Kaggle试水之泰坦尼克灾难
比赛地址:https://www.kaggle.com/c/titanic
再次想吐槽CSDN,编辑界面经常卡死,各种按钮不能点,注释的颜色不能改,很难看清。写了很多卡死要崩溃。
我也是第一次参加这个,代码还是看了一下别人介绍的,修改了错误的代码,并且在自己的理解了改进了一点代码,排名从5900到2200,改进还是不错的。而且目前未做任何参数的微调,仅仅是代码改进了一下。
以下介绍代码及分析过程,编辑界面使用jupyter
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns#可视化工具
import warnings
import re #忽视警告
warnings.filterwarnings('ignore')
#这个是jupyter notebook里的,用于直接显示图像到控制台,其他地方不必
%matplotlib inline
加载文件:
train_data=pd.read_csv('train.csv')
test_data=pd.read_csv('test.csv')
#提取测试id,因为测试数据也要预处理,而后面还要保存结果上传文件
test_x=test_data['PassengerId']
#看一下有哪些特征
test_data.columns

查看一些测试集有哪些特征,结果如下所示,训练集多一个survivor特征
Index(['PassengerId', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch',
'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
我们可以使用一个函数来查看特征的缺失情况,以便处理缺失值。
def missingdata(data):
#isnull函数将DataFrame变为一个True(如果是None或NaN)和False的类数组结构
#sum统计的是缺失的,即isnull后为True的
#count统计全部,不论为True还是False。但不能直接用count,否则缺失的不会统计
total = data.isnull().sum().sort_values(ascending = False)
percent = (data.isnull().sum()/data.isnull().count()*100).sort_values(ascending = False)
#axis:应该是0为竖直方向拼接,即拼接在行后,1为按列拼接,类似table添加column
#concat调用时在jupyter下自动绘表
ms=pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
#去除百分比为0的属性
ms= ms[ms["Percent"] > 0]
f,ax =plt.subplots(figsize=(8,6))
plt.xticks(rotation='')
fig=sns.barplot(ms.index, ms["Percent"],color="green",alpha=0.8)
plt.xlabel('Features', fontsize=15)
plt.ylabel('Percent of missing values', fontsize=15)
plt.title('Percent missing data by feature', fontsize=15)
return ms
调用函数missingdata(test_data) 显示如下图:

以上是测试数据的丢失情况,将Fare改为Embarked,就是训练数据的丢失情况。
下面处理丢失情况,可以用众数、平均数或中位数来填充缺失数据。对于港口,我们使用第一个代替,对于年龄和票价,使用中位数填充。
#训练数据 train_data['Embarked'].fillna(train_data['Embarked'][0],inplace=True) train_data['Age'].fillna(train_data['Age'].median(),inplace=True) #测试数据 test_data['Age'].fillna(test_data['Age'].median(),inplace=True) test_data['Fare'].fillna(test_data['Fare'].median(),inplace=True)
然后,对于丢失严重的Cabin和冗余、不必要的特征,可以直接丢掉。
columns=['PassengerId','Ticket','Fare','Cabin'] train_data.drop(columns=columns,inplace=True) test_data.drop(columns=columns,inplace=True)
定义一个函数,获取Name里的称呼
def get_title(name):
title_search = re.search(' ([A-Za-z]+)\.', name)
# If the title exists, extract and return it.
if title_search:
return title_search.group(1)
return ""
将Name特征替换为称呼,并按尊贵级别分类
train_data['Title']=train_data['Name'].apply(get_title)#名字只保留称呼 test_data['Title']=test_data['Name'].apply(get_title) #分为Rare尊贵称呼,以及女士、小姐、男士
train_data['Title'] = train_data['Title'].replace(['Master','Don', 'Rev','Dr', 'Major','Lady',
'Sir', 'Col', 'Capt', 'Countess', 'Jonkheer'], 'Rare') #分出小姐和夫人
train_data['Title'] = train_data['Title'].replace('Mlle', 'Miss')
train_data['Title'] = train_data['Title'].replace('Ms', 'Miss')
train_data['Title'] = train_data['Title'].replace('Mme', 'Mrs') #测试集多了一个Dona
test_data['Title'] = test_data['Title'].replace(['Master','Don','Dona','Rev','Dr', 'Major','Lady',
'Sir', 'Col', 'Capt', 'Countess', 'Jonkheer'], 'Rare') #分出小姐和夫人
test_data['Title'] = test_data['Title'].replace('Mlle', 'Miss')
test_data['Title'] = test_data['Title'].replace('Ms', 'Miss')
test_data['Title'] = test_data['Title'].replace('Mme', 'Mrs')
替换后将旧特征Name去除
test_data.drop(columns=['Name'],inplace=True) train_data.drop(columns=['Name'],inplace=True)
新建一个特征,表示家庭人员数量
#添加一个新特征:家庭人员数量
train_data['FamilySize'] = train_data['SibSp'] + train_data['Parch'] + 1 test_data['FamilySize'] = test_data['SibSp'] + test_data['Parch'] + 1
然后取出旧的特征:
columns=['SibSp','Parch']
#有了新的特征,这2个特征可以去除
train_data.drop(columns=columns,inplace=True) test_data.drop(columns=columns,inplace=True)
我们将年龄进行区段划分,在此之前我统计了一下年龄的分布,当然不同人可能有不同的划分。
#将年龄划分一下区段
train_data['Age_bin']=pd.cut(train_data['Age'],bins=[0,14,20,50,100],labels=['Children','Teenage','Adult','Elder']) test_data['Age_bin']=pd.cut(test_data['Age'],bins=[0,14,20,50,100],labels=['Children','Teenage','Adult','Elder'])
同样,清除旧的Age特征:
#划分后删除Age特征
train_data.drop(columns=['Age'],inplace=True) test_data.drop(columns=['Age'],inplace=True)
将数据按家庭成员数量进行划分,可以看看家庭成员数量的分布:
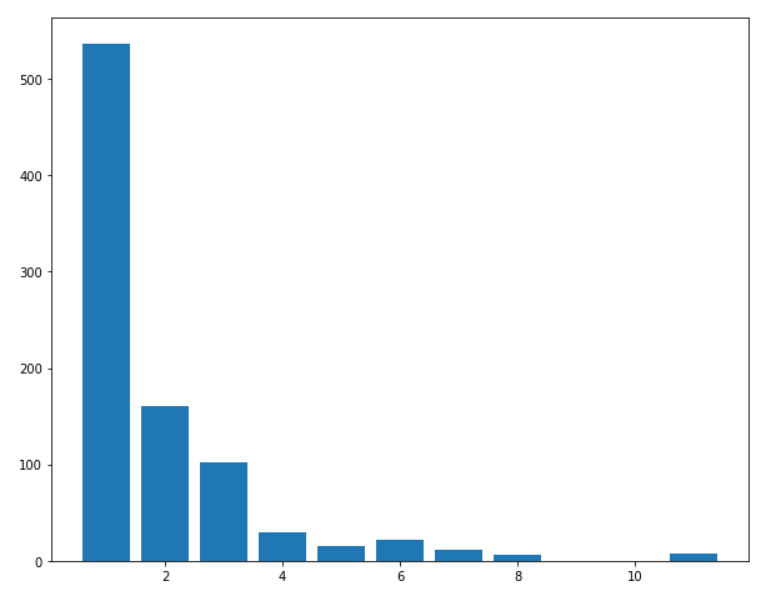
#将家庭大小也分段
train_data['Family_bin']=pd.cut(train_data['FamilySize'],bins=[0,3,7,12],labels=['Small','Medium','Large']) test_data['Family_bin']=pd.cut(test_data['FamilySize'],bins=[0,3,7,12],labels=['Small','Medium','Large'])
去除旧的特征:
#删除旧的特征,到此大概有3*2*3*3*4*3=648理论节点
train_data.drop(columns=['FamilySize'],inplace=True) test_data.drop(columns=['FamilySize'],inplace=True)
接下来使用类似one-hot机制处理数据,并绘制相关图:
图中绿色代表相关性高,可以看到,2个不同的特征之间相关性是很低的,这说明选取的特征较为相互独立。
train_show=pd.get_dummies(train_data,columns=['Pclass', 'Sex', 'Embarked', 'Title', 'Age_bin',
'Family_bin'])
test_show=pd.get_dummies(test_data,columns=['Pclass', 'Sex', 'Embarked', 'Title', 'Age_bin',
'Family_bin'])
sns.heatmap(train_show.corr(),annot=True,cmap='RdYlGn',linewidths=0.2)
fig=plt.gcf()
fig.set_size_inches(20,12)
plt.show()

接下来建立模型
#建模
from sklearn.model_selection import train_test_split #for split the data
from sklearn.metrics import accuracy_score #for accuracy_score
from sklearn.ensemble import RandomForestClassifier #划分训练特征和训练目标标签
data_y=train_show['Survived']
data_x=train_show.drop('Survived',axis=1)#inplace=False #分出验证集
x_train,x_val,y_train,y_val=train_test_split(data_x,data_y,test_size=0.3,random_state=0) model = RandomForestClassifier(n_estimators=700,
max_features='auto',oob_score=True,
random_state=1,n_jobs=-1)
训练模型,看看验证精度,这里验证精度与参考代码差不多,但是后面预测的精度的精度更高。
model.fit(x_train,y_train)
pre_val=model.predict(x_val)
round(accuracy_score(pre_val,y_val)*100,2)#82%左右
使用模型对测试数据进行预测,并存为文件,以便上传打分。
pre_test=model.predict(test_show)
#test_x即最初开始就提取的乘客id,因为预测时这个特征是不用的
result=pd.DataFrame({'PassengerId':test_x, 'Survived':pre_test})
result.to_csv("result.csv", index=False)#存储
至此,只需要将csv文件提交,即可得到一个分数。
Kaggle试水之泰坦尼克灾难的更多相关文章
- Kaggle泰坦尼克数据科学解决方案
原文地址如下: https://www.kaggle.com/startupsci/titanic-data-science-solutions --------------------------- ...
- kaggle之泰坦尼克的沉没
Titanic 沉没 参见:https://github.com/lijingpeng/kaggle 这是一个分类任务,特征包含离散特征和连续特征,数据如下:Kaggle地址.目标是根据数据特征预测一 ...
- Kaggle 泰坦尼克
入门kaggle,开始机器学习应用之旅. 参看一些入门的博客,感觉pandas,sklearn需要熟练掌握,同时也学到了一些很有用的tricks,包括数据分析和机器学习的知识点.下面记录一些有趣的数据 ...
- 利用python进行泰坦尼克生存预测——数据探索分析
最近一直断断续续的做这个泰坦尼克生存预测模型的练习,这个kaggle的竞赛题,网上有很多人都分享过,而且都很成熟,也有些写的非常详细,我主要是在牛人们的基础上,按照数据挖掘流程梳理思路,然后通过练习每 ...
- Kaggle_泰坦尼克乘客存活预测
转载 逻辑回归应用之Kaggle泰坦尼克之灾 此转载只为保存!!! ————————————————版权声明:本文为CSDN博主「寒小阳」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附 ...
- 逻辑回归应用之Kaggle泰坦尼克之灾(转)
正文:14pt 代码:15px 1 初探数据 先看看我们的数据,长什么样吧.在Data下我们train.csv和test.csv两个文件,分别存着官方给的训练和测试数据. import pandas ...
- python__画图表可参考(转自:寒小阳 逻辑回归应用之Kaggle泰坦尼克之灾)
出处:http://blog.csdn.net/han_xiaoyang/article/details/49797143 2.背景 2.1 关于Kaggle 我是Kaggle地址,翻我牌子 亲,逼格 ...
- pytorch kaggle 泰坦尼克生存预测
也不知道对不对,就凭着自己的思路写了一个 数据集:https://www.kaggle.com/c/titanic/data import torch import torch.nn as nn im ...
- Kaggle泰坦尼克-Python(建模完整流程,小白学习用)
参考Kernels里面评论较高的一篇文章,整理作者解决整个问题的过程,梳理该篇是用以了解到整个完整的建模过程,如何思考问题,处理问题,过程中又为何下那样或者这样的结论等! 最后得分并不是特别高,只是到 ...
随机推荐
- 优化oracle读写任务
查读盘次数最多的前十个sql操作: SELECT * FROM (select PARSING_USER_ID, EXECUTIONS, SORTS, COMMAND_TYPE, DISK_READS ...
- BZOJ1050 [HAOI2006]旅行comf[并查集判图连通性]
★ Description 给你一个无向图,N(N<=500)个顶点, M(M<=5000)条边,每条边有一个权值Vi(Vi<30000).给你两个顶点S和T,求 一条路径,使得路径 ...
- DataGridView增加右键取消操作
) { dgvinfo.Rows[e.RowIndex].Selected = true; Point point = dgvinfo.PointToClient(Cursor.Position); ...
- [Linux系统] 如何修改CentOS7网卡名
一.关闭一致性网络设备命名法 cat /etc/sysconfig/grub GRUB_TIMEOUT= GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g ...
- MySQL数据库中的索引(一)——索引实现原理
今天我们来探讨一下数据库中一个很重要的概念:索引. MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构,即索引是一种数据结构. 我们知道,数据库查询是数据库的最主要 ...
- BZOJ 3784: 树上的路径 点分治+二分+set
很容易想出二分这个思路,但是要想办法去掉一个 $log$. 没错,空间换时间. 双指针的部分错了好几次~ Code: #include <set> #include <queue&g ...
- Acwing:137. 雪花雪花雪花(Hash表)
有N片雪花,每片雪花由六个角组成,每个角都有长度. 第i片雪花六个角的长度从某个角开始顺时针依次记为ai,1,ai,2,…,ai,6ai,1,ai,2,…,ai,6. 因为雪花的形状是封闭的环形,所以 ...
- BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm总结
https://blog.csdn.net/liuxiao214/article/details/81037416 http://www.dataguru.cn/article-13032-1.htm ...
- 第六周总结&实验报告四
这周是放国庆节的假,所有没有进行深入的学习,只是写了个实验的题目,也发现了自己在基础上还是要加强学习. 实验四 类的继承 一. 实验目的 (1) 掌握类的继承方法: (2) 变量的继承和覆盖,方法的继 ...
- 【python】windows更改jupyter notebook(ipython)的默认打开工作路径
写在前面:本博客为本人原创,严禁任何形式的转载!本博客只允许放在博客园(.cnblogs.com),如果您在其他网站看到这篇博文,请通过下面这个唯一的合法链接转到原文! 本博客全网唯一合法URL:ht ...