Python学习笔记 - day14 - Celery异步任务
Celery概述
关于celery的定义,首先来看官方网站:
Celery(芹菜) 是一个简单、灵活且可靠的,处理大量消息的分布式系统,并且提供维护这样一个系统的必需工具。
简单来看,是一个基于python开发的分布式异步消息任务队列,持使用任务队列的方式在分布的机器、进程、线程上执行任务调度。通过它可以轻松的实现任务的异步处理, 如果你的业务场景中需要用到异步任务,就可以考虑使用celery, 举几个实例场景中可用的例子:
- 你想对100台机器执行一条批量命令,可能会花很长时间 ,但你不想让你的程序等着结果返回,而是给你返回 一个任务ID,你过一段时间只需要拿着这个任务id就可以拿到任务执行结果, 在任务执行ing进行时,你可以继续做其它的事情。
- 你想做一个定时任务,比如每天检测一下你们所有客户的资料,如果发现今天 是客户的生日,就给他发个短信祝福 。
Celery 在执行任务时需要通过一个中间人(消息中间件)来接收和发送任务消息,以及存储任务结果,完整的中间人列表请查阅官方网站
PS:任务队列是一种在线程或机器间分发任务的机制。
PS:消息队列的输入是工作的一个单元,称为任务,独立的工作(Worker)进程持续监视队列中是否有需要处理的新任务。
Celery简介
Celery 系统可包含多个职程和中间人,以此获得高可用性和横向扩展能力,其基本架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
- 消息中间件,Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成,一般使用rabbitMQ or Redis,当然其他的还有MySQL以及Mongodb。
- 任务执行单元,Worker是Celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中。
- 任务结果存储,Task result store用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括Redis,MongoDB,Django ORM,AMQP等。
Celery的主要特点:
- 简单:一单熟悉了celery的工作流程后,配置和使用还是比较简单的
- 高可用:当任务执行失败或执行过程中发生连接中断,celery 会自动尝试重新执行任务
- 快速:一个单进程的celery每分钟可处理上百万个任务
- 灵活: 几乎celery的各个组件都可以被扩展及自定制
Celery基本工作流程图
根据前面的介绍,我们可以得出如下流程图:
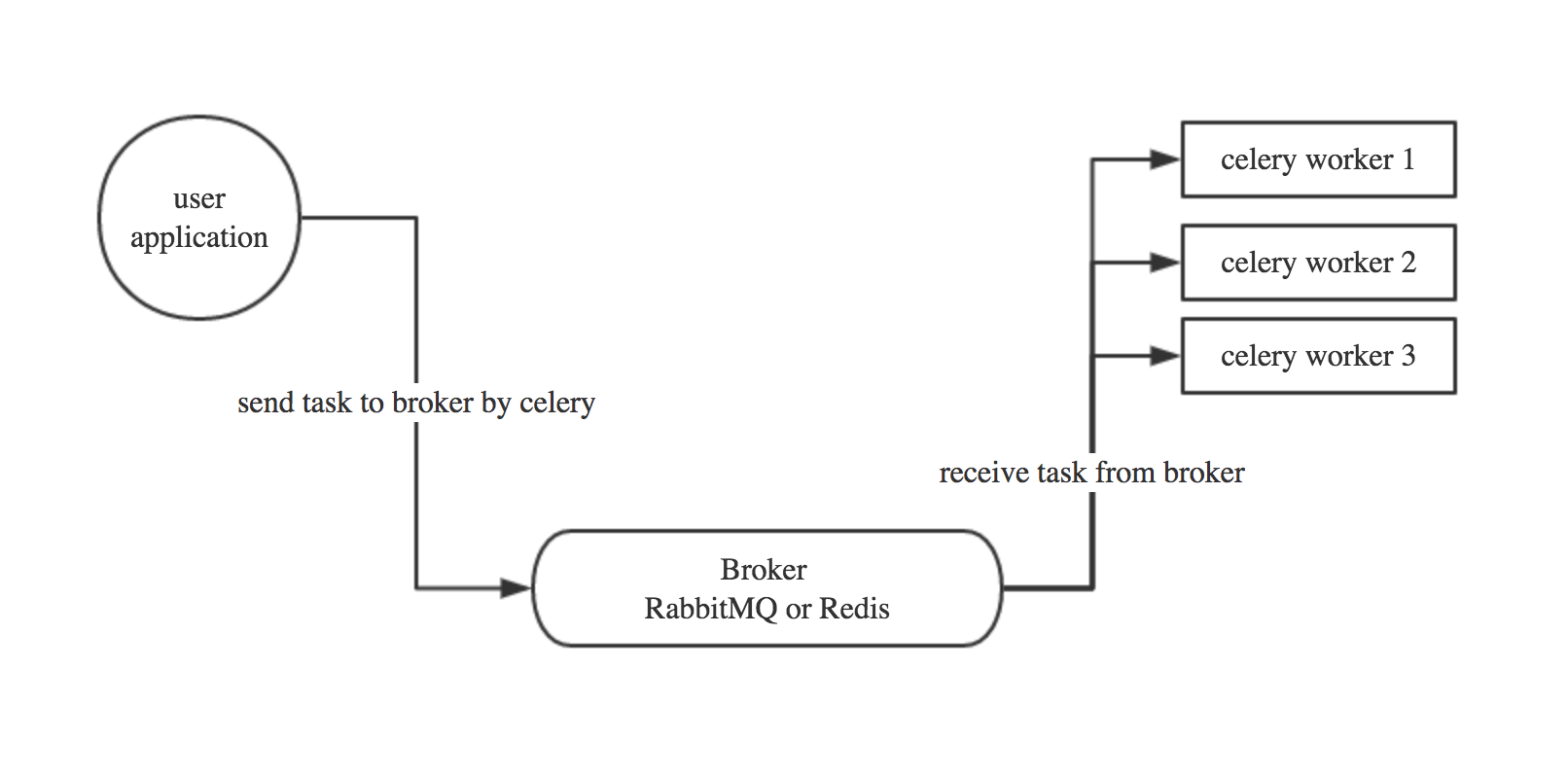
1、用户应用程序讲任务通过celery放入Broker中。
2、多个worker通过Broker获取任务并执行。
3、worker执行完成后,会把任务的结果、状态等信息返回到Broker中存储,供用户程序读取。
PS:Celery 用消息通信,通常使用中间人(Broker)在客户端和职程间斡旋。这个过程从客户端向队列添加消息开始,之后中间人把消息派送给职程。
Celery模块的基本使用
要使用Celery需要先安装celery模块,下面的例子使用Python3进行举例。
# 利用pip3命令安装celery模块
pip3 install celery # 测试是否成功安装
[root@namenode ~]# python3
Python 3.6.4 (default, Dec 21 2017, 17:26:43)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-16)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import celery # 没有报错表示模块安装正常
>>>
PS:如果你是编译安装的Python3,执行以上步骤后不一定代表正确安装,还需要在命令行下执行celery命令,如果报错请参考这篇文章:Python3安装Celery模块后执行Celery命令报错。
Celery初探
下面的例子使用redis作为消息中间人的角色。
创建一个celery application
用来定义任务列表,这里任务文件的名称叫做task.py(注意后面会用到文件名)。
from celery import Celery
app = Celery('task', # 是当前模块的名称,这个参数是必须的,这样的话名称可以自动生成
broker="redis://10.0.0.3:6379/0", # 中间人的地址
backend="redis://10.0.0.3:6379/1" # 结果数据存放地址
)
@app.task # 使用celery标识一个任务,多个任务都需要使用该装饰器
def add(x,y):
return x+y
# rabbitmq
broker = 'amqp://user:password@ip:5672//' # redis
broker = 'redis://passwordf@ip:6379/db'
其他中间人配置方法
运行一个worker
当然这里可以执行多个worker,在命令行下执行
celery -A task worker --loglevel=debug # -A参数表示的是Celery APP的名称,task就是APP的名称(应用文件名)
# worker表示是一个执行任务角色
# loglevel=info记录日志类型默认是info。
[2017-12-22 15:34:36,819: INFO/MainProcess] Received task: task.add[b881bbea-e729-444e-9efd-434fa6e43f57]
[2017-12-22 15:34:46,828: INFO/ForkPoolWorker-1] Task task.add[b881bbea-e729-444e-9efd-434fa6e43f57] succeeded in 10.008738335978705s: 3 # 从上面日志可以看到,当worker从中间人那获取任务后,会生成一个task ID,这里我们和之前发送任务返回的AsyncResult对比我们发现,每个task都有一个唯一的ID,第二行说明了这个任务执行succeed,执行结果为3。
Celery worker启动后info日志信息
发布(调用)任务
这里在task.py所在的目录调用Python解释器执行,这样可以方便的引入这个app。
>>> from task import add
>>> add.delay(4, 4) # 使用 delay() 方法来调用任务,这是 apply_async() 方法的快捷方式,该方法允许你更好地控制任务执行(异步执行)。
# 这个任务已经由之前启动的职程(worker)执行,可以查看职程的控制台输出来验证。
PS:调用任务会返回一个 AsyncResult 实例,可用于检查任务的状态,等待任务完成或获取返回值(如果任务失败,则为异常和回溯)。 但这个功能默认是不开启的,需要设置一个 Celery 的结果后端(配置了backend才会生效)。
PS:通过检查redis的数据也可以查看结果信息
[root@namenode python]# redis-cli
127.0.0.1:6379[1]> keys *
1) "celery-task-meta-31f2f75d-20d9-4bb6-8b04-079ef65afbab"
2) "celery-task-meta-334f0e9b-87f6-461a-a068-571bd3773691"
3) "celery-task-meta-57bb002b-017d-43bc-a88a-6d470a9dfe95"
4) "celery-task-meta-05161a38-3fd9-4be1-bae9-dc674d30296c"
5) "celery-task-meta-bb12d773-686c-4bc0-91de-747a33bae666"
6) "celery-task-meta-2349b371-8e29-4af1-911c-ebc322708190"
7) "celery-task-meta-b881bbea-e729-444e-9efd-434fa6e43f57"
8) "celery-task-meta-a208ad2f-f90e-4c90-9d02-5fb4419f5002"
9) "celery-task-meta-22e84e77-a416-45bb-b605-a6790318f860"
10) "celery-task-meta-18e39c21-5699-4b5a-9696-aa1fa77126d6"
11) "celery-task-meta-6642c643-a6fc-4701-b485-7dcbee0464a5"
12) "celery-task-meta-4b1a4158-e4e5-4865-b654-aec3c2ea1085"
13) "celery-task-meta-1c8beef9-56c8-4065-a33c-760f053a2f6a"
14) "celery-task-meta-faae55de-8476-4b5d-9dd9-ae131e81750f"
15) "celery-task-meta-35fd65e9-9ad4-41be-ac83-ff3b17941843"
16) "celery-task-meta-6bdd80e4-5237-47a1-9d2f-0d248eb6b03b"
17) "celery-task-meta-cddbc105-ce52-4d30-bab0-2114749dcf99"
127.0.0.1:6379[1]> get celery-task-meta-cddbc105-ce52-4d30-bab0-2114749dcf99
"{\"status\": \"SUCCESS\", \"result\": 4, \"traceback\": null, \"children\": [], \"task_id\": \"cddbc105-ce52-4d30-bab0-2114749dcf99\"}"
127.0.0.1:6379[1]> # 可以看到有很多celery任务执行的结果
# 使用get 就可以查看存储的信息(类型为string)
redis结果信息
AsyncResult 实例常用方法
通过获取异步执行对象的返回值来获取AsyncResult实例对象
[root@namenode python]# python3
Python 3.6.4 (default, Dec 21 2017, 17:26:43)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-16)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from task import add
>>> add.delay(4,5) # 返回一个 result对象
<AsyncResult: 18e39c21-5699-4b5a-9696-aa1fa77126d6>
>>> result = add.delay(4,5) # 定义变量接受
ready() 方法查看任务是否完成处理
>>> result.ready()
True
# 对象有两个结果:True/False 表示 完成/未完成
get() 等待任务完成,但这很少使用,因为它把异步调用变成了同步调用
>>> result.get(timeout=1) # 不加timeout参数会同步等待
9
>>> # timeout 表示超时时间,如果在1秒内没有返回会报异常
# celery.exceptions.TimeoutError: The operation timed out.
# 倘若任务抛出了一个异常, get() 会重新抛出异常。
# 使用 propagate 参数美化 get 抛出的异常信息
# 程序抛出的异常,get也会打印,使用propagate=False来美化输出 >>> result.get(propagate=False)
>>> NameError("name 'name' is not defined",)
# 我们在worker中引用了一个位置的变量name,使用propagate后显示的结果更优雅
利用propagate美化get异常输出
PS:如果celery没有配置backend,那么执行get方法将会异
traceback 获取原始的回溯信息
>>> r.traceback
'Traceback (most recent call last):\n File "/usr/local/python3/lib/python3.6/site-packages/celery/app/trace.py", line 374, in trace_task\n R = retval = fun(*args, **kwargs)\n File "/usr/local/python3/lib/python3.6/site-packages/celery/app/trace.py", line 629, in __protected_call__\n return self.run(*args, **kwargs)\n File "/root/python/task.py", line 13, in add\n print(name)\nNameError: name \'name\' is not defined\n'
>>>
task_id 获取任务的任务id
>>> r.task_id
'd1180279-58f3-4c30-afd6-73008191156e'
在项目中使用Celery
在项目中,把配置信息和程序代码写在一起,是一件很low的事请,所以在项目中我们一般会使用配置文件的方式,来对之前的基本使用方式进行拆分
celery应用
即单独把celery任务做成一个单独的应用。
我的celery应用名称为appcelery,目录结构如下:
appcelery/
|-- celery.py
|-- __init__.py
`-- tasks.py
PS:celery的配置文件命名必须为celery,否则提示无法导入,不知道为啥,这里就先按照celery来命名。
配置及worker代码如下:
# ---------------------- celery.py ---------------------- from __future__ import absolute_import # 绝对导入,保证不会覆盖celery模块 from celery import Celery app = Celery(
'appcelery', # 项目名称
broker='redis://10.0.0.3:6379/0',
backend='redis://10.0.0.3:6379/1',
include=['appcelery.tasks'] # 包含的worker配置(注意格式:项目名.任务名)
) app.conf.update( # 利用conf.update配置其他参数
result_expires=3600, # 设置worker返回的结果在redis中保存的时间
) if __name__ == '__main__':
app.start() # ---------------------- tasks.py ---------------------- from .celery import app # 导入应用 @app.task
def add(x,y):
return x + y @app.task
def minus(x,y):
return x - y
后台启动多进程celery work
前面的启动方法一次只能启动一个,会在前台显示并打印日志,终端退出,那么celery进程也会退出,当然我们可以使用&来进行后台启动,日志可以使用-q来禁止输出,但是这毕竟不是最佳方法,官方提供了多进程后台的启动方式利用 celery multi 启动
# 后台启动 celery worker进程 celery multi start work_1 -A appcelery # work_1 为woker的名称,可以用来进行对该进程进行管理
其他常用参数
celery其他的常用于管理worker的参数有很多,可以使用celery -h来查看。
[root@namenode celerymodule]# celery
usage: celery <command> [options] Show help screen and exit. positional arguments:
args optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit Global Options:
-A APP, --app APP
-b BROKER, --broker BROKER
--loader LOADER
--config CONFIG
--workdir WORKDIR
--no-color, -C
--quiet, -q
celery命令帮助文档
其他参数举例:
# 多进程相关
celery multi stop WOERNAME # 停止worker进程,有的时候这样无法停止进程,就需要加上-A 项目名,才可以删掉
celery multi restart WORKNAME # 重启worker进程 # 查看进程数
celery status -A celery # 查看该项目运行的进程数
测试
这里还是用python解释器进行测试
# 为了导入方便,这里在appcelery同级目录下 执行python解释器
[root@namenode celerymodule]# ls
appcelery __pycache__ task.py [root@namenode celerymodule]# python3
Python 3.6.4 (default, Dec 25 2017, 17:45:03)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-16)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from appcelery import tasks # 相对导入
>>> tasks.add.delay(1,2) # 执行任务
<AsyncResult: bc90bfa6-7972-4679-b897-4f5a98c70ae0>
>>>
在redis中查看key的过期时间
[root@namenode celerymodule]# redis-cli
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> keys *
1) "celery-task-meta-1c8372d7-3d98-4a23-999d-1f07a6b12966" 127.0.0.1:6379[1]> ttl celery-task-meta-1c8372d7-3d98-4a23-999d-1f07a6b12966
(integer) 3580 # 过期时间已更改
127.0.0.1:6379[1]>
Celery的定时任务
celery支持定时任务,设定好任务的执行时间,celery就会定时自动帮你执行, 这个定时任务模块叫celery beat,类似于Linux中的crontab。主要有两种类型:每隔多久执行一次或者定期执行。
由于是定期执行,所以celery的定时任务主要有两类进程,即完成任务的worker进程和分发任务的beat进程。
定时任务程序
from celery import Celery
from celery.schedules import crontab app = Celery('celeryperiodoc',
broker="redis://10.0.0.3:6379/0",
backend="redis://10.0.0.3:6379/1"
) @app.on_after_configure.connect # 定时任务必须要用的装饰器
def setup_periodic_tasks(sender, **kwargs): # sender是必须传递的参数,类似于django的requests一样
# Calls test('hello') every 10 seconds.
sender.add_periodic_task(10.0, test.s('hello'), name='add every 10') # 添加一个定时任务,10.0表示每隔10秒,test.s表示给test函数传递的参数,name表示任务名称 # Calls test('world') every 30 seconds
sender.add_periodic_task(30.0, test.s('world'), expires=10) # Executes every Thureday at 19:52 p.m.
sender.add_periodic_task(
crontab(hour=19, minute=52,day_of_week='thu'), # 利用crontab设定定时执行
test.s('Happy Mondays!'),
) @app.task
def test(arg):
print(arg)
启动一个beat进程:celery -A celeryperiodic beat
[root@namenode celerymodule]# celery -A celeryperiodoc beat
celery beat v4.1.0 (latentcall) is starting.
__ - ... __ - _
LocalTime -> 2017-12-26 20:13:54
Configuration ->
. broker -> redis://10.0.0.3:6379/0
. loader -> celery.loaders.app.AppLoader
. scheduler -> celery.beat.PersistentScheduler
. db -> celerybeat-schedule
. logfile -> [stderr]@%WARNING
. maxinterval -> 5.00 minutes (300s)
启动beat进程
启动一个worker进程: celery -A celeryperiodic worker
日志结果
[2017-12-26 20:24:14,267: INFO/MainProcess] Received task: celeryperiodoc.test[641d0e17-ff26-4791-acca-8c0cce8d6709]
[2017-12-26 20:24:14,269: WARNING/ForkPoolWorker-1] hello
[2017-12-26 20:24:14,276: INFO/ForkPoolWorker-1] Task celeryperiodoc.test[641d0e17-ff26-4791-acca-8c0cce8d6709] succeeded in 0.007056772010400891s: None [2017-12-26 20:24:24,269: INFO/MainProcess] Received task: celeryperiodoc.test[25b3ea6a-0405-4431-a1e1-840f5dbdc57e] expires:[2017-12-26 12:24:34.266983+00:00]
[2017-12-26 20:24:24,270: WARNING/ForkPoolWorker-1] world
[2017-12-26 20:24:24,271: INFO/ForkPoolWorker-1] Task celeryperiodoc.test[25b3ea6a-0405-4431-a1e1-840f5dbdc57e] succeeded in 0.0009060979355126619s: None [2017-12-26 20:24:24,271: INFO/MainProcess] Received task: celeryperiodoc.test[b5dce374-4596-4282-987a-494e2ede365c]
[2017-12-26 20:24:24,273: WARNING/ForkPoolWorker-1] hello
[2017-12-26 20:24:24,273: INFO/ForkPoolWorker-1] Task celeryperiodoc.test[b5dce374-4596-4282-987a-494e2ede365c] succeeded in 0.0006978920428082347s: None [2017-12-26 20:24:34,270: INFO/MainProcess] Received task: celeryperiodoc.test[1a67a24a-0348-416d-a4c0-fc033108cda1]
[2017-12-26 20:24:34,271: WARNING/ForkPoolWorker-1] hello
[2017-12-26 20:24:34,272: INFO/ForkPoolWorker-1] Task celeryperiodoc.test[1a67a24a-0348-416d-a4c0-fc033108cda1] succeeded in 0.0008945289300754666s: None [2017-12-26 20:24:44,272: INFO/MainProcess] Received task: celeryperiodoc.test[e6853e92-9c42-4c49-8148-5d575268f3a7]
[2017-12-26 20:24:44,273: WARNING/ForkPoolWorker-1] hello
[2017-12-26 20:24:44,274: INFO/ForkPoolWorker-1] Task celeryperiodoc.test[e6853e92-9c42-4c49-8148-5d575268f3a7] succeeded in 0.0009920489974319935s: None # 观察hello的输出间隔,发现是每隔10秒输出一次
# 观察world的输出间隔,可以看出是每隔30秒输出一次
其他
执行完毕后会在当前目录下产生一个二进制文件,celerybeat-schedule 。
该文件用于存放上次执行结果:
1、如果存在celerybeat-schedule文件,那么读取后根据上一次执行的时间,继续执行。
2、如果不存在celerybeat-schedule文件,那么会立即执行一次。
3、如果存在celerybeat-schedule文件,读取后,发现间隔时间已过,那么会立即执行。
Python学习笔记 - day14 - Celery异步任务的更多相关文章
- 【目录】Python学习笔记
目录:Python学习笔记 目标:坚持每天学习,每周一篇博文 1. Python学习笔记 - day1 - 概述及安装 2.Python学习笔记 - day2 - PyCharm的基本使用 3.Pyt ...
- python学习笔记整理——字典
python学习笔记整理 数据结构--字典 无序的 {键:值} 对集合 用于查询的方法 len(d) Return the number of items in the dictionary d. 返 ...
- VS2013中Python学习笔记[Django Web的第一个网页]
前言 前面我简单介绍了Python的Hello World.看到有人问我搞搞Python的Web,一时兴起,就来试试看. 第一篇 VS2013中Python学习笔记[环境搭建] 简单介绍Python环 ...
- python学习笔记之module && package
个人总结: import module,module就是文件名,导入那个python文件 import package,package就是一个文件夹,导入的文件夹下有一个__init__.py的文件, ...
- python学习笔记(六)文件夹遍历,异常处理
python学习笔记(六) 文件夹遍历 1.递归遍历 import os allfile = [] def dirList(path): filelist = os.listdir(path) for ...
- python学习笔记--Django入门四 管理站点--二
接上一节 python学习笔记--Django入门四 管理站点 设置字段可选 编辑Book模块在email字段上加上blank=True,指定email字段为可选,代码如下: class Autho ...
- python学习笔记--Django入门0 安装dangjo
经过这几天的折腾,经历了Django的各种报错,翻译的内容虽然不错,但是与实际的版本有差别,会出现各种奇葩的错误.现在终于找到了解决方法:查看英文原版内容:http://djangobook.com/ ...
- python学习笔记(一)元组,序列,字典
python学习笔记(一)元组,序列,字典
- Pythoner | 你像从前一样的Python学习笔记
Pythoner | 你像从前一样的Python学习笔记 Pythoner
随机推荐
- chrome extensions & debug
chrome extensions & debug debug background.js debug popup.js debug content_script.js chrome.stor ...
- 【bzoj1692】[Usaco2007 Dec]队列变换 贪心+后缀数组
题目描述 FJ打算带他的N(1 <= N <= 30,000)头奶牛去参加一年一度的“全美农场主大奖赛”.在这场比赛中,每个参赛者都必须让他的奶牛排成一列,然后领她们从裁判席前依次走过. ...
- openstack中间件message queue 与memcached环境部署
为什么要安装中间件 组件间的通信使用的是REST API 而组件内部之间的通信则是使用的中间件 首先登陆openstack的官网查看官方文档 www.openstack.org 应为在部署一个架构之前 ...
- BZOJ5190 Usaco2018 Jan Stamp Painting(动态规划)
可以大胆猜想的一点是,只要有不少于一个长度为k的颜色相同子串,方案就是合法的. 直接算有点麻烦,考虑减去不合法的方案. 一个正(xue)常(sha)的思路是枚举序列被分成的段数,问题变为用一些1~k- ...
- 【原创】Oracle Not In 导致有存在Null的数据被过滤
解决方法: WHERE NVL(ID,) NOT IN ('') 注:红字部分不相等就可以
- 【以前的空间】poj 2288 Islands and Bridges
一个不错的题解 : http://blog.csdn.net/accry/article/details/6607703 这是一道状态压缩.每个点有一个值,我们最后要求一个最值sum.sum由三部分组 ...
- POJ3264:Balanced Lineup——题解+st表解释
我早期在csdn的博客之一,正好复习st表就拿过来.http://write.blog.csdn.net/mdeditor#!postId=63713810 这道题其实本身不难(前提是你得掌握线段树或 ...
- [LOJ10186]任务安排
link 试题分析 一道斜率优化的dp 易得方程$f[j]=(S+t[i])\times c[j]+f[i]-t[i]\times c[i]+s\times c[n]$,为什么要写成这要,因为这样其实 ...
- NDK plugin来构建JNI项目(相对于手动构建)
http://blog.csdn.net/codezjx/article/details/8879670 1.添加ndk环境支持 Android Tools -> Add Native Supp ...
- Javascript计算世界完全对称日
今天是 2011-11-02 日,微博啊.G+啊什么的都传是世界完全对称日,还说是多少年一遇的.下面写个 JavaScript 小程序,看看是否真的N年一遇.计算范围在公元2000年到3000年. 名 ...