ElasticSearch集群-Windows
概述
ES集群是一个P2类型的分布式系统,除了集群状态管理以外,其他所有的请求都可以发送到集群内任意一台节点上,这个节点可以自己找到需要转发给哪些节点,并且直接跟这些节点通信。所以,从网络架构及服务配置上来说,构建集群需要的配置及其简单。在Elasticsearch2.0之前,无阻碍的网络下,所有配置了相同cluster.name的节点都自动归属到一个集群中。2.0版本之后,基于安全的考虑避免开发环境过于随便造成的麻烦,从2.0版本开始,默认的自动发现方式改为了单播(unicast)方式。配置里提供几台节点的地址,ES将其视作gossip router角色,借以完成集群的发现。由于这只是ES内一个很小的功能,所以gossip router角色并不需要单独配置,每个ES节点都可以担任。所以,采用单播方式的集群,各节点都配置相同的几个节点列表作为router即可。
集群中节点数量没有限制,一般大于等于2个节点就可以看做是集群了。一般处于高性能及高可用方面来考虑一般集群中的节点数量都是3个及3个以上。
集群的相关概念
1.集群cluster
一个集群就是由一个或多个节点组织一起,它们共同有整个的数据,并一起提供索引和搜索功能。一个集群有一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
2.节点node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确认网络中的哪些服务器对应于elasticsearch集群中的哪些节点;
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中;
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何elasticsearch节点,这是启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
3.分片和复制 shards&replicas
集群的搭建
1.准备三台elasticsearch服务器
2.修改每台服务器配置
node1节点:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-
#必须为本机的ip地址
network.host: 127.0.0.1
#服务器端口号,在同一机器下必须不一样
http.port:
#集群间通讯的端口号,同一机器下必须不一样
transport.tcp.port:
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"] http.cors.enabled: true
http.cors.allow-origin: "*"
node2节点:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-
#必须为本机的ip地址
network.host: 127.0.0.1
#服务器端口号,在同一机器下必须不一样
http.port:
#集群间通信端口号,同一机器下必须不一样
transport.tcp.port: 9301
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"] http.cors.enabled: true
http.cors.allow-origin: "*"
node3节点:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-#本机的ip地址
network.host: 127.0.0.1
#服务器端口号
http.port:
#集群间通信端口号
transport.tcp.port: #设置集群自动发现机器的ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"] http.cors.enabled: true
http.cors.allow-origin: "*"
注意:如果你是复制以前使用过的elasticsearch,需要将三个集群的【data】文件夹分别删除,否则会有异常;
3.分别启动三个集群的服务器elasticsearch.bat
使用如下地址查看集群的状态
http://127.0.0.1:9200/_cat/nodes?v

4.启动elasticsearch-head-master服务
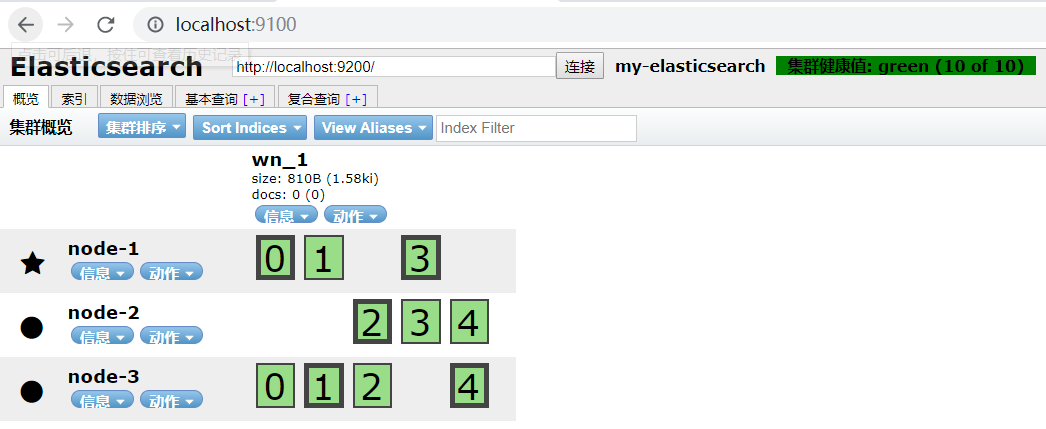
5.添加索引和映射
5.1 请求的url (请求方式PUT)
http://localhost:9200/wn_1
5.2 请求体
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"store": true,
"index":"not_analyzed"
},
"title": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"ik_max_word"
},
"content": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"ik_max_word"
}
}
}
}
}
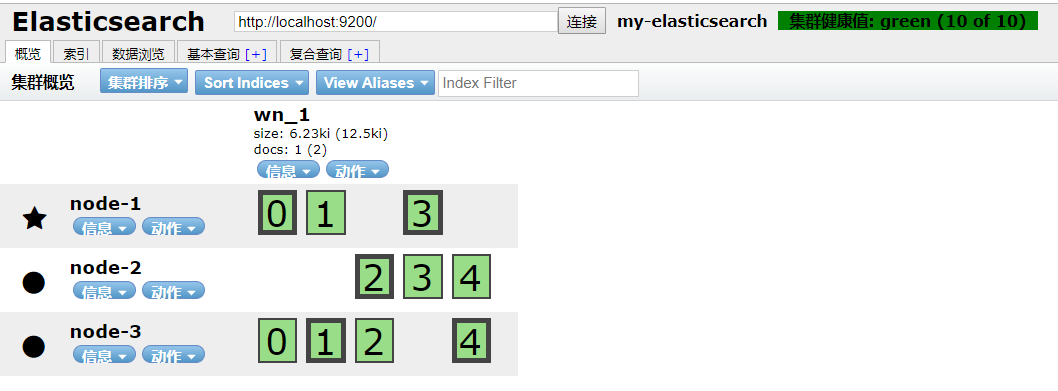
5.3 效果实现
6.添加文档
6.1 请求的url(请求方式post)
http://localhost:9200/wn_1/article/1
6.2 请求体
{
"id":,
"title":"ElasticSearch是一个基于Lucene的搜索服务器",
"content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTfulweb接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。"
}
6.3 效果实现

ElasticSearch集群-Windows的更多相关文章
- ES2:ElasticSearch 集群配置
ElasticSearch共有两个配置文件,都位于config目录下,分别是elasticsearch.yml和logging.yml,其中,elasticsearch.yml 用来配置Elastic ...
- Elasticsearch集群 管理
第7章 深入Elasticsearch集群 启动一个Elasticsearch节点时,该节点会开始寻找具有相同集群名字并且可见的主节点.如 果找到主节点,该节点加入一个已经组成了的集群:如果没有找到, ...
- 【Elasticsearch】深入Elasticsearch集群
7.1 节点发现启动Elasticsearch的时候,该节点会寻找有相同集群名字且课件的主节点,如果有加入,没有自己成为主节点,负责发现的模块两个目的 选出主节点以及发现集群的新节点7.1.1发现的类 ...
- ElasticSearch实战系列一: ElasticSearch集群+Kinaba安装教程
前言 本文主要介绍的是ElasticSearch集群和kinaba的安装教程. ElasticSearch介绍 ElasticSearch是一个基于Lucene的搜索服务器,其实就是对Lucene进行 ...
- Elasticsearch集群搭建教程及生产环境配置
Elasticsearch 是一个极其强大的搜索和分析引擎,其强大的部分在于能够对其进行扩展以获得更好的性能和稳定性. 本教程将提供有关如何设置 Elasticsearch 集群的一些信息,并将添加一 ...
- Ubuntu 14.04中Elasticsearch集群配置
Ubuntu 14.04中Elasticsearch集群配置 前言:本文可用于elasticsearch集群搭建参考.细分为elasticsearch.yml配置和系统配置 达到的目的:各台机器配置成 ...
- elasticsearch 集群
elasticsearch 集群 搭建elasticsearch的集群 现在假设我们有3台es机器,想要把他们搭建成为一个集群 基本配置 每个节点都要进行这样的配置: cluster.name: ba ...
- 我的ElasticSearch集群部署总结--大数据搜索引擎你不得不知
摘要:世上有三类书籍:1.介绍知识,2.阐述理论,3.工具书:世间也存在两类知识:1.技术,2.思想.以下是我在部署ElasticSearch集群时的经验总结,它们大体属于第一类知识“techknow ...
- Elasticsearch集群中处理大型日志流的几个常用概念
之前对于CDN的日志处理模型是从logstash agent==>>redis==>>logstash index==>>elasticsearch==>&g ...
随机推荐
- 使用RobotFramework的DataBaseLibrary(Java实现)
RobotFramework能用Python和Jython两条腿走路.但有的时候你得选一条.今天就碰上个问题,为了整合其它模块必须用Java实现的DataBaseLibrary 其实实它很简单,记录步 ...
- Codeforces Round #615 (Div. 3) 题解
A - Collecting Coins 题意: 给你四个数a,b,c,d,n.问你是否能将n拆成三个数A,B,C,使得A+a=B+b=C+c. 思路: 先计算三个数的差值的绝对值abs,如果abs大 ...
- Nito.AsyncEx 这个库
有一个非常聪明的小伙子 (我高度赞扬) 叫 Stephen Cleary ,他写了一个很棒的 Extension 集,共同参与开发的还有 Stephen Toub (他显然是经验丰富的),所以我充分信 ...
- 关于 C#和.net 的 发展
591. C# 1 的 委托 语法 看起来 似乎 并不 太坏 [2016-04-27 09:00:56]592. C# 2 支持 从 方法 组 到 一个 兼容 委托 类型 的 隐式 转换. [2016 ...
- 使用Rclone和WinFsp挂载FTP为磁盘
介绍 Rclone:是一款的命令行工具,支持在不同对象存储.网盘间同步.上传.下载数据.官网网址:rclone.org WinFsp:是一款Windows平台下的文件系统代理软件(Windows Fi ...
- git hub安装
windows下GitHub的安装.配置以及项目的上传过程详细介绍 阅读目录 概要 操作必备 GitHub的安装 Git的初始配置 本地Git与远程GitHub连接的建立 将本地项目上传到GitHub ...
- oc---instancetype和id的异同
[instancetype和id的异同] 相同点:都可以作为方法的返回类型. 不同点: (1)instancetype可以返回方法所在类相同类型的对象,id只能返回未知类型的对象: (2)instan ...
- Java 设计模式之工厂模式
工厂模式(Factory Pattern)是 Java 中最常用的设计模式之一.这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式. 在工厂模式中,我们在创建对象时不会对客户端暴露创建逻 ...
- Matlab 与 c++对txt 文档的读写格式
学习g++能够读取什么格式的txt文件. 读基本指令: >sprintf(filename, "doc_%d.txt", d); >fileptr = fopen(fi ...
- Java 加密/解密Excel
概述 设置excel文件保护时,通常可选择对整个工作簿进行加密保护,打开文件时需要输入密码:或者对指定工作表进行加密,即设置表格内容只读,无法对工作表进行编辑.另外,也可以对工作表特定区域设置保护,即 ...