小爬爬7:回顾&&crawlSpider
1.回顾昨日内容
回顾
- 全站数据爬取(分页)
- 手动请求的发送Request(url,callback)
- post请求和cookie处理
- start_requests(self)
- FromRequest(url,callback,formdata)
- cookie操作是自动处理 - 请求传参
- 使用场景:
- 实现:scrapy.Request(url,callback,meta={'':''})
callback:response.meta['']
- 中间件
- 下载中间件:批量拦截所有的请求和响应
- 拦截请求:UA伪装(process_request),代理ip(process_exception:return request)
- 拦截响应:process_response
2.crawl总结
- CrawlSpider
作用:就是用于进行全站数据的爬取
- CrawlSpider就是Spider的一个子类
- 如何新建一个基于CrawlSpider的爬虫文件
- scrapy genspider -t crawl xxx www.xxx.com
- LinkExtractor连接提取器:根据指定规则(正则)进行连接的提取
- Rule规则解析器:将链接提取器提取到的链接进行请求发送,然后对获取的页面数据进行
指定规则(callback)的解析
- 一个链接提取器对应唯一一个规则解析器
3.高效的全栈数据爬取
新建一个抽屉的项目,我们对其进行全栈数据的爬取


下图是页码对应的url

# -*- coding: utf- -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule class ChoutiSpider(CrawlSpider):
name = 'chouti'
# allowed_domains = ['www.xxx.com']
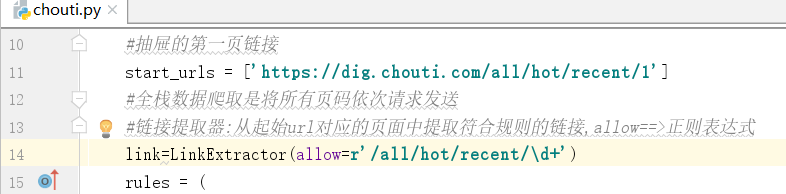
#抽屉的第一页链接
start_urls = ['https://dig.chouti.com/all/hot/recent/1']
#全栈数据爬取是将所有页码依次请求发送
#链接提取器:从起始url对应的页面中提取符合规则的链接,allow==>正则表达式
link=LinkExtractor(allow=r'/all/hot/recent/\d+')
rules = (
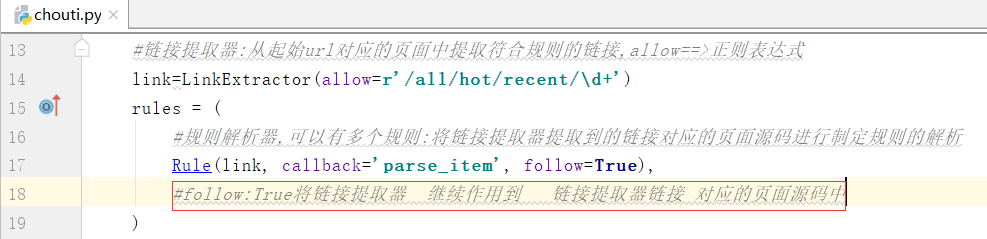
#规则解析器,可以有多个规则:将链接提取器提取到的链接对应的页面源码进行制定规则的解析
Rule(link, callback='parse_item', follow=False),
) def parse_item(self, response):
# item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
# return item
print(response)
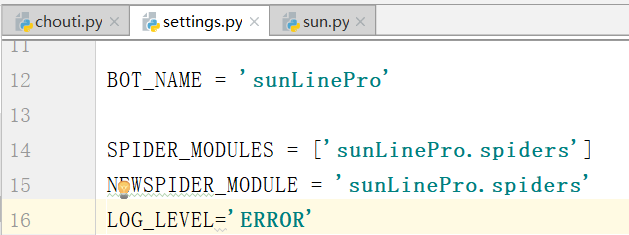
修改下面的内容:
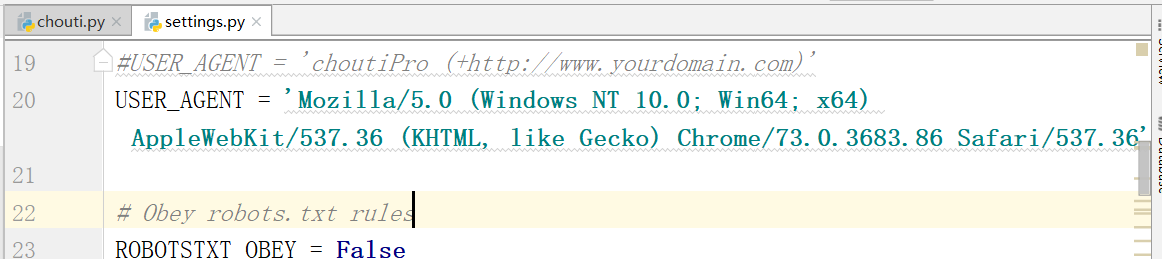
LOG_LEVEL='ERROR'
下面我们提取指定的规则执行下面的命令:
运行之后,我们只是爬取到了10条数据

我们需要将最后一个界面作为起始,也就是follow=True就可以了
再次运行下面的命令:
运行上边的命令,我们就成功取到120页的数据.
自己理解这句话:
follow:True将链接提取器继续作用到链接提取器链接对应的页面源码中,
新的需求:
4.crawlSpider深度爬取
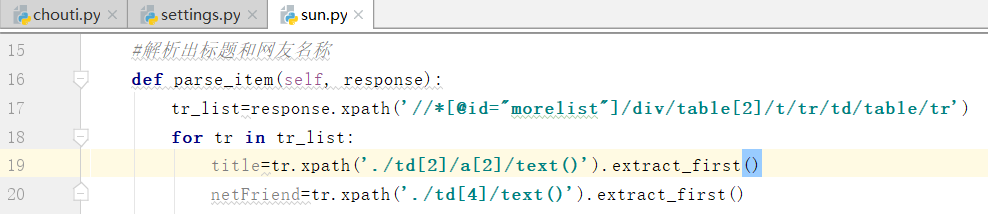
案例:阳光热线,我们解析出首页的对应"标题"和详情页中的"段落"
2个链接提取器和2和规则解析器
(1)下面第一步,我们需要新建一个工程


添加UA和修改robot协议为false
注释allowed_domains,并且将起始url写在start_urls里边
阳光热线的第一页:http://wz.sun0769.com/index.php/question/report?page=
看一下,我们如何取到源码的链接:
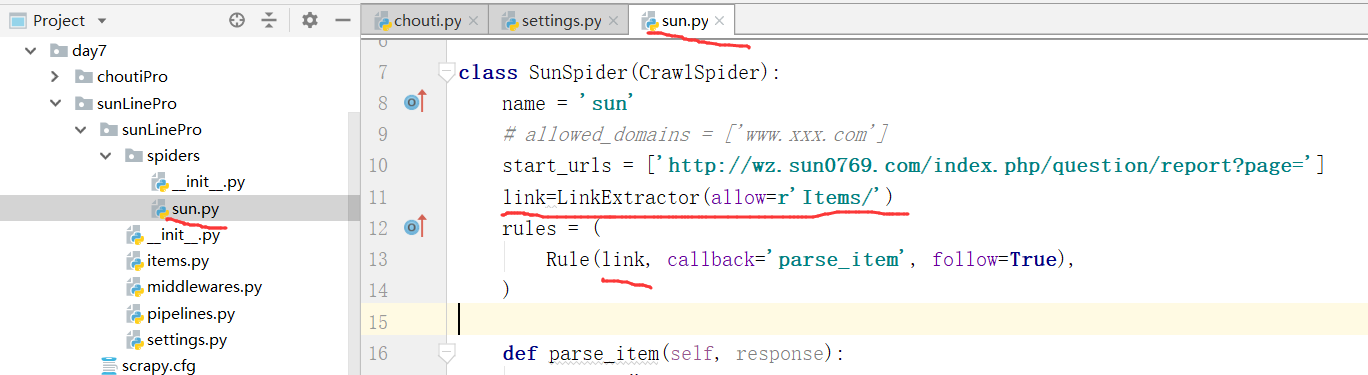
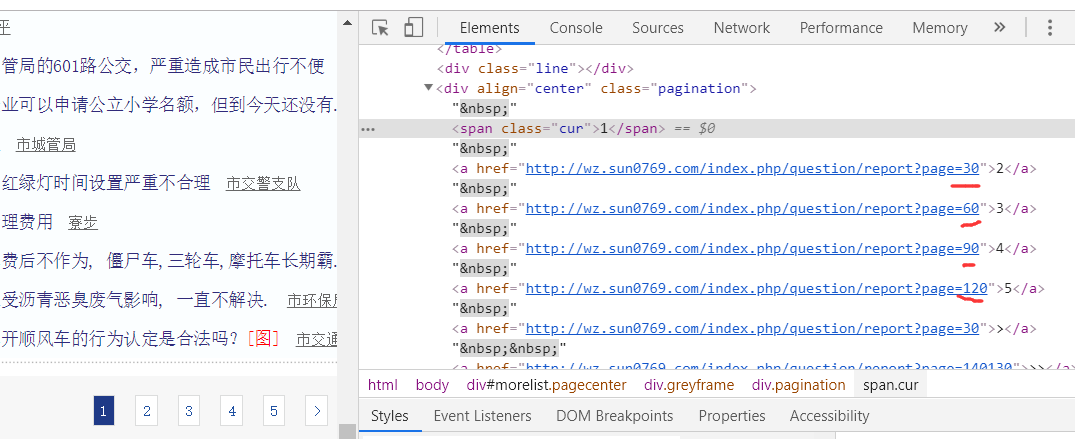
我们看到的是页码中的数据是30的倍数,对比我们看到了这个发生了变化
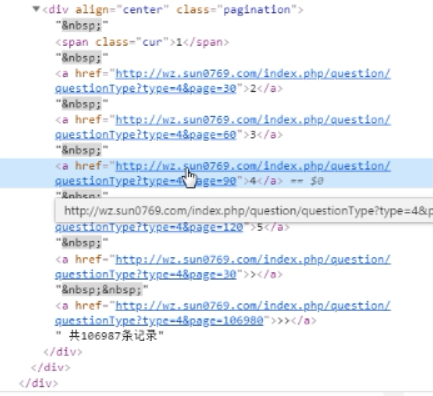

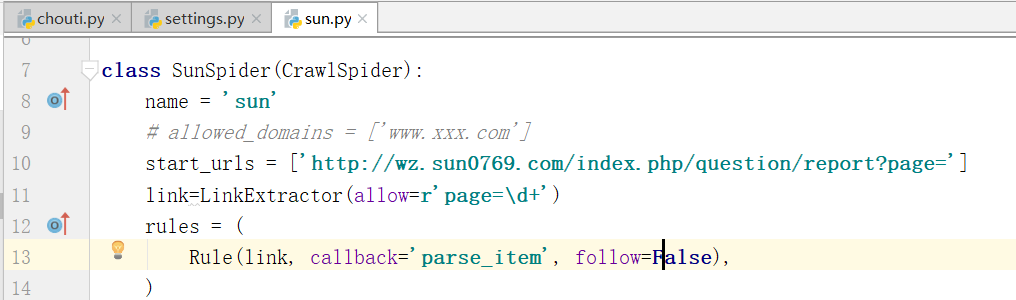
修改follow=False,只爬取前五页,原因是数据量太大
我们需要拿到table的xpath解析,注意要修改tbody,再拿到下面的tr
执行程序
小爬爬7:回顾&&crawlSpider的更多相关文章
- ELK之开心小爬爬
1.开心小爬爬 在爬取之前需要先安装requests模块和BeautifulSoup这两个模块 ''' https://www.autohome.com.cn/all/ 爬取图片和链接 写入数据库里边 ...
- 小爬爬6.scrapy回顾和手动请求发送
1.数据结构回顾 #栈def push(self,item) def pop(self) #队列 def enqueue(self,item) def dequeue(self) #列表 def ad ...
- 小爬爬5:重点回顾&&移动端数据爬取1
1. ()什么是selenium - 基于浏览器自动化的一个模块 ()在爬虫中为什么使用selenium及其和爬虫之间的关联 - 可以便捷的获取动态加载的数据 - 实现模拟登陆 ()列举常见的sele ...
- java小知识点简单回顾
1.java的数据类型分为两种:简单类型和引用类型(数组.类以及接口).注意,java没有指针的说法,只有引用.简单类型的变量被声明时,存储空间也同时被分配:而引用类型声明变量(对象)时,仅仅为其分配 ...
- 小爬爬5:scrapy介绍3持久化存储
一.两种持久化存储的方式 1.基于终端指令的吃持久化存储: 特点:终端指令的持久化存储,只可以将parse方法的返回值存储到磁盘文件 因此我们需要将上一篇文章中的author和content作为返回值 ...
- 小爬爬4:12306自动登录&&pyppeteer基本使用
超级鹰(更简单的操作验证) - 超级鹰 - 注册:普通用户 - 登陆: - 创建一个软件(id) - 下载示例代码 1.12306自动登录 # Author: studybrother sun fro ...
- 小爬爬1:jupyter简单使用&&爬虫相关概念
1.jupyter的基本使用方式 两种模式:code和markdown (1)code模式可以直接编写py代码 (2)markdown可以直接进行样式的指定 (3)双击可以重新进行编辑 (4)快捷键总 ...
- 小爬爬5:scrapy介绍2
1.scrapy:爬虫框架 -框架:集成了很多功能且具有很强通用性的一个项目模板 -如何学习框架:(重点:知道有哪些模块,会用就行) -学习框架的功能模板的具体使用. 功能:(1)异步爬取(自带buf ...
- 小爬爬6: 网易新闻scrapy+selenium的爬取
1.https://news.163.com/ 国内国际,军事航空,无人机都是动态加载的,先不管其他我们最后再搞中间件 2. 我们可以查看到"国内"等板块的位置 新建一个项目,创建 ...
随机推荐
- 【DM642学习笔记九】XDS560仿真器 Can't Initialize Target CPU
以前用的瑞泰的ICETEK-5100USB仿真器,现在换成XDS560试了试,速度快多了.把720*576的图片在imgae中显示也只需要四五秒钟.而5100仿真器需要三四分钟. 仿真器驱动安好后,刚 ...
- Django模型中的OneToOneField和ForeignKey有什么区别?
说是ForeignKey是one-to-many的,并举了一个车的例子: 有两个配件表,一个是车轮表,另一个是引擎表.两个表都有一个car字段,表示该配件对应的车. 对于车轮来说,多个对应一个car的 ...
- c++ 链接mysql:error LNK2019: 无法解析的外部符号
使用VS2012编译项目报错如下: error LNK2019: 无法解析的外部符号 _mysql_real_connect@32,该符号在函数 _main 中被引用 error LNK2019: 无 ...
- vim编辑shell
vi编辑 u撤销 i输入 dd删除游标所在的那一整行(常用) yy复制游标所在的那一行(常用) p 为将已复制的数据在光标下一行贴上 nyy n 为数字.复制光标所在的向下 n 行,例如 20yy ...
- maximum clique 1
maximum clique 1 时间限制:C/C++ 1秒,其他语言2秒空间限制:C/C++ 262144K,其他语言524288KSpecial Judge, 64bit IO Format: % ...
- angular1.0 $http jsonp callback
$http.jsonp(sDUrl,{cache:false,jsonpCallbackParam:'callback'}); https://stackoverflow.com/questions/ ...
- git与github建立链接(将本次项目与网络GitHub同步)(二)
第一步:我们需要先创建一个本地的版本库(其实也就是一个文件夹). 你可以直接右击新建文件夹,也可以右击打开Git bash命令行窗口通过命令来创建. 现在我通过命令行在桌面新建一个TEST文件夹(你也 ...
- MacBook安装QF9700网卡驱动
HOW TO USE A GENERIC USB ETHERNET ADAPTER QF9700 ON MAC OS X 20 February 2016 macOS Zahid Mahmood ...
- Markdown文档使用
Markdown使用 一.markdown标题:1级-6级 一级 #空格 二级 ##空格 三级 ###空格 ... 六级 ######空格 二.代码块 print("hello world! ...
- 使用junit单元测试,报Cannot instantiate test(s): java.lang.SecurityException: Prohibited package name: java.com.com.test
在测试类中不能一级包名不能以java开头, 将包改为com.com.test就好了.