scrapy的使用--Rcrapy-Redis
Scrapy-Redis分布式爬虫组件
Scrapy是一个框架,他本身是不支持分布式的。如果我们想要做分布式的爬虫。就需要借助一个组件叫做Scrapy-Redis。这个组件正式利用了Redis可以分布式的功能,继承到Scrapy框架中,使得爬虫可以进行分布式,可以充分的利用资源(多个ip,更多带宽,同步爬取)来提高爬虫的爬取效率。
-分布式爬虫组件的优点:
1.可以充分利用多台机器的带宽
2.可以充分利用多台机器的ip地址
3.多台机器工作,io频率提高,爬取效率更高
-分布式爬虫需要解决的问题:
1.分布式爬虫是好几个台式机器在同时运行,保证不同的机器爬取页面的时候不会出现重复爬取的问题。
2.同样,分布式爬虫在不同的机器上运行,在把数据爬取完后如何保存在同一个地方。
Scrapy 框架图
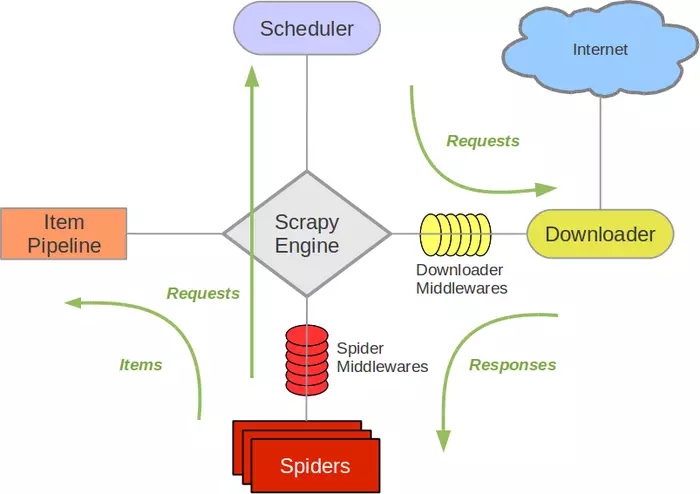
Scrapy-Redis
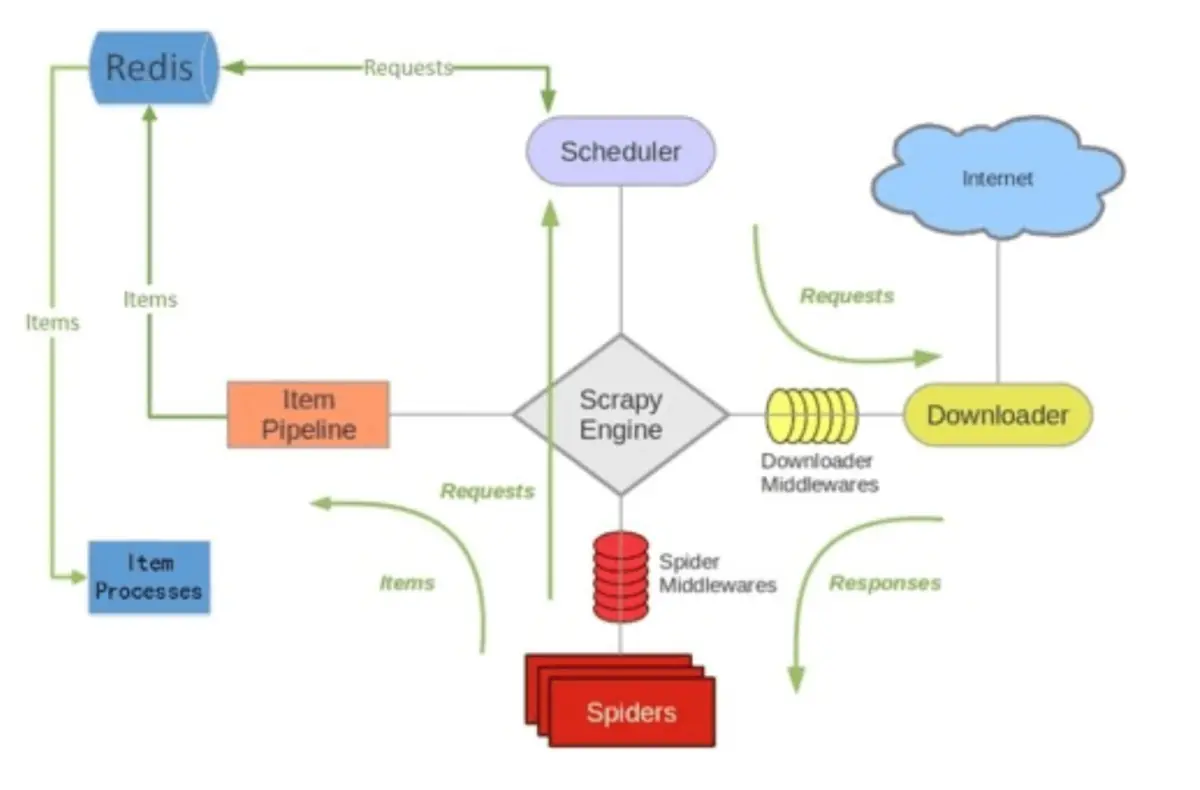
-分布式架构图:
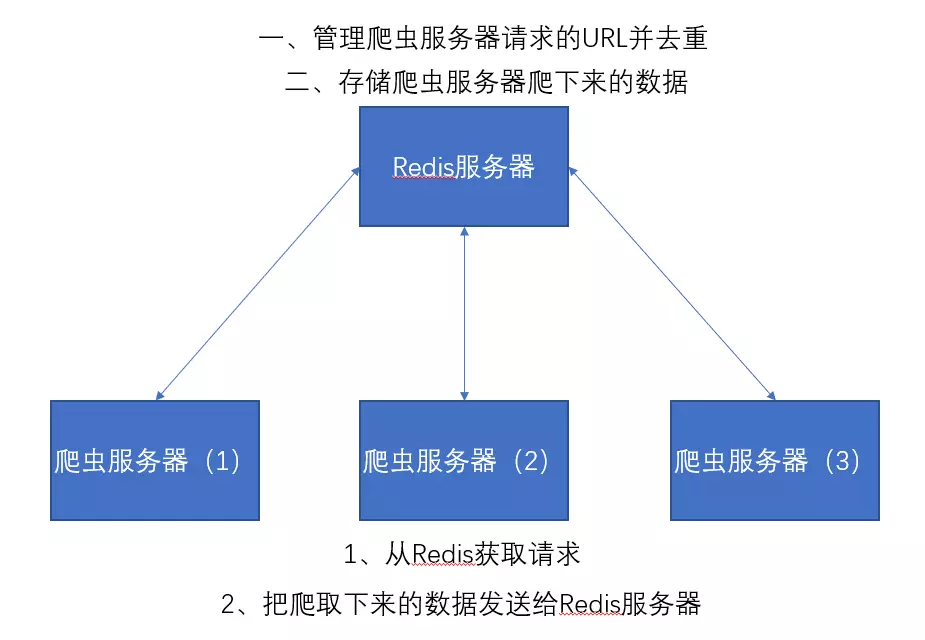
Redis教程:
概述
redis是一种支持分布式的nosql数据库,他的数据是深存在内存中,同时可以将数据持久化,并且他比memcached 支持更多的数据结构(string,list,set,sorted set(有序集合),hash(hash)
redis使用的场景:
1.登录会话存储在redis中。memcached(缓存)
2.作为消息队列,‘celary’使用redis作为中间人(消息队列)
3.排行版/计数器:比如一些秀场类的项目,经常会有一些钱多少名的主播排名,或者点赞数之类的(计数器)
4. 当前在线人数,会显示当前系统多少在线人数。
5.一些常用的数据缓存:一些论坛,模块不会经常变化。但是每次访问首页都要从MySQL中获取,可以在redis中缓存起来,不用每次请求数据库。
6.把前200篇文章缓存或者评论缓存;一般用户浏览网站,只会浏览前面一部分文章或者评论,那么可以把前面200篇文章和对应的评论缓存起来,用户访问超时的,就访问数据库,并且以后文章超过200篇,则把之前的文章删除。
7.好友关系,微博的好友关系使用redis实现。
8.发布和订阅功能,可以用来聊天软件
具体分布式区别:https://www.cnblogs.com/457248499-qq-com/p/7392653.html
scrapy的使用--Rcrapy-Redis的更多相关文章
- scrapy与redis分布式组件
Scrapy 和 scrapy-redis的区别 Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础 ...
- Scrapy 和 scrapy-redis的区别
Scrapy 和 scrapy-redis的区别 Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础 ...
- scrapy入门与进阶
Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非 ...
- Python爬虫框架Scrapy教程(1)—入门
最近实验室的项目中有一个需求是这样的,需要爬取若干个(数目不小)网站发布的文章元数据(标题.时间.正文等).问题是这些网站都很老旧和小众,当然也不可能遵守 Microdata 这类标准.这时候所有网页 ...
- scrapy实战2分布式爬取lagou招聘(加入了免费的User-Agent随机动态获取库 fake-useragent 使用方法查看:https://github.com/hellysmile/fake-useragent)
items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentati ...
- scrapy基础知识之 Scrapy 和 scrapy-redis的区别:
Scrapy 和 scrapy-redis的区别 Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础 ...
- 浅析scrapy与scrapy_redis区别
最近在工作中写了很多 scrapy_redis 分布式爬虫,但是回想 scrapy 与 scrapy_redis 两者区别的时候,竟然,思维只是局限在了应用方面,于是乎,搜索了很多相关文章介绍,这才搞 ...
- scrapy架构流程
1.爬虫spiders将请求通过引擎传递给调度器scheduler 2.scheduler有个请求队列,在请求队列中拿出请求给下载器,downloader 3.downloader从Internet的 ...
- 浅析scrapy与scrapy-redis的区别
首先,要了解两者的区别,就要清楚scrapy-redis是如何产生的,有需求才会有发展,社会在日新月异的飞速发展,大量相似网页框架的飞速产生,人们已经不满足于当前爬取网页的速度,因此有了分布式爬虫,让 ...
- Scrapy-redis 分布式
分布式:架构方式 多台真实机器+爬虫(如requests,scrapy等)+任务共享中心 多台虚拟机器(或者部分虚拟部分真实)+爬虫(如requests,scrapy等)+任务共享中心 多台容器级虚拟 ...
随机推荐
- Java习题练习
Java习题练习 1. 依赖注入和控制反转是同一概念: 依赖注入和控制反转是对同一件事情的不同描述,从某个方面讲,就是它们描述的角度不同.依赖注入是从应用程序的角度在描述,可以把依赖注入描述完整点:应 ...
- CSS:CSS Id 和 Class选择器
ylbtech-CSS:CSS Id 和 Class选择器 1.返回顶部 1. CSS Id 和 Class id 和 class 选择器 如果你要在HTML元素中设置CSS样式,你需要在元素中设置& ...
- $.ajax(),传参要用data
$("#modal").find(".btn-primary").unbind("click").click(function(){ var ...
- 剑指offer——45整数中1出现的次数
题目描述 求出1~13的整数中1出现的次数,并算出100~1300的整数中1出现的次数?为此他特别数了一下1~13中包含1的数字有1.10.11.12.13因此共出现6次,但是对于后面问题他就没辙了. ...
- testNG官方文档翻译-1 简介
官方文档链接http://testng.org/doc/documentation-main.html 简介 TestNG是一个被设计用来简化广泛的测试需求的测试框架,它既可应用于单元测试(测试一个独 ...
- 34-Ubuntu-用户权限-05-超级用户
超级用户 Linux系统中的root(超级用户)账号通常用于系统的维护和管理,对操作系统的所有资源具有访问的权限. 在大多数的Linux版本中,都不推荐直接使用root账号登录系统. 在Linux安装 ...
- 关于memset赋值无穷大无穷小
memset(a,,sizeof(a)); 即得到无穷大. memset(a,,sizeof(a)); 即得到无穷小,与上述的值互为相反数. memset(a,,sizeof(a)); 即近似为第一个 ...
- android Intent和IntentFilter
android的应用程序包含三种重要的组件:Activity.Service.BroadcastReceiver,应用程序采用一致的方式来启动他们——都是依靠Intent来进行启动.Intent就封装 ...
- Jenkins 搭建 .NET FrameWork 持续集成环境
本文不赘述如何安装 Jenkins,如有需要请看之前文章,这里我们主要搭建 .Net 环境.本文是在 Windows 环境下安装的 Jenkins 进行操作 一.安装所需环境 这里我们 ...
- leetcood学习笔记-108-将有序数组转换为二叉搜索树
---恢复内容开始--- 题目描述: 方法一: class Solution(object): def sortedArrayToBST(self, nums): """ ...