前向传播和反向传播实战(Tensor)
前面在mnist中使用了三个非线性层来增加模型复杂度,并通过最小化损失函数来更新参数,下面实用最底层的方式即张量进行前向传播(暂不采用层的概念)。
主要注意点如下:
· 进行梯度运算时,tensorflow只对tf.Variable类型的变量进行记录,而不对tf.Tensor或者其他类型的变量记录
· 进行梯度更新时,如果采用赋值方法更新即w1=w1+x的形式,那么所得的w1是tf.Tensor类型的变量,所以要采用原地更新的方式即assign_sub函数,或者再次使用tf.Variable包起来(不推荐)
代码如下:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets
import os os.environ['TF_CPP_MIN_LOG_LEVEL']='' # x:[60k,28,28]
# y:[60k]
(x,y),_=datasets.mnist.load_data() x = tf.convert_to_tensor(x,dtype=tf.float32)/255.0
y = tf.convert_to_tensor(y,dtype=tf.int32) print(x.shape,y.shape,x.dtype,y.dtype)
print(tf.reduce_min(x),tf.reduce_max(x))
print(tf.reduce_min(y),tf.reduce_max(y)) train_db=tf.data.Dataset.from_tensor_slices((x,y)).batch(128)
train_iter=iter(train_db)
sample=next(train_iter)
print('batch:',sample[0].shape,sample[1].shape) # [b,784]=>[b,256]=>[b,128]=>[b,10]
# w shape[dim_in,dim_out] b shape[dim_out]
w1 = tf.Variable(tf.random.truncated_normal([784,256],stddev=0.1))
b1 = tf.Variable(tf.zeros([256])) w2 = tf.Variable(tf.random.truncated_normal([256,128],stddev=0.1))
b2 = tf.Variable(tf.zeros([128])) w3 = tf.Variable(tf.random.truncated_normal([128,10],stddev=0.1))
b3 = tf.Variable(tf.zeros([10])) # 设置学习率
lr = 0.001
for epoch in range(10): # 对数据集迭代
for step,(x,y) in enumerate(train_db):
# x:[128,28,28] y:[128]
x = tf.reshape(x,[-1,28*28]) with tf.GradientTape() as tape: # tape只会跟踪tf.Variable
# x:[b,28*28]
# [b,784]@[784,256]+[256]=>[b,256]+[256]
h1 = x@w1 + b1
h1 = tf.nn.relu(h1) # 去线性化
h2 = h1@w2 + b2
h2 = tf.nn.relu(h2) # 去线性化
out = h2@w3 + b3 # 计算损失
y_onehot = tf.one_hot(y,depth=10)
# mse = mean(sum(y-out)^2)
loss = tf.square(y_onehot - out)
# mean:scalar
loss = tf.reduce_mean(loss) # 计算梯度
grads = tape.gradient(loss,[w1,b1,w2,b2,w3,b3])
# w1 = w1 -lr * w1_grad
w1.assign_sub(lr * grads[0]) # 原地更新
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
w3.assign_sub(lr * grads[4])
b3.assign_sub(lr * grads[5]) if step % 100 == 0:
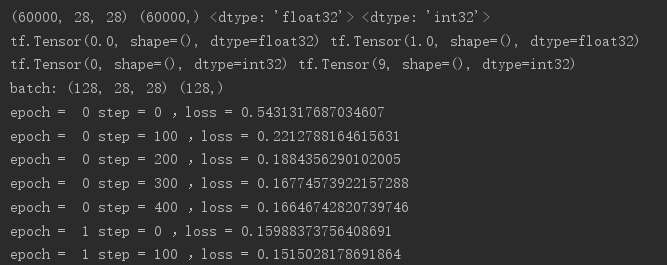
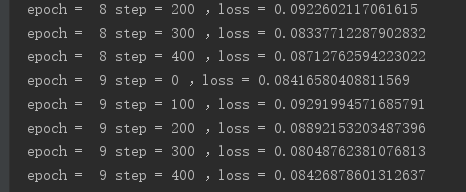
print('epoch = ',epoch,'step =',step,',loss =',float(loss))
效果如下:
前向传播和反向传播实战(Tensor)的更多相关文章
- 机器学习(ML)八之正向传播、反向传播和计算图,及数值稳定性和模型初始化
正向传播 正向传播的计算图 通常绘制计算图来可视化运算符和变量在计算中的依赖关系.下图绘制了本节中样例模型正向传播的计算图,其中左下角是输入,右上角是输出.可以看到,图中箭头方向大多是向右和向上,其中 ...
- 小白学习之pytorch框架(6)-模型选择(K折交叉验证)、欠拟合、过拟合(权重衰减法(=L2范数正则化)、丢弃法)、正向传播、反向传播
下面要说的基本都是<动手学深度学习>这本花书上的内容,图也采用的书上的 首先说的是训练误差(模型在训练数据集上表现出的误差)和泛化误差(模型在任意一个测试数据集样本上表现出的误差的期望) ...
- caffe中 softmax 函数的前向传播和反向传播
1.前向传播: template <typename Dtype> void SoftmaxLayer<Dtype>::Forward_cpu(const vector< ...
- caffe中的前向传播和反向传播
caffe中的网络结构是一层连着一层的,在相邻的两层中,可以认为前一层的输出就是后一层的输入,可以等效成如下的模型 可以认为输出top中的每个元素都是输出bottom中所有元素的函数.如果两个神经元之 ...
- BP原理 - 前向计算与反向传播实例
Outline 前向计算 反向传播 很多事情不是需要聪明一点,而是需要耐心一点,踏下心来认真看真的很简单的. 假设有这样一个网络层: 第一层是输入层,包含两个神经元i1 i2和截距b1: 第二层是隐含 ...
- 反向传播算法(前向传播、反向传播、链式求导、引入delta)
参考链接: 一文搞懂反向传播算法
- Tensorflow笔记——神经网络图像识别(一)前反向传播,神经网络八股
第一讲:人工智能概述 第三讲:Tensorflow框架 前向传播: 反向传播: 总的代码: #coding:utf-8 #1.导入模块,生成模拟数据集 import t ...
- BP神经网络反向传播之计算过程分解(详细版)
摘要:本文先从梯度下降法的理论推导开始,说明梯度下降法为什么能够求得函数的局部极小值.通过两个小例子,说明梯度下降法求解极限值实现过程.在通过分解BP神经网络,详细说明梯度下降法在神经网络的运算过程, ...
- 深度学习与CV教程(4) | 神经网络与反向传播
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
随机推荐
- 初学maven的一些配置
初学Maven的一些配置 1.maven的安装 2.从官网下载3.6.1版本后,高级版本可能会出现不兼容 jdk1.8 3.配置maven 在 settings.xml <settings> ...
- Window下,Jenkins忘记密码解决方法
没有修改过密码的情况下找回初始密码(或者第一次部署的时候) 进入目录 D:\jenkins\secrets ,找到文件 initialAdminPassword 在jenkins页面,输入登录名adm ...
- 2020牛客寒假算法基础集训营4 C : 子段乘积
C:子段乘积 考察点 : 线段树,尺取,乘法逆元 坑点 : 区间要做到不重不漏, long long 侃侃 : 这道题在比赛是写的尺取,但是写了半天发现不好处理除 0 问题(浮点错误),需要用到乘法逆 ...
- 腾讯云Centos服务器部署问题
在Centos7上部署Tomcat过程 下载并安装JDK 下载并部署Tomcat 打开Centos中对应的端口(默认80) 这几步操作很清楚,但首次使用Centos7时遇到了一个问题,外网无法访问服务 ...
- 手写Tomcat
学习JavaWeb之后,只知道如何部署项目到Tomcat中,而并不了解其内部如何运行,底层原理为何,因此写下此篇博客初步探究一下.学习之前需要知识铺垫已列出:Tomcat目录结构.HTTP协议.IO. ...
- abp(net core)+easyui+efcore实现仓储管理系统——入库管理之一(三十七)
abp(net core)+easyui+efcore实现仓储管理系统目录 abp(net core)+easyui+efcore实现仓储管理系统——ABP总体介绍(一) abp(net core)+ ...
- Linux 软件安装卸载 (源码、rpm)
Linux下软件的安装主要有两种不同的形式.第一种安装为源码安装,文件名为xxx.tar.gz压缩包为主;以第一种方式发行的软件多为以源码形式发送的.第二种方式则是另一种安装文件名为xxx.i386. ...
- zabbix-proxy配置文件参数说明
配置文件路径: /etc/zabbix/zabbix_proxy.conf Server=10.0.0.10 #<===指定zabbix server的ip地址或主机名 Hostname=zab ...
- Centos7.5中Nginx报错:nginx: [error] invalid PID number "" in "/run/nginx.pid" 解决方法
服务器重启之后,执行 nginx -t 是OK的,然而在执行 nginx -s reload 的时候报错 nginx: [error] invalid PID number "" ...
- 十天学会CS之操作系统——进程管理01
进程管理01 进程的概念 进程是计算机中一个非常重要的概念,在整个计算机发展历史中,操作系统中程序运行机制的演变按顺序大致可以分为: 单道程序:通常是指每一次将一个或者一批程序(一个作业)从磁盘加载进 ...