pytorch --Rnn语言模型(LSTM,BiLSTM) -- 《Recurrent neural network based language model》
论文通过实现RNN来完成了文本分类。
论文地址:88888888
模型结构图:
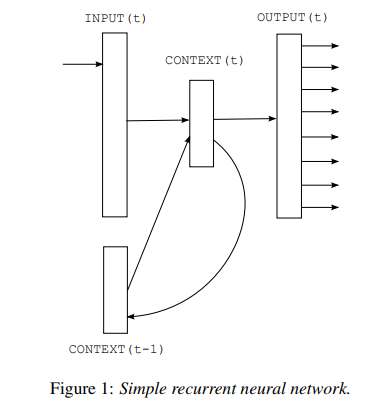
原理自行参考论文,code and comment(https://github.com/graykode/nlp-tutorial):
# -*- coding: utf-8 -*-
# @time : 2019/11/9 15:12 import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable dtype = torch.FloatTensor sentences = [ "i like dog", "i love coffee", "i hate milk"] word_list = " ".join(sentences).split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict) # TextRNN Parameter
batch_size = len(sentences)
n_step = 2 # number of cells(= number of Step)
n_hidden = 5 # number of hidden units in one cell def make_batch(sentences):
input_batch = []
target_batch = [] for sen in sentences:
word = sen.split()
input = [word_dict[n] for n in word[:-1]]
target = word_dict[word[-1]] input_batch.append(np.eye(n_class)[input])
target_batch.append(target) return input_batch, target_batch # to Torch.Tensor
input_batch, target_batch = make_batch(sentences)
input_batch = Variable(torch.Tensor(input_batch))
target_batch = Variable(torch.LongTensor(target_batch)) class TextRNN(nn.Module):
def __init__(self):
super(TextRNN, self).__init__() self.rnn = nn.RNN(input_size=n_class, hidden_size=n_hidden,batch_first=True)
self.W = nn.Parameter(torch.randn([n_hidden, n_class]).type(dtype))
self.b = nn.Parameter(torch.randn([n_class]).type(dtype)) def forward(self, hidden, X):
if self.rnn.batch_first == True:
# X [batch_size,time_step,word_vector]
outputs, hidden = self.rnn(X, hidden) # outputs [batch_size, time_step, hidden_size*num_directions]
output = outputs[:, -1, :] # [batch_size, num_directions(=1) * n_hidden]
model = torch.mm(output, self.W) + self.b # model : [batch_size, n_class]
return model
else:
X = X.transpose(0, 1) # X : [n_step, batch_size, n_class]
outputs, hidden = self.rnn(X, hidden)
# outputs : [n_step, batch_size, num_directions(=1) * n_hidden]
# hidden : [num_layers(=1) * num_directions(=1), batch_size, n_hidden] output = outputs[-1,:,:] # [batch_size, num_directions(=1) * n_hidden]
model = torch.mm(output, self.W) + self.b # model : [batch_size, n_class]
return model model = TextRNN() criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001) # Training
for epoch in range(5000):
optimizer.zero_grad() # hidden : [num_layers * num_directions, batch, hidden_size]
hidden = Variable(torch.zeros(1, batch_size, n_hidden))
# input_batch : [batch_size, n_step, n_class]
output = model(hidden, input_batch) # output : [batch_size, n_class], target_batch : [batch_size] (LongTensor, not one-hot)
loss = criterion(output, target_batch)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss)) loss.backward()
optimizer.step() # Predict
hidden_initial = Variable(torch.zeros(1, batch_size, n_hidden))
predict = model(hidden_initial, input_batch).data.max(1, keepdim=True)[1]
print([sen.split()[:2] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
LSTM unit的RNN模型:
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable dtype = torch.FloatTensor char_arr = [c for c in 'abcdefghijklmnopqrstuvwxyz']
word_dict = {n: i for i, n in enumerate(char_arr)}
number_dict = {i: w for i, w in enumerate(char_arr)}
n_class = len(word_dict) # number of class(=number of vocab) seq_data = ['make', 'need', 'coal', 'word', 'love', 'hate', 'live', 'home', 'hash', 'star'] # TextLSTM Parameters
n_step = 3
n_hidden = 128 def make_batch(seq_data):
input_batch, target_batch = [], [] for seq in seq_data:
input = [word_dict[n] for n in seq[:-1]] # 'm', 'a' , 'k' is input
target = word_dict[seq[-1]] # 'e' is target
input_batch.append(np.eye(n_class)[input])
target_batch.append(target) return Variable(torch.Tensor(input_batch)), Variable(torch.LongTensor(target_batch)) class TextLSTM(nn.Module):
def __init__(self):
super(TextLSTM, self).__init__() self.lstm = nn.LSTM(input_size=n_class, hidden_size=n_hidden)
self.W = nn.Parameter(torch.randn([n_hidden, n_class]).type(dtype))
self.b = nn.Parameter(torch.randn([n_class]).type(dtype)) def forward(self, X):
input = X.transpose(0, 1) # X : [n_step, batch_size, n_class] hidden_state = Variable(
torch.zeros(1, len(X), n_hidden)) # [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
cell_state = Variable(
torch.zeros(1, len(X), n_hidden)) # [num_layers(=1) * num_directions(=1), batch_size, n_hidden] outputs, (_, _) = self.lstm(input, (hidden_state, cell_state))
outputs = outputs[-1] # [batch_size, n_hidden]
model = torch.mm(outputs, self.W) + self.b # model : [batch_size, n_class]
return model input_batch, target_batch = make_batch(seq_data) model = TextLSTM() criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001) # Training
for epoch in range(1000): output = model(input_batch)
loss = criterion(output, target_batch)
if (epoch + 1) % 100 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step() inputs = [sen[:3] for sen in seq_data] predict = model(input_batch).data.max(1, keepdim=True)[1]
print(inputs, '->', [number_dict[n.item()] for n in predict.squeeze()])
BiLSTM RNN model:
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import torch.nn.functional as F dtype = torch.FloatTensor sentence = (
'Lorem ipsum dolor sit amet consectetur adipisicing elit '
'sed do eiusmod tempor incididunt ut labore et dolore magna '
'aliqua Ut enim ad minim veniam quis nostrud exercitation'
) word_dict = {w: i for i, w in enumerate(list(set(sentence.split())))}
number_dict = {i: w for i, w in enumerate(list(set(sentence.split())))}
n_class = len(word_dict)
max_len = len(sentence.split())
n_hidden = 5 def make_batch(sentence):
input_batch = []
target_batch = [] words = sentence.split()
for i, word in enumerate(words[:-1]):
input = [word_dict[n] for n in words[:(i + 1)]]
input = input + [0] * (max_len - len(input))
target = word_dict[words[i + 1]]
input_batch.append(np.eye(n_class)[input])
target_batch.append(target) return Variable(torch.Tensor(input_batch)), Variable(torch.LongTensor(target_batch)) class BiLSTM(nn.Module):
def __init__(self):
super(BiLSTM, self).__init__() self.lstm = nn.LSTM(input_size=n_class, hidden_size=n_hidden, bidirectional=True)
self.W = nn.Parameter(torch.randn([n_hidden * 2, n_class]).type(dtype))
self.b = nn.Parameter(torch.randn([n_class]).type(dtype)) def forward(self, X):
input = X.transpose(0, 1) # input : [n_step, batch_size, n_class] hidden_state = Variable(torch.zeros(1*2, len(X), n_hidden)) # [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
cell_state = Variable(torch.zeros(1*2, len(X), n_hidden)) # [num_layers(=1) * num_directions(=1), batch_size, n_hidden] outputs, (_, _) = self.lstm(input, (hidden_state, cell_state))
outputs = outputs[-1] # [batch_size, n_hidden]
model = torch.mm(outputs, self.W) + self.b # model : [batch_size, n_class]
return model input_batch, target_batch = make_batch(sentence) model = BiLSTM() criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001) # Training
for epoch in range(10000):
output = model(input_batch)
loss = criterion(output, target_batch)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss)) optimizer.zero_grad()
loss.backward()
optimizer.step() predict = model(input_batch).data.max(1, keepdim=True)[1]
print(sentence)
print([number_dict[n.item()] for n in predict.squeeze()])
pytorch --Rnn语言模型(LSTM,BiLSTM) -- 《Recurrent neural network based language model》的更多相关文章
- 4.5 RNN循环神经网络(recurrent neural network)
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取: https://www.cnblogs.com/bclshuai/p/11380657.html 1.1 RNN循环神经网络 ...
- 论文笔记:ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks
ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks2018-03-05 11:13:05 ...
- 【NLP】Recurrent Neural Network and Language Models
0. Overview What is language models? A time series prediction problem. It assigns a probility to a s ...
- RNN循环神经网络(Recurrent Neural Network)学习
一.RNN简介 1.)什么是RNN? RNN是一种特殊的神经网络结构,考虑前一时刻的输入,且赋予了网络对前面的内容的一种'记忆'功能. 2.)RNN可以解决什么问题? 时间先后顺序的问题都可以使用RN ...
- Recurrent Neural Network系列1--RNN(循环神经网络)概述
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- (zhuan) Recurrent Neural Network
Recurrent Neural Network 2016年07月01日 Deep learning Deep learning 字数:24235 this blog from: http:/ ...
- Recurrent neural network (RNN) - Pytorch版
import torch import torch.nn as nn import torchvision import torchvision.transforms as transforms # ...
- Recurrent Neural Network系列2--利用Python,Theano实现RNN
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- Recurrent Neural Network系列4--利用Python,Theano实现GRU或LSTM
yi作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORK ...
随机推荐
- java 字典 map 和 list.forEach
1.keySet key 集 2.values value 集(为何不叫valueSet)... 3.entrySet key value 集 List<?> 循环 1.Iterable ...
- docker使用阿里云加速器
1 登录阿里云获得地址 登录https://cr.console.aliyun.com ,点击"镜像加速器",会给我一个地址. 2 写入/etc/docker/daemon.jso ...
- java面试题-集合类
准备年后要跳槽,所以最近一直再看面试题,并且把收集到的面试题整理了以下发到博客上,希望对大家有所帮助. 首先是集合类的面试题 1. HashMap 排序题,上机题. 已知一个 HashMap< ...
- 一个按键搞定日常git操作
Git is a free and open source distributed version control system designed to handle everything from ...
- hdu4417 主席树求区间小于等于K
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4417 Problem Description Mario is world-famous plum ...
- 基于AOP和ThreadLocal实现的一个简单Http API日志记录模块
Log4a 基于AOP和ThreadLocal实现的一个简单Http API日志记录模块 github地址 : https://github.com/EalenXie/log4a 在API每次被请求时 ...
- unbuntu18.04安装启用splash
官网:https://splash.readthedocs.io/en/stable/ 1.安装Docker https://www.cnblogs.com/wt7018/p/11880666.htm ...
- 跨源请求cors和jsonp
0.产生跨域的原因 浏览器的同源策略 什么是浏览器的同源策略? src开发 ajax禁止 解决方法 jsonp 通过src绕过浏览器的同源策略 缺点:只发送GET请求 cors 通过设置相应头 分类 ...
- Java单体应用 - 开发工具 - 01.IntelliJ IDEA
原文地址:http://www.work100.net/training/monolithic-tools-intellij-idea.html 更多教程:光束云 - 免费课程 IntelliJ ID ...
- Redis(四):del/unlink 命令源码解析
上一篇文章从根本上理解了set/get的处理过程,相当于理解了 增.改.查的过程,现在就差一个删了.本篇我们来看一下删除过程. 对于客户端来说,删除操作无需区分何种数据类型,只管进行 del 操作即可 ...