数据预处理 | 使用 OneHotEncoder 及 get_dummuies 将分类型数据转变成哑变量矩阵
【分类数据的处理】
问题:
在数据建模过程中,很多算法或算法实现包无法直接处理非数值型的变量,如 KMeans 算法基于距离的相似度计算,而字符串则无法直接计算距离
如:
性别中的男和女 [0,1] [1,0]
用户的价值度分为高、中、低
处理方法:
将字符串表示的 分类特征 转换成 数值 类型(哑变量矩阵)
导入数据:
import pandas as pd
from sklearn.preprocessing import OneHotEncoder # 生成数据
df = pd.DataFrame({'id': [3566841, 6541227, 3512441],
'sex': ['male', 'Female', 'Female'],
'level': ['high', 'low', 'middle'],
'score': [1, 2, 3]})

方法 1 :使用 sklearn 库的 OneHotEncoder
# 获得ID列(还保留二维的形式,等一会儿还要拼回去)
id_data = df[['id']]
# 指定要转换的列
test_data = df.iloc[:,1:] # 建立标志转换模型对象(也称为哑编码对象)
onehot_model = OneHotEncoder()
df1 = onehot_model.fit_transform(test_data).toarray() # 拼接
df_all = pd.concat((id_data, pd.DataFrame(df1)), axis=1)

完成转换~
注:
1> 通过 OneHotEncoder 后,得到一个矩阵对象,
# 得到的 df1 是一个矩阵对象 <3x8 sparse matrix of type '<class 'numpy.float64'>'
df1 = onehot_model.fit_transform(test_data)

2> 矩阵进行 toarray() 后,得到 array 对象, 得到的 array 要进一步转化成 DataFrame,才能使用 pd.concat 完成拼接
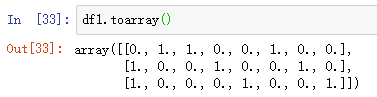
df1 = pd.DataFrame(df1.toarray())
df_all = pd.concat([id_data,df1],axis=1)
方法二:使用 pandas 的 get_dummuies
此方法只会对非数值类型的数据做转换
id_data = df.id
test_data = df.iloc[:,1:] test_data_dum = pd.get_dummies(test_data) # 核心代码
df_dum = pd.concat([id_data, test_data_dum],axis=1)
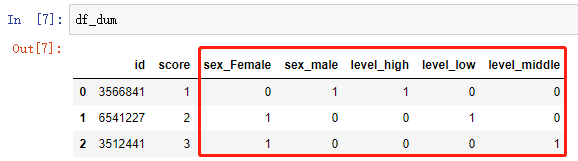
保留数值型特征 score,对非数值型的 sex 和 level 进行了转换
数据预处理 | 使用 OneHotEncoder 及 get_dummuies 将分类型数据转变成哑变量矩阵的更多相关文章
- 机器学习实战基础(十一):sklearn中的数据预处理和特征工程(四) 数据预处理 Preprocessing & Impute 之 处理分类特征:编码与哑变量
处理分类特征:编码与哑变量 在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的 ...
- sklearn preprocessing 数据预处理(OneHotEncoder)
1. one hot encoder sklearn.preprocessing.OneHotEncoder one hot encoder 不仅对 label 可以进行编码,还可对 categori ...
- Python数据预处理:机器学习、人工智能通用技术(1)
Python数据预处理:机器学习.人工智能通用技术 白宁超 2018年12月24日17:28:26 摘要:大数据技术与我们日常生活越来越紧密,要做大数据,首要解决数据问题.原始数据存在大量不完整.不 ...
- 吴裕雄 python 机器学习——数据预处理二元化OneHotEncoder模型
from sklearn.preprocessing import OneHotEncoder #数据预处理二元化OneHotEncoder模型 def test_OneHotEncoder(): X ...
- 机器学习实战基础(十二):sklearn中的数据预处理和特征工程(五) 数据预处理 Preprocessing & Impute 之 处理分类特征:处理连续性特征 二值化与分段
处理连续性特征 二值化与分段 sklearn.preprocessing.Binarizer根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量.大于阈值的值映射为1,而小于或等于阈值的值 ...
- 数据准备<3>:数据预处理
数据预处理是指因为算法或者分析需要,对经过数据质量检查后的数据进行转换.衍生.规约等操作的过程.整个数据预处理工作主要包括五个方面内容:简单函数变换.标准化.衍生虚拟变量.离散化.降维.本文将作展开介 ...
- 【sklearn】数据预处理 sklearn.preprocessing
数据预处理 标准化 (Standardization) 规范化(Normalization) 二值化 分类特征编码 推定缺失数据 生成多项式特征 定制转换器 1. 标准化Standardization ...
- 第一章:AI人工智能 の 数据预处理编程实战 Numpy, Pandas, Matplotlib, Scikit-Learn
本课主题 数据中 Independent 变量和 Dependent 变量 Python 数据预处理的三大神器:Numpy.Pandas.Matplotlib Scikit-Learn 的机器学习实战 ...
- sklearn学习笔记(一)——数据预处理 sklearn.preprocessing
https://blog.csdn.net/zhangyang10d/article/details/53418227 数据预处理 sklearn.preprocessing 标准化 (Standar ...
随机推荐
- C++ char to string 方法
1. 使用string()构造函数方法 //method 1: the constructor of string() char c = 'F'; , c); cout << s ; 2. ...
- Redis-位图
关于位图,可能大家不太熟悉, 那么位图能干啥呢?位图的内容其实就是普通的字符串,也就是byte数组,我们都知道 byte 8 位无符号整数 0 到 255 说个场景.比如你处理一些业务时候,往往会存在 ...
- ELK学习002:Elasticsearch 7.x 的安装及配置
Elasticsearch 的安装与启动 1.1 下载 Elasticsearch 7.6.0 下载地址:https://www.elastic.co/cn/downloads/elasticsear ...
- Win10好用的快捷键
Win10好用的快捷键 Win键,Tab键,空格键,上下左右方向键,Enter键,Shift+Tab键 Win键--Tab键--上下左右方向键--Enter确定或者---空格键(确定的意思),Ente ...
- python——异常(1),捕获特定异常
"""1.捕获指定异常,异常类型有多种2.若尝试执行的代码异常类型与捕获的异常类型不同则报错3.try下方一般只放一行代码,若有多行可能异常代码,则捕获一个异常类型后函数 ...
- Azure Media Services -可提供视频点播(VOD)
Azure Media Services 提供直播/VOD点播相关的功能. •提供编码和打包以适用于各种设备播放视频(IOS/Android/web等). •向大量在线观众流式传输实时直播,例如活动 ...
- Html介绍,认识html文件基本结构
一个HTML文件的基本机构如下: <html><head>...</head><body>...</body></html>代码 ...
- 多柱汉诺塔问题“通解”——c++
多柱汉诺塔问题 绪言 有位同学看到了我的初赛模拟卷上有一道关于汉诺塔的数学题.大概就是要求4柱20盘的最小移动次数. 他的数学很不错,找到了应该怎样推. 如果要把n个盘子移到另一个柱子上,步骤如下: ...
- android中关于时间的控件
1.日期选择器 <DatePicker android:layout_width="wrap_content" android:layout_height="wra ...
- Android_向用户发送短信
一段代码,用的时候copy就行 记得在manifest里声明send-sms和read-sms权限 public class SendMsgActivity extends AppCompatActi ...