(4.14)mysql备份还原——mysql物理热备工具之ibbackup
【1】mysqlpump介绍与基本使用
之前详细介绍了Mysqldump备份工具使用,下面说下MySQL5.7之后新添加的备份工具mysqlpump。mysqlpump是mysqldump的一个衍生,mysqldump备份功能这里就不多说了,现在看看mysqlpump到底有了哪些提升,详细可以查看官网文档。mysqlpump和mysqldump一样,属于逻辑备份,备份以SQL形式的文本保存。逻辑备份相对物理备份好处是不关心log的大小,直接备份数据即可。
Mysqlpump主要特点
- 并行备份数据库和数据库中的对象的,加快备份过程。
- 更好的控制数据库和数据库对象(表,存储过程,用户帐户)的备份。
- 备份用户账号作为帐户管理语句(CREATE USER,GRANT),而不是直接插入到MySQL的系统数据库。
- 备份出来直接生成压缩后的备份文件。
- 备份进度指示(估计值)。
- 重新加载(还原)备份文件,先建表后插入数据最后建立索引,减少了索引维护开销,加快了还原速度。
- 备份可以排除或则指定数据库。
优点:
- 支持基于表的并行导出功能(参数
--default-parallelism,默认为2,参数--parallel-schemas,控制并行导出的库) - 导出的时候带有进度条(参数
--watch-progress,默认开启) - 支持直接压缩导出导入(参数
--compress-output,支持ZLIB和LZ4) - 重新加载(还原)备份文件,先建表后插入数据最后建立索引,减少了索引维护开销,加快了还原速度。
- 更好的控制数据库和数据库对象(表,存储过程,用户帐户)的备份。
Mysqlpump缺点
- 只能并行到表级别,如果表特别大,开多线程和单线程是一样的,并行度不如mydumper;
- 无法获取当前备份对应的binlog位置,如果想用这个玩意儿搭建个备库,岂不是奢望?(暂时不支持--master-data,--dump-slave参数了);
- MySQL5.7.11之前的版本不要使用,并行导出和single-transaction是互斥的;
参数说明:Mysqlpump绝大部分参数使用和Mysqldump一致,下面顺便重温一下。注意对于mysqlpump 专有参数会用背景色 标记出来。
1) --add-drop-database: 在建立库之前先执行删库操作
|
1
|
DROP DATABASE IF EXISTS `...`; |
2) --add-drop-table:在建表之前先执行删表操作
|
1
|
DROP TABLE IF EXISTS `...`.`...`; |
3) --add-drop-user:在CREATE USER语句之前增加DROP USER。 注意:这个参数需要和--users一起使用,否者不生效。
|
1
|
DROP USER 'backup'@'172.16.60.%'; |
4) --add-locks:备份表时,使用LOCK TABLES和UNLOCK TABLES。注意:这个参数不支持并行备份,需要关闭并行备份功能:--default-parallelism=0
|
1
2
3
|
LOCK TABLES `...`.`...` WRITE;...UNLOCK TABLES; |
5) --all-databases:备份所有库,即 -A。
6) --bind-address:指定通过哪个网络接口来连接Mysql服务器(一台服务器可能有多个IP),防止同一个网卡出去影响业务。
7) --complete-insert:dump出包含所有列的完整insert语句。
8) --compress: 压缩客户端和服务器传输的所有的数据,即 -C。
9) --compress-output:默认不压缩输出,目前可以使用的压缩算法有LZ4和ZLIB
|
1
2
3
4
5
|
[root@localhost ~]# mysqlpump --compress-output=LZ4 > dump.lz4[root@localhost ~]# lz4_decompress dump.lz4 dump.txt[root@localhost ~]# mysqlpump --compress-output=ZLIB > dump.zlib[root@localhost ~]# zlib_decompress dump.zlib dump.txt |
10) --databases:手动指定要备份的库,支持多个数据库,用空格分隔,即-B。
11) --default-character-set:指定备份的字符集。
12) --default-parallelism:指定并行线程数,默认是2,如果设置成0,表示不使用并行备份。注意:每个线程的备份步骤是:先create table但不建立二级索引(主键会在create table时候建立),再写入数据,最后建立二级索引。
13) --defer-table-indexes:延迟创建索引,直到所有数据都加载完之后,再创建索引,默认开启。若关闭则会和mysqldump一样:先创建一个表和所有索引,再导入数据,因为在加载还原数据的时候要维护二级索引的开销,导致效率比较低。关闭使用参数:--skip--defer-table-indexes。
14) --events:备份数据库的事件,默认开启,关闭使用--skip-events参数。
15) --exclude-databases:备份排除该参数指定的数据库,多个用逗号分隔。类似的还有--exclude-events、--exclude-routines、--exclude-tables、--exclude-triggers、--exclude-users
|
1
2
3
4
|
[root@localhost ~]# mysqlpump --exclude-databases=mysql,sys -p123456 --set-gtid-purged=off >/root/db.sql #备份过滤mysql和sys数据库[root@localhost ~]# mysqlpump --exclude-tables=rr,tt -p123456 --set-gtid-purged=off > /root/db.sql #备份过滤所有数据库中rr、tt表[root@localhost ~]# mysqlpump -B test --exclude-tables=tmp_ifulltext,tt -p123456 --set-gtid-purged=off >/root/db.sql #备份过滤test库中的rr、tt表... |
注意:要是只备份数据库的账号,需要添加参数--users,并且需要过滤掉所有的数据库,如
|
1
2
|
#备份除dba和backup的所有账号。[root@localhost ~]# mysqlpump --users --exclude-databases=sys,mysql,db1,db2 --exclude-users=dba,backup -p123456 --set-gtid-purged=off >/root/db.sql |
16) --include-databases:指定备份数据库,多个用逗号分隔,类似的还有--include-events、--include-routines、--include-tables、--include-triggers、--include-users,大致方法使用同15。
17) --insert-ignore:备份用insert ignore语句代替insert语句。
18) --log-error-file:备份出现的warnings和erros信息输出到一个指定的文件。
19) --max-allowed-packet:备份时用于client/server直接通信的最大buffer包的大小。
20) --net-buffer-length:备份时用于client/server通信的初始buffer大小,当创建多行插入语句的时候,mysqlpump 创建行到N个字节长。
21) --no-create-db:备份不写CREATE DATABASE语句。要是备份多个库,需要使用参数-B,而使用-B的时候会出现create database语句,该参数可以屏蔽create database 语句。
22) --no-create-info:备份不写建表语句,即不备份表结构,只备份数据,即 -t。
23) --hex-blob: 备份binary字段的时候使用十六进制计数法,受影响的字段类型有BINARY、VARBINARY、BLOB、BIT。
24) --host :备份指定的数据库地址,即 -h。
25) --parallel-schemas=[N:]db_list:指定并行备份的库,多个库用逗号分隔,如果指定了N,将使用N个线程的地队列,如果N不指定,将由 --default-parallelism才确认N的值,可以设置多个--parallel-schemas
|
1
2
3
4
5
6
7
|
#4个线程备份vs和aa,3个线程备份pt。通过show processlist 可以看到有7个线程。[root@localhost ~]# mysqlpump --parallel-schemas=4:vs,aa --parallel-schemas=3:pt -p123456 --set-gtid-purged=off > /root/db.sql #默认2个线程,即2个线程备份vs和abc,2个线程备份pt[root@localhost ~]# mysqlpump --parallel-schemas=vs,abc --parallel-schemas=pt -p123456 --set-gtid-purged=off > /root/db.sql #当然要是硬盘IO不允许的话,可以少开几个线程和数据库进行并行备份 |
26) --password:备份需要的密码。
27) --port :备份数据库的端口。
28) --protocol={TCP|SOCKET|PIPE|MEMORY}:指定连接服务器的协议。
29) --replace:备份出来replace into语句。
30) --routines:备份出来包含存储过程和函数,默认开启,需要对 mysql.proc表有查看权限。生成的文件中会包含CREATE PROCEDURE 和 CREATE FUNCTION语句以用于恢复,关闭则需要用--skip-routines参数。
31) --triggers:备份出来包含触发器,默认开启,使用--skip-triggers来关闭。
31) --set-charset:备份文件里写SET NAMES default_character_set 到输出,此参默认开启。 -- skip-set-charset禁用此参数,不会在备份文件里面写出set names...
32) --single-transaction:该参数在事务隔离级别设置成Repeatable Read,并在dump之前发送start transaction 语句给服务端。这在使用innodb时很有用,因为在发出start transaction时,保证了在不阻塞任何应用下的一致性状态。对myisam和memory等非事务表,还是会改变状态的,当使用此参的时候要确保没有其他连接在使用ALTER TABLE、CREATE TABLE、DROP TABLE、RENAME TABLE、TRUNCATE TABLE等语句,否则会出现不正确的内容或则失败。--add-locks和此参互斥,在mysql5.7.11之前,--default-parallelism大于1的时候和此参也互斥,必须使用--default-parallelism=0。5.7.11之后解决了--single-transaction和--default-parallelism的互斥问题。
33) --skip-definer:忽略那些创建视图和存储过程用到的 DEFINER 和 SQL SECURITY 语句,恢复的时候,会使用默认值,否则会在还原的时候看到没有DEFINER定义时的账号而报错。
34) --skip-dump-rows:只备份表结构,不备份数据,即-d。注意:mysqldump支持--no-data,mysqlpump不支持--no-data
35) --socket:对于连接到localhost,Unix使用套接字文件,在Windows上是命名管道的名称使用,即 -S。
36) --ssl:--ssl参数将要被去除,用--ssl-mode取代。关于ssl相关的备份。
37) --tz-utc:备份时会在备份文件的最前几行添加SET TIME_ZONE='+00:00'。注意:如果还原的服务器不在同一个时区并且还原表中的列有timestamp字段,会导致还原出来的结果不一致。默认开启该参数,用 --skip-tz-utc来关闭参数。
38) --user:备份时候的用户名,即 -u。
39) --users:备份数据库用户,备份的形式是CREATE USER...,GRANT...,只备份数据库账号可以通过如下命令
|
1
2
|
#过滤掉所有数据库[root@localhost ~]# mysqlpump --exclude-databases=% --users -p123456 --set-gtid-purged=off >/root/db.sql |
40) --watch-progress:定期显示进度的完成,包括总数表、行和其他对象。该参数默认开启,用--skip-watch-progress来关闭。
Mysqlpump的多线程架构图如下

- mysqlpump是MySQL5.7的官方工具,用于取代mysqldump,其参数与mysqldump基本一样;
- mysqlpump是多线程备份,但只能到表级别,单表备份还是单线程;
- mysqldump备份时,有个默认队列(default),队列下开N个线程去备份数据库/数据库中的表;
- 支持开多个队列(对应不同库/表),然后每个队列设置不同线程,进行备份;
Mysqlpump支持基于库和表的并行导出,Mysqlpump的并行导出功能的架构为:队列+线程,允许有多个队列(--parallel-schemas),每个队列下有多个线程(N),而一个队列可以绑定1个或者多个数据库(逗号分隔)。
Mysqlpump的备份是基于表并行的,对于每张表的导出只能是单个线程的,这里会有个限制是如果某个数据库有一张表非常大,可能大部分的时间都是消耗在这个表的备份上面,并行备份的效果可能就不明显。
这里可以利用Mydumper其是以chunk的方式批量导出,即Mydumper支持一张表多个线程以chunk的方式批量导出。但相对于Mysqldump有很大提升。
对比测试如下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
mysqlpump压缩备份kevin数据库 三个并发线程备份,消耗时间:222s[root@localhost ~]# mysqlpump -uroot -p123456 -h172.16.60.211 --single-transaction --default-character-set=utf8 --compress-output=LZ4 --default-parallelism=3 -B kevin > /data/db_backup/kevin_db.sql.lz4mysqldump备份压缩kevin数据库 单个线程备份,消耗时间:900s,gzip的压缩率比LZ4的高[root@localhost ~]# mysqldump -uroot -p123456 -h172.16.60.211 --default-character-set=utf8 -P3306 --skip-opt --add-drop-table --create-options --quick --extended-insert --single-transaction -B kevin | gzip > /data/db_backup/kevin.sql.gzmydumper备份kevin数据库 三个并发线程备份,消耗时间:300s,gzip的压缩率比LZ4的高[root@localhost ~]# mydumper -u root -p123456 -h 172.16.60.211 -P 3306 -t 3 -c -l 3600 -s 10000000 -B kevin -o /data/db_backup/kevin/mydumper备份kevin数据库,五个并发线程备份,并且开启对一张表多个线程以chunk的方式批量导出,-r。消耗时间:180s[root@localhost ~]# mydumper -u root -p123456 -h 172.16.60.211 -P 3306 -t 5 -c -r 300000 -l 3600 -s 10000000 -B kevin -o /data/db_backup/kevin/注意: 如果是开启了GTID功能的数据库,备份时还需要添加"--set-gtid-purged=off"参数,否则可能会报错! |
从上面看出,mysqlpump的备份效率是最快的,mydumper次之,mysqldump最差。所以在IO允许的情况下,能用多线程就别用单线程备份。并且mysqlpump还支持多数据库的并行备份,而mydumper要么备份一个库,要么就备份所有库。可以看出,在mysql数据库备份方面,mysqlpump比mysqldump的测试结果要好。由于实际情况不同,测试给出的速度提升只是参考。到底开启多少个并行备份的线程,这个看磁盘IO的承受能力,若该服务器只进行备份任务,可以最大限制的来利用磁盘。
测试中发现mysqlpump和mysqldump对比:
- mysqldump默认是不会有建库命令, 但是默认会有drop table的命令;
- mysqlpump默认是有建库命令,但是不会有drop table的命令,所以mysqlpump恢复的时候不要直接< file.sql ;
- mysqldump恢复时会先创建表及其所有索引,然后再导入数据;mysqlpump恢复时会先创建表,然后再导入数据,最后建索引;
- mysqlpump可以指定多线程并发备份,默认是2个;备份时会有进度指示,虽然只是估计值,但不会再想mysqldump备份时那么枯燥,看不到过程.
注意:mysqlpump备份的几个重要参数
|
1
2
3
4
5
6
7
8
|
--default-parallelism 指定线程数,默认开2个线程进行并发备份--parallel-schemas 指定哪些数据库进行并发备份--set-gtid-purged=OFF 这个是5.7.18版本后加入的参数,--set-gtid-purged=OFF这个参数很重要,如果备份命令里不加上,则备份可能会报错:Warning: A partial dump from a server that has GTIDs will by default include the GTIDs of all transactions, even those that changedsuppressed parts of the database. If you don't want to restore GTIDs, pass --set-gtid-purged=OFF. To make a complete dump, pass--all-databases --triggers --routines --events. |
备份演示如下
- 备份命令如下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
[root@localhost ~]# mysqlpump --single-transaction --set-gtid-purged=OFF --parallel-schemas=2:kevin --parallel-schemas=4:dbt3 -B kevin dbt3 -p123456 > /tmp/backup.sqlmysqlpump: [Warning] Using a password on the command line interface can be insecure.Dump progress: 1/5 tables, 0/7559817 rowsDump progress: 3/15 tables, 286750/12022332 rowsDump progress: 3/15 tables, 686750/12022332 rowsDump progress: 3/15 tables, 1042250/12022332 rows...Dump completed in 43732 milliseconds接着另外打开一个终端会话,登录mysql看下情况(root@172.16.0.10) [(none)]> show processlist;+--------+------+------------------+------+---------+------+-------------------+------------------------------------------------------------------------------------------------------+| Id | User | Host | db | Command | Time | State | Info |+--------+------+------------------+------+---------+------+-------------------+------------------------------------------------------------------------------------------------------+| 138199 | root | 172.16.60.50:39238 | NULL | Query | 0 | starting | show processlist || 138267 | root | 172.16.60.50:39776 | NULL | Sleep | 2 | | NULL || 138268 | root | 172.16.60.50:39778 | NULL | Query | 2 | Sending to client | SELECT SQL_NO_CACHE `emp_no`,`dept_no`,`from_date`,`to_date` FROM `kevin`.`dept_emp` || 138269 | root | 172.16.60.50:39780 | NULL | Query | 2 | Sending to client | SELECT SQL_NO_CACHE `emp_no`,`birth_date`,`first_name`,`last_name`,`gender`,`hire_date` FROM `emplo || 138270 | root | 172.16.60.50:39782 | NULL | Query | 2 | Sending to client | SELECT SQL_NO_CACHE `o_orderkey`,`o_custkey`,`o_orderstatus`,`o_totalprice`,`o_orderDATE`,`o_orderpr || 138271 | root | 172.16.60.50:39784 | NULL | Query | 2 | Sending to client | SELECT SQL_NO_CACHE `p_partkey`,`p_name`,`p_mfgr`,`p_brand`,`p_type`,`p_size`,`p_container`,`p_retai || 138272 | root | 172.16.60.50:39786 | NULL | Query | 2 | Sending data | SELECT SQL_NO_CACHE `l_orderkey`,`l_partkey`,`l_suppkey`,`l_linenumber`,`l_quantity`,`l_extendedpric || 138273 | root | 172.16.60.50:39788 | NULL | Query | 2 | Sending to client | SELECT SQL_NO_CACHE `c_custkey`,`c_name`,`c_address`,`c_nationkey`,`c_phone`,`c_acctbal`,`c_mktsegme || 138274 | root | 172.16.60.50:39790 | NULL | Sleep | 2 | | NULL || 138275 | root | 172.16.60.50:39792 | NULL | Sleep | 1 | | NULL |+--------+------+------------------+------+---------+------+-------------------+------------------------------------------------------------------------------------------------------+10 rows in set (0.00 sec)可以看到138268和138269在备份kevin库,138270,138271,138272,138273在备份dbt3,这里没打印全。 |
- 备份过程如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
终端会话1:(root@localhost) [(none)]> truncate mysql.general_log;Query OK, 0 rows affected (0.10 sec)(root@localhost) [(none)]> set global log_output = 'table';Query OK, 0 rows affected (0.00 sec)(root@localhost) [(none)]> set global general_log = 1;Query OK, 0 rows affected (0.03 sec)终端会话2:[root@VM_0_5_centos ~]# mysqlpump --single-transaction kevin --set-gtid-purged=OFF -p123456> /tmp/backup.sqlDump completed in 592 milliseconds(root@localhost) [(none)]> select thread_id,left(argument, 64) from mysql.general_log order by event_time;................................+-----------+------------------------------------------------------------------+| 7 | root@localhost on using Socket || 7 | FLUSH TABLES WITH READ LOCK || 7 | SHOW WARNINGS || 7 | SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ || 7 | SHOW WARNINGS || 7 | START TRANSACTION WITH CONSISTENT SNAPSHOT || 7 | SHOW WARNINGS || 8 | root@localhost on using Socket || 8 | SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ || 8 | SHOW WARNINGS || 8 | START TRANSACTION WITH CONSISTENT SNAPSHOT || 8 | SHOW WARNINGS || 9 | root@localhost on using Socket || 9 | SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ || 9 | SHOW WARNINGS || 9 | START TRANSACTION WITH CONSISTENT SNAPSHOT || 9 | SHOW WARNINGS || 7 | UNLOCK TABLES || 7 | SHOW WARNINGS || 9 | SET SQL_QUOTE_SHOW_CREATE= 1 || 9 | SHOW WARNINGS || 9 | SET TIME_ZONE='+00:00' || 8 | SET SQL_QUOTE_SHOW_CREATE= 1 || 8 | SHOW WARNINGS || 8 | SET TIME_ZONE='+00:00' || 3 | set global general_log = 0 |+-----------+------------------------------------------------------------------+根据上面信息,可以看出:- 线程7 进行 FLUSH TABLES WITH READ LOCK 。对表加一个读锁- 线程7、8、9分别开启一个事务(RR隔离级别)去备份数据,由于之前锁表了,所以这三个线程备份出的数据是具有一致性的- 线程7 解锁 UNLOCK TABLE- 整个过程都没有获取二进制位置点 |
- compress-output
mysqlpump支持压缩输出,支持LZ4和ZLIB(ZLIB压缩比相对较高,但是速度较慢)
|
1
2
|
[root@localhost tmp]# mysqlpump --single-transaction --compress-output=lz4 kevin --set-gtid-purged=OFF -p123456 > /tmp/backup_kevin.sqlDump completed in 511 milliseconds |
- 备份恢复
未压缩的备份
|
1
|
mysql < source /tmp/backup.sql; |
压缩过的备份
|
1
2
3
4
5
|
先解压[root@localhost ~]# lz4_decompress /tmp/backup_kevin.sql /tmp/kevin.sql再导入mysql < source /tmp/kevin.sql; |
可以看出来,这个导入是单线程。mysqlpump备份的数据恢复时会先插入数据, 再建索引, 而mysqldump备份的数据恢复是在建立表的时候就把索引加上了, 所以前者备份的数据恢复时速度要快一点!
总体来说mysqlpump还是很好用的,尤其是多数据库表的备份。不过如果有一张表格外大,那么备份的大部分时间还是要消耗在这张表上,因为mysqlpump的备份是基于表并行的,对于每张表的导出只能是单个线程的。
另外注意mysqlpump备份时并发线程的数量还是要看自身服务器的IO负载能力,并不是说一味的增加并发线程数量就可以加快速度。
mysqldump和mysqlpump的使用方法绝大部分一致,mysqlpump新的参数文章上已经标明,到底用那种工具备份数据库这个要在具体的环境下才能做出选择,有些时候可能用物理备份更好(xtrabackup)。
总之根据需要进行测试,最后再决定使用哪种备份工具进行备份。
本节转自:https://www.cnblogs.com/kevingrace/p/9760185.html
【2】mysqlpump基本效率测试
MySQL在备份方面包含了自身的mysqldump工具,但其只支持单线程工作,这就使得它无法迅速的备份数据。所以就有人写了mydumper工具,支持多线程,并且是行级粒度,支持正则匹配多数据库。MySQL官方当然也意识到了这个问题,所以从MySQL 5.7开始就推出了mysqlpump工具,mysqlpump相对于之前的逻辑备份工具mysqldump来说,总结的优势如下:
但mysqlpump真正可以在生产使用,直到MySQL 5.7.11版本发布,其中最有意义的部分在于官方修复了之前mysqlpump工具一致性备份的问题,使得mysqlpump工具在生产环境中有了用武之地。而在之前MySQL 5.7的文档中明确写着,mysqlpump是不支持一致性的备份,如下:
注意:mysqlpump的多线程备份是基于表的,所以当只有一张表或99张是小表,1张是超级大表,mysqlpump备份速度还不如mysqldump(实际测试单表一千万数据,mysqlpump在7秒,mysqldump在5秒多),甚至更慢。
mysqlpump的并行导出功能的架构为:队列+线程,允许有多个队列,每个队列下有多个线程,而一个队列可以绑定1个或者多个数据库。但是,对于每张表的导出只能是单个线程的,这和mydumper工具是不一样的,因为mydumper支持一张表多个线程以chunk的方式批量导出,能够实现记录级别的并行备份,这在主键是随机的情况下,导出速度还能有提升。
mysqlpump的架构如下图所示:
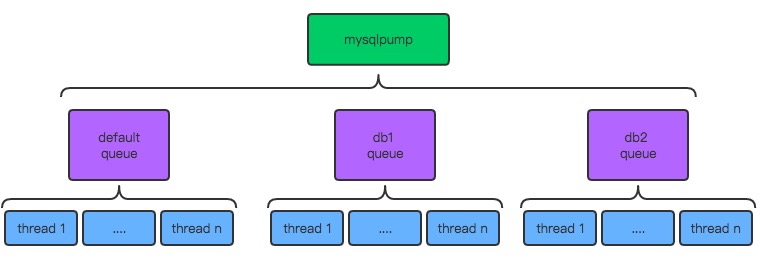
接着对比了mysqldump与mysqlpump的导出速度,选择的数据库大小为7.8G,每次备份测试时都重启数据库,清空缓冲池中的内容。其中各表的大小如下所示:
-rw-r----- 1 mysql mysql 1.9G Feb 21 22:58 tpcc/customer.ibd
-rw-r----- 1 mysql mysql 160K Feb 21 23:12 tpcc/district.ibd
-rw-r----- 1 mysql mysql 208M Feb 21 22:58 tpcc/history.ibd
-rw-r----- 1 mysql mysql 17M Feb 21 22:23 tpcc/item.ibd
-rw-r----- 1 mysql mysql 32M Feb 22 00:05 tpcc/new_orders.ibd
-rw-r----- 1 mysql mysql 2.1G Feb 22 10:00 tpcc/order_line.ibd
-rw-r----- 1 mysql mysql 132M Feb 22 00:05 tpcc/orders.ibd
-rw-r----- 1 mysql mysql 3.5G Feb 21 23:12 tpcc/stock.ibd
-rw-r----- 1 mysql mysql 48K Feb 21 23:11 tpcc/warehouse.ibd
|
1
2
3
4
5
6
7
8
9
10
|
root@test-1:/mdata/mysql_data# ls -lh tpcc/*.ibd
-rw-r----- 1 mysql mysql 1.9G Feb 21 22:58 tpcc/customer.ibd
-rw-r----- 1 mysql mysql 160K Feb 21 23:12 tpcc/district.ibd
-rw-r----- 1 mysql mysql 208M Feb 21 22:58 tpcc/history.ibd
-rw-r----- 1 mysql mysql 17M Feb 21 22:23 tpcc/item.ibd
-rw-r----- 1 mysql mysql 32M Feb 22 00:05 tpcc/new_orders.ibd
-rw-r----- 1 mysql mysql 2.1G Feb 22 10:00 tpcc/order_line.ibd
-rw-r----- 1 mysql mysql 132M Feb 22 00:05 tpcc/orders.ibd
-rw-r----- 1 mysql mysql 3.5G Feb 21 23:12 tpcc/stock.ibd
-rw-r----- 1 mysql mysql 48K Feb 21 23:11 tpcc/warehouse.ibd
|
由于只有tpcc单个数据库,这里mysqlpump测试采用默认单队列2个线程和单队列4个线程测试,mysqlpump测试语句如下:
$ time mysqlpump --single-transaction --default-parallelism=4 -B tpcc > tpcc.sql
|
1
2
|
$ time mysqlpump --single-transaction -B tpcc > tpcc.sql
$ time mysqlpump --single-transaction --default-parallelism=4 -B tpcc > tpcc.sql
|
最后的测试结果如下所示:
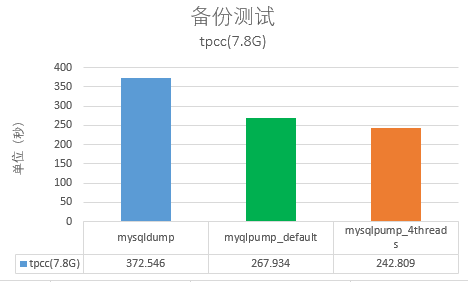
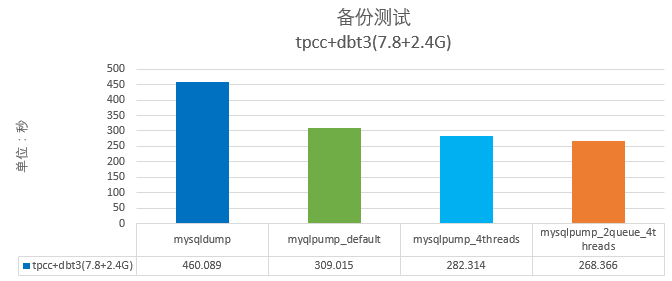
测试在网易云环境下,这时可以发现默认配置下mysqlpump的速度比起mysqldump快了39.04%,4个线程下快了有48.89%。接着测试多个数据库备份的场景,这里选择7.8G大小的tpcc库和2.4G大小的dbt3数据库,最后得到的结果mysqlpump比起mysqldump最高快了70%多的时间:
总结
mysqlpump的语法与mysqldump高度兼容,支持基于库和表的并行导出,对比mysqldump速度提升非常明显。MySQL 5.7.11版本解决了一致性备份问题,推荐线上环境使用。由于每个数据库大小,架构不同,测试给出的速度提升只是参考,或许在你的环境会没有任何差别,也可能速度提升更大。anyway,是时候好好测试mysqlpump,看看对你的生产环境是否会有极大的速度提升。
【2】mysqlpump备份工具使用
mysqlpump语法跟mysqldump语法大部分都相同(除mysqldump支持而mysqlpump不支持的选项外),另外除了多线程部分和显示进度条外,其他部分的实现原理也都差不多,可以看MySQL备份工具:单线程mysqldump工具使用。
-h, --host 指定备份连接的主机地址。
-P, --port 指定备份连接的主机端口。
-u, --user 指定备份用户。
-p, --password 指定备份用户密码。
-S, --socket 指定备份socket。
--character-sets-dir 指定备份数据导出字符集。
-C, --compress 压缩客户端和服务器传输的所有的数据。
--compress-output 默认不压缩输出,目前可以使用的压缩算法有LZ4和ZLIB(ZLIB压缩比更加高效)。 $ mysqlpump --compress-output=LZ4 > dump.sql.lz4
$ lz4_decompress dump.lz4 dump.sql $ mysqlpump --compress-output=ZLIB > dump.sql.zlib
$ zlib_decompress dump.zlib dump.sql $ mysqlpump --compress-output=LZ4 > dump.sql.lz4
$ lz4_decompress dump.lz4 dump.sql $ mysqlpump --compress-output=ZLIB > dump.sql.zlib
$ zlib_decompress dump.zlib dump.sql
--default-parallelism 指定并行线程数,默认是2,如果设置成0,表示不使用并行备份。 注意:每个线程的备份步骤是:先create table但不建立二级索引(主键会在create table时候建立),再写入数据,最后建立二级索引。 --defer-table-indexes 延迟创建索引,直到所有数据都加载完之后,再创建索引,默认开启。
#若关闭则会和mysqldump一样:先创建一个表和所有索引,再导入数据,因为在加载还原数据的时候要维护二级索引的开销,导致效率比较低。关闭使用参数:--skip--defer-table-indexes。 --exclude-databases 备份排除该参数指定的数据库,多个用逗号分隔。类似的还有--exclude-events、--exclude-routines、--exclude-tables、--exclude-triggers、--exclude-users。
--include-databases 指定备份数据库,多个用逗号分隔。类似的还有--include-events、--include-routines、--include-tables、--include-triggers、--include-users,大致方法使用同15。
--exclude-tables 备份排除该参数指定的表,多个用逗号分隔。
--include-tables 指定备份表,多个用逗号分隔。
--parallel-schemas 指定并行备份的库,多个库用逗号分隔,如果指定了N,将使用N个线程的队列。 如果N不指定,将由--default-parallelism才确认N的值,可以设置多个--parallel-schemas。 # 4个线程备份vs和aa,3个线程备份pt。通过show processlist可以看到有7个线程;
$ mysqlpump --parallel-schemas=4:vs,aa --parallel-schemas=3:pt # 默认2个线程,即2个线程备份vs和abc,2个线程备份pt;
$ mysqlpump --parallel-schemas=vs,abc --parallel-schemas=pt -d, --skip-dump-rows 只备份表结构,不备份数据。注意:mysqldump支持--no-data,mysqlpump不支持--no-data。 --users 备份数据库用户,备份的形式是CREATE USER…,GRANT…,只备份数据库账号可以通过如下命令。 # 过滤掉所有数据库;
$ mysqlpump --exclude-databases=% --users
--watch-progress 定期显示进度的完成,包括总数表、行和其他对象。该参数默认开启,用--skip-watch-progress来关闭。 --single-transaction 该参数适用于InnoDB表,与–lock-tables参数互斥,备份期间不锁表(但会有一个瞬间需执行FLUSH TABLE WITH READ LOCK),即热备份。
此参数在备份开始前,会开启事务,并且会设置隔离级别为RR,利用可重复读特性来获得备份的一致性。当启用该参数并进行备份时,为确保得到有效的备份文件。
使用该参数备份期间应避免使用DDL(ALTER TABLE, CREATE TABLE, DROP TABLE, RENAME TABLE, TRUNCATE TABLE.)语句,因为连续性的读并没有对这些语句进行隔离。
备份期间使用这些DDL语句会导致潜在的select获取到的返回的数据不一致或错误,比如数据读出一半表被删了。 --login-path 可以支持免密码备份数据
参考:mysqlpump免密码备份
【3】mysqlpump备份实践
#mysqlpump压缩备份vs数据库,三个并发线程备份,消耗时间:222s。 $ mysqlpump -uzjy -p -h192.168.123. --single-transaction --compress-output=LZ4 --default-parallelism= -B vs > vs_db.sql.lz4
#mysqldump备份压缩vs数据库,单个线程备份,消耗时间:900s,gzip的压缩率比LZ4的高。 $ mysqldump -uzjy -p -h192.168.123. --skip-opt --add-drop-table --create-options --quick --extended-insert --single-transaction -B vs | gzip > vs.sql.gz
【4】mysqlpump原理
mysqlpump这个工具网上有大把大把的文章介绍,相信各位都用得炉火纯青。网上的文章都介绍了mysqlpump的一大特色是并发,可是.
没有说清楚mysqlpump并发的最小粒度是什么?它是怎么工作原理?现在我就简单研究下,如有错误,还请各位不吝指教!
首先准备环境,来看下:redhat7.5 +mysql5.7.22 源码安装。我们使用test库,里面有12张表,其中tab2和t22这两张表有476万条数据,总共3.6G容量。


废话不多说。我们开始测试:

我用了4个并发线程,采取的一致性导出。然后导出的库是test.整个导出很简单。
现在问题来了,这4个并发线程是怎么分工合作的呢?哪个线程导出大表tab2?哪个线程导出大表t22?mysqlpump又是如何判断这些数据的呢?
其实要回答这些问题,我们需要使用命令show
processlist ,以及general_log.
来看下processlist 都记录了啥:


发现总共有6个会话。其中id 2会话是我的登录会话。还有5个会话。读到这里首先会有一个疑问,配置了4个会话,怎么会有5个吗?问题2,貌似只有id 4,5会话在工作,id 3,6,7会话都没有做什么,事情真的是这样吗?
来看下general log



看看这些日志,就可以回答我的问题了:
1. 5个线程分工是这样:id7会话是管理线程,其余4个导出线程,所以4+1=5,总共5个线程。
2. id 4,5线程分别导出表t22,tab2.
3. id 3,6线程不是没有事情干,而是人家也分配了任务,也导出了数据,只不过导出任务瞬间完成了。
4. 并行的最小粒度是表,不是库database,也不是行。其实我觉得如果mysqlpump并行再优化,可以到行。比如分配多几个线程导出大表数据,比如分配2线程导出表t22的400万行数据,速度会更快。但是控制更加复杂。
5. 管理线程知道分配2个线程导出2个大表,还算挺智能的哦。
不知道各位看明白了没有,没有看明白,思考一下。
现在总结如下:
mysqlpump并发线程会有一个管理线程,然后有N个工作线程。并发导出的时候,管理线程会判断找出大表来,并分配任务。导出数据最小的单位是表。
最后一个问题,mysqlpump是怎么做到一致性导出的呢?这个问题留给各位自己思考。
该部转载于:http://blog.itpub.net/30393770/viewspace-2646610/
【5】ibbackup
1. 准备
ibbackup 是 InnoDB 提供的收费工具,它支持在线热备 InnoDB 数据,主要有以下特性:
- * Online backup of InnoDB tables — the backup takes place entirely online, without preventing queries or updates.
- * Online backup of MyISAM tables — during the backup of InnoDB tables, read and write access is permitted to MyISAM tables. While the MyISAM tables are being copied, updates (but not reads) to the MyISAM tables are precluded.
- * Compressed backups — the backup of InnoDB files can be compressed at various levels, saving as much as 70% or more of the storage required.
- * Partial backups — you can selectively backup all or only some of your InnoDB tables.
- * High performance — backup time is comparable to file copy, applying logs for recovery is even faster.
- * Unlimited database size — no practical limit to database size or number of tables.
- * Broad platform support — runs on Linux, Windows and leading Unix platforms.
在 innodb官网 申请了个试用版测试下,发现效果还是不错的,不过在我们自己的独特应用环境下,ibbackup 的优势并没有多少。具体的测试结果就不发上来了,有兴趣的同学自己测试看看吧。
ibbackup 只需要识别简单的几个 InnoDB 相关参数即可。它在备份时需要用到2个配置文件,一个是指定在线运行的信息,一个是备份相关信息。例如:
online-my.cnf 告诉 ibbackup 当前正在运行的mysql数据文件所在目录
[mysqld]
datadir = /home/mysql
innodb_data_file_path = ibdata1:512M:autoextend
innodb_data_home_dir = /home/mysql
innodb_log_file_size = 256M
innodb_log_files_in_group = 3
innodb_log_group_home_dir = /home/mysql
backup-my.cnf 告诉 ibbackup 备份文件存储的目录
[mysqld]
datadir = /home/hotbackup
innodb_data_file_path = ibdata1:512M:autoextend
innodb_data_home_dir = /home/hotbackup
innodb_log_file_size = 256M
innodb_log_files_in_group = 3
innodb_log_group_home_dir = /home/hotbackup
运行 ibbackup --help,就能看到以下几个主要选项:
[yejr@imysql.cn]# ibbackup --help
Usage:
ibbackup [--sleep ms] [--suspend-at-end] [--compress [level]]
[--include regexp] my.cnf backup-my.cnf
or
ibbackup --apply-log [--use-memory mb] [--uncompress] backup-my.cnf
or
ibbackup --restore [--use-memory mb] [--uncompress] backup-my.cnf
我一般只需要用到 --compress 以及 --uncompress,告诉 ibbackup 压缩/解压缩的级别。
开始备份

备份完成

(4.14)mysql备份还原——mysql物理热备工具之ibbackup的更多相关文章
- (4.3)mysql备份还原——mysql备份策略
(4.3)mysql备份还原——mysql备份策略 1.指定备份策略时需要考虑的点 [1.1]备份周期:2次备份间隔时长 [1.2]备份方式:在备份周期中,使用什么备份方式.备份模式 [1.3]实现方 ...
- (4.1)mysql备份还原——mysql常见故障
(4.1)mysql备份还原——mysql常见故障 1.常见故障类型 在数据库环境中,常见故障类型: 语句失败,用户进程失败,用户错误 实例失败,介质故障,网络故障 其中最严重的故障主要是用户错误和介 ...
- (4.12)mysql备份还原——mysql逻辑备份之mysqldump
关键词:mysql逻辑备份介绍,mysqldump,mysqldump最佳实践 我的相关文章:https://www.cnblogs.com/gered/p/9721696.html 正文 1.mys ...
- (4.11)mysql备份还原——mysql闪回技术(基于binlog)
0.闪回技术与工具简介 mysql闪回工具比较流行三大类: [0.1]官方的mysqlbinlog:支持数据库在线/离线,用脚本处理binlog的输出,转化成对应SQL再执行.通用性不好,对正则.se ...
- 备份还原mysql数据库
Windows下cmd命令行中备份还原mysql数据库 先cmd 上cd 到mysql的安装bin目录下,然后再运行下面的命令. 例如:cd C:\Program Files\MySQL\MySQL ...
- C#程序调用cmd执行命令-MySql备份还原
1.简单实例 //备份还原mysql public static void TestOne() { Process p = new Process(); p.StartInfo.FileName = ...
- C#备份还原MySql数据库
原文:C#备份还原MySql数据库 项目结束,粘点代码出来让Google或Baidu一下,原因是现在还搜不到这么现成的 调用MySql的工具mysqldump来实现. 类Cmd来实现调用cmd命令, ...
- (4.8)mysql备份还原——binlog查看工具之show binlog的使用
(4.8)mysql备份还原——binlog查看工具之mysqlbinlog及show binlog的使用 关键词:show binlog,mysql binlog查看,二进制文件查看,binlog查 ...
- (4.5)mysql备份还原——深入解析二进制日志(1)binlog的3种工作模式与配置
(4.5)mysql备份还原——深入解析二进制日志(binlog) 关键词:二进制日志,binlog日志 0.建议 (1)不建议随便去修改binlog格式(数据库级别) (2)binlog日志的清理 ...
随机推荐
- linux c++下遍历文件
https://blog.csdn.net/u013617144/article/details/44807333
- wepy-开发总结(功能点)
开发小程序中,遇到的wepy的几点坑,记录一下; 更详细的项目总结记录请见我的个人博客:https://fanghongliang.github.io/ 1.定时器: 在页面中有需要用到倒计时或者其他 ...
- 配置apache密码认证
配置apache密码认证 apache提供了一系列的认证,授权,访问控制模块,我们这里选用最方便的mod_auth_basic,mod_authn_file,mod_authz_user这三个 ...
- OCP
desc dba_objects; select * from dba_objects where rownum = 6; select owner, object_id from dba_objec ...
- layui数据表格分页加载动画,自己定义加载动画,"加载中..."
记录思路,仅供参考 在表格渲染完成后,在done回调函数中给分页动态加点击事件, 关闭"加载中..."动画也是在 done回调函数中关闭 这是我实现的思路,记录给大家参考. , d ...
- 【leetcode】622. Design Circular Queue
题目如下: Design your implementation of the circular queue. The circular queue is a linear data structur ...
- 【leetcode】All Paths From Source to Target
题目如下: Given a directed, acyclic graph of N nodes. Find all possible paths from node 0 to node N-1, a ...
- jquery-时间轴滑动
效果预览图: html: <div class="tim"> <div class="timdiv"> <div class=&q ...
- android 8.0 适配(总结)
android 8.0 对应的 sdk 版本 26 1. 通知栏 Android 8.0 引入了通知渠道,其允许您为要显示的每种通知类型创建用户可自定义的渠道.用户界面将通知渠道称之为通知类别. 针 ...
- 谷歌 AXURE RP EXTENSION拓展问题
我们打开某种文件页面是 会提示我们下载 AXURE RP EXTENSION 拓展. 其实我们可以直接用ie浏览器打开即可,不用下载