9.3.2 map端连接-CompositeInputFormat连接类
1.1.1 map端连接-CompositeInputFormat连接类
(1)使用CompositeInputFormat连接类需要满足三个条件:
1)两个数据集都是大的数据集,不能用缓存文件的方式。
2)数据集都是按照相同的键进行排序;
3)数据集有相同的分区数,同一个键的所有记录在同一个分区中,输出文件不可分割;
要满足这三个条件,输入数据在达到map端连接函数之前,两个数据集被reduce处理,reduce任务数量相同都为n,两个数据集被分区输出到n个文件,同一个键的所有记录在同一个分区中,且数据集中的数据都是按照连接键进行排序的。reduce数量相同、键相同且都是按键排序、输出文件是不可切分的(小于一个HDFS块,或通过gzip压缩实现),则就满足map端连接的前提条件。利用org.apach.hadoop.mapreduce.join包中的CompositeInputFormat类来运行一个map端连接。
(2)CompositeInputFormat类简介
CompositeInputFormat类的作用就将job的输入格式设置为job.setInputFormatClass(CompositeInputFormat.class);同时通过conf的set(String name, String value)方法设置两个数据集的连接表达式,表达式内容包括三个要素:连接方式(inner、outer、override、tbl等) ,读取两个数据集的输入方式,两个数据集的路径。这三个要素按照一定的格式组织成字符串作为表达式设置到conf中。
//设置输入格式为 CompositeInputFormat
job.setInputFormatClass(CompositeInputFormat.class);
//conf设置连接的表达式public static final String JOIN_EXPR = "mapreduce.join.expr";
Configuration conf = job.getConfiguration();
conf.set(CompositeInputFormat.JOIN_EXPR, CompositeInputFormat.compose(
"inner", KeyValueTextInputFormat.class,
FileInputFormat.getInputPaths(job)));
//等价转换之后就是如下表达式
//conf.set("mapreduce.join.expr", CompositeInputFormat.compose(
// "inner", KeyValueTextInputFormat.class, userPath,commentPath));
CompositeInputFormat类的源码如下
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
// package org.apache.hadoop.mapreduce.lib.join; import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map.Entry;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.hadoop.classification.InterfaceAudience.Public;
import org.apache.hadoop.classification.InterfaceStability.Stable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.InputFormat;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.join.Parser.CNode;
import org.apache.hadoop.mapreduce.lib.join.Parser.Node;
import org.apache.hadoop.mapreduce.lib.join.Parser.WNode; @Public
@Stable
public class CompositeInputFormat<K extends WritableComparable> extends InputFormat<K, TupleWritable> {
public static final String JOIN_EXPR = "mapreduce.join.expr";
public static final String JOIN_COMPARATOR = "mapreduce.join.keycomparator";
private Node root; public CompositeInputFormat() {
} public void setFormat(Configuration conf) throws IOException {
this.addDefaults();
this.addUserIdentifiers(conf);
this.root = Parser.parse(conf.get("mapreduce.join.expr", (String)null), conf);
} protected void addDefaults() {
try {//有默认的四种连接方式,每种连接方式都有对应的Reader
CNode.addIdentifier("inner", InnerJoinRecordReader.class);
CNode.addIdentifier("outer", OuterJoinRecordReader.class);
CNode.addIdentifier("override", OverrideRecordReader.class);
WNode.addIdentifier("tbl", WrappedRecordReader.class);
} catch (NoSuchMethodException var2) {
throw new RuntimeException("FATAL: Failed to init defaults", var2);
}
} private void addUserIdentifiers(Configuration conf) throws IOException {
Pattern x = Pattern.compile("^mapreduce\\.join\\.define\\.(\\w+)$");
Iterator i$ = conf.iterator(); while(i$.hasNext()) {
Entry<String, String> kv = (Entry)i$.next();
Matcher m = x.matcher((CharSequence)kv.getKey());
if (m.matches()) {
try {
CNode.addIdentifier(m.group(1), conf.getClass(m.group(0), (Class)null, ComposableRecordReader.class));
} catch (NoSuchMethodException var7) {
throw new IOException("Invalid define for " + m.group(1), var7);
}
}
} } public List<InputSplit> getSplits(JobContext job) throws IOException, InterruptedException {
this.setFormat(job.getConfiguration());
job.getConfiguration().setLong("mapreduce.input.fileinputformat.split.minsize", 9223372036854775807L);
return this.root.getSplits(job);
} public RecordReader<K, TupleWritable> createRecordReader(InputSplit split, TaskAttemptContext taskContext) throws IOException, InterruptedException {
this.setFormat(taskContext.getConfiguration());
return this.root.createRecordReader(split, taskContext);
}
//按格式组织连接表达式
public static String compose(Class<? extends InputFormat> inf, String path) {
return compose(inf.getName().intern(), path, new StringBuffer()).toString();
}
//连接方式(inner、outer、override、tbl等) 、读取两个数据集的输入方式、两个数据集的路径
public static String compose(String op, Class<? extends InputFormat> inf, String... path) {
String infname = inf.getName();//org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat
StringBuffer ret = new StringBuffer(op + '(');
String[] arr$ = path;
int len$ = path.length; for(int i$ = 0; i$ < len$; ++i$) {
String p = arr$[i$];
compose(infname, p, ret);
ret.append(',');
} ret.setCharAt(ret.length() - 1, ')');
return ret.toString();
} public static String compose(String op, Class<? extends InputFormat> inf, Path... path) {
ArrayList<String> tmp = new ArrayList(path.length);
Path[] arr$ = path;
int len$ = path.length; for(int i$ = 0; i$ < len$; ++i$) {
Path p = arr$[i$];
tmp.add(p.toString());
} return compose(op, inf, (String[])tmp.toArray(new String[0]));
} private static StringBuffer compose(String inf, String path, StringBuffer sb) {
sb.append("tbl(" + inf + ",\"");
sb.append(path);
sb.append("\")");
return sb;
}
}
其中主要的函数就是compose函数,他是一个重载函数:
public static String compose(String op, Class<? extends InputFormat> inf, String... path);
op表示连接类型(inner、outer、override、tbl),inf表示数据集的输入方式,path表示输入数据集的文件路径。这个函数的作用是将传入的表达式三要素:连接方式(inner、outer、override、tbl等) 、读取两个数据集的输入方式、两个数据集的路径组成字符串。假设conf按如下方式传入三要素:
conf.set("mapreduce.join.expr", CompositeInputFormat.compose(
"inner", KeyValueTextInputFormat.class,“/hdfs/inputpath/userpath”, “/hdfs/inputpath/commentpath”));
compose函数最终得出的表达式为:
inner(tbl(org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat,” /hdfs/inputpath/userpath”),tbl(org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat,” /hdfs/inputpath/ commentpath”))
现在我只能深入到这里,至于为什么要满足三个条件才可以连接?设置表达式之后内部又是如何实现连接?有知道的欢迎留言讨论。
(3)CompositeInputFormat实现map端连接的实例
成绩数据和名字数据通过CompositeInputFormat实现map连接
成绩数据:
1,yuwen,100
1,shuxue,99
2,yuwen,99
2,shuxue,88
3,yuwen,99
3,shuxue,56
4,yuwen,33
4,shuxue,99名字数据:
1,yaoshuya,25
2,yaoxiaohua,29
3,yaoyuanyie,15
4,yaoshupei,26
文件夹定义如下:

代码:
package Temperature;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.join.CompositeInputFormat;
import org.apache.hadoop.mapreduce.lib.join.TupleWritable;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.File;
import java.io.IOException;
public class CompositeJoin extends Configured implements Tool {
private static class CompositeJoinMapper extends Mapper<Text, TupleWritable,Text,TupleWritable>
{
@Override
protected void map(Text key, TupleWritable value, Context context) throws IOException, InterruptedException {
context.write(key,value);
}
}
public int run(String[] args) throws Exception {
Path userPath = new Path(args[0]);
Path commentPath = new Path(args[1]);
Path output = new Path(args[2]);
Job job=null;
try {
job = new Job(getConf(), "mapinnerjoin");
} catch (IOException e) {
e.printStackTrace();
}
job.setJarByClass(getClass());
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(TupleWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(TupleWritable.class);
// 设置两个输入数据集的目录
FileInputFormat.addInputPaths(job, args[0]);
FileInputFormat.addInputPaths(job, args[1]);
//设置输出目录
FileOutputFormat.setOutputPath(job,output);
Configuration conf = job.getConfiguration();
//设置输入格式为 CompositeInputFormat
job.setInputFormatClass(CompositeInputFormat.class);
conf.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator", ",");
//conf设置连接的表达式public static final String JOIN_EXPR = "mapreduce.join.expr";
//conf.set(CompositeInputFormat.JOIN_EXPR, CompositeInputFormat.compose(
// "inner", KeyValueTextInputFormat.class,
// FileInputFormat.getInputPaths(job)));
//等价转换之后就是如下表达式
String strExpretion=CompositeInputFormat.compose("inner", KeyValueTextInputFormat.class, userPath,commentPath);
conf.set("mapreduce.join.expr",strExpretion );
job.setOutputFormatClass(TextOutputFormat.class);
job.setNumReduceTasks(0);//map端连接,reduce为0,不使用reduce
job.setMapperClass(CompositeJoinMapper.class);
//键值属性分隔符设置为空格
//删除结果目录,重新生成
FileUtil.fullyDelete(new File(args[2]));
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception
{
//三个参数,两个连接的数据路径,一个输出路径
int exitCode= ToolRunner.run(new CompositeJoin(),args);
System.exit(exitCode);
}
}
设置run->edit Configuration设置输入输出路径,两个输入,一个输出
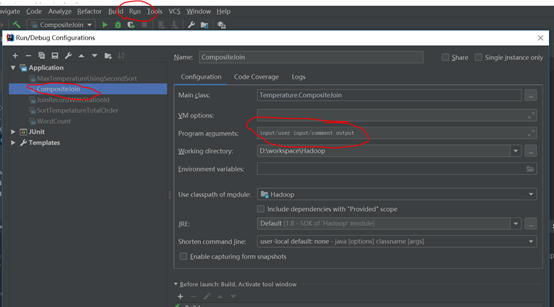
运行该类的main函数得到结果

自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取:
https://www.cnblogs.com/bclshuai/p/11380657.html
9.3.2 map端连接-CompositeInputFormat连接类的更多相关文章
- 使用map端连接结合分布式缓存机制实现Join算法
前面我们介绍了MapReduce中的Join算法,我们提到了可以通过map端连接或reduce端连接实现join算法,在文章中,我们只给出了reduce端连接的例子,下面我们说说使用map端连接结合分 ...
- 9.3.1 map端连接- DistributedCache分布式缓存小数据集
1.1.1 map端连接- DistributedCache分布式缓存小数据集 当一个数据集非常小时,可以将小数据集发送到每个节点,节点缓存到内存中,这个数据集称为边数据.用map函数 ...
- Asp.Net SignalR - 持久连接类
持久连接类 通过SignalR持久连接类可以快速的构建一个即时通讯的应用,上篇博文已经我们创建一个owin Startup类和一个持久连接类来完成我们的工作,然后在Startup类的Configura ...
- ADO.NET基础巩固-----连接类和非连接类
最近的一段时间自己的状态还是不错的,早上,跑步,上自习看书,下午宿舍里面编程实战,晚上要么练习代码,要么去打球(在不打就没机会了),生活还是挺丰富的. 关于C#的基础回顾就先到前面哪里,这 ...
- 深入理解php的MySQL连接类
php的MySQL连接类. 后面几个show_databases和show_tables....等方法都用了一堆echo,好像一直不喜欢在类的方法里直接用输出语句,不过这也只是列举数据库和表名,构造 ...
- List、Map和Set实现类
List.Map和Set实现类 1.List实现类 (1)ArrayList (2)Vector 2.Map实现类 (1)HashMap (2)Hashtable 3.Set实现类 (1)HashSe ...
- PHP mysqli方式连接类
分享一个PHP以mysqli方式连接类完整代码实例,有关mysqli用法实例. 一个在PHP中以mysqli方式连接数据库的一个数据库类实例,该数据库类是从一个PHP的CMS中整理出来的,可实现PHP ...
- C/S模式客户端连接服务器连接不上的问题
C/S模式客户端连接服务器连接不上的问题 1.服务器电脑防火墙关闭 2.服务器端SQL SERVER2008R: 配置工具--SQL SERVER配置管理器 MSSQLSERVER协议.客户端协议(S ...
- [C++学习笔记14]动态创建对象(定义静态方法实现在map查找具体类名对应的创建函数,并返回函数指针,map真是一个万能类)good
[C++学习笔记14]动态创建对象 C#/Java中的反射机制 动态获取类型信息(方法与属性) 动态创建对象 动态调用对象的方法 动态操作对象的属性 前提:需要给每个类添加元数据 动态创建对象 实 ...
随机推荐
- [JavaScript设计模式] 什么是单例模式
概念 保证一个类仅有一个实例,并提供一个全局访问点 为什么要用单例模式 想象一下某些web应用,当点击登录按钮时,会弹出一个登录框,无论你点击多少次这个登录按钮,登录框都只会出现一个,不会出现多个登录 ...
- 【转】Java Web Services面试问题集锦
Q. 应用集成方式有哪些? A. 应用可以采用以下方式集成: 1. 共享数据库 2. 批量文件传输 3. 远程过程调用(RPC) 4. 通过消息中间件来交换异步信息(MOM) Q. 应用集成可以采用的 ...
- element-ui input 组件 回车事件
直接在el-input 标签上添加@keyup.enter="funName" 是不起作用的,在组件中使用需要加上.native. <el-input v-model = & ...
- 简单 hash 入门题目
题目描述 NOIP 复赛之前,HSD 桑进行了一项研究,发现人某条染色体上的一段 DNA 序列中连续的 kkk 个碱基组成的碱基序列与做题的 AC 率有关!于是他想研究一下这种关系.现在给出一段 DN ...
- 干货!SQL性能优化,书写高质量SQL语句
写SQL语句的时候我们往往关注的是SQL的执行结果,但是是否真的关注了SQL的执行效率,是否注意了SQL的写法规范? 以下的干货分享是在实际开发过程中总结的,希望对大家有所帮助! 1. limit分页 ...
- 小白学Java:奇怪的RandomAccess
目录 小白学Java:奇怪的RandomAccess RandomAccess是个啥 forLoop与Iterator的区别 判断是否为RandomAccess 小白学Java:奇怪的RandomAc ...
- select的disabled形式的数据,使用表单序列化方式无法将数据传到后台
之前博客里有讲述到使用表单序列化的方式传递数据到后台,那里是将数据为disabled形式的内容剔除掉了,所以为disabled的select肯定也是传不过去的. 解决方式: 1.在序列化表单方法之前将 ...
- Activiti邮件任务
Activiti邮件任务 作者:Jesai 会不会有那么一天,你会妒忌 Activiti有一种任务叫做邮件任务,顾名思义,就是流程办理到邮件任务的时候,系统就会自动的给你发送任务. Activiti所 ...
- scala 对一个数组分组操作
通常我们有一些需求,对一个数组两两进行翻转,通常就涉及到奇数偶数,否则就会出现数组index异常了,所以我们该怎么办呢? 虽然是一个入门级问题,但是我还是觉得这是一个很有意思的题目,因此写了一个对于通 ...
- form get
<form action=""> <input type="text" name="query" id="&qu ...