorDetail') # 作者和作者详情是一对一的关系 def __str__(self):
return '作者对象的名字:%s' % self.name class AuthorDetail(models.Model):
phone = models.CharField(max_length=32)
addr = models.CharField(max_length=32)
1、新增数据
# ①基于create创建
user_obj = models.User.objects.create(name='jason', age=73, register_time='2019-6-12')
print(user_obj.register_time) # ②基于对象的绑定方法创建
user_obj = models.User(name='egon', age=46, register_time='2018-6-12')
user_obj.save()
2、修改数据
# ①基于queryset
models.User.objects.filter(name='egon').update(age=30) # ②基于对象
user_obj = models.User.objects.filter(name='jason').first()
user_obj.age = 28
user_obj.save()
3、删除数据
# ①基于queryset
models.User.objects.filter(name='egon').delete() # ②基于对象
user_obj = models.User.objects.filter(name='owen').first()
user_obj.delete()
4、查询数据
①基于对象的表查询
# < 1 > all(): 查询所有结果
res = models.User.objects.all()
print(res) # < 2 > filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
res = models.User.objects.filter(name='jason', age=28)
# filter内可以放多个限制条件但是需要注意的是多个条件之间是and关系
print(res) # < 3 > get(**kwargs)
# 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。不推荐使用 # < 4 > exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
res = models.User.objects.exclude(name='jason')
print(res) # < 5 > order_by(*field): 对查询结果排序('-id') / ('price')
res = models.User.objects.order_by('age') # 默认是升序
res = models.User.objects.order_by('-age') # 可以在排序的字段前面加一个减号就是降序
res = models.User.objects.order_by('name')
res = models.User.objects.order_by('-name')
print(res) # < 6 > reverse(): 对查询结果反向排序,前面要先有排序才能反向
res = models.User.objects.order_by('age').reverse()
print(res) # < 7 > count(): 返回数据库中匹配查询(QuerySet) 的对象数量。
# 只要是queryset对象就可以无限制的点queryset方法
res = models.User.objects.count()
res = models.User.objects.all().count()
print(res) # < 8 > first(): 返回第一条记录
res = models.User.objects.all().first()
res = models.User.objects.all()[0] # 不支持负数的索引取值
print(res) # < 9 > last(): 返回最后一条记录
res = models.User.objects.all().last()
print(res) # < 10 > exists(): 如果QuerySet包含数据,就返回True,否则返回False
res = models.User.objects.all().exists()
res1 = models.User.objects.filter(name='jerry').exists()
print(res, res1) # < 11 > values(*field): 返回一个ValueQuerySet:一个特殊的QuerySet,运行后得到的并不是一系列
# model的实例化对象,而是一个可迭代的字典序列
res = models.User.objects.values('name') # 列表套字典
res = models.User.objects.values('name', 'age') # 列表套字典
# print(res) # < 12 > values_list(*field):
# 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
res = models.User.objects.values_list('name','age') # 列表套元组
print(res) # < 13 > distinct(): 从返回结果中剔除重复纪录 去重的对象必须是完全相同的数据才能去重
res = models.User.objects.values('name','age').distinct()
print(res)
②基于双下划线的表查询
# <1>年纪: 大于 小于 大于等于 小于等于 在几个条件中 在某个范围内
# 查询年轻大于30岁的用户
res = models.User.objects.filter(age__gt=30)
print(res) # 查询年轻小于30岁的用户
res = models.User.objects.filter(age__lt=30)
print(res) # 查询年轻大于等于30岁的用户
res = models.User.objects.filter(age__gte=30)
print(res) # 查询年轻小于等于30岁的用户
res = models.User.objects.filter(age__lte=30)
print(res) # 查询年龄是28或者30或者59的用户
res = models.User.objects.filter(age__in=[28, 30, 59])
print(res) # 查询年龄在28到30范围内
res = models.User.objects.filter(age__range=[28, 30])
print(res) # <2>以什么开头 以什么结尾
# 查询名字以j开头的用户
es = models.User.objects.filter(name__startswith='j')
print(res) # 查询名字以k结尾的用户
res = models.User.objects.filter(name__endswith='k')
print(res) # <3>按年查询
# 查询注册是在2019年的用户
res = models.User.objects.filter(register_time__year=2019)
print(res) # <4>模糊查询
# 查询名字中包含字母n的用户, 注意sqlite数据库演示不出来大小写的情况
res = models.User.objects.filter(name__contains='n') # 排除大写
res = models.User.objects.filter(name__icontains='n') # 忽略大小写
print(res)
③F与Q 查询
class Produce(models.Model):
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8, decimal_places=2)
sell = models.IntegerField()
stock = models.IntegerField() def __str__(self):
return '商品对象的名字:%s' % self.name
models.py
F查询:F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
# <1>查询卖出数大于库存的商品
res = models.Produce.objects.filter(sell__gt=F('stock'))
print(res) # <2>将所有的商品的价格提高100块
models.Produce.objects.update(price=F('price')+100) # <3>将所有商品的名字后面都加上'爆款'(这个时候需要对字符串进行拼接Concat操作,并且要加上拼接值Value)
from django.db.models.functions import Concat
from django.db.models import Value
models.Produce.objects.update(name=Concat(F('name'), Value('爆款')))
Q查询:filter() 等方法中逗号隔开的条件是与(and)的关系。 如果你需要执行更复杂的查询(例如or),你可以使用Q对象。
from django.db.models import F, Q
res = models.Produce.objects.filter(Q(price=199.99), Q(name='裤子爆款')) # and
print(res) res = models.Produce.objects.filter(Q(price=199.99) | Q(name='裤子爆款')) # or
print(res) res = models.Produce.objects.filter(Q(price=199.99) | ~Q(name='裤子爆款')) # not
print(res) # 混合使用:需要注意的是Q对象必须放在普通的过滤条件前面
res = models.Product.objects.filter(~Q(name='连衣裙爆款'),price=188.88)
print(res)
# Q对象补充(*****):通过字符串而不是变量名
from django.db.models import F, Q
q = Q()
# q.connector = 'or' # 通过这个参数可以将Q对象默认的and关系变成or
q.children.append(('name', '衣服爆款'))
q.children.append(('name', '裤子爆款'))
res = models.Produce.objects.filter(q)
print(res)
④事务
from django.db import transaction
from django.db.models import F
with transaction.atomic():
# 在with代码块写你的事物操作
models.Produce.objects.filter(id=1).update(stock=F('stock')-1)
models.Produce.objects.filter(id=1).update(sell=F('sell')+1)
# 写其他逻辑代码
print('大卖')
⑤only与defer:拿到的是一个对象,两者是相反的
only:能够帮你拿到一个对象,能够直接点自己有的字段,不会走数据库,如果点其他字段,会频繁地走数据库,拖慢数据库运行效率
defer:能够帮你拿到一个对象,能够直接点自己有的字段,频繁地走数据库,如果点其他字段,不会走数据库
res = models.Produce.objects.values('name')
res = models.Produce.objects.only('name') # 只查一个name属性
res = models.Produce.objects.defor('name') # 除了name,其他的都要
print(res)
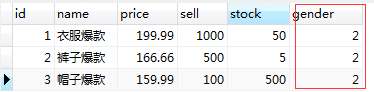
⑥choices参数
models.py:
class Produce(models.Model):
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8, decimal_places=2)
sell = models.IntegerField()
stock = models.IntegerField() # choices参数
choices = ((1, '男'), (2, '女'), (3, '其他'))
gender = models.IntegerField(choices=choices, default=2) def __str__(self):
return '商品对象的名字:%s' % self.name
text.py:
res = models.Produce.objects.filter(id=1).first()
print(res.gender) # 拿出来的是一个性别对应的数字,展示的应该是性别,用到下面的
print(res.get_gender_display()) # 展示的不是数字,而是男或女 # models.Product.objects.create(...gender=1) # 展示的是男或者女,但是数据库存的是对应的数字
三、ORM多表操作
表与表之间的关系:
一对一(OneToOneField):一对一字段无论建在哪张关系表里面都可以,但是推荐建在查询频率比较高的那张表里面
一对多(ForeignKey):一对多字段建在多的那一方
多对多(ManyToManyField):多对多字段无论建在哪张关系表里面都可以,但是推荐建在查询频率比较高的那张表里面
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8, decimal_places=2)
publish_date = models.DateField(auto_now_add=True)
# 外键关系
publish = models.ForeignKey(to='Publish') # 书籍和出版社是一对多的关系
authors = models.ManyToManyField(to='Author') # 书籍和作者是多对多的关系 def __str__(self):
return '书籍对象的名字:%s' % self.title class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=32)
email = models.EmailField() # 对应就是varchar类型 def __str__(self):
return '出版社对象的名字:%s' % self.name class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
# 外键关系
authordetail = models.OneToOneField(to='AuthorDetail') # 作者和作者详情是一对一的关系 def __str__(self):
return '作者对象的名字:%s' % self.name class AuthorDetail(models.Model):
phone = models.CharField(max_length=32)
addr = models.CharField(max_length=32)
models.py
1、一对多字段
①新增数据
# ①直接写id
models.Book.objects.create(title='红楼梦', price=66.66, publish_id=1)
# ②传数据对象
publish_obj = models.Publish.objects.filter(pk=2).first()
models.Book.objects.create(title='三国演义', price=199.99, publish=publish_obj)
②修改数据
# ①queryset修改
models.Book.objects.filter(pk=1).update(publish_id=3) # ②对象修改
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.publish_id = 1
book_obj.save()
③删除数据
# ①基于filter
models.Book.objects.filter(pk=1).delete() # 书籍删除
models.Publish.objects.filter(pk=1).delete() # 出版社删除,关联的书籍也跟着删除 # ②基于数据
book_obj = models.Book.objects.filter(pk=2).first()
book_obj.delete()
2、多对多字段:给书籍绑定与作者之间的关系
①添加关系 add:add支持传数字或对象,并且都可以传多个
# ①基于数字
book_obj = models.Book.objects.filter(pk=5).first()
book_obj.authors.add(1)
book_obj.authors.add(1, 2, 3) # ②基于对象
book_obj = models.Book.objects.filter(pk=5).first()
author_obj = models.Author.objects.filter(pk=1).first()
author_obj1 = models.Author.objects.filter(pk=2).first()
author_obj2 = models.Author.objects.filter(pk=3).first()
book_obj.authors.add(author_obj, author_obj1, author_obj2)
②修改关系 set():可以传数字和对象,并且支持传多个,set传的必须是可迭代对象
# ①基于数字
book_obj = models.Book.objects.filter(pk=5).first()
book_obj.authors.set((1,))
book_obj.authors.set((1, 2, 3)) # ②基于对象
author_list = models.Author.objects.all()
book_obj = models.Book.objects.filter(pk=5).first()
book_obj.authors.set(author_list)
③删除关系 remove
# ①基于数字
book_obj = models.Book.objects.filter(pk=5).first()
book_obj.authors.remove(1)
book_obj.authors.remove(1, 2, 3) # ②基于对象
book_obj = models.Book.objects.filter(pk=5).first()
author_list = models.Author.objects.all()
book_obj.authors.remove(*author_list) # 需要将queryset打散
④清空关系 clear :清空的是你当前这个表记录对应的绑定关系
book_obj = models.Book.objects.filter(pk=5).first()
book_obj.authors.clear()
3、多表跨表查询
正向与反向的概念:
正向:关联字段在你当前这张表,查询另一张
反向:关联字段不在你当前这张表,查询另张表
总结:正向查询按字段,反向查询按表名小写点方法
# 一对一
正向:author---关联字段在author表里--->authordetail 按字段
反向:authordetail---关联字段在author表里--->author 按表名小写
查询jason作者的手机号 正向查询
查询地址是 :山东 的作者名字 反向查询 # 一对多
正向:book---关联字段在book表里--->publish 按字段
反向:publish---关联字段在book表里--->book 按表名小写_set.all() 因为一个出版社对应着多个图书 # 多对多
正向:book---关联字段在book表里--->author 按字段
反向:author---关联字段在book表里--->book 按表名小写_set.all() 因为一个作者对应着多个图书
①基于对象的跨表查询(子查询)
# 正向
# 查询书籍是西游记的出版社邮箱
book_obj = models.Book.objects.filter(title='西游记').first()
print(book_obj.publish.email) # 查询书籍是聊斋的作者的姓名
book_obj = models.Book.objects.filter(title='聊斋').first()
print(book_obj.authors) # app01.Author.None
print(book_obj.authors.all()) # 查询作者为jason电话号码
user_obj = models.Author.objects.filter(name='jason').first()
print(user_obj.authordetail.phone)
# 反向
# 查询出版社是东方出版社出版的书籍 一对多字段的反向查询
publish_obj = models.Publish.objects.filter(name='东方出版社').first()
print(publish_obj.book_set) # app01.Book.None
print(publish_obj.book_set.all()) # 查询作者jason写过的所有的书 多对多字段的反向查询
author_obj = models.Author.objects.filter(name='jason').first()
print(author_obj.book_set) # app01.Book.None
print(author_obj.book_set.all()) # 查询作者电话号码是130的作者姓名 一对一字段的反向查询
authordetail_obj = models.AuthorDetail.objects.filter(phone=130).first()
print(authordetail_obj.author.name)
②基于双下划线的跨表查询(联表操作)
# 正向
# 查询书籍为西游记的出版社地址
res = models.Book.objects.filter(title='西游记').values('publish__addr', 'title')
print(res) # 查询书籍为聊斋的作者的姓名
res = models.Book.objects.filter(title='聊斋').values('authors__name', 'title')
print(res) # 查询作者为jason的家乡
res = models.Author.objects.filter(name='jason').values('authordetail__addr')
print(res)
# 反向
# 查询南方出版社出版的书名
res = models.Publish.objects.filter(name='南方出版社').values('book__title')
print(res) # 查询电话号码为120的作者姓名
res = models.AuthorDetail.objects.filter(phone=120).values('author__name')
print(res) # 查询作者为jason的写的书的名字
res = models.Author.objects.filter(name='jason').values('book__title')
print(res) # 查询书籍为西游记的作者的电话号码
res = models.Book.objects.filter(title='西游记').values('authors__authordetail__phone')
print(res)
③聚合查询 aggregate
from django.db.models import Max, Min, Count, Sum, Avg # 查询所有出版社出版的书的平均价格
res = models.Publish.objects.aggregate(avg_price=Avg('book__price'))
print(res) # 统计东方出版社出版的书籍的个数
res = models.Publish.objects.filter(name='东方出版社').aggregate(count_num=Count('book__id'))
print(res)
④分组查询 annotate
from django.db.models import Max, Min, Count, Sum, Avg # 统计每个出版社出版的书的平均价格
res = models.Publish.objects.annotate(avg_price=Avg('book__price')).values('name', 'avg_price')
print(res) # 统计每一本书的作者个数
res = models.Book.objects.annotate(count_num=Count('authors')).values('title', 'count_num')
print(res) # 统计出每个出版社卖的最便宜的书的价格
res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name', 'min_price')
print(res) # 查询每个作者出的书的总价格
res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name', 'sum_price')
print(res)
四、Django模型Model自定义表名和字段名
1、默认情况下:
Django模型Model的类名为:应用名+下划线+模型类名,如app01应用下的Book模型,对应的数据表为app01_book
Django模型Model的属性名即为字段名
2、自定义配置:
字段配置参数db_column指定表字段列名:db_column='book_name'
模型Model内部类Meta指定数据表名:db_table = 'z_book' class Book(models.Model):
name = models.CharField(name='书名', max_length=64, db_column='book_name') # 字段名由 'book' 改为 'book_name'
author = models.ManyToManyField(Author)
pub_date = models.DateField(name='出版日期') def __str__(self):
return self.name class Meta:
db_table = "z_book" # 表名由 '应用名_book' 改为 'z_book'
优化查询select_related和prefetch_related
一、select_related查询优化
select_related通过多表join关联查询,一次性获得所有数据,通过降低数据库查询次数来提升性能,但关联表不能太多,因为join操作本来就比较消耗性能。
本文通过Django debug toolbar工具来直观显示查询次数、查询语句,如果不会使用“Django debug toolbar”工具,可以翻看我之前写的博客,从而配置它!
model.Book.objects.all().select_related()
model.Book.objects.all().select_related('外键字段')
model.Book.objects.all().select_related('外键字段__外键字段')
models.py:
from django.db import models class Publisher(models.Model):
name = models.CharField(max_length=30, verbose_name="名称")
address = models.CharField("地址", max_length=50)
city = models.CharField('城市', max_length=60)
state_province = models.CharField(max_length=30)
country = models.CharField(max_length=50)
website = models.URLField()
class Author(models.Model):
name = models.CharField(max_length=30)
hobby = models.CharField(max_length=20, default="", blank=True)
class Book(models.Model):
title = models.CharField(max_length=100, verbose_name="书名")
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher, verbose_name="出版社")
publication_date = models.DateField(null=True)
price = models.DecimalField(max_digits=5, decimal_places=2, default=10, verbose_name="价格")
views.py:
def index(request):
obj = Book.objects.all()
return render(request, "index.html", locals())
book.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p>django debug toolbar!</p>
{% for item in obj %}
<div>{{ item.title }} {{ item.price }} {{ item.publisher.name }}</div>
{% endfor %}
</body>
</html>
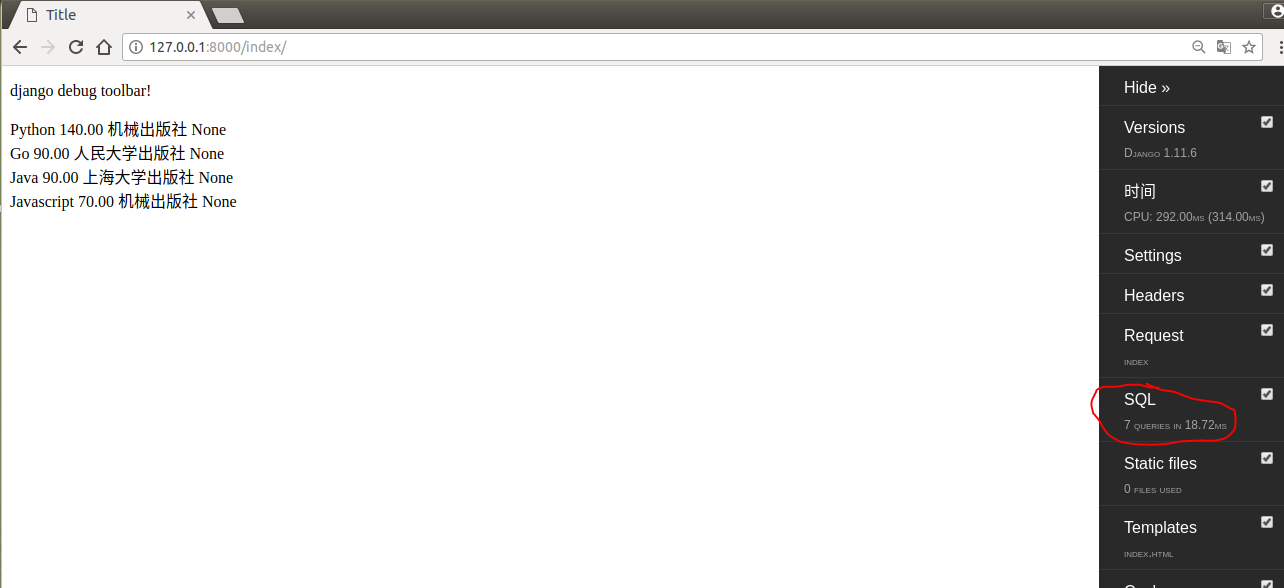
当我们没有使用select_related时,在前端模板中,每一次循环就要向数据库发送一次请求,因为我表中数据很少,所有只发起了7次查询,
但实际生产中每个表的数据肯定是成千上万的,传统的操作对数据库的性能影响很大!
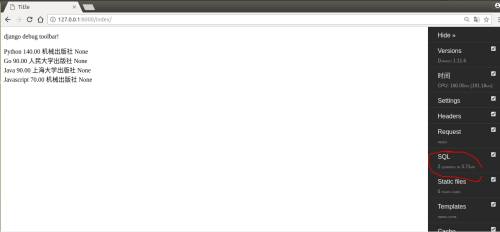
当我们使用select_related连表操作时,请看下例,只发起了两次查询
def index(request):
obj = Book.objects.all().select_related("publisher")
return render(request, "index.html", locals())
总结:
select_related主要针一对一和多对一关系进行优化。
select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。
可以通过可变长参数指定需要select_related的字段名。也可以通过使用双下划线“__”连接字段名来实现指定的递归查询(也就是外键的外键,多层连表查询)。没有指定的字段不会缓存,没有指定的深度不会缓存,如果要访问的话Django会再次进行SQL查询。
二、prefetch_related查询优化
prefetch_related()和select_related()的设计目的很相似,都是为了减少SQL查询的数量,但是实现的方式不一样。后者是通过JOIN语句,在SQL查询内解决问题。
但是对于多对多关系,使用SQL语句解决就显得有些不太明智,因为JOIN得到的表将会很长,会导致SQL语句运行时间的增加和内存占用的增加。prefetch_related()的解决方法是,分别查询每个表,然后用Python处理他们之间的关系!
models.Book.objects.prefetch_related('外键字段')
我们还是通过上例来举例:
def index(request):
obj = Book.objects.all().prefetch_related("publisher")
return render(request, "index.html", locals())
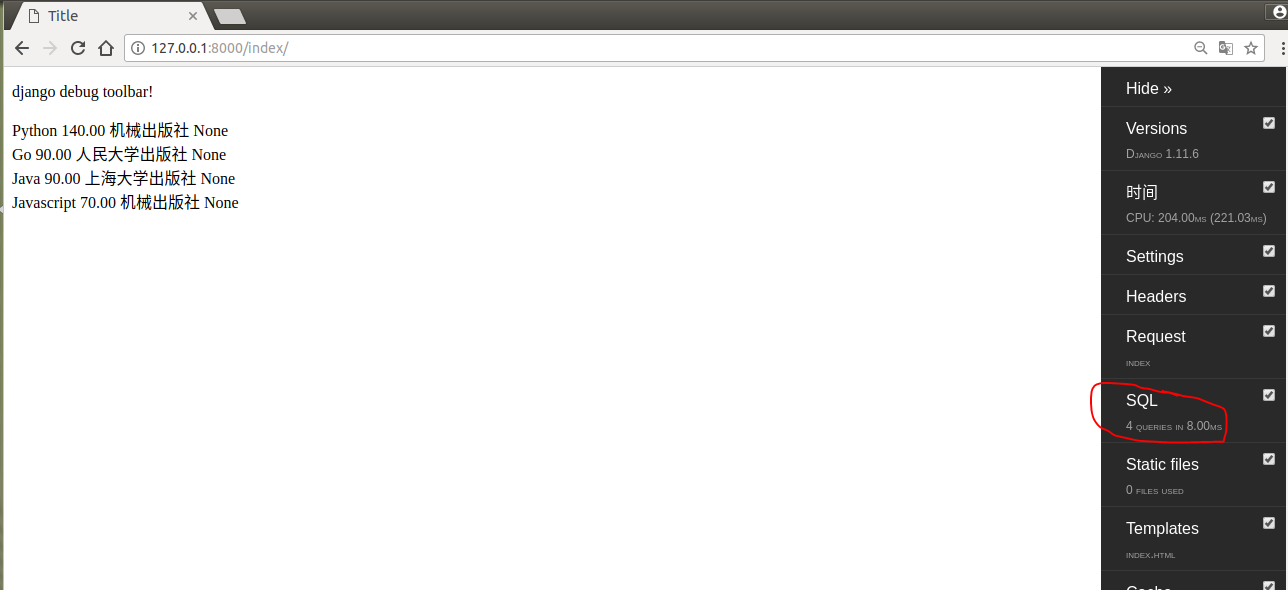
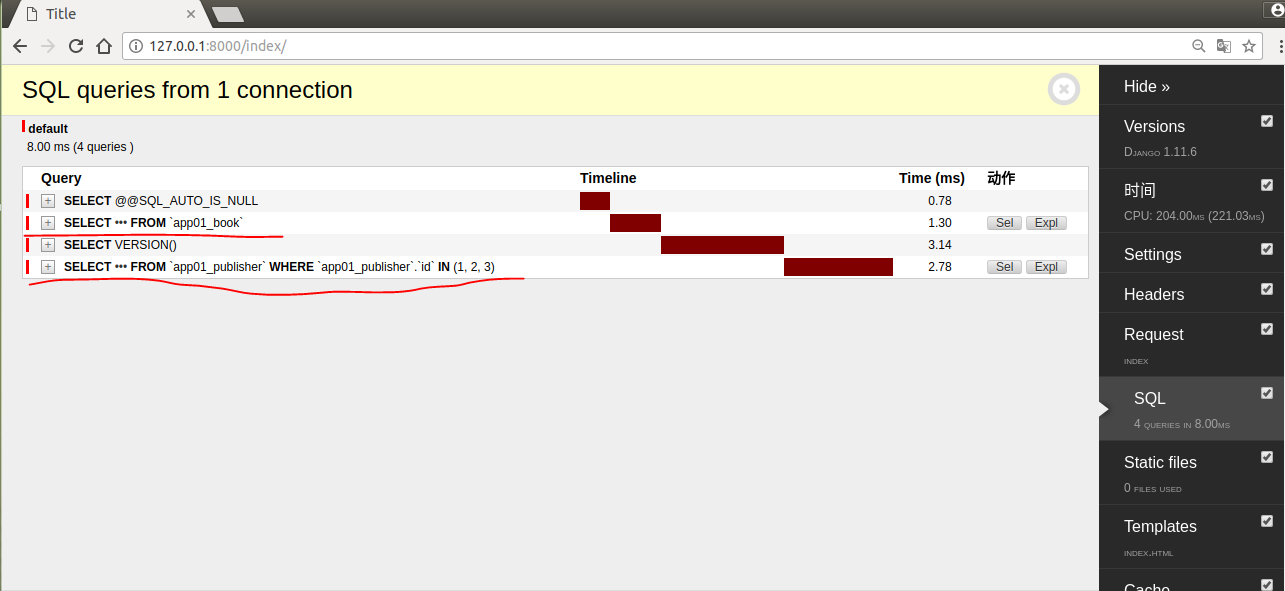
使用prefetch_related优化查询,貌似发起了四次数据库请求,但实际是只有两次的,就是图中划横线的SQL语句,其他两条是session相关的,我们不用理会。
我来解释一下prefetch_related是怎么发起请求的,第一步:先拿到book表的所有数据;第二步:通过select .. from ... where ... in (book表中所有出版社的外键ID)。
这样通过分别发起两次请求,获取了book表以及和book表相关联的publisher表的数据(并不是所有publisher表数据,只有和book表相关联数据!),然后通过Python处理数据的对应关联。
总结:
prefetch_related主要针一对多和多对多关系进行优化。
prefetch_related通过分别获取各个表的内容,然后用Python处理他们之间的关系来进行优化。
两者区别:
select_related是通过join来关联多表,一次获取数据,存放在内存中,但如果关联的表太多,会严重影响数据库性能。
prefetch_related是通过分表,先获取各个表的数据,存放在内存中,然后通过Python处理他们之间的关联。
模型层ORM操作的更多相关文章
- Django 模型层 ORM 操作
运行环境 1. Django:2.1.3 version 2. PyMysql: 0.9.3 version 3. pip :19.0.3 version 4. python : 3.7 versio ...
- python 全栈开发,Day70(模板自定义标签和过滤器,模板继承 (extend),Django的模型层-ORM简介)
昨日内容回顾 视图函数: request对象 request.path 请求路径 request.GET GET请求数据 QueryDict {} request.POST POST请求数据 Quer ...
- Django基础(2)--模板自定义标签和过滤器,模板继承 (extend),Django的模型层-ORM简介
没整理完 昨日回顾: 视图函数: request对象 request.path 请求路径 request.GET GET请求数据 QueryDict {} request.POST POST请求数据 ...
- 1127 模型层orm表操作
目录 昨日回顾 模型层 1.配置测试脚本 1.1 应用下tests文件 1.2 新建任意名称文件 2. 数据的增删改查 2.1 创建数据 2.2 修改数据 2.3 删除数据 2.4查询数据 十三门徒 ...
- Django模型层—ORM
目录 一.模型层(models) 1-1. 常用的字段类型 1-2. 字段参数 1-3. 自定义char字段 1-4. 外键关系 二.Django中测试脚本的使用 三.单表操作 3-1. 添加记录 3 ...
- Django模型层ORM学习笔记
一. 铺垫 1. 连接Django自带数据库sqlite3 之前提到过Django自带一个叫做sqlite3的小型数据库,当我们做本地测试时,可以直接在sqlite3上测试.不过该数据库是小型的,在有 ...
- DjangoMTV模型之model层——ORM操作数据库(基本增删改查)
Django的数据库相关操作 对象关系映射(英语:(Object Relational Mapping,简称ORM),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换.从效果上说 ...
- (17)模型层 -ORM之msql 单表的增、删、改、查 及其他操作
单表操作-增.删.改.查 ret=models.User.objects.filter(id=1) #这里的结果是一个queryset对象 ret=modles.User.Objects.filte ...
- (18)模型层 -ORM之msql 多表操作(字段的属性)
数据库表的对应关系 1.一对一 #关联字段写在那张表都可以 PS:只要写OneToOneField就会自动加一个id 2.一对多 #关系确立,关联字段写在多的一方 3.多对多 #多对多的关系 ...
随机推荐
- CDH5.X文档
属性参数 https://www.cloudera.com/documentation/enterprise/properties.html
- Magento开发基础知识之RequireJs
一.RequireJS概述 RequireJS是一个工具库,主要用于客户端的模块管理.实现异步或动态加载,从而提高代码的性能和可维护性. RequireJS的基本思想是,通过define方法,将代码定 ...
- Scrapy学习(二)
1.在合适的位置创建一个文件夹,创建python虚拟环境: 2.在虚拟环境中安装Scrapy库和pypiwin32库: 命令:pip install scrapy pip install pypiwi ...
- P4304 [TJOI2013]攻击装置
传送门 看到棋盘先黑白染色冷静一下 然后发现...攻击的时候同种颜色不会相互攻击 这样就是个网络流经典套路了,关于这个套路我以前好像写过几题,那边有解释一下:传送门 #include<iostr ...
- webpack3 打包
1. 基于 webpack 3.0 2.步骤.说明 2.1 webpack 本地初始化.安装基本包 npm init > package.json npm i webpack ...
- 【检测工具】keepalived安装及配置
一.keepalived安装 keepalived是一个检测服务器状态的脚本,在高可用机制上经常可以看到它的身影. 在Linux中安装keepalived: 1.在网上直接下载相应的压缩包,推荐链接 ...
- liunx weblogic服务启停脚本
#!/bin/bash #sh xx.sh start xx项目 例如:sh autoWeblogic.sh start bius #经测试发现weblogic 启动大概需要完全启动成功35秒左右 停 ...
- SCC统计
Kosoraju SCC总数及记录SCC所需要的最少边情况 #include<cstdio> ; ; ][N], nxt[][N], v[][N], ed, q[N], t, vis[N] ...
- robotframework ride报错 Keyword 'BuiltIn.Log' expected 1 to 5 arguments, got 12.
错误原因,else和else if使用了小写,必须使用大写才能识别到.
- python 类的成员及继承
1. @staticmethod 静态方法 静态方法不能访问实例变量和类变量,除了身处类里面,所以只能通过类调用以外,它其实和类没有什么关系.如果想要用它访问实例变量或类变量,需要把实例和类传递给函数 ...