[翻译]Hystrix wiki–How it Works
注:本文并非是精确的文档翻译,而是根据自己理解的整理,有些内容可能由于理解偏差翻译有误,有些内容由于是显而易见的,并没有翻译,而是略去了。本文更多是学习过程的产出,请尽量参考原官方文档。
流程图
下图描述了当通过Hystrix请求依赖服务时的流程:
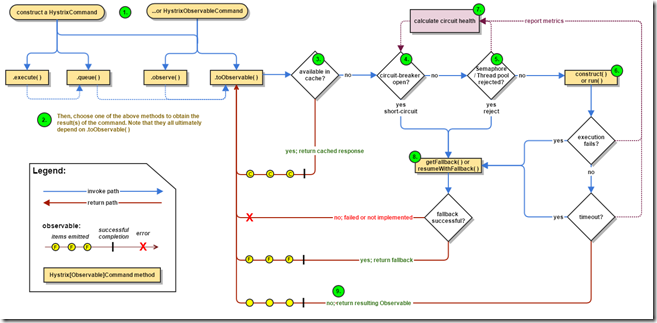
1. 创建HystrixCommand 或者 HystrixObserverbleCommand对象
通过将调用服务所需的参数传入commad的构造函数,创建commad对象。HystrixObserverbleCommand表示,调用的服务将返回一个Observable对象并且发射(emit)响应。
HystrixCommand command = new HystrixCommand(arg1, arg2);
HystrixObservableCommand command = new HystrixObservableCommand(arg1, arg2);
2. 执行command
上述两种command有四种执行方式(前两种只适用于HystrixCommand ):
- execute() -- 阻塞调用,返回所调用服务的正常、错误或者异常返回信息。
- queue() -- 返回Future对象,可从其中获取所调用服务的返回
- observe() -- 订阅代表服务返回的Observable对象,并且返回该对象的一个副本
- toObservable() -- 返回Observable对象,当向其订阅时,将会执行commad并且发射一个response
K value = command.execute();
Future<K> fValue = command.queue();
Observable<K> ohValue = command.observe(); //hot observable
Observable<K> ocValue = command.toObservable(); //cold observable
同步调用execute()会调用queue().get()方法,queue()会调用toObservable().toBlocking().toFuture。所以,最终每个HystrixCommand都是Observable实现。
3. 响应是否被缓存?
如对应依赖的响应缓存是打开的,并且缓存中存在对应响应,则会以Observable的形式从缓存中直接返回。
4. 断路器是否打开?
在执行commad时,将会检查断路器是否打开。
当断路器处于打开的状态时,将不会执行Commad,跳转到第8步执行降级策略。
如果断路器关闭,将会继续执行第5步,并且检查是否有足够的容量来执行命令。
5. 线程池/队列/信号量是否满?
当上述资源池已满,将不会执行Command,跳转到第8步执行降级策略。
6. 执行HystrixObservableCommand.construct() 或 HystrixCommand.run()
通过执行上述方法中的一种,Hystrix实现对依赖的调用,其中:
- HystrixCommand.run() -- 正常返回或者抛出异常
- HystrixObservableCommand.construct() -- 返回Observable对象,发射一个返回或者onError通知
如果run或者construct方法超时,对应线程将会抛出超时异常。此时进入降级流程,并且如果正常的服务调用没有取消而且最终得到响应,则此响应将被丢弃。
这里需要注意的是,由于没有办法确保一个线程强制结束,Hystrix最多能够向服务调用线程抛出一个InterruptedException。如果实际的工作线程没有对该异常进行正常响应,而是忽略;则Hystrix线程池将继续执行,此时客户端实际上已经得到了TimeoutException。尽管此时客户端的负载已被有效隔离,这种情形仍可能导致Hystrix线程池耗尽。大多数的Java Http Client组件库在得到InterruptedException时不会正常终止线程执行,因此,请确保服务调用的读写超时配置正确。
7. 计算回路健康指标
断路器通过维护一组计数器来统计回路的健康指标,Hystrix会将服务调用的成功、失败、拒绝、超时等次数发给断路器。
断路器通过统计数据来决定是否触发断路逻辑。断路器打开后,将经过一定的预设时间,在此期间所有的请求均不会实际执行。预设时间达到后,如果此时服务调用健康检测通过,则会关闭断路器。
8. 进入降级策略
当command执行失败(4、5、6步中提及的情形),Hystrix将触发降级。
使用Hystrix时,需要根据具体的场景写出降级逻辑,可以是从缓存中获取响应或者进入静态的处理逻辑。如果,此时仍旧必须通过网络调用来执行降级逻辑,则需要在另外一个Command中执行。
当使用HystrixCommand时,需要实现HystrixCommand.getFallBack()方法来实现降级策略。
当使用HystrixObservableCommand时,需要实现HystrixObservableCommand.resumeWithFallback(),其将会返回一个Observable对象。
当降级方法返回时,Hystrix向调用者相应返回。使用HystrixCommand.getFallback()时,返回Observable对象发射从降级方法中得到的响应。当使用HystrixObservableCommand.resumeWithFallback()时,返回降级方法实际返回的Observable对象。
如果在使用时未实现降级方法,或者降级方法本身会抛出异常,Hystrix仍然会返回Observable对象,但不会发射任何对象,而是会在onError通知后立即结束。通过onError通知,导致Command终止的异常被传递给调用方。(降级方法本身不应该失败,在实际中应该尽量避免这种情况)
触发Hystrix command的方式不同,失败的降级方法的结果不同:
- execute() – 抛出异常
- queue() -- 返回Future,当其get()方法被调用时,抛出异常
- observe() -- 返回Observable,当对其subscribe时,通过调用subscriber的onError方法将立即终止
- toObservable() -- 返回Observable,当对其subscribe时, 通过调用subscriber的onError方法将终止
9. 成功返回
当Hystrix command成功返回时,其通过Observable向调用者返回。实际返回的形式取决于第2步中触发command的方式:
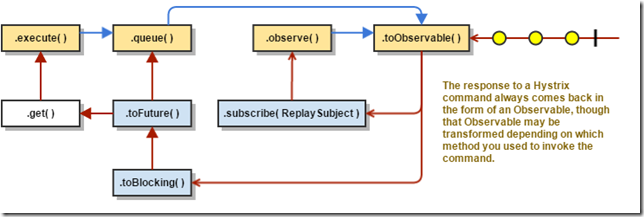
- execute() – 通过Future对象的get()方法得到返回值。
- queue() -- 通过将Observable对象转换为BlockingObservable对象,以便转换为Future对象并返回。
- observe() -- 首先向Observable注册,并开始执行command;最终返回Observable对象,当向其订阅时,将会执行发射或者通知
- toObservable() -- 直接返回Observable对象;必须显示订阅来触发调用
断路器
下面的时序图,表示了HystrixCommand和断路器间的交互逻辑以及各统计判断过程。
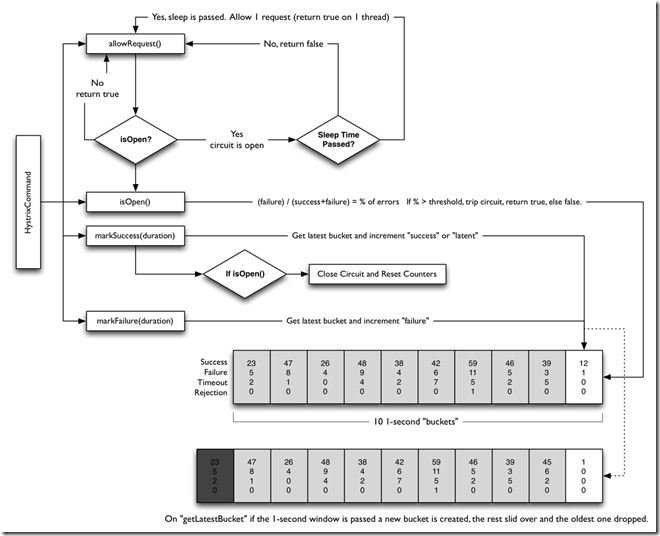
断路器的开关状态切换如下:
- 如果通过回路的流量达到一定值
- 如果出错率超过了预设的出错率
- 断路器打开
- 当断路器打开时,所有请求将不会被通过
- 达到预设的时间后,下一个请求将会被通过(half-open)。如果请求失败,断路器将继续保持打开状态并休眠固定的时间;如果请求成功,则断路器关闭。
隔离
Hystrix采用壁仓模式(bulkhead pattern)隔离依赖。
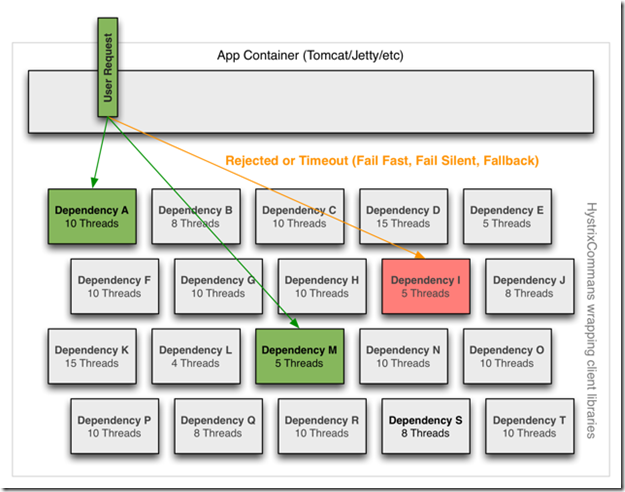
线程及线程池
Hystrix 使用每个服务独立的线程池,这样一来,每个服务的延迟最坏只会造成该服务对应的线程池耗尽。
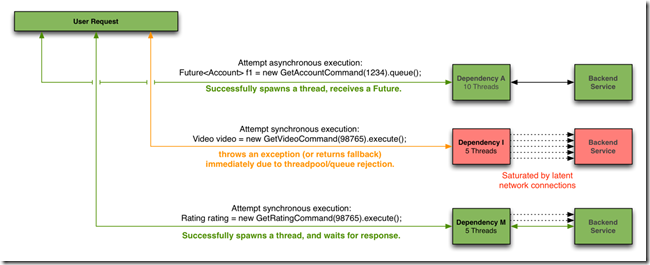
也可以不使用针对每个服务独立的线程池,在这种情况下,要保证服务不受外部依赖影响,则需要客户端能够快速失败并且能够正确返回失败信息。
Hystrix采用线程池作为服务隔离的手段主要有以下原因:
- 许多应用依赖的后台服务成十上百,这些服务可能有许多不同的团队开发。
- 每个服务都提供了自己的客户端库
- 客户端库总是在不停的改变中
- 客户端库可能随着需要调用的服务增多而改变内部逻辑
- 客户端库可能包含了诸如重试、缓存、数据解析等等内部逻辑
- 对于使用方来说客户端库更像是一个黑盒,实现细节、网络调用方式、默认配置等对使用方来说不是非常显而易见的
- 在线上,很多问题的最终定位原因都会归结为:“客户端有些东西改变,需要对应调整应用的配置”或者“客户端的逻辑改变了”
- 如果使用方未做任何变更,服务本身可能升级,这种情况可能也会引起使用方配置的不可用从而引起问题
- Transitive dependencies can pull in other client libraries that are not expected and perhaps not correctly configured.(没明白)
- 网络调用通常是同步的调用
- 不仅仅是网络调用,客户端代码也可能引起超时或者不可用
使用线程池的好处
使用服务级独立的线程池,主要有以下好处:
- 应用受保护不被不可用的客户端库影响。每个服务只可能耗尽对应的线程池,不会影响整个应用
- 新加入的客户端库带来的影响可控
- 当客户端库恢复可用后,对应的线程池能够快速恢复可用。相反,不使用线程池时,应用级的恢复可能耗费更多的时间。
- 如果某个依赖客户端的配置有误,可以迅速定位问题,并且在不影响整个应用的情况下快速修复问题。
- 同样地,当某个客户端的特性改变引起原油的配置不适用时,也可以迅速定位问题,同样可以迅速修复问题。
- 除了隔离带来的益处,适用线程池在同步调用的基础上增加了一层内建的异步机制
总之,线程池隔离能够使得应用对于客户端库以及远程服务的改变迅速响应,优雅应对,避免资源耗尽。
线程池的缺陷
采用线程池带来的主要负面影响是额外的计算开销。每个单独的command执行都包含排队、调度、上下文切换等等由于线程执行带来的开销。
线程的开销
Hystrix对父线程端到端执行的总时间消耗以及执行command的子线程的时间消耗都做了计量,以次来观测Hystrix带来的整体开销。
下图描述了一个每秒通过HystrixCommand处理每秒约60次请求(向后每秒调用约350次后台服务)的请求开销:
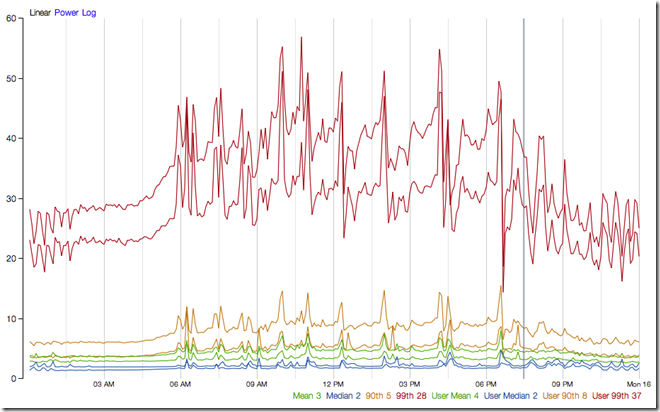
在中位数处,采用额外的线程没有带来明显的开销
在90%处,额外的线程带来的开销约为3ms
在99%处,额外的线程带来的开销约为9ms。相比于中位数处,实际服务调用时间从2增加到28,而额外的线程开销从0增加到9。
这种额外的开销相比起带来的益处在大多数情况下我们认为是可以接受的。
信号量
作为线程池的替代,Hystrix同样支持使用信号量(或计数器)限制某个服务的并发调用量。与线程池不同的是,信号量不支持超时计数(timing out)和walking away(这个咋翻。。。)。在信任客户端并且仅仅想达到负载限制的目的的情况下,可以采用这种方法。
HystrixCommand和HystrixObservableCommand在如下两个方面支持信号量:
降级:当Hystrix获取降级返回时,总是在调用容器线程上进行
执行:如果将execution.isolaiton.strategy设置为SEMOPHORE,则将采用信号量作为限制并发数的方法。
上述两个方面均可以通过动态参数的方式实现配置,来实现对并发线程数的限制。限制数的大小和线程池大小的估计方法类似。
注意:如果一个外部依赖时通过信号量的方式隔离的,并且发生了延迟,则父线程将同样保持阻塞,直至调用超时或者返回。
信号量并发数限制将会在达到后立即生效,但是已经阻塞的线程将继续保持阻塞,不能提前返回。
请求合并
可以在HystrixCommand前置一个collapser,来实现对多个请求对应的后台服务调用的合并。
下图是采用和不采用请求合并的服务调用的示意图。
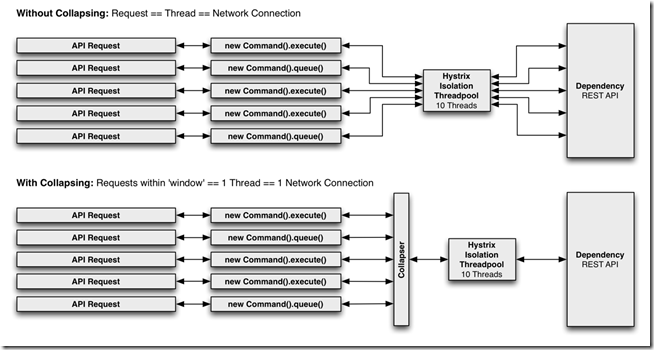
为什么采用请求合并?
在并发请求下,使用请求合并主要用来降低并发的线程数及网络连接数。Hystrix采用自动的方式来完成请求合并,不需要开发者显示执行请求合并操作。
全局上下文
理想的合并应该是应用全局级别的,这样容器内所有用户的请求均合一被合并。
例如,如果对请求电影排行的一个服务做了请求合并配置,那么同一个JVM内的所有请求,都将别Hystrix合并到一个网络调用中。
需要注意的是,collapser会通过网络调用向下游系统发送一个HystrixRequestContext,下游系统必须能够正确处理这个context以便正确响应。
单用户请求上下文
Hystrix还支持基于单个用户态的线程对请求做合并,比如某用户线程请求300部电影的标签信息,Hystrix会将300各请求合并成一个。
关于对象模型及代码复杂度
有些时候当在客户端设计了一个符合业务逻辑的对象模型后,通常会发现,这个模型在有效利用服务端资源方面可能并不好。
例如,对于一个获取300各电影的各自标签的场景,逐个迭代调用标签获取服务是最简单的逻辑,但是这种设计会在短时间内发起300个后台的服务调用请求,容易造成资源的耗尽。
对于这种场景,有常见的解决方式,。例如,在用户视角做限制,在获取电影标签前,必须让用户限定获取标签的电影范围,而不是全部电影。或者,可以对对象模型做分解,可以首先调用一个服务获取电影信息列表,再针对这个列表请求属性信息。
显而易见,这些设计可能导致用户不友好的API设计或者不符合现实逻辑的模型设计。同时,在许多开发者协同开发的应用系统中,这些特殊的设计很有可能被其他开发者修改而失效。
Hystrix通过将请求合并下沉到实际应用逻辑以外,使得对象模型的特殊设计与否、服务调用的顺序特殊考虑与否都不会对应用造成显著影响,甚至开发者也不需要做太多额外的业务逻辑外的优化。
请求合并的代价是什么?
很明显,请求合并带来的额外消耗主要是执行合并带来的时间延迟。其最大值便是合并的时间窗口的最大值。
例如,有一个外部调用花费5ms,并且通过Hystrix对其做了时间窗口为10ms的合并,那么,最坏情况下,这个外部调用将可能花费15ms。但是,一般来讲,并不是所有请求都在窗口刚刚打开的那一刻进来,因此,实际上做请求合并带来的平均额外时间消耗是5ms。
是否做请求合并的关键是外部请求本身的特性。对于一个本身耗时很高的调用,对其做请求合并带来的额外时间影响可能微乎其微。同时,对外部服务的并发调用数也是关键。显然没有必要对一个并发是1或者2的外部调用做请求合并。
然而,对于并发很高的外部调用,例如在合并窗口内并发可以达到几十或者上百,则做请求合并带来的额外延时相比于过多的资源消耗调用是可以忽略的。
请求流程图
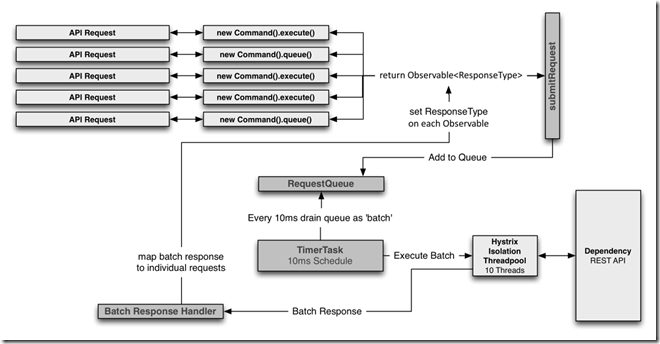
请求缓存
HystrixCommand和HystrixObservableCommand的实现可以针对并发场景下的请求定义缓存key,来减少后续的实际网络请求。
下图展示了一个HTTP请求的生命周期及两个执行该请求的线程:
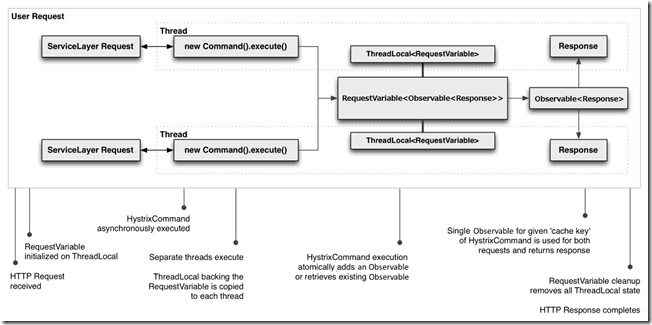
请求缓存的主要优势在于:
- 不同的代码路径都可以执行Hystrix command,而不用担心重复工作。
这在较大的团队中带来的好处通常更加明显。例如,对于获取用户账户的服务调用,多处代码都可能这样写:
Account account = new UserGetAccount(accountId).execute(); //or Observable<Account> accountObservable = new UserGetAccount(accountId).observe();
Hystrix的RequestCache将仅执行一次run()方法,所有执行HystrixCommand的线程都将得到相同的返回结果,尽管他们完全不同的线程实例。
- 整个请求中得到的数据都是一致的
当第一个返回被缓存后,在同一个请求中,后续的command执行的返回都将是一致的。
- 消除了重复的线程执行
Request cache位于执行run()或者executed()方法之前,因此可以消除实际执行调用带来的重复线程执行消耗。
【Reference】
https://github.com/Netflix/Hystrix/wiki/How-it-Works
[翻译]Hystrix wiki–How it Works的更多相关文章
- [翻译]Hystrix wiki–Home
注:本文并非是精确的文档翻译,而是根据自己理解的整理,有些内容可能由于理解偏差翻译有误,有些内容由于是显而易见的,并没有翻译,而是略去了.本文更多是学习过程的产出,请尽量参考原官方文档. 什么是Hys ...
- PHP经验——PHPDoc PHP注释的标准文档(翻译自Wiki)
文档注释,无非“//”和“/**/”两种 ,自己写代码,就那么点,适当写几句就好了:但是一个人总有融入团队的一天,团队的交流不是那几句注释和一张嘴能解决的,还需要通用的注释标准. PHPDoc是PHP ...
- 翻译:wiki中的business logic词条
Business logic 业务逻辑 From Wikipedia, the free encyclopedia 来自Wikipedia,自由的百科全书 In computer software, ...
- 翻译wiki(一):Bios boot partition
文章翻译自wiki,水平有限,若有错万请见谅.原文:https://en.wikipedia.org/wiki/BIOS_boot_partition BIOS boot partition是一个分区 ...
- How Hystrix Works?--官方
https://github.com/Netflix/Hystrix/wiki/How-it-Works Contents Flow Chart Circuit Breaker Isolation T ...
- 【附1】hystrix详述(1)
一.hystrix的作用 控制被依赖服务的延时和失败 防止在复杂系统中的级联失败 可以进行快速失败(不需要等待)和快速恢复(当依赖服务失效后又恢复正常,其对应的线程池会被清理干净,即剩下的都是未使用的 ...
- 【第十九章】 springboot + hystrix(1)
hystrix是微服务中用于做熔断.降级的工具. 作用:防止因为一个服务的调用失败.调用延时导致多个请求的阻塞以及多个请求的调用失败. 1.pom.xml(引入hystrix-core包) 1 < ...
- 附1 hystrix详述(1)
一.hystrix的作用 控制被依赖服务的延时和失败 防止在复杂系统中的级联失败 可以进行快速失败(不需要等待)和快速恢复(当依赖服务失效后又恢复正常,其对应的线程池会被清理干净,即剩下的都是未使用的 ...
- 第十九章 springboot + hystrix(1)
hystrix是微服务中用于做熔断.降级的工具. 作用:防止因为一个服务的调用失败.调用延时导致多个请求的阻塞以及多个请求的调用失败. 1.pom.xml(引入hystrix-core包) <! ...
随机推荐
- C++中long是什么类型
long long本质上还是整型,只不过是一种超长的整型. int型:32位整型,取值范围为-2^31 ~ (2^31 - 1) .long:在32位系统是32位整型,取值范围为-2^31 ~ (2^ ...
- 第四次工业革命:人工智能(AI)入门
转载自 http://www.infoq.com/cn/articles/the-fourth-industrial-revolution-an-introduction-to-ai "过去 ...
- mac phpstrom 环境配置
因为mac下自带php,但是没有环境(ini文件)所有需要自己重新安装一下: curl -s http://php-osx.liip.ch/install.sh | bash -s 5.5 # 5.5 ...
- Data Flow ->> OLE DB Destination ->> Fast Load
OLE DB Destination组件提供了fast load选项,用bulk模式load数据而不是row-to-row的模式.这样性能上好.但是需要注意一点就是,一旦用了fast load,err ...
- Studying TCP's Throughput and Goodput using NS
Studying TCP's Throughput and Goodput using NS What is Throughput Throughput is the amount of data r ...
- JAVA程序员常用开发工具
1.JDK (Java Development Kit)Java开发工具集 SUN的Java不仅提了一个丰富的语言和运行环境,而且还提了一个免费的Java开发工具集(JDK).开发人员和最终用户可以利 ...
- 一个较复杂的执行redis的lue脚本
- 用jquery实现的简单数据双向绑定
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- [19/04/08-星期一] 多线程_线程的优先级(Priority) 和 守护线程(Daemon)
一.概念 1. 处于就绪状态的线程,会进入“就绪队列”等待JVM来挑选. 2. 线程的优先级用数字表示,范围从1到10,一个线程的缺省优先级是5. 3. 使用下列方法获得或设置线程对象的优先级. in ...
- shiro简单入门介绍
shiro是apache的一个java安全框架 可以完成认证,授权,加密,会话管理,基于web继承,缓存等 功能简介: 从外部来看: shiro架构 Subject:主体,代表了当前“用户”,这个用 ...