AdaBoost笔记之原理
转自:https://www.cnblogs.com/ScorpioLu/p/8295990.html
一、Boosting提升算法
AdaBoost是典型的Boosting算法,属于Boosting家族的一员。在说AdaBoost之前,先说说Boosting提升算法。Boosting算法是将“弱学习算法“提升为“强学习算法”的过程,主要思想是“三个臭皮匠顶个诸葛亮”。一般来说,找到弱学习算法要相对容易一些,然后通过反复学习得到一系列弱分类器,组合这些弱分类器得到一个强分类器。
Boosting算法要涉及到两个部分,加法模型和前向分步算法。
加法模型就是说强分类器由一系列弱分类器线性相加而成。一般组合形式如下:
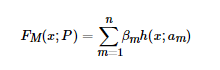
其中,h(x;am) 就是一个个的弱分类器,am是弱分类器学习到的最优参数,βm就是弱学习在强分类器中所占比重,P是所有am和βm的组合。这些弱分类器线性相加组成强分类器。
前向分步就是说在训练过程中,下一轮迭代产生的分类器是在上一轮的基础上训练得来的。也就是可以写成这样的形式:
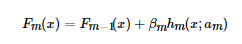
由于采用的损失函数不同,Boosting算法也因此有了不同的类型,AdaBoost就是损失函数为指数损失的Boosting算法。
二、AdaBoost
原理理解
基于Boosting的理解,对于AdaBoost,我们要搞清楚两点:
- 每一次迭代的弱学习h(x;am)有何不一样,如何学习?
- 弱分类器权值βm如何确定?
对于第一个问题,AdaBoost改变了训练数据的权值,也就是样本的概率分布,其思想是将关注点放在被错误分类的样本上,减小上一轮被正确分类的样本权值,提高那些被错误分类的样本权值。然后,再根据所采用的一些基本机器学习算法进行学习,比如逻辑回归。
对于第二个问题,AdaBoost采用加权多数表决的方法,加大分类误差率小的弱分类器的权重,减小分类误差率大的弱分类器的权重。这个很好理解,正确率高分得好的弱分类器在强分类器中当然应该有较大的发言权。
实例
为了加深理解,我们来举一个例子。
有如下的训练样本,我们需要构建强分类器对其进行分类。x是特征,y是标签。
| 序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
令权值分布D1=(w1,1,w1,2,…,w1,10)
并假设一开始的权值分布是均匀分布:w1,i=0.1,i=1,2,…,10
现在开始训练第一个弱分类器。我们发现阈值取2.5时分类误差率最低,得到弱分类器为:
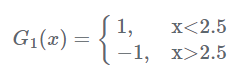
当然,也可以用别的弱分类器,只要误差率最低即可。这里为了方便,用了分段函数。得到了分类误差率e1=0.3。
第二步计算G1(x)在强分类器中的系数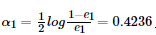 ,这个公式先放在这里,下面再做推导。
,这个公式先放在这里,下面再做推导。
第三步更新样本的权值分布,用于下一轮迭代训练。由公式:
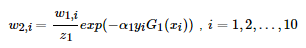
得到新的权值分布,从各0.1变成了:
可以看出,被分类正确的样本权值减小了,被错误分类的样本权值提高了。
第四步得到第一轮迭代的强分类器:
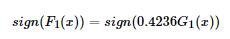
以此类推,经过第二轮……第N轮,迭代多次直至得到最终的强分类器。迭代范围可以自己定义,比如限定收敛阈值,分类误差率小于某一个值就停止迭代,比如限定迭代次数,迭代1000次停止。
这里数据简单,在第3轮迭代时,得到强分类器:
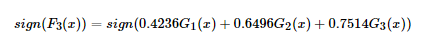
的分类误差率为0,结束迭代。
F(x)=sign(F3(x))就是最终的强分类器。
算法流程
总结一下,得到AdaBoost的算法流程:

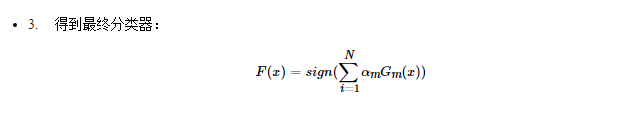
公式推导
现在我们来搞清楚上述公式是怎么来的。


真漂亮!
另外,AdaBoost的代码实战与详解请戳代码实战之AdaBoost
还可参考:机器学习实战之AdaBoost算法
AdaBoost笔记之原理的更多相关文章
- Adaboost 算法的原理与推导——转载及修改完善
<Adaboost算法的原理与推导>一文为他人所写,原文链接: http://blog.csdn.net/v_july_v/article/details/40718799 另外此文大部分 ...
- [转]Adaboost 算法的原理与推导
看了很多篇解释关于Adaboost的博文,觉得这篇写得很好,因此转载来自己的博客中,以便学习和查阅. 原文地址:<Adaboost 算法的原理与推导>,主要内容可分为三块,Adaboost ...
- AdaBoost笔记之通俗易懂原理介绍
转自:https://blog.csdn.net/px_528/article/details/72963977 写在前面 说到Adaboost,公式与代码网上到处都有,<统计学习方法>里 ...
- Adaboost 算法的原理与推导
0 引言 一直想写Adaboost来着,但迟迟未能动笔.其算法思想虽然简单“听取多人意见,最后综合决策”,但一般书上对其算法的流程描述实在是过于晦涩.昨日11月1日下午,邹博在我组织的机器学习班第8次 ...
- AlloyTouch.js 源码 学习笔记及原理说明
alloyTouch这个库其实可以做很多事的, 比较抽象, 需要我们用户好好的思考作者提供的实例属性和一些回调方法(touchStart, change, touchMove, pressMove, ...
- AlloyFinger.js 源码 学习笔记及原理说明
此手势库利用了手机端touchstart, touchmove, touchend, touchcancel原生事件模拟出了 rotate touchStart multipointStart ...
- AdaBoost笔记之代码
最近要做二分类问题,先Mark一下知识点和代码,参考:Opencv2.4.9源码分析——Boosting 以下内容全部转自此文 一 原理 二 opencv源码 1.先看构建Boosting的参数: ...
- JeeSite学习笔记~代码生成原理
1.建立数据模型[单表,一对多表,树状结构表] 用ERMaster建立数据模型,并设定对应表,建立关联关系 2.系统获取对应表原理 1.怎样获取数据库的表 genTableForm.jsp: < ...
- java concurrency in practice读书笔记---ThreadLocal原理
ThreadLocal这个类很强大,用处十分广泛,可以解决多线程之间共享变量问题,那么ThreadLocal的原理是什么样呢?源代码最能说明问题! public class ThreadLocal&l ...
随机推荐
- 实战:基于 Spring 的应用配置如何迁移至阿里云应用配置管理 ACM
最近遇到一些开发者朋友,准备将原有的Java Spring的应用配置迁移到 阿里云应用配置管理 ACM 中.迁移过程中,遇到不少有趣的问题.本文将通过一个简单的样例来还原迁移过程中遇到的问题和相关解决 ...
- ASP.NET 服务器控件对应的HTML标签
label----------<span/> button---------<input type="submit"/> textbox--------&l ...
- 基于V8的JsonMapper
<dependency> <groupId>com.eclipsesource.j2v8</groupId> <artifactId>j2v8_win3 ...
- C++——变量
1.变量的初始化和赋值 初始化:创建变量时赋予一个初始值 赋值:把变量的当前值擦除,以新的值替代 2.变量的声明和定义 声明:名字为程序所知.如果一个程序要使用另一个程序的名字,则要包含对那个名字的声 ...
- PE代码段中的数据
PE代码段中可能包含一些数据,比如 optional header中的data directory会索引到一些数据,比如import/export table等等: 还有一些jump table/sw ...
- Django框架(十)—— 多表操作:一对一、一对多、多对多的增删改,基于对象/双下划线的跨表查询、聚合查询、分组查询、F查询与Q查询
目录 多表操作:增删改,基于对象/双下划线的跨表查询.聚合查询.分组查询.F查询与Q查询 一.创建多表模型 二.一对多增删改表记录 1.一对多添加记录 2.一对多删除记录 3.一对多修改记录 三.一对 ...
- java实现后台自动发邮件功能
web.xml文件 <?xml version="1.0" encoding="UTF-8"?><!DOCTYPE web-app PUBLI ...
- Spring MVC源码分析(二):SpringMVC的DispatcherServlet的设计与实现
概述 DispatcherServlet是SpringMVC的一个前端控制器,是MVC架构中的C,即controller的实现,用于拦截这个web应用的所有请求,具体为在web.xml中配置这个s ...
- Redis数据结构之整数集合-intset
当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis会使用整数集合(intset)来存储集合元素. intset是紧凑的数组结构,同时支持16位.32位和64位整数. 结构 struc ...
- pytest-mark跳过
import pytestimport sysenvironment='android' @pytest.mark.skipif(environment=="android",re ...