HDFS镜像文件fsimage和编辑日志文件edits
镜像文件和编辑日志文件
1)概念
namenode被格式化之后,将在/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current目录中产生如下文件
edits_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION
(1)Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息(id、类型、目录、所属用户、用户权限、时间戳……)。
(2)Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
(3)seen_txid文件保存的是一个数字,就是最后一个edits_的数字
(4)每次Namenode启动的时候都会将fsimage文件读入内存,并从00001开始到seen_txid中记录的数字依次执行每个edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成Namenode启动的时候就将fsimage和edits文件进行了合并。
2)oiv查看fsimage文件
(1)查看oiv和oev命令
[atguigu@hadoop102 current]$ hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
(2)基本语法
hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径
(3)案例实操
[atguigu@hadoop102 current]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current [atguigu@hadoop102 current]$ hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-2.7.2/fsimage.xml [atguigu@hadoop102 current]$ cat /opt/module/hadoop-2.7.2/fsimage.xml
将显示的xml文件内容拷贝到eclipse中创建的xml文件中,并格式化。

3)oev查看edits文件
(1)基本语法
hdfs oev -p 文件类型 -i 编辑日志 -o 转换后文件输出路径
(2)案例实操
[atguigu@hadoop102 current]$ hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-2.7.2/edits.xml
[atguigu@hadoop102 current]$ cat /opt/module/hadoop-2.7.2/edits.xml
将显示的xml文件内容拷贝到eclipse中创建的xml文件中,并格式化。
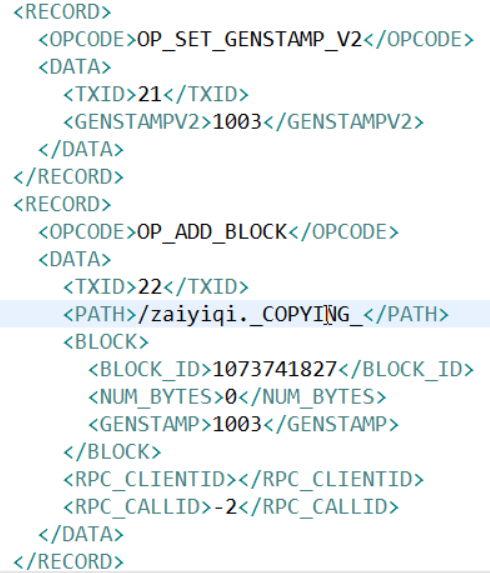
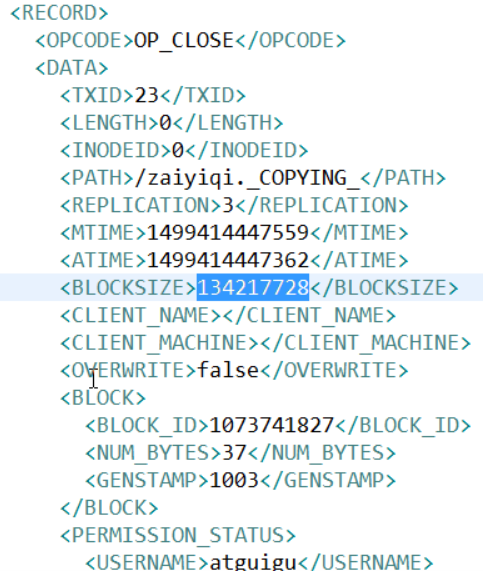
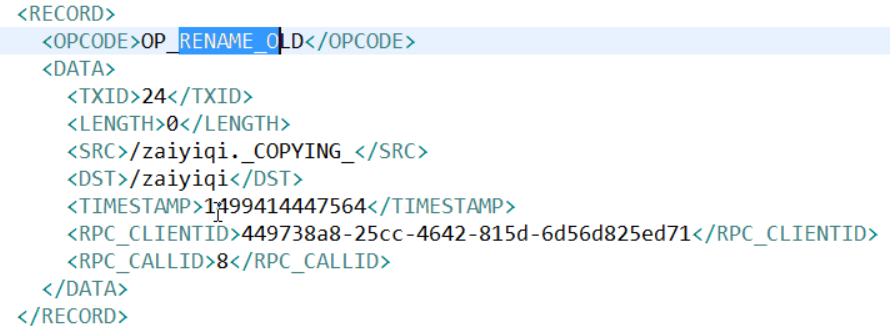
滚动编辑日志
正常情况HDFS文件系统有更新操作时,就会滚动编辑日志。也可以用命令强制滚动编辑日志。
1)滚动编辑日志(前提必须启动集群)
[atguigu@hadoop102 current]$ hdfs dfsadmin -rollEdits
2)镜像文件什么时候产生
Namenode启动时加载镜像文件和编辑日志

HDFS镜像文件fsimage和编辑日志文件edits的更多相关文章
- Hadoop基础-镜像文件(fsimage)和编辑日志(edits)
Hadoop基础-镜像文件(fsimage)和编辑日志(edits) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查看日志镜像文件(如:fsimage_00000000000 ...
- hadoop镜像文件和编辑日志文件
镜像文件和编辑日志文件 1)概念 namenode被格式化之后,将在/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current目录中产生如下文件 edits_ ...
- SQL Server无法收缩日志文件 2 因为逻辑日志文件的总数不能少于 2问题
SQL Server无法收缩日志文件 2 因为逻辑日志文件的总数不能少于 2问题 最近服务器执行收缩日志文件大小的job老是报错 我所用的一个批量收缩日志脚本 USE [master] GO /*** ...
- SQL Server日志文件过大 大日志文件清理方法 不分离数据库
SQL Server日志文件过大 大日志文件清理方法 ,网上提供了很多分离数据库——〉删除日志文件-〉附加数据库 的方法,此方法风险太大,过程也比较久,有时候也会出现分离不成功的现象.下面的方式 ...
- 【转】SQL Server日志文件过大 大日志文件清理方法 不分离数据库
https://blog.csdn.net/slimboy123/article/details/54575592 还未测试 USE[master] GO ALTER DATABASE 要清理的数据库 ...
- 使用SQL语句创建数据库2——创建多个数据库文件和多个日志文件
在matser数据库下新建查询,输入的命令如下: USE master GOCREATE DATABASE E_MarketON PRIMARY--主文件组( NAME ='E_Market_data ...
- 通达OA任意文件上传+文件包含GetShell/包含日志文件Getshell
0x01 简介 通达OA采用基于WEB的企业计算,主HTTP服务器采用了世界上最先进的Apache服务器,性能稳定可靠.数据存取集中控制,避免了数据泄漏的可能.提供数据备份工具,保护系统数据安全.多级 ...
- python 实现创建文件夹和创建日志文件
一.实现创建文件夹和日志 #!/usr/bin/env python # -*- coding:utf-8 -*- # Author: nulige import os import datetime ...
- SQL server 数据库日志文件过大清空日志文件
SQL2008:'在SQL2008中清除日志就必须在简单模式下进行,等清除动作完毕再调回到完全模式. USE [master] GO ALTER DATABASE DBName SET RECOVER ...
随机推荐
- <authentication> 元素
<authentication> 元素 配置 ASP.NET 身份验证支持.该元素只能在计算机.站点或应用程序级别声明.如果试图在配置文件中的子目录或页级别上进行声明,则将产生分析器错误信 ...
- Vscode添加谷歌Debug插件
1. 2.安装好 Debugger for Chrome之后,找到要进行Debug的文件 3. 4.进入到launch.json文件中进行相应的配置 配置文件内容如下: { "version ...
- Android Studio的安装
下载Android Studio(需要翻墙才能安装得快):直接到官网进行下载就可以了.下载地址:https://developer.android.com/ “Android Virtual Devi ...
- bzoj3754 Tree之最小方差树 最小生成树+推性质
题目传送门 https://lydsy.com/JudgeOnline/problem.php?id=3754 题解 感觉这个思路挺神仙的. 后悔没有好好观察题目的数据范围,一直把 \(n\) 和 \ ...
- MySQL简版(一)
第一章 数据库的基本概念 1.1 数据库的英文单词 Database,简称DB. 1.2 什么是数据库? 用于存储和管理数据的仓库. 1.3 数据库的特点 持久化存储数据的.其实数据库就是一个文件系统 ...
- 模型监控指标- 混淆矩阵、ROC曲线,AUC值,KS曲线以及KS值、PSI值,Lift图,Gain图,KT值,迁移矩阵
1. 混淆矩阵 确定截断点后,评价学习器性能 假设训练之初以及预测后,一个样本是正例还是反例是已经确定的,这个时候,样本应该有两个类别值,一个是真实的0/1,一个是预测的0/1 TP(实际为正预测为正 ...
- [洛谷P1864] NOI2009 二叉查找树
问题描述 已知一棵特殊的二叉查找树.根据定义,该二叉查找树中每个结点的数据值都比它左儿子结点的数据值大,而比它右儿子结点的数据值小. 另一方面,这棵查找树中每个结点都有一个权值,每个结点的权值都比它的 ...
- LeetCode--078--子集(python)
给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集). 说明:解集不能包含重复的子集. 示例: 输入: nums = [1,2,3]输出:[ [3], [1], [2], ...
- 果蝇优化算法(FOA)
果蝇优化算法(FOA) 果蝇优化算法(Fruit Fly Optimization Algorithm, FOA)是基于果蝇觅食行为的仿生学原理而提出的一种新兴群体智能优化算法. 果蝇优化算法(FOA ...
- Leetcode 4. Median of Two Sorted Arrays(中位数+二分答案+递归)
4. Median of Two Sorted Arrays Hard There are two sorted arrays nums1 and nums2 of size m and n resp ...