ES读写数据过程及原理
ES读写数据过程及原理
倒排索引
首先来了解一下什么是倒排索引
倒排索引,就是建立词语与文档的对应关系(词语在什么文档出现,出现了多少次,在什么位置出现)
搜索的时候,根据搜索关键词,直接在索引中找到对应关系,搜索速度快。
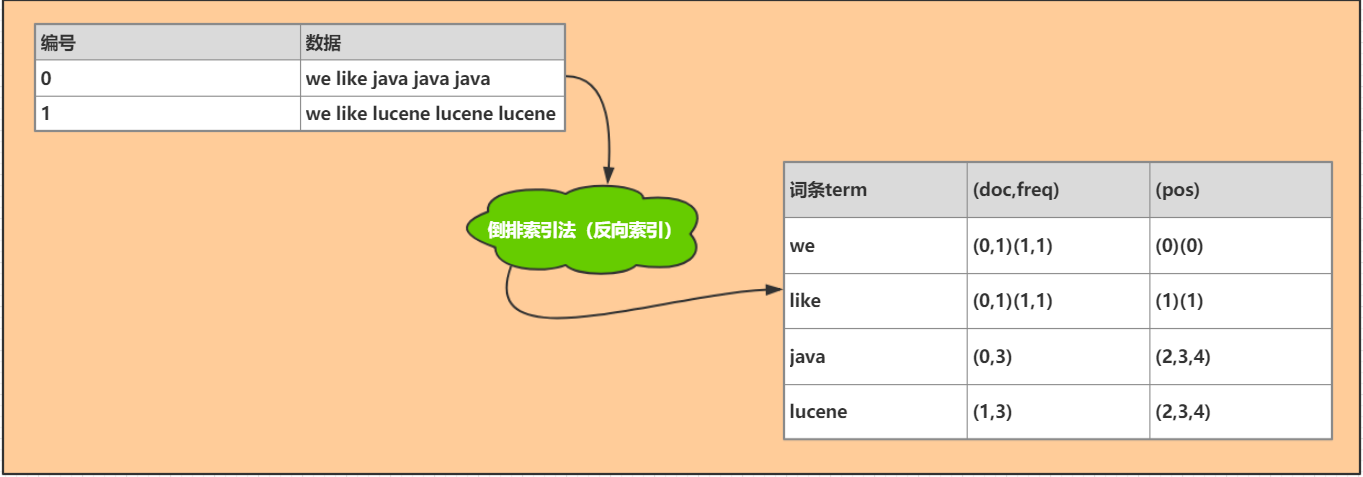

doc:表示哪个文档,
frep:表示出现的频率
pos:表示出现的位置
1、写数据过程
客户端通过hash选择一个node发送请求,这个node被称做coordinating node(协调节点),
协调节点对docmount进行路由,将请求转发给到对应的primary shard
primary shard 处理请求,将数据同步到所有的replica shard
此时协调节点,发现primary shard 和所有的replica shard都处理完之后,就反馈给客户端。
2、写数据的底层原理

在到达primary shard的时候 ,数据先写入内存buffer , 此时,在buffer里的数据是不会被搜索到的同时生成一个translog日志文件 , 将数据写入translog里
如果内存buffer空间快man满了,就会将数据refresh到一个新的segment file文件中,而且es里每隔1s就会将buffer里的数据写入到一个新的segment file中,这个segment file就存储最最近1s中buffer写入的数据,如果buffer里面没有数据,就不会执行refresh操作,当建立segment file文件的时候,就同时建立好了倒排索引库。
在buffer refresh到segment之前 ,会先进入到一个叫os cache中,只要被执行了refresh操作,就代表这个数据可以被搜索到了。数据被输入os cache中,buffer就会被清空了,所以为什么叫es是准实时的?NRT,near real-time,准实时。默认是每隔1秒refresh一次的,所以es是准实时的,因为写入的数据1秒之后才能被看到。还可以通过es的restful api或者java api,手动执行一次refresh操作,就是手动将buffer中的数据刷入os cache中,让数据立马就可以被搜索到。
就这样新的数据不断进入buffer和translog,不断将buffer数据写入一个又一个新的segment file中去,每次refresh完buffer清空,translog保留。随着这个过程推进,translog会变得越来越大。当translog达到一定长度的时候,就会触发commit操作。translog也是先进入os cache中,然后每隔5s持久化到translog到磁盘中,
commit操作,第一步,就是将buffer中现有数据refresh到os cache中去,清空buffer 每隔30分钟flush
es也有可能会数据丢失 ,有5s的数据停留在buffer、translog os cache, segment file os cache中,有5s的数据不在磁盘上,如果此时宕机,这5s的数据就会丢失,如果项目要求比较高,不能丢失数据,就可以设置参数,每次写入一条数据写入buffer,同时写入translog磁盘文件中,但这样做会使es的性能降低。
如果是删除操作,commit操作的时候就会生成一个.del文件,将这个document标识为deleted状态,在搜索的搜索的时候就不会被搜索到了。
如果是更新操作,就是将原来的document标识为deleted状态,然后新写入一条数据
buffer每次refresh一次,就会产生一个segment file,所以默认情况下是1秒钟一个segment file,segment file会越来越多,当躲到一定程度的时候,es就会自动触发merge(合并)造作,将所有segment file文件 merge成一个segment file,并同时物理删除掉标识为deleted的doc,
3、es读取过程
客户端发送get请求到任意一个node节点,然后这个节点就称为协调节点,
协调节点对document进行路由,将请求转发到对应的node,此时会使用随机轮询算法,在primary shard 和replica shard中随机选择一个,让读取请求负载均衡,
接收请求的node返回document给协调节点,
协调节点,返回document给到客户端
4、 搜索过程
客户端发送请求到协调节点,
协调节点将请求大宋到所有的shard对应的primary shard或replica shard ;
每个shard将自己搜索到的结果返回给协调节点,返回的结果是dou.id或者自己自定义id,然后协调节点对数据进行合并排序操作,最终得到结果。
最后协调节点根据id到个shard上拉取实际 的document数据,左后返回给客户端。
ES读写数据过程及原理的更多相关文章
- ES读写数据的工作原理
es写入数据的工作原理是什么啊?es查询数据的工作原理是什么?底层的lucence介绍一下呗?倒排索引了解吗? 一.es写数据过程 1.客户端选择一个node发送请求过去,这个node就是coordi ...
- 面试系列八 es写入数据的工作原理
(1)es写数据过程 1)客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点) 2)coordinating node,对document进行路由,将请求 ...
- HDFS读写数据过程
一.文件的打开 1.1.客户端 HDFS打开一个文件,需要在客户端调用DistributedFileSystem.open(Path f, int bufferSize),其实现为: public F ...
- 【ElasticSearch】ES 读数据,写数据与搜索数据的过程
ES读数据的过程: 1.ES客户端选择一个node发送请求,该请求作为协调节点(coordinating node): 2.corrdinating node 对 doc id 对哈希,找出该文档对应 ...
- ElasticSearch写入数据的工作原理是什么?
面试题 es 写入数据的工作原理是什么啊?es 查询数据的工作原理是什么啊?底层的 lucene 介绍一下呗?倒排索引了解吗? 面试官心理分析 问这个,其实面试官就是要看看你了解不了解 es 的一些基 ...
- ElasticSearch 基本介绍和读写搜索过程
cluster 代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的.es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部 ...
- 【分布式搜索引擎】Elasticsearch写入和读取数据过程
一.Elasticsearch写人数据的过程 1)客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)2)coordinating node,对docum ...
- Scrapy-redis实现分布式爬取的过程与原理
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的时候,单个主机的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求 ...
- C# .Net 多进程同步 通信 共享内存 内存映射文件 Memory Mapped 转 VC中进程与进程之间共享内存 .net环境下跨进程、高频率读写数据 使用C#开发Android应用之WebApp 分布式事务之消息补偿解决方案
C# .Net 多进程同步 通信 共享内存 内存映射文件 Memory Mapped 转 节点通信存在两种模型:共享内存(Shared memory)和消息传递(Messages passing). ...
随机推荐
- python day01练习和作业
习题:1.简述编译型与解释型语言的区别,且分别列出你知道的哪些语言属于编译型,哪些属于解释型编译型语言:优点:执行速度快 缺点:维护成本高,跨平台性差解释型语言:优点:维护成本低,跨平台性好 缺点:执 ...
- 《ASP.NET Core 高性能系列》环境(EnvironmentName)的设置
一.概述 程序启动时Host捕获到环境相关数据,然后交由IEnvironment(传说要作废,但是觉得这个有设计点问题,因为.NET Core 非Web怎么处理?),然后交由IWebHostEnvir ...
- ubuntu+mysql+php+apache2+wordpress建站全记录
虽然操作并不难,但用到的各种命令,各种坑的解决方法还需要记一下 建好的博客: 念诗之人的博客 VPS和域名选购 VPS选购 国内外有很多商家可供选择,国内有如阿里云,百度云,腾讯云等(ECS,BCC等 ...
- VMware Workstation 14 Pro 安装 CentOS 7 Linux 虚拟机
CentOS 7 下载地址:http://isoredirect.centos.org/centos/7/isos/x86_64/ ,选择 CentOS-7-x86_64-DVD-1908.iso : ...
- OpenCV3入门(八)图像边缘检测
1.边缘检测基础 图像的边缘是图像的基本特征,边缘点是灰度阶跃变化的像素点,即灰度值的导数较大或极大的地方,边缘检测是图像识别的第一步.用图像的一阶微分和二阶微分来增强图像的灰度跳变,而边缘也就是灰度 ...
- go微服务框架kratos学习笔记八 (kratos的依赖注入)
目录 go微服务框架kratos学习笔记八(kratos的依赖注入) 什么是依赖注入 google wire kratos中的wire Providers injector(注入器) Binding ...
- 《C/C++实现Console下的加载进度条模拟[美观版]》
前言 有时候我们会遇到在CMD或DOS控制台上出现的加载进度条,虽然不是如网页和软件写的美观.但确确实实也有着自己的特色.而且,一个好看的加载进度条也能增加用户使用控制台程序的体验!所以,拿来研究 ...
- Python3(八) 枚举详解
一.枚举其实是一个类 建议标识名字用大写 1.枚举类: from enum import Enum class VIP(Enum): YELLOW = 1 GREEN = 2 ...
- Linux bash管道符“|”使用介绍与例子
https://blog.csdn.net/wangqianyilynn/article/details/75576815
- 基于 H5 Canvas 实现楼宇新风系统
前言 现如今,新型冠状病毒疫情牵动着每一个人的神经,每天起床后的第一件事就是打开疫情地图,看看最新的疫情数据. (http://www.hightopo.com/demo/coronavirus/) ...