2017-2018-1 20179205《Linux内核原理与设计》第八周作业
《Linux内核原理与设计》第八周作业
视频学习及操作分析
预处理、编译、链接和目标文件的格式
可执行程序是怎么来的?
以C语言为例,经过编译器预处理、编译成汇编代码、汇编器编译成目标代码,然后链接成可执行文件,再将可执行程序加载到内存中执行,过程可以通过下图展示(其中预处理已省略):
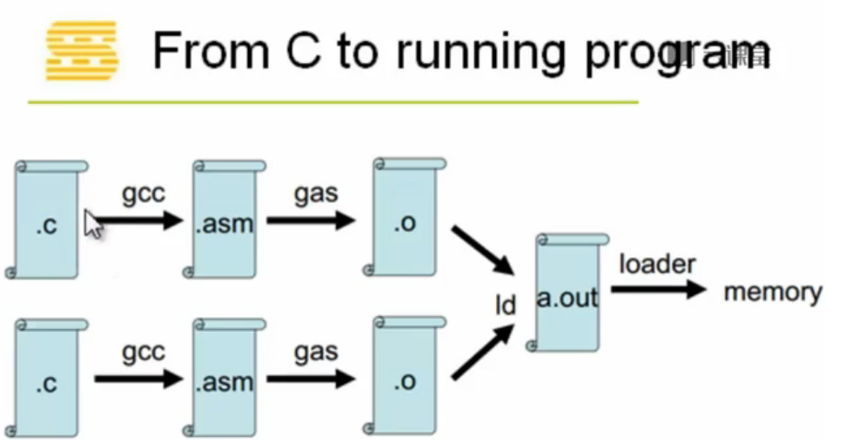
可执行文件的创建--预处理、编译和链接:
cd Code
vi hello.c
gcc –E –o hello.cpp hello.c –m32 //预处理,把include的文件包含进来及宏替换等工作
vi hello.cpp //cpp为预处理的中间文件
gcc -x cpp-output -S -o hello.s hello.cpp -m32 //编译成汇编代码
vi hello.s
gcc -x assembler -c hello.s -o hello.o -m32 //编译成目标代码
vi hello.o //得到二进制.o文件,ELF格式
gcc -o hello hello.o -m32 //链接成可执行文件hello
vi hello //也是二进制文件,ELF格式
gcc -o hello.static hello.o -m32 -static //静态编译,占用内存较大
ls -l
常见的目标文件格式,最古老的目标文件格式是A.out,然后发展成coff,现在我们常用的pe(windows系统运用较多)、elf(linux系统中应用较多)。ELF全称为EXECUTABLE AND LINKABLE FORMAT,即可执行和可链接模式,是一个文件格式的标准。目标文件我们一般也叫它ABI(应用程序二进制接口),实际上在目标文件里面它已经是二进制兼容的格式了,也就是说它这个目标文件已经是适应到某一种cpu体系结构上的二进制指令。比如说我们在一个32位x86编译出来的目标文件链接成ARM平台上的可执行文件肯定是不可以的。
elf文件格式中的三种主要目标文件:
1、一个可重定位(relocatable)文件保存着代码和适当的数据,用来和其他的object文件一起来创建一个可执行文件或者是一个共享文件。(主要是.o文件)
2、一个可执行(executable)文件保存着一个用来执行的程序;该文件指出了exec(BA_OS)如何来创建程序进程映象。
3、一个共享object文件保存着代码和合适的数据,用来被下面的两个链接器链接。第一个是连接编辑器[请参看ld(SD_CMD)],可以和其他的可重定位和共享object文件来创建其他的object。第二个是动态链接器,联合一个可执行文件和其他的共享object文件来创建一个进程映象。(主要是.so文件)
当创建或增加一个进程映像的时候,系统在理论上将拷贝一个文件的段到一个虚拟的内存段。如图可执行文件的格式和进程地址空间有一个映射关系:
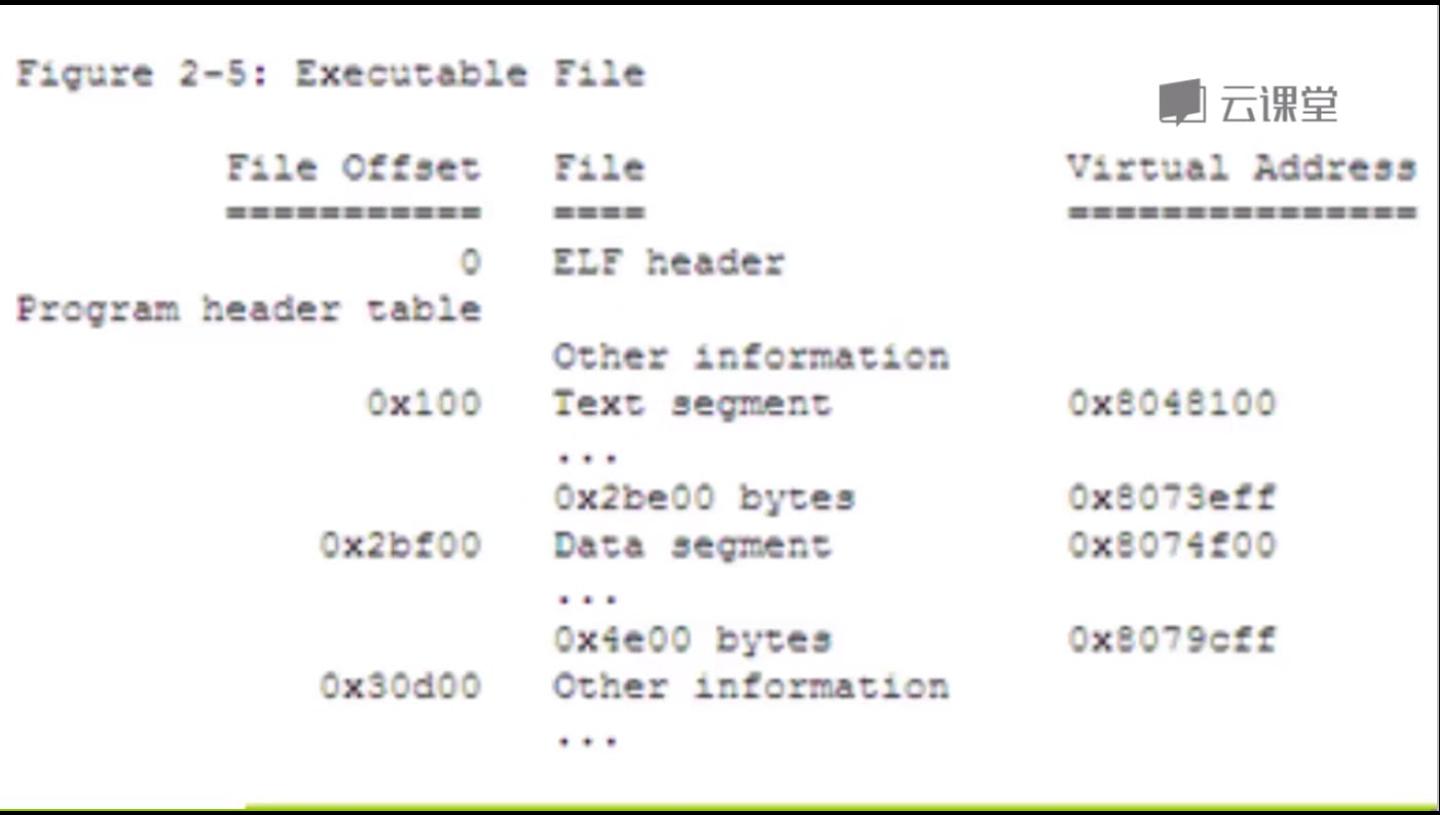
静态链接的ELF可执行文件与进程的地址空间的联系:

当elf文件加载到内存的时候,他把代码的数据加载到一块内存中来,其中有很多段代码。加载进来之后默认从0x8048000开始加载,前面是elf头部的一些信息,一般头部的大小会有不同,加载的入口点的位置可能是0x8048300,即程序的实际入口。当启动一个刚加载过可执行文件的进程的时候,开始执行的入口点。文件是一个elf的静态连接文件,链接的时候已经链接好了。从这(0x8048300)开始执行,压栈出栈,从main函数到结束,所有的链接在静态链接时候已经设定好了。正常需要用到共享库或动态链接的时候,情况会更复杂一点。
装载可执行程序之前,先了解一下可执行程序的执行环境。一般我们执行一个程序的shell环境,它本身不限制命令行参数的个数,命令行参数的个数受限于命令自身,比如 int main(int argc,char *argv[]) ,shell会调用execve将命令行参数和环境参数传递给可执行程序的main函数。命令行参数和环境串都放在用户态的堆栈中。Shell程序->execve -> sys_execve,然后在初始化新程序堆栈时拷贝进去。
可执行程序、共享库和动态加载
动态链接有可执行装载时的动态链接和运行时的动态链接,下面演示了两种动态链接:
共享库shilibexample.c实现SharedLibApi()函数:
#include <stdio.h>
#include "shlibexample.h"
/*
* Shared Lib API Example
* input : none
* output : none
* return : SUCCESS(0)/FAILURE(-1)
*
*/
int SharedLibApi()
{
printf("This is a shared libary!\n");
return SUCCESS;
}
shilibexample.h:
#ifndef _SH_LIB_EXAMPLE_H_
#define _SH_LIB_EXAMPLE_H_
#define SUCCESS 0
#define FAILURE (-1)
#ifdef __cplusplus
extern "C" {
#endif
/*
* Shared Lib API Example
* input : none
* output : none
* return : SUCCESS(0)/FAILURE(-1)
*
*/
int SharedLibApi();
#ifdef __cplusplus
}
#endif
#endif /* _SH_LIB_EXAMPLE_H_ */
通过gcc -shared shlibexaple.c -o libshlibexample.so -m32 编译成一个共享库文件,
下面是同样使用 gcc -shared dllibexample.c -o libdllibexample.so -m32 得到动态加载共享库。
其中dellibexample.c实现了DynamicalLoadingLibApi()函数:
#include <stdio.h>
#include "dllibexample.h"
#define SUCCESS 0
#define FAILURE (-1)
/*
* Dynamical Loading Lib API Example
* input : none
* output : none
* return : SUCCESS(0)/FAILURE(-1)
*
*/
int DynamicalLoadingLibApi()
{
printf("This is a Dynamical Loading libary!\n");
return SUCCESS;
}
dellibexample.h:
#ifndef _DL_LIB_EXAMPLE_H_
#define _DL_LIB_EXAMPLE_H_
#ifdef __cplusplus
extern "C" {
#endif
/*
* Dynamical Loading Lib API Example
* input : none
* output : none
* return : SUCCESS(0)/FAILURE(-1)
*
*/
int DynamicalLoadingLibApi();
#ifdef __cplusplus
}
#endif
#endif /* _DL_LIB_EXAMPLE_H_ */
main.c()函数:
#include <stdio.h>
#include "shlibexample.h"
#include <dlfcn.h>
/*
* Main program
* input : none
* output : none
* return : SUCCESS(0)/FAILURE(-1)
*
*/
int main()
{
printf("This is a Main program!\n");
/* Use Shared Lib */
printf("Calling SharedLibApi() function of libshlibexample.so!\n");
SharedLibApi();
/* Use Dynamical Loading Lib */
void * handle = dlopen("libdllibexample.so",RTLD_NOW);
if(handle == NULL)
{
printf("Open Lib libdllibexample.so Error:%s\n",dlerror());
return FAILURE;
}
int (*func)(void);
char * error;
func = dlsym(handle,"DynamicalLoadingLibApi");
if((error = dlerror()) != NULL)
{
printf("DynamicalLoadingLibApi not found:%s\n",error);
return FAILURE;
}
printf("Calling DynamicalLoadingLibApi() function of libdllibexample.so!\n");
func();
dlclose(handle);
return SUCCESS;
}
我们发现main函数中含有include "shlibexample.h" 以及include dlfcn,而没有include dllibexample(动态加载共享库)。当需要调用动态加载共享库时,使用定义在dlfcn.h中的dlopen。
最后通过 gcc main.c -o main -L/path/to/your/dir -lshlibexample -ldl -m32
接下来编译main()函数,注意这里只提供shlibexample的-L(库对应的接口头文件所在目录)和-l(库名,如libshlibexample.so去掉lib和.so的部分),并没有提供dllibexample的相关信息,只是指明了-ldl,然后我们继续执行:
$ export LD_LIBRARY_PATH=$PWD #将当前目录加入默认路径,否则main找不到依赖的库文件,当然也可以将库文件copy到默认路径下。
$ ./main
使用gdb跟踪sys_execve内核函数的处理过程
打开test.c文件:

可以发现增加了一句,MenuConfig("exec","Execute a program",Exec)
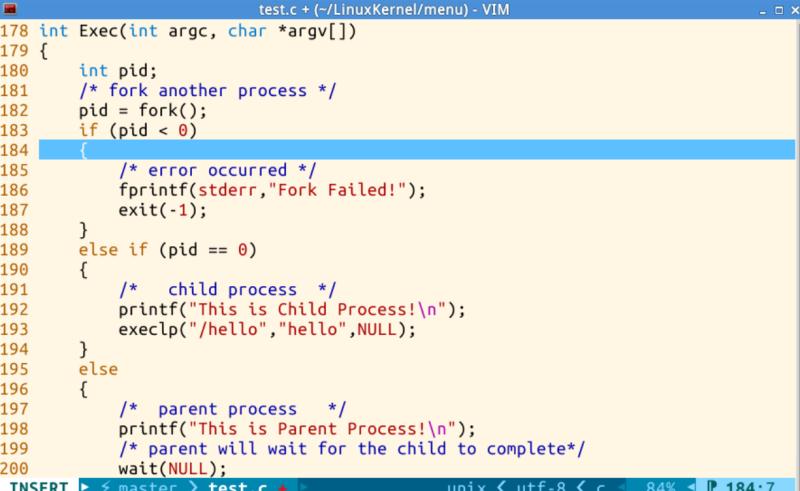
看一下这段代码,和fork()函数类似,增加了一个fork,子进程增加了一个execlp("/hello","hello",NULL); 启动hello,看一下hello.c:
看一下Makefile文件,静态的方式编译了hello.c,并在生成根文件系统时把init 和hello都放在rootfs里面:
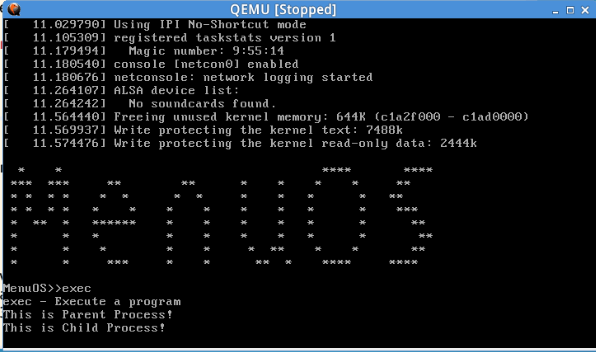
输入命令 make rootfs ,在qemu窗口中输入help 执行一下exec:
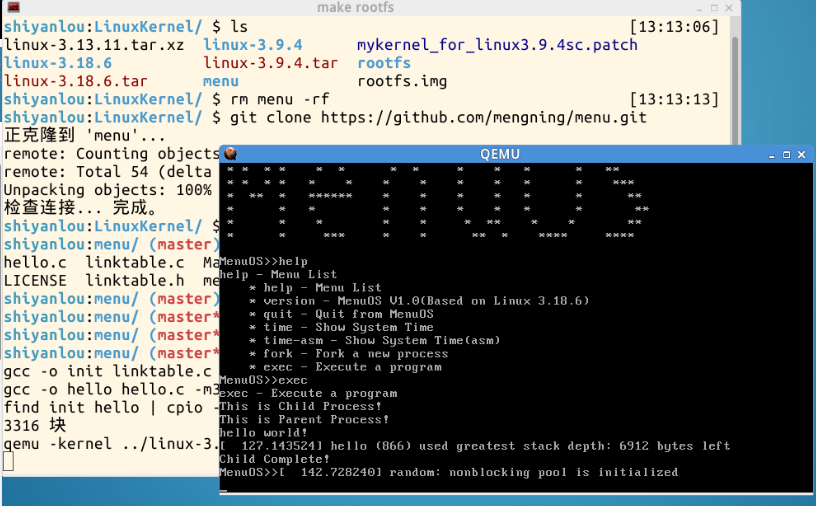
先cd .. 返回到上一级,qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S启动,水平分割,gdb
然后把符号表文件加载进来,gdb服务器使用默认端口号1234来连接,并通过gdb跟踪调试,设置断点,可以先停在sys_execve然后再设置其他断点:
按c执行:
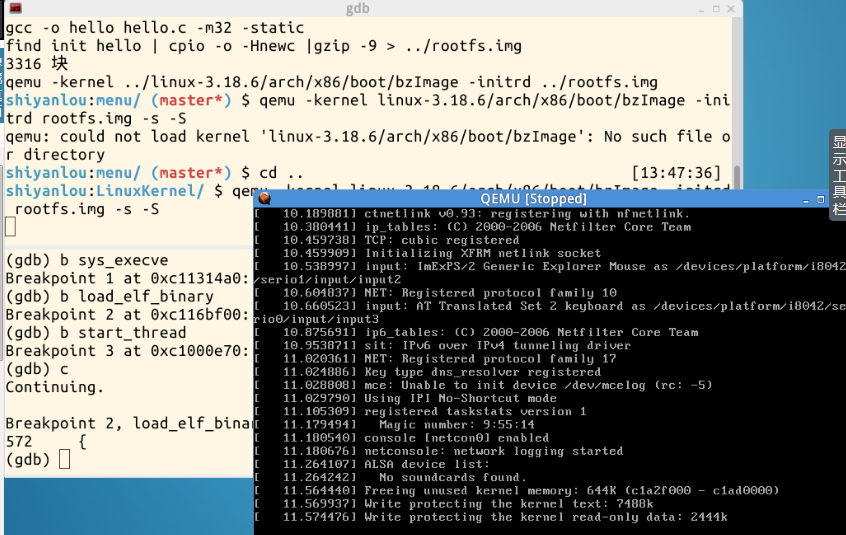
连续c执行三次,在menuos窗口输入exec,发现执行到 This is child process! 停下:
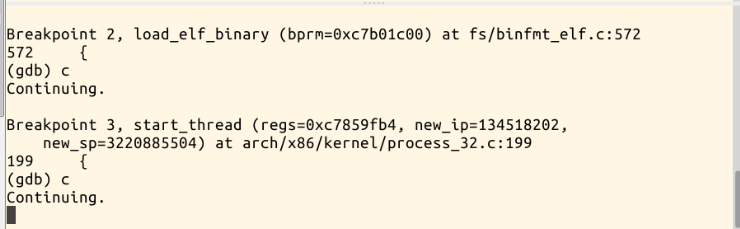
进入sys_execve系统调用,list列出来,跟踪:
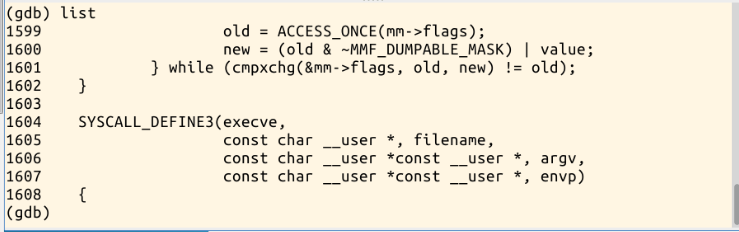
接下来通过s进入sys_execve内部
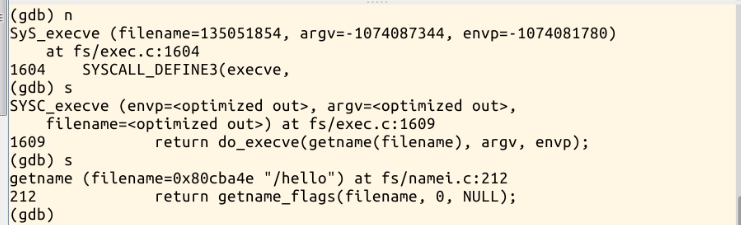
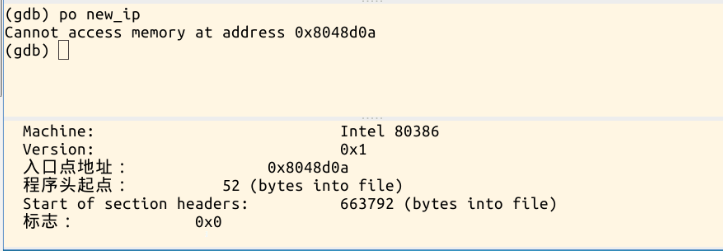
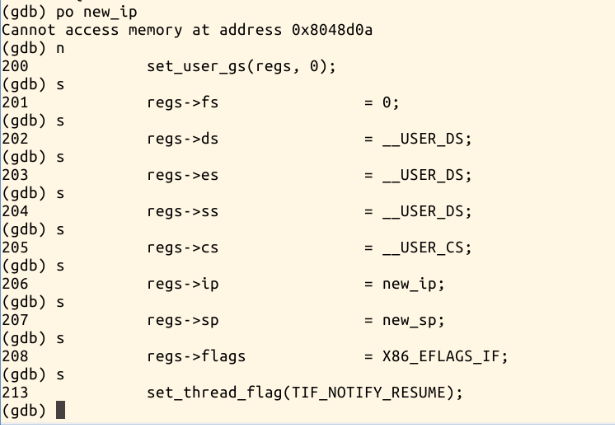
按c继续执行到load_elf_binary,list查看;再按c执行,执行到start_thread,想知道new_ip到底指向哪里,new_ip是返回到用户态的第一条指令的地址。再水平分割一个控制台出来,使用命令readelf -h hello,可以看到入口点地址和上面po new_ip所显示的地址一样:
然后我们继续执行s步骤,可以看到在进行修改内核堆栈的位置,发现原来压栈的ip和sp都被改成了新的ip(程序hello的入口点地址)和新的sp,这样在返回到用户态的时候程序就有一个新的可执行上下文环境。最后按一下c,exec的执行结束:
教材十三、十四章学习
1、虚拟文件系统(VFS)是Linux内核中的一个软件层,用于给用户空间的程序提供文件系统接口;同时,它也提供了内核中的一个抽象功能,允许不同的文件系统共存。系统中所有的文件系统不但依赖 VFS共存,而且也依靠VFS协同工作。一个实际的文件系统想要被Linux支持,就必须提供一个符合VFS标准的接口,才能与VFS协同工作,跨文件系统操作才能实现
2、VFS借助它四个主要的数据结构即超级块、索引节点、目录项和文件对象以及一些辅助的数据结构,向Linux中不管是普通的文件还是目录、设备、套接字等都提供同样的操作界面,如打开、读写、关闭等。只有当实际的文件系统有了控制权时,实际的文件系统才会做出区分,对不同的文件类型执行不同的操作。 所以我觉得“一切皆是文件”这句话的意思就是,不论是普通的文件,还是特殊的目录、设备等,VFS都将它们同等看待成文件,Linux都会提供同样的操作界面,这是不同于实际文件系统的根本。
3、文件是具有完整意义的信息项的系列,在Linux中,除了普通文件,其他诸如目录、设备、套接字等也以文件被对待;目录好比一个文件夹,用来容纳相关文件。因为目录可以包含子目录,所以目录是可以层层嵌套,形成 文件路径; 目录项在一个文件路径中,路径中的每一部分都被称为目录项;如路径/home/source/helloworld.c中,目录 /, home, source和文件 helloworld.c都是一个目录项;索引节点是用于存储文件的元数据的一个数据结构。文件的元数据,也就是文件的相关信息,和文件本身是两个不同的概念。它包含的是诸如文件的大小、拥有者、创建时间、磁盘位置等和文件相关的信息; 超级块用于存储文件系统的控制信息的数据结构。描述文件系统的状态、文件系统类型、大小、区块数、索引节点数等,存放于磁盘的特定扇区中。每次一个实际的文件系统被安装时, 内核会从磁盘的特定位置读取一些控制信息来填充内存中的超级块对象。一个安装实例和一个超级块对象一一对应,超级块通过其结构中的一个域s_type记录它所属的文件系统类型。
4、进程与超级块、文件、索引结点、目录项的关系
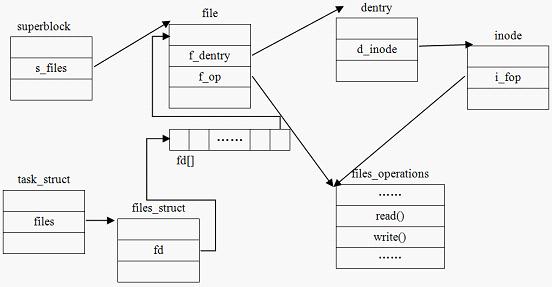
5、两种基本的设备类型,块设备和字符设备,它们的区别在于是否可以随机的访问数据。扇区是设备的最小寻址单元;块是文件系统的最小寻址单元,又称为文件块或者I/O块。缓冲区(buffer)是存放块的区域;缓冲头是存放内核处理数据时需要的一些相关信息的结构描述符(如块属于哪一个设备,块对应的是哪个缓冲区),描述符用buffer_head表示。Linus电梯能执行合并和排序预处理。新提交的请求和原有请求队列中的请求访问的扇区相邻,这种情况可以合并;没有合并的条件,但是有多个请求访问的扇区比较接近,通过将请求排序,可以使得磁头线性工作。
问题与分析:
VFS把一切都看为文件,提供同样的操作界面,跨文件系统的文件操作基本原理是什么?
比如说,将vfat格式的磁盘上的一个文件a.txt拷贝到ext3格式的磁盘上,命名为b.txt。这包含两个过程,对a.txt进行读操作,对b.txt进行写操作。读写操作前,需要先打开文件。由前面的分析可知,打开文件时,VFS会知道该文件对应的文件系统格式,以后操作该文件时,VFS会调用其对应的实际文件系统的操作方法。所以,VFS调用vfat的读文件方法将 a.txt的数据读入内存;在将a.txt在内存中的数据映射到b.txt对应的内存空间后,VFS调用ext3的写文件方法将b.txt写入磁盘;从而实现了最终的跨文件系统的复制操作。
参考网址:Linux的虚拟文件系统
2017-2018-1 20179205《Linux内核原理与设计》第八周作业的更多相关文章
- 2017-2018-1 20179205《Linux内核原理与设计》第九周作业
<Linux内核原理与设计>第九周作业 视频学习及代码分析 一.进程调度时机与进程的切换 不同类型的进程有不同的调度需求,第一种分类:I/O-bound 会频繁的进程I/O,通常会花费很多 ...
- 2017-2018-1 20179205《Linux内核原理与设计》第二周作业
<Linux内核原理与分析>第二周作业 本周视频学习情况: 通过孟老师的视频教程,大致对风诺依曼体系结构有了一个初步的认识,视频从硬件角度和程序员角度对CPU和Main Memory(内存 ...
- 20169212《Linux内核原理与分析》第二周作业
<Linux内核原理与分析>第二周作业 这一周学习了MOOCLinux内核分析的第一讲,计算机是如何工作的?由于本科对相关知识的不熟悉,所以感觉有的知识理解起来了有一定的难度,不过多查查资 ...
- 20169210《Linux内核原理与分析》第二周作业
<Linux内核原理与分析>第二周作业 本周作业分为两部分:第一部分为观看学习视频并完成实验楼实验一:第二部分为看<Linux内核设计与实现>1.2.18章并安装配置内核. 第 ...
- 2018-2019-1 20189221 《Linux内核原理与分析》第九周作业
2018-2019-1 20189221 <Linux内核原理与分析>第九周作业 实验八 理理解进程调度时机跟踪分析进程调度与进程切换的过程 进程调度 进度调度时机: 1.中断处理过程(包 ...
- 2017-2018-1 20179215《Linux内核原理与分析》第二周作业
20179215<Linux内核原理与分析>第二周作业 这一周主要了解了计算机是如何工作的,包括现在存储程序计算机的工作模型.X86汇编指令包括几种内存地址的寻址方式和push.pop.c ...
- 2019-2020-1 20199329《Linux内核原理与分析》第九周作业
<Linux内核原理与分析>第九周作业 一.本周内容概述: 阐释linux操作系统的整体构架 理解linux系统的一般执行过程和进程调度的时机 理解linux系统的中断和进程上下文切换 二 ...
- 2019-2020-1 20199329《Linux内核原理与分析》第二周作业
<Linux内核原理与分析>第二周作业 一.上周问题总结: 未能及时整理笔记 Linux还需要多用 markdown格式不熟练 发布博客时间超过规定期限 二.本周学习内容: <庖丁解 ...
- 2019-2020-1 20209313《Linux内核原理与分析》第二周作业
2019-2020-1 20209313<Linux内核原理与分析>第二周作业 零.总结 阐明自己对"计算机是如何工作的"理解. 一.myod 步骤 复习c文件处理内容 ...
- 2017-2018-1 20179205《Linux内核原理与设计》第四周作业
<Linux内核原理与分析> 视频学习及实验操作 Linux内核源代码 视频中提到了三个我们要重点专注的目录下的代码,一个是arch目录下的x86,支持不同cpu体系架构的源代码:第二个是 ...
随机推荐
- 每天网络半小时(MAC数据包在哪里合并的)
ip_deliver_local函数中函数中完成合并 听过netfilter框架中也会 因为net_filter框架需要感知到第四层的信息,但是单个数据包是无法感知到这些信息的,所以需要在netfil ...
- 自定义JS Map 函数
// 自定义JS Map 函数 function Map() { var map = function (key, value) {//键值对 this.key = key; this.value = ...
- python 内存分析
1.改源码重新编译打印相关信息 obmalloc.c 文件中打印 maxarenas,值为当前环境分配 arena 个数:分配 arena 时并没有马上分配对应的pools,故对于每一个 arena, ...
- BZOJ3673 & BZOJ3674 & 洛谷3402:可持久化并查集——题解
https://www.lydsy.com/JudgeOnline/problem.php?id=3673 https://www.lydsy.com/JudgeOnline/problem.php? ...
- 用camke编译python程序
project(test) cmake_minimum_required(VERSION 3.0) find_package(OpenCV REQUIRED) find_package (Python ...
- 仅此一文让你明白ASP.NET MVC 之Model的呈现
本文目的 我们来看一个小例子,在一个ASP.NET MVC项目中创建一个控制器Home,只有一个Index: public class HomeController : Controller { pu ...
- 使用树莓派录音——USB声卡
原文链接:http://jingyan.eeboard.com/article/73723 我们都知道树莓派只有音频输出口,而没有音频输入的接口,怎么办呢?其实只要一个USB声卡就可以了. USB声卡 ...
- ubuntu 服务器搭建汇总
开启ssh 1.首先:终端安装开启ssh-server服务: sudo apt-get install openssh-server 2.然后确认sshserver是否启动了: ps-e | grep ...
- 深入探索C++对象模型(一)
再读<深入探索C++对象模型>笔记. 关于对象 C++在加入封装后(只含有数据成员和普通成员函数)的布局成本增加了多少? 答案是并没有增加布局成本.就像C struct一样,memeber ...
- [LeetCode] 11. Container With Most Water ☆☆
Given n non-negative integers a1, a2, ..., an, where each represents a point at coordinate (i, ai). ...