消息队列MQ(一)
消息队列
为什么要用消息队列,都有什么优缺点?
要问的是消息队列都有哪些场景,然后项目里具体实现的什么场景,你在这个场景里用的什么消息队列?
期望的回答是,你们公司有个什么业务,这个业务场景有什么技术挑战,如果不用MQ可能会很麻烦,但是你现在用了MQ带给你什么好处?
场景比较多,但是比较核心的是3个:解耦、异步、削峰
解耦
需要去考虑你负责的系统中是否有类似的场景,一个系统调用了多个系统和模块,互相之间的调用很复杂,维护起来很麻烦。但是这个调用并不需要直接同步调用接口,如果用MQ给它异步化解耦,也是可以的,你就需要 考虑在你的项目中,是不是可以运用这个MQ去进行解耦。在简历中体现出来
异步化
异步化可以大幅度提升高延迟接口的性能
削锋:
未使用MQ的时候: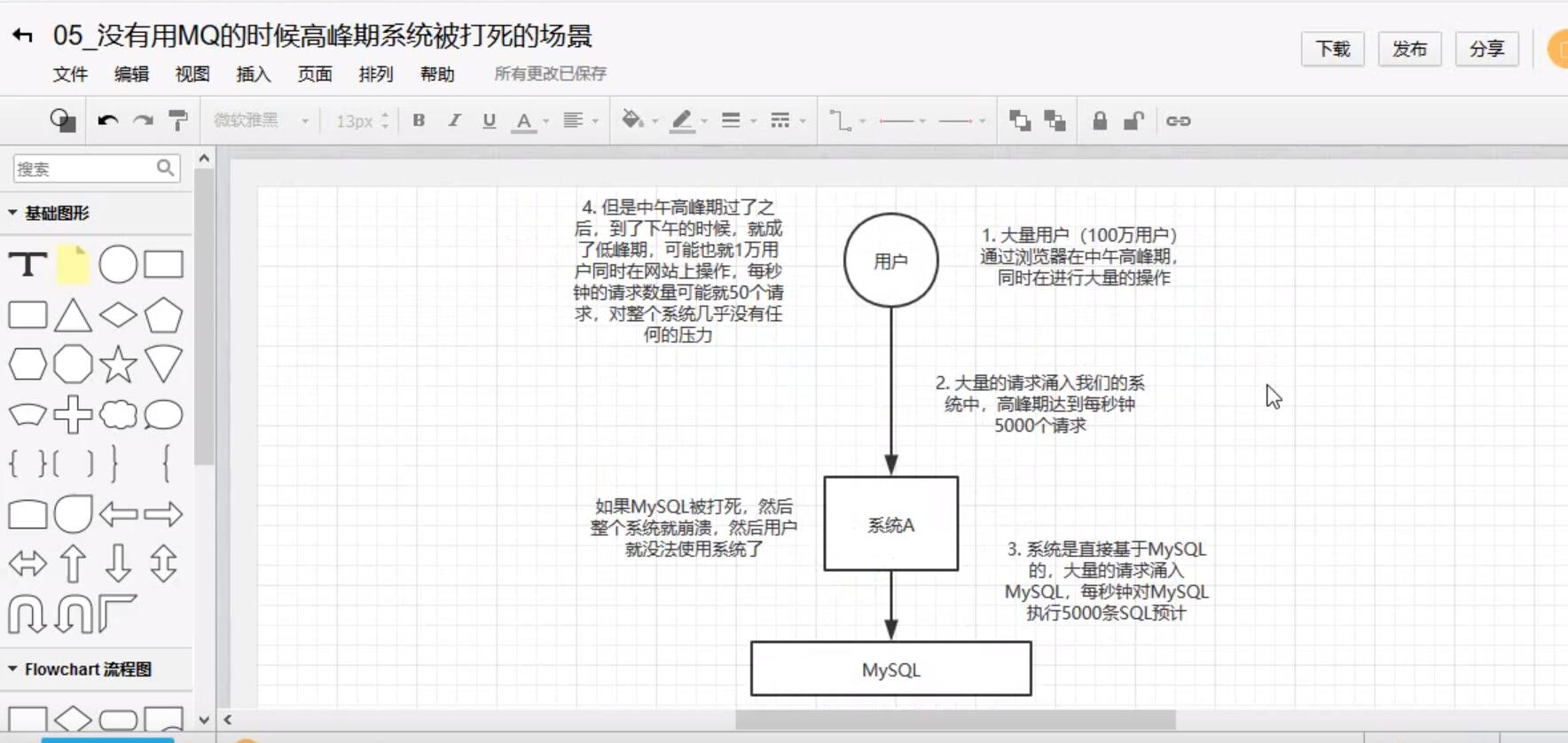

使用MQ以后:

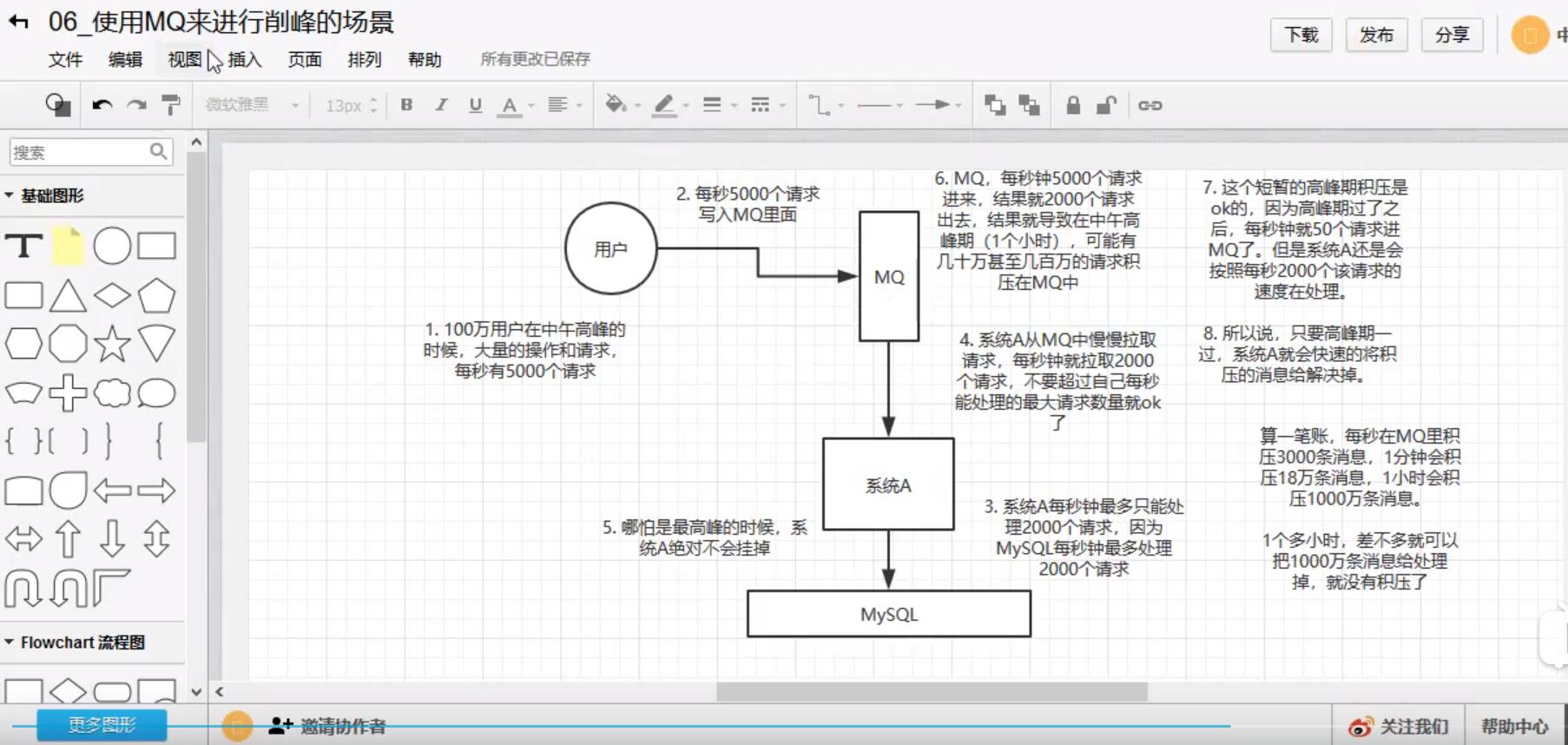
系统架构中引入MQ后可能存在的缺陷:
系统可用性降低:系统引入的外部依赖越多,越容易挂掉。
系统的复杂性更高:需要考虑的问题越多
一致性问题

问题2:kafka,activeMq,rabbitMq,rocketMq 都有什么优缺点?
| 特性 | ACTIVEMQ | RABBITMQ | ROCKETMQ | KAFKA |
|---|---|---|---|---|
| 单击吞吐量 | 万级吞吐量,相比RocketMq和Kafka要第一个数量级 | 万级,吞吐量相比RocketMq和 Kafka要低一个数量级 | 10万级,RocketMq也是可以支撑高吞吐的一种MQ | 10万级别,吞吐量高,一般是配合大数据系统来进行实时的数据计算,日志采集等场景。 |
| 时效性 | ms级 | 微妙级,这是RabbitMq的一大特点,延时是最低的 | ms级 | ms级别以内 |
| 可用性 | 高,基于主从架构实现高可用性 | 高,基于主从架构实现高可用性 | 非常高,分布式架构 | 分布式,比较高,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失消息 | 经过参数优化配置,可以做到0丢失 | 经过参数优化配置,可以做到0丢失 | |
| 功能支持 | MQ领域的功能极其完备 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低 | MQ的功能比较完备的,开始分布式的,扩展性比较好 | 功能较为简单,主要支持简单的MQ的功能,在大数据领域的实时计算和日志采集都支持的比较好 |
| 优劣势总结 | 非常成熟,业内大量的公司在使用;<br />偶尔会丢失消息,官方维护的比较少了<br />而且主要是基于解耦和异步来用的,较少在大规模吞吐的场景中使用 | 基于erlang开发,所以并发能力很强,延时很低;MQ功能比较完备。而且开源版本提供的管理界面非常棒,用起来好用。 社区相对比较活跃,几乎每个月都要发布几个版本,但是吞吐量只有几万,比较低,而且erlang开发,国内没有几个公司做erlang级别的源码级别的研究和定制;很难去看懂源码,公司对这个中间件的掌控能力比较多,只能依靠开源社区的版本迭代 | API简单易用,而且是阿里开源项目,质量还是可以肯定的。日处理消息可以达上百亿之多,可以做大规模吞吐,分布式扩展也方便,社 区维护开可以,由于是java开发的,所以可以方便的阅读源码,定制自己公司的mq. | |
| TOPIC数量对吞吐量的影响 | topic可以达到几百,几千个级别,吞吐量有较小幅度的降低 | topic可以达到几百,几千个级别,吞吐量有较小幅度的降低 |
如何保证消息队列的高可用?
问的是你用的哪种MQ,是如何保证高可用的?
RabbitMQ的高可用性
RabbitMQ是比较有代表性的,因为主要是基于主从做高可用的,我们就以他为例讲第一种MQ的高可用性的具体实现
单击模式
就是Demo级别的,一般是本地启动体验一下
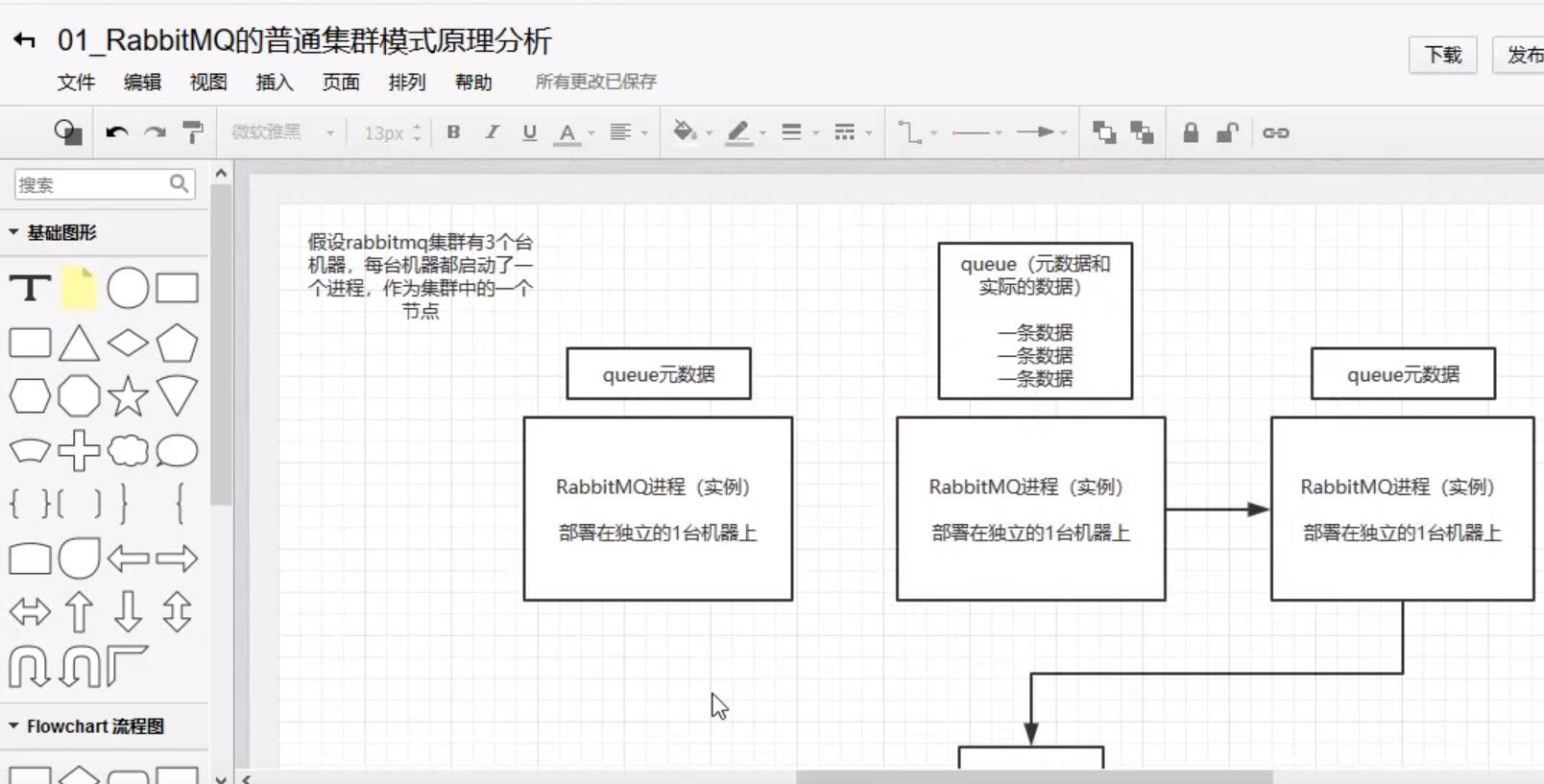
普通集群模式
多台机器启动多个rabbitMq实例,每个机器启动一个,但是你创建的queue只会放在一个rabbitmq实例上,但是每个实例同步queue的元数据,完了你消费完以后,实际上如果你连接到另外一个实例, 那么这个实例会从queue所在实例上拉取数据过来。
缺点:可能会在rabbitMq集群内部产生大量的数据传输
可用性几乎没有什么保障,如果queue所在实例的节点的机器宕机了,整个消息队列都不可用
图解:

3.镜像集群模式
这个才是rabbit高可用的解决方案,创建的queue,无论元数据还是queue里的消息都会存在与多个实例中,然后每次写消息到queue中时,都会自动把消息放到多个实例的queue中进行数据同步。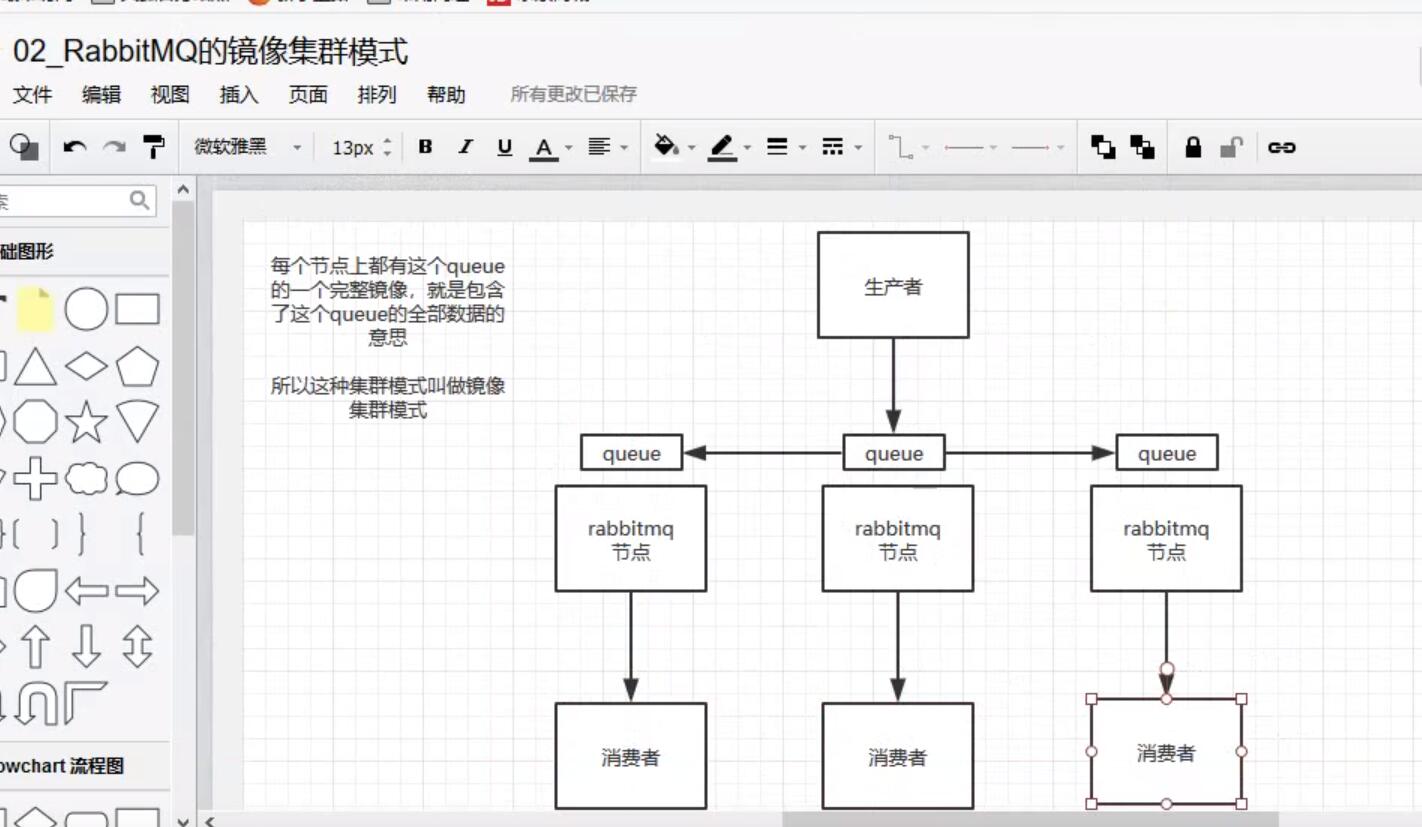

如何开启镜像策略:
在rabbitMq有一个管理控制台,在后台新增一个策略,这个策略就是镜像集群模式的策略,指定的时候可以要求数据同步到所有节点,也可以要求同步到指定数量的节点,然后再次创建queue时,应用这个策略,就会自动同步数据到其他节点上
4.kafka的高可用性:
一个最基本的架构认识,多个broker组成,每个broker是一个节点,创建一个topic,这个topic可以划分为多个partition,每个partition可以存在与不同的broker上,每个partiton就放一部分数据。
kafka是一个天然的分布式的消息队列,就是说一个topic的数据分布在多个机器上面,每个机器就放一部分数据

如何保证消息不被重复消费?如何保证消费的时候是幂等?

幂等性:
一条数据或者一个请求,给你重复来多次,你得确保对应的数据是不会改变的,不能出错

如何保证幂等呢?
一条数据重复出现了两次,数据库里只有一条数据,这就保证了系统的幂等性
(1) 比如拿到数据要入库,你先根据主键查一下,如果这个数据有了,就别再插入了,update一下就好
(2) 比如是写redis,那就没问题,因为是set,天然幂等的。
(3) 如果不是以上所述的场景,你需要让生产者发送数据的时候,添加一个全局唯一的ID,然后到了消费者的时候,现根据id去排查,之前是否消费过? 如果没有就处理,然后这个ID 写入到map或者redis中;如果消费过了,那就别处理了,保障消息不被重复处理即可;
如何保证消息的可靠性传输?要是消息丢了怎么办?
1).生产者弄丢数据
生产者将数据发送到rabbitmq的时候,可能数据就在半路给弄丢了,因为网络原因,都用可能
此时可以选择用rabbitmq提供的事务功能,就是生产者发送数据之前开启rabbitMQ事务(channel.txSelect)
,然后发送消息,如果消息没有成功被rabbitmq接收到,那么生产者会收到异常报错,此时就可以回滚事务(channel.txRollback),然后尝试重发消息;如果收到消息,那么可以提交事务(channel.txCommit).但是问题是,rabbitMQ事务机制一搞,吞吐量就会下来,因为太耗性能。

2).MQ自己弄丢了数据
对于rabbitMQ,可以开启持久化,写入的消息以后会持久化到磁盘里,哪怕是mq自己挂了,恢复之后会自动读取之前存储的数据;
设置持久化有两个步骤:
创建queue的时候将其设置为持久化,这样就可以保证rabbitmq持久化queue的元数据,但是不会持久化queue里面的数据;
发送消息的时候将消息 deliveryMode 设置为2,就是将消息设置为持久化,此时,rabbitMQ就会将消息持久化到磁盘里。 因此必须要同时设置这两个持久化才行
总结: 生产者处的方案:开启confirm模式,通过回调接口来得知是否成功发送到MQ
MQ内部的方案: 通过持久化到磁盘的方式,避免机器宕机导致内存中的数据丢失
消费者处的方案: 关闭 autoAck ,当消费者消费并处理完后手动进行ACK
3).Kafka
kafka消费者端丢失数据
唯一可能导致消费者端丢失数据的情况,在消费到这个消息的时候,消费者那边自动提交了ofttset,让kafka以为你已经消费了这个消息;其实刚准备处理消息,还没处理完 ,就已经挂了,此时这条消息就已经丢了。
因为kafka会自动提交offset,那么只要关闭自动提交offset,在处理玩以后再提交,就能够避免这一类问题
kafka自己丢失数据
即kafka某个broker所在的机器宕机了,然后重新选partition的leader时,要是此时其他的follower还没同步完数据,leader挂了,就造成数据的丢失。
一般要求有如下设置步骤:
给这个topic 设置 replication.factor参数 ,这个数值必须大于1,要求每个partition至少有2个副本
在kafka服务端设置 min.insync.replicas参数,这个数值必须大于1,这个要求一个leader至少感知到至少一个follower还跟自己保持联系,这样才能保证leader挂了以后还有一个follower。
在producer端设置 acks=null : 这个要求生产者在写消息,必须写入leader,而且同步到所有的follower之后,生产者才会认为这条消息已经写入了kafka中 ;
在procuduer端设置 retries=max(很大很大的值):这个要求一旦写入失败,就无限重试,卡在这里
生产者会不会丢失数据
如果按照上面的思路设置 acks=null,一定不会丢失,因为leader收到消息后,要同步数据到所有的follower后,才认为本次写入消息成功,否则生产者会不断重试写入,无限重试。
如何保证消息的顺序性?
先看看顺序出错的场景
rabbitMQ:一个queue,多个consumer;这就明显乱了
kafka: 一个topic,一个partition,一个consumer,多个线程去并发处理,就可能产生顺序错乱
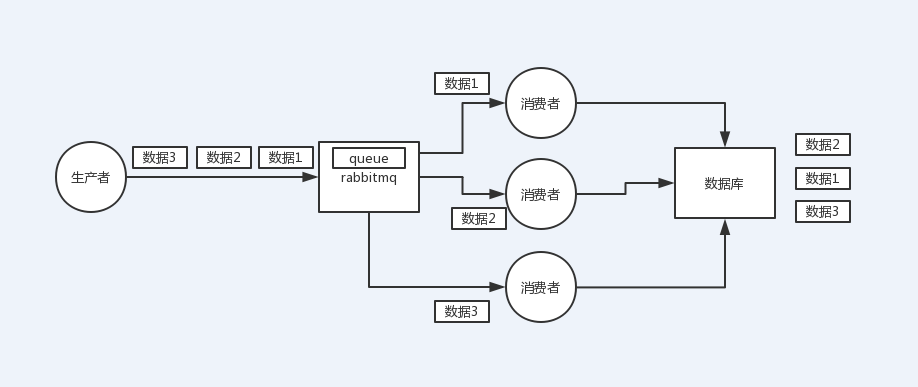
rabbitMQ如何保证消息的顺序性:如果有多个消费者,就配置多个queue,将需要保证顺序的消息全部写到一个queue里,这样就能保证消息的顺序性
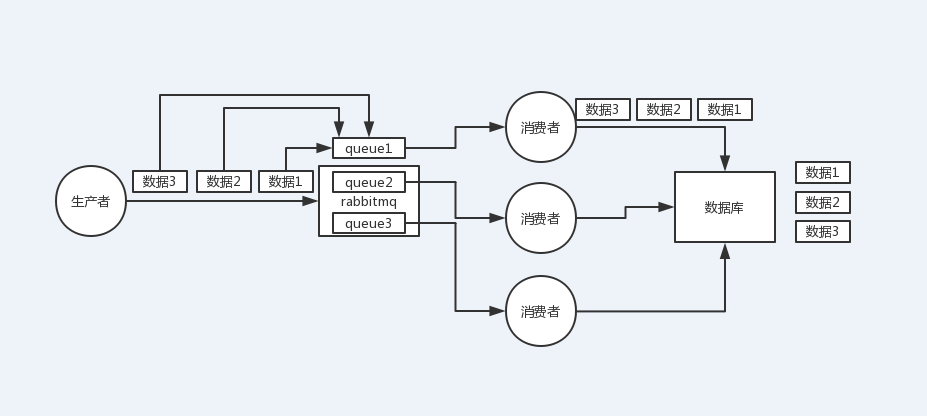
kafka顺序性问题

1个topic,3个partition,3个consumer,每个消费者消费一个partition,需要保证顺序的消息都放入同一个partiton,但是如果一个消费者开启多个线程来处理,还是无法保证消息的顺序性。
kafka如何保证消息的顺序性:

解决办法:每个消费者内部设置多个内存队列,对消息的key做hash,将需要保证顺序的消息映射到同一个内存队列中,每个线程负责处理一个内存队列
如何解决消息队列的延时过期失效问题?消息队列满了以后该如何处理?有几百万消息持续积压几个小时,说说怎么解决?
本质针对的场景是,消费端出问题了,不消费了,或者消费端消费速度很慢,可能消息队列集群的磁盘都快满了,都没消费者来消费,导致整个就积压了几个小时,这个时候该怎么办?
RabbitMQ中由于消息积压导致过期被清理了怎么办
假设你用的是rabbitmq,rabbitmq是可以设置过期时间的,就是TTL,如果消息在queue中积压超过一定的时间就会被rabbitmq给清理掉,这个数据就没了。
这就不是说数据会大量积压在mq里,而是大量的数据会直接搞丢。
这个情况下,就不是说要增加consumer消费积压的消息,因为实际上没啥积压,而是丢了大量的消息。
我们可以采取一个方案,就是批量重导。就是大量积压的时候,我们当时就直接丢弃数据了,然后等过了高峰期以后,这个时候我们就开始写程序,将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新灌入mq里面去,把白天丢的数据给他补回来。
假设1万个订单积压在mq里面,没有处理,其中1000个订单都丢了,你只能手动写程序把那1000个订单给查出来,手动发到mq里去再补一次
如果让你来写一个消息队列,该如何进行架构设计?说一下你的思路?
首先这个MQ得支持可伸缩性,就是需要的时候快速扩容,就可以增加吞吐量和容量,如何搞? 设计一个分布式的系统呗,参考kafka的设计理念, broker->topic->partition ,每个partition放一个机器,就存一部分数据。如果现在资源不够,就给topic增加partition(分区),然后做数据迁移,增加机器,就可以存放更多数据,提供更高的吞吐量。。。
其次要考虑这个MQ是否需要持久化到磁盘,肯定是要的,比如MQ进程挂了,数据还保存在磁盘中,导致数据不丢失。如何落地到磁盘?顺序写,这样就没有磁盘随机读取的寻址开销,磁盘顺序读写的性能是很高的,这就是 Kafka的设计理念
其次还得考虑MQ的可用性,参照Kafka的高可用的策略。多副本->leader&follower->broker 挂了重新选举leader即可对外服务
能不能支持0数据丢失,可以参照Kafka的数据零丢失方案
其实MQ是一个相当复杂的东西
消息队列MQ(一)的更多相关文章
- 为什么会需要消息队列(MQ)?
为什么会需要消息队列(MQ)? #################################################################################### ...
- 消息队列一:为什么需要消息队列(MQ)?
为什么会需要消息队列(MQ)? #################################################################################### ...
- 详解RPC远程调用和消息队列MQ的区别
PC(Remote Procedure Call)远程过程调用,主要解决远程通信间的问题,不需要了解底层网络的通信机制. RPC框架 知名度较高的有Thrift(FB的).dubbo(阿里的). RP ...
- 消息队列 MQ 入门理解
功能特性: 应用场景: 消息队列 MQ 可应用于如下几个场景: 分布式事务 在传统的事务处理中,多个系统之间的交互耦合到一个事务中,响应时间长,影响系统可用性.引入分布式事务消息,交易系统和消息队列之 ...
- 消息队列MQ简介
项目中要用到RabbitMQ,领导让我先了解一下.在之前的公司中,用到过消息队列MQ,阿里的那款RocketMQ,当时公司也做了简单的技术分享,自己也看了一些博客.自己在有道云笔记上,做了一些整理,但 ...
- 消息队列MQ集合
消息队列MQ集合 消息队列简介 kafka简介 Centos7部署zookeeper和Kafka集群 .
- 高并发系统:消息队列MQ
注:前提是知道什么是消息队列.不懂的去搜索各种消息队列入门(activeMQ.rabbitMQ.rocketMQ.kafka) 1.为什么要使用MQ?(MQ的好处:解耦.异步.削峰) (1)解耦:主要 ...
- java面试记录三:hashmap、hashtable、concurrentHashmap、ArrayList、linkedList、linkedHashmap、Object类的12个成员方法、消息队列MQ的种类
口述题 1.HashMap的原理?(数组+单向链表.put.get.size方法) 非线程安全:(1)hash冲突:多线程某一时刻同时操作hashmap并执行put操作时,可能会产两个key的hash ...
- 【消息队列MQ】各类MQ比较
目录(?)[-] RabbitMQ Redis ZeroMQ ActiveMQ JafkaKafka 目前业界有很多MQ产品,我们作如下对比: RabbitMQ 是使用Erlang编写的一个开源的消息 ...
- 消息队列mq的原理及实现方法
消息队列技术是分布式应用间交换信息的一种技术.消息队列可驻留在内存或磁盘上,队列存储消息直到它们被应用程序读走.通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置.或在继续执行前不需要等待 ...
随机推荐
- Java基础语法和基本数据类型
Java基础语法 一个Java程序可以认为是一系列对象的集合,而这些对象通过调用彼此的方法来协同工作. 对象:对象是类的一个实例,有状态(属性)和行为(方法). 类:类是一个模板,他描述一类对象的行为 ...
- HCNA网络技术学习指南
网络通信基础 网络与通信 OSI模型和TCP/IP模型 网络类型 传输介质及通信方式 2 VRP基础 VRP简介 VRP命令行 登录设备 基本配置 配置文件管理 通过Telnet登录设备 文件管理 基 ...
- 个人第四次作业Alpha2版本测试
个人第四次作业Alpha2版本测试 这个作业属于哪个课程 软件工程 这个作业要求在哪里 作业要求 团队名称 GP工作室 这个作业的目标 对其他小组的项目进行测试 测试人员 陈杰 学号 20173102 ...
- ssh隧道使用
在内网中几乎所有的linux服务器和网络设备都支持ssh协议.一般情况下,ssh协议是允许通过防火墙和边界设备的,所以经常被攻击者利用.同时ssh协议的传输过程是加密的,所以我们很难区分合法的ssh会 ...
- CSS-11-外边距
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- SIFT特征匹配算法介绍
原文路径:https://www.learnopencv.com/histogram-of-oriented-gradients/ 按语:偶得SIFT特征匹配算法原理介绍,此文章确通俗易懂,分享之! ...
- 在windows中python安装sit-packages路径位置 在Pycharm中导入opencv不能自动代码补全问题
在Pycharm中导入opencv不能自动代码补全问题 近期学习到计算机视觉库的相关知识,经过几个小时的探讨,终于解决了opencv不能自动补全代码的困惑, 我们使用pycharm安装配置可能会添加多 ...
- ios---图片缩放
1.设置scrollview的代理 2.实现如下方法 -(UIView )viewForZoomingInScrollView:(UIScrollView )scrollView{ return se ...
- Docker底层架构之容器格式
最初,Docker 采用了 LXC 中的容器格式.自 1.20 版本开始,Docker 也开始支持新的 libcontainer 格式,并作为默认选项.
- 暑假第四周总结(HDFS编程实践,安装HBASE)
本周根据书上以及教程的提示,对HDFS进行了编程实践,将教程所给的代码(判断文件是否存在,创建文件,读取文件)进行了应用,根据视频的讲解,对一些简单的语句有了一定的了解,但还是比较生疏.另外还根据提示 ...