base64加/解密算法C++实现
base64编码原理:维基百科 - Base64
其实编码规则很简单,将字符串按每三个字符组成一组,因为每个字符的 ascii 码对应 0~127 之间(显然,不考虑其他字符集编码),即每个字符的二进制以 8 bit 存储,$ 3 \times 8 = 4 \times 6 $,这样就可以很方便的转为 4 个 6 bit 的字符,当一组中的字符(最后一组会出现这样的情况)少于3个字符,则用"="字符填充。
解码也就是一个逆过程,也不难(见最后完整实现代码:base64decode())。
既然是二进制,显然应该想到利用位操作。。。
注意到:
1. 6 bit 的二进制组成的数的十进制一定小于 64,$ (111111)_{2} = (63)_{10} $。这就是那张 base64 表的原因。
2.将前一个字符的多余的二进制,填充到后一位字符的二进制的前面以填充满 6 位,每 3 个字符为 1 周期 。
如果对位操作很熟练,那么这个算法会很简单(核心部分):
unsigned bit[6] = {0u};
size_t ens = 0, i = 2u;
for (unsigned j = 0u; inputs[j]; j++)
{
int asc_ = int(inputs[j]);
unsigned inx = asc_ >> i;
for (unsigned k = 0u; k < i - 2; k++)
inx += (bit[k] & 1) << (8 + k - i); // min: 0, max:{1, 2, 4, 8, 16, 32}
encode[ens++] = base64_table[inx];
if (i != 6) {
for (unsigned k = 0u, n = asc_; k < i; n >>= 1, k++)
bit[k] = n & 1;
i += 2;
}
else {
i = asc_;
inx = i >= 64 ? (i >= 128 ? i - 128 : i - 64) : i;
encode[ens++] = base64_table[inx];
if (inputs[j + 1] != '\0') i = 2;
}
}
下面从分析时间复杂度方向来解释算法:
unsigned bit[6] = {0u};
size_t ens = 0, i = 2u;
首先我们需要维护一个大小为6的无符号整形数组 bit 来存储6个二进制数位;
ens 是用来维护 encode 字符数组的栈下标;
变量 i 扮演了几个小而十分重要的角色:判断周期变化,维护扫描到的每一个字符当前应该做多少次的位移数,当 $ i = 6 $ ,意味着可以通过当前分组中的第3个字符的后 6 bit 编码得到第 4 个字符,这里为了减少局部变量冗余以及便利,我使用了 i 来多做了一点本不属于它的任务。
然后进入循环主体
for (unsigned j = 0u; inputs[j]; j++)
循环次数为我们需要编码的字符串的长度。
int asc_ = int(inputs[j]);
unsigned inx = asc_ >> i;
for (unsigned k = 0u; k < i - 2; k++)
inx += (bit[k] & 1) << (8 + k - i); // min: 0, max:{1, 2, 4, 8, 16, 32}
encode[ens++] = base64_table[inx];
上面代码片段的主要作用是:
1.将字符转为十进制ascii码
2.将 asc_ 右移 i 得到 6 bit,因为这里不用手动计算二进制,它本身就得到了一个 0~63 的十进制数,将其作为 base64 表的下标索引得到第一个字符(i 的所有取值情况为 { 2, 4, 6 } ,这也是 bit 数组为 6 的原因)。
3.如果程序进行到当前分组的第一个字符,那么循环
for (unsigned k = 0u; k < i - 2; k++)
inx += (bit[k] & 1) << (8 + k - i);
将不会进行,否则,计算该分组前一个字符存储在 bit 中的对应的 i 位上的值(计算字符移除的 bit 代码在后面,因为每组的第一个字符不需要计算加上 bit 的结果)。时间复杂度 $ O(1) $
例如(该例来自wikipedia - Base64):
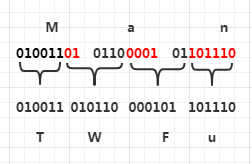
第一个字符右移出的2个bit(01)保存到bit数组,剩余的编码为 T 字符,扫描到字符 a 时,先将其值大小右移 4 位,变为 6(0110),将 bit 中的 2 个 bit 加到 0110 前面,也就是 010110,这里 bit 中的 1 的位为 4($ 1 \times 2^4 = 16 $ ),0的位为 5($ 0 \times 2^5 = 0 $ ), 可以根据 8 + k - i 来计算应该位移多少(注释中列举了可能情况)。
4.利用计算出的结果作为 base64 表的索引,取出对应的字符,并存储到 encode 栈中。
下一个片段:
if (i != 6) {
for (unsigned k = 0u, n = asc_; k < i; n >>= 1, k++)
bit[k] = n & 1;
i += 2;
}
当程序还在周期中进行时,程序就会进入到该片段,目的就是将当前字符后 i 个 bit 存储到 bit 数组中,以维护并填充下一个字符的前 i 个 bit。
否则执行片段:
else {
i = asc_;
inx = i >= 64 ? (i >= 128 ? i - 128 : i - 64) : i;
encode[ens++] = base64_table[inx];
if (inputs[j + 1] != '\0') i = 2;
}
当扫描到分组中第 3 个字符时,一个周期就结束了,因为 $ 4 \times 6 = 3 \times 8 $,所以,最后一个字符不需要位移,更准确的说,最后一个字符可以编码成两个字符,前 2 bit 结合前一个字符的后 4 bit,得到一个字符;后 6 bit 可以直接编码为一个字符。但如何将 8 bit 的前 2 个 bit 去掉呢?思考了一下,第7位二进制有效的最小的十进制值为64,第8位二进制有效的最小的十进制值为128,所以,就有了上面代码片段中第3行的代码,实际上,我们的输入是 ascii 字符集,不可能有大于等于 128 的情况,所以,可以写成:
inx = i >= 64 ? i - 64 : i;
然后将 inx 作为 base64 表的索引,取出字符并加入到 encode 栈顶。注意:inx 值是合法的,且一定不会导致越界发生。
最后如果下一个字符不是结束符,则将 i 重新置为 2,以开始新一轮的编码。当下一个字符为结束符时,i 的值一定大于 6(对于字母和数字的字符部分)。
核心部分基本就是这些了,但还有一些细节没处理。
对于上面的程序,当输入的字符串长度不能整除 3 时,最后一个字符的后面一部分一定会没有被编码出来,以及没有填充 "=" 来完成 base64 的编码规则。
所以,继续完善细节,见下面片段:
if (i <= 6)
{
unsigned inx = 0;
for (unsigned k = 0u; k < i - 2; k++)
inx += (bit[k] & 1) << (8 + k - i);
encode[ens++] = base64_table[inx];
} while (i <= 6) encode[ens++] = '=', i += 2;
前面的程序的结束情况一定在 if 之后就完成循环了,最后一个字符的 8 bit 后面 i 部分存入 bit 中的后,没有用上,于是,将其取出来后面全填充为 0 并计算出值即可,然后判断循环结束前执行到周期的第几个字符(一定是1或2),填充上"="。时间复杂度 $ O(1) $
于是,该算法的总时间复杂度为 $ O(n) $ ,n 为字符串长度。
最后
完整实现代码:
#include <iostream>
#include <cstdio>
#include <cstring> const char * base64_table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; class Base64Table {
int * amappi;
public:
Base64Table()
{
amappi = new int[128];
for (unsigned i = 0u; i < 64; i++)
amappi[base64_table[i]] = i;
}
~Base64Table()
{ delete[] amappi; }
unsigned operator[](char _c) const
{ return amappi[_c]; }
}; char * base64encode(char * encode, const char * inputs)
{
unsigned bit[6] = {0u};
size_t ens = 0, i = 2u; for (unsigned j = 0u; inputs[j]; j++)
{
int asc_ = int(inputs[j]);
unsigned inx = asc_ >> i;
for (unsigned k = 0u; k < i - 2; k++)
inx += (bit[k] & 1) << (8 + k - i); // min: 0, max:{1, 2, 4, 8, 16, 32}
encode[ens++] = base64_table[inx];
if (i != 6) {
for (unsigned k = 0u, n = asc_; k < i; n >>= 1, k++)
bit[k] = n & 1;
i += 2;
}
else {
i = asc_;
inx = i >= 64 ? i - 64 : i;
encode[ens++] = base64_table[inx];
if (inputs[j + 1] != '\0') i = 2;
}
} if (i <= 6)
{
unsigned inx = 0;
for (unsigned k = 0u; k < i - 2; k++)
inx += (bit[k] & 1) << (8 + k - i);
encode[ens++] = base64_table[inx];
} while (i <= 6) encode[ens++] = '=', i += 2; encode[ens] = 0; return encode;
} char * base64encode(char * encode, std::string inputs)
{
return base64encode(encode, inputs.c_str());
} char * base64decode(char * decode, const char * inputs)
{
unsigned f = 2u, des = 0, inx = 0;
Base64Table integer;
for (unsigned i = 3u, j = 0u; (inputs[j] != '\0') & (inputs[j] != '='); j++)
{
if (i != 3u) {
inx += integer[inputs[j]] >> (6 - f);
decode[des++] = char(inx);
i++, f += 2;
}
else i = 0u, f = 2u;
unsigned size_ = integer[inputs[j]];
for (unsigned k = 0u; k < f - 2; k++)
{
unsigned n_ = 1 << (8 - f + k);
if (size_ >= n_) size_ -= n_;
}
inx = size_ << f;
}
decode[des] = 0;
return decode;
} char * base64decode(char * decode, std::string inputs)
{
return base64decode(decode, inputs.c_str());
} int main(int argc, char* argv[])
{
if (argc <= 1)
{
std::cout << "usage:" << std::endl;
std::cout << " -e <input text>" << std::endl;
std::cout << " -d <input text>" << std::endl;
return 0;
}
if ( !strcmp(argv[1], "-e") )
{
std::string doc = argv[2];
int len = doc.size();
char* encode = new char[len * (4 / 3) + 1];
std::cout << base64encode(encode, argv[2]) << std::endl;
delete[] encode;
encode = nullptr;
}
else if (!strcmp(argv[1], "-d") ) {
std::string doc = argv[2];
int len = doc.size();
char* decode = new char[len];
std::cout << base64decode(decode, argv[2]) << std::endl;
delete[] decode;
decode = nullptr;
}
return 0;
}
测试一下(测试样本来自wikipedia - Base64)
encode:
base64 -e "Man is distinguished, not only by his reason, but by this singular passion from other animals, which is a lust of the mind, that by a perseverance of delight in the continued and indefatigable generation of knowledge, exceeds the short vehemence of any carnal pleasure."
Output:
TWFuIGlzIGRpc3Rpbmd1aXNoZWQsIG5vdCBvbmx5IGJ5IGhpcyByZWFzb24sIGJ1dCBieSB0aGlzIHNpbmd1bGFyIHBhc3Npb24gZnJvbSBvdGhlciBhbmltYWxzLCB3aGljaCBpcyBhIGx1c3Qgb2YgdGhlIG1pbmQsIHRoYXQgYnkgYSBwZXJzZXZlcmFuY2Ugb2YgZGVsaWdodCBpbiB0aGUgY29udGludWVkIGFuZCBpbmRlZmF0aWdhYmxlIGdlbmVyYXRpb24gb2Yga25vd2xlZGdlLCBleGNlZWRzIHRoZSBzaG9ydCB2ZWhlbWVuY2Ugb2YgYW55IGNhcm5hbCBwbGVhc3VyZS4=
decode:
base64 -d "TWFuIGlzIGRpc3Rpbmd1aXNoZWQsIG5vdCBvbmx5IGJ5IGhpcyByZWFzb24sIGJ1dCBieSB0aGlzIHNpbmd1bGFyIHBhc3Npb24gZnJvbSBvdGhlciBhbmltYWxzLCB3aGljaCBpcyBhIGx1c3Qgb2YgdGhlIG1pbmQsIHRoYXQgYnkgYSBwZXJzZXZlcmFuY2Ugb2YgZGVsaWdodCBpbiB0aGUgY29udGludWVkIGFuZCBpbmRlZmF0aWdhYmxlIGdlbmVyYXRpb24gb2Yga25vd2xlZGdlLCBleGNlZWRzIHRoZSBzaG9ydCB2ZWhlbWVuY2Ugb2YgYW55IGNhcm5hbCBwbGVhc3VyZS4="
Output:
Man is distinguished, not only by his reason, but by this singular passion from other animals, which is a lust of the mind, that by a perseverance of delight in the continued and indefatigable generation of knowledge, exceeds the short vehemence of any carnal pleasure.
base64加/解密算法C++实现的更多相关文章
- MFC BASE64加解密 算法
unsigned char * base64 = (unsigned char *)"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz ...
- java base64加解密
接上篇java Base64算法. 根据之前过程使用base64加解密,所以写成了工具类. 代码示例; public class Base64Util { private static Logger ...
- 3des加解密算法
编号:1003时间:2016年4月1日09:51:11功能:openssl_3des加解密算法http://blog.csdn.net/alonesword/article/details/17385 ...
- QQ协议的TEA加解密算法
QQ通讯协议里的加解密算法. #include <stdio.h> #include <stdlib.h> #include <memory.h> #include ...
- DES加解密算法Qt实现
算法解密qt加密table64bit [声明] (1) 本文源码 大部分源码来自:DES算法代码.在此基础上,利用Qt编程进行了改写,实现了DES加解密算法,并添加了文件加解密功能.在此对署名为b ...
- AES加解密算法Qt实现
[声明] (1) 本文源码 在一位未署名网友源码基础上,利用Qt编程,实现了AES加解密算法,并添加了文件加解密功能.在此表示感谢!该源码仅供学习交流,请勿用于商业目的. (2) 图片及描述 除图1外 ...
- C#加解密算法
先附上源码 加密解密算法目前已经应用到我们生活中的各个方面 加密用于达到以下目的: 保密性:帮助保护用户的标识或数据不被读取. 数据完整性:帮助保护数据不被更改. 身份验证:确保数据发自特定的一方. ...
- AES加解密算法在Android中的应用及Android4.2以上版本调用问题
from://http://blog.csdn.net/xinzheng_wang/article/details/9159969 AES加解密算法在Android中的应用及Android4.2以上 ...
- [转]RSA,DSA等加解密算法介绍
From : http://blog.sina.com.cn/s/blog_a9303fd90101cgw4.html 1) MD5/SHA MessageDigest是一个数据的数字指纹. ...
随机推荐
- 虚拟磁盘VHD文件压缩方法
问题描述 因工作需要在Mac上跑了一个VirtualBox虚拟win7,使用对win系统友好的vhd格式作为虚拟硬盘.经过一段时间使用发现vhd占用空间远大于虚拟磁盘使用量,想办法减减肥才行. 步骤整 ...
- opencv 实现人脸检测(harr特征)
我这里用的是已经训练好的haar级联分类器. 眼睛检测 haarcascade_eye_tree_eyeglasses.xml 人脸检测 haarcascade_frontalface_alt2.xm ...
- zabbix4.2配置监控MySQL
1.在被监控主机安装好MySQL 相关步骤省略. 2.创建监控所需要的MySQL账户(MySQL服务器端) MariaDB [(none)]>grant usage on *.* to zabb ...
- js清空子节点
删除全部子节点 function removeAllChild(){ var div = document.getElementById("div1"); while(div.ha ...
- DM9000C网卡驱动程序编写与测试
一般网卡驱动程序厂商会给我们提供一份模板驱动,我们的工作就是需要根据自己的需要更改这个模板驱动 1.DM9000C的硬件连接 硬件连接图如下所示:它接在S3C2440的BANK4内存控制器上,它只占用 ...
- RFC3984: RTP Payload Format for H.264 Video(中文版)
转载地址:https://blog.csdn.net/h514434485/article/details/51010950 官方文档,中文版本地址:http://www.rosoo.net/File ...
- Python之路【第三十二篇】:django 分页器
Django的分页器paginator 文件为pageDemo models.py from django.db import models # Create your models here. cl ...
- Java之字符串输入next()与nextLine()
next():一定要读取到有效字符后才可以结束输入,对输入有效字符之前遇到的空格键.Tab键或Enter键等结束符,next()方法会自动将其去掉: 只有在输入有效字符之后,next( ...
- Ninject 2.x细说---1.基本使用
Ninject 2.x细说---1.基本使用 https://blog.csdn.net/weixin_33809981/article/details/86091159 本来想使用一下Ninje ...
- Java-POJ1006-Biorhythms(中国剩余定理)
https://blog.csdn.net/shanshanpt/article/details/8724769 有中文题面,就不解释了. 妥妥的中国剩余定理没跑了. Java跑得慢,一点办法也没有, ...