爬虫实战【10】利用Selenium自动登陆京东签到领金币
今天我们来讲一下如何通过python来实现自动登陆京东,以及签到领取金币。
如何自动登陆京东?
我们先来看一下京东的登陆页面,如下图所示:
【插入图片,登陆页面】
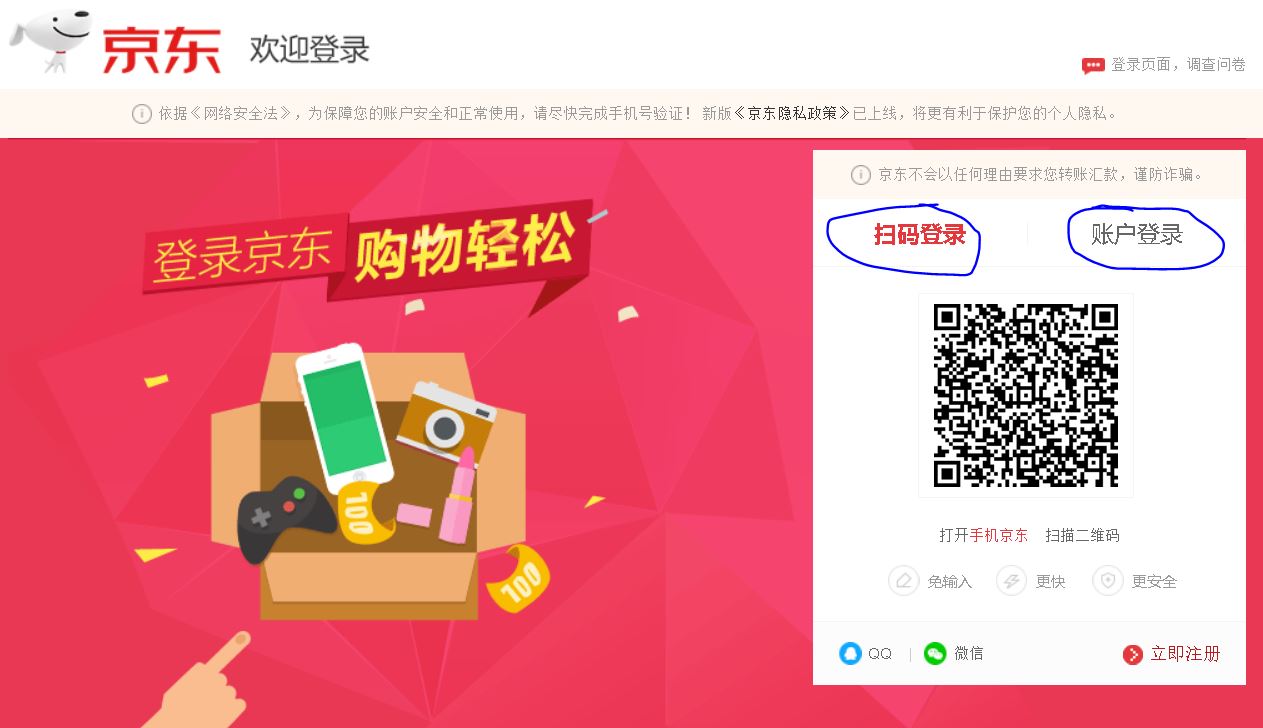
登陆框就是右面这一个框框了,但是目前我们遇到一个困呐,默认的登陆方式是扫码登陆,如果我们想要以用户民个、密码的形式登陆,就要切换一下。
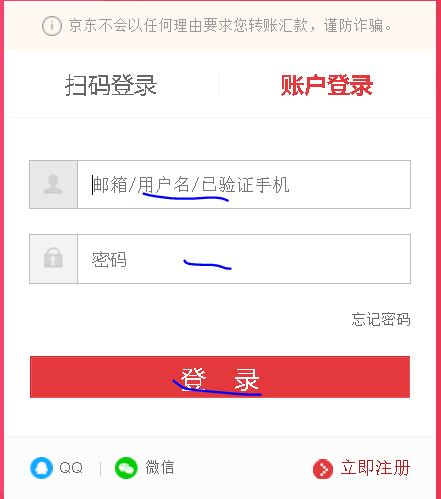
我们看一下这两种登陆方式是如何切换的,通过浏览器的元素检查,我们看一下两个标签。
【插入图片,两种登陆方式】

扫码登陆和用户登陆分别在一个div标签里面,我们可以通过css选择器选定用户登陆,使其下面的a标签的class为checked,接下来的一切就比较简单了。
我们要获取到用户名输入框、密码输入框以及登陆按钮即可。
【插入图片,用户登陆框】
下面看一下实现的代码,假设我们通过FireFox浏览器模拟登陆吧。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import time
login_url='https://passport.jd.com/uc/login'
uid='********'
pwd='********'
browser=webdriver.Firefox()
wait=WebDriverWait(browser, 10)
def login():
try:
browser.get(login_url)
login_tab_u=wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "div.login-tab:nth-child(3)")))
login_tab_u.click()#这里我们没有获取那个a标签,而是直接获取外层的div标签,比较简单而且方便
uid_input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#loginname")))
pwd_input=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#nloginpwd")))
login_button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#loginsubmit")))
uid_input.send_keys(uid)
pwd_input.send_keys(pwd)
login_button.click()
except TimeoutException:
login()
def main():
login()
time.sleep(5)
browser.close()
if __name__=='__main__':
main()
如何自动签到领金币?
领金币一定要登陆vip页面才可以。
vip页面的url=’https://vip.jd.com/home.html‘
但是要登陆vip页面的话,还是会跳转到第一步的那个登陆页面,我们利用第一步的方法登陆即可。
【插入图片,签到页面】
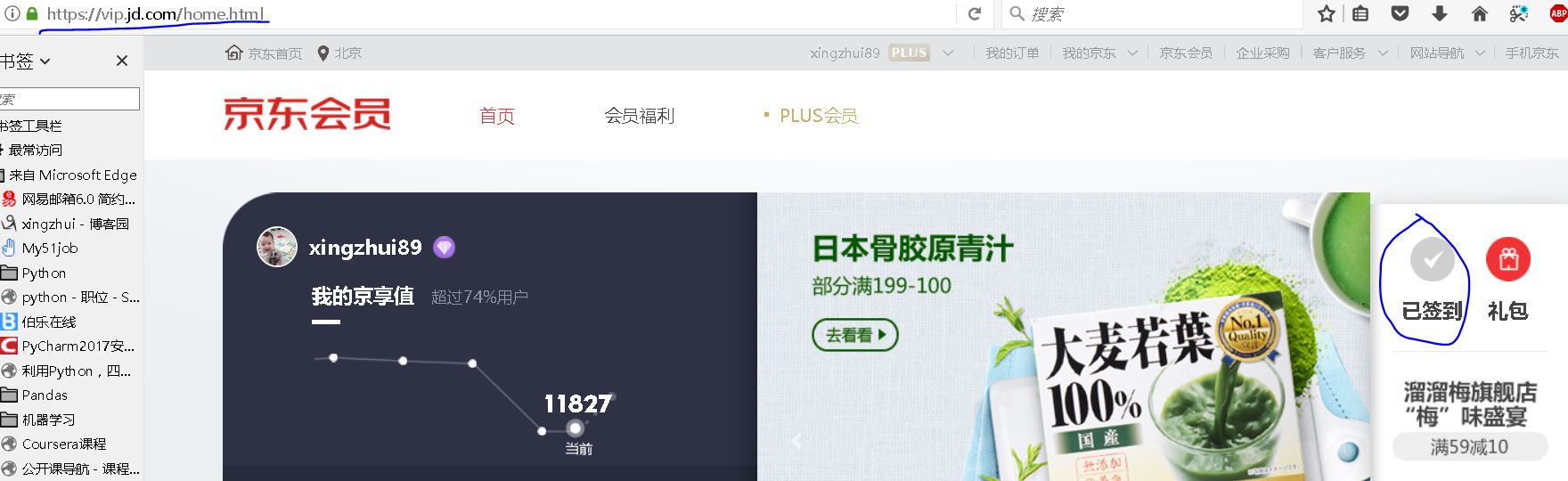
签到的链接在右侧,我们获取到这个链接点击就行了。
【插入图片,签到链接】
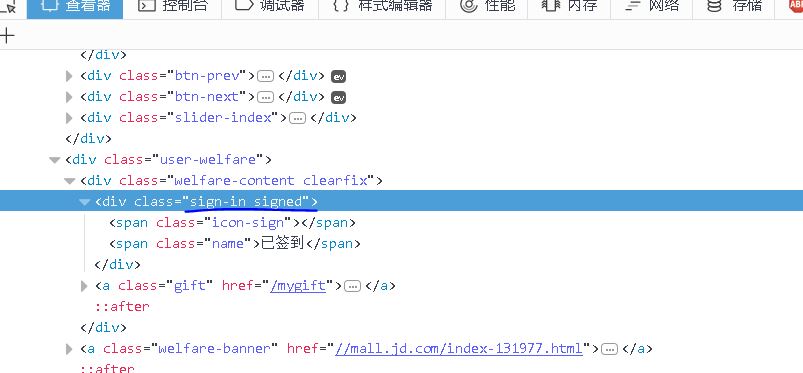
这个标签很简单。
vip_url='https://vip.jd.com/home.html'
def user_singin():
try:
browser.get(vip_url)
login_tab_u=wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "div.login-tab:nth-child(3)")))
login_tab_u.click()
uid_input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#loginname")))
pwd_input=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#nloginpwd")))
login_button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#loginsubmit")))
uid_input.send_keys(uid)
pwd_input.send_keys(pwd)
login_button.click()
sign_in_button=wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#signIn")))
sign_in_button.click()
print('您已签到成功!')
except TimeoutException:
user_singin()
前面的代码跟上面是一样的,只不过要获取到签到的标签。
这种登陆方式基本上可以用于任何网站,只不过做一些修改就可以了。
请大家参考。

爬虫实战【10】利用Selenium自动登陆京东签到领金币的更多相关文章
- 利用selenium爬取京东商品信息存放到mongodb
利用selenium爬取京东商城的商品信息思路: 1.首先进入京东的搜索页面,分析搜索页面信息可以得到路由结构 2.根据页面信息可以看到京东在搜索页面使用了懒加载,所以为了解决这个问题,使用递归.等待 ...
- 爬虫系列(十三) 用selenium爬取京东商品
这篇文章,我们将通过 selenium 模拟用户使用浏览器的行为,爬取京东商品信息,还是先放上最终的效果图: 1.网页分析 (1)初步分析 原本博主打算写一个能够爬取所有商品信息的爬虫,可是在分析过程 ...
- PYTHON 爬虫笔记十:利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB(实战项目三)
利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB 目标站点分析 淘宝页面信息很复杂的,含有各种请求参数和加密参数,如果直接请求或者分析Ajax请求的话会很繁琐.所以我们可 ...
- 利用selenium模拟登陆
第一部:利用selenium登陆 导入selenium库 from selenium import webdriver 明确模拟浏览器在电脑中存放的位置,比如我存在当前目录 chromePath = ...
- Python爬虫实战:使用Selenium抓取QQ空间好友说说
前面我们接触到的,都是使用requests+BeautifulSoup组合对静态网页进行请求和数据解析,若是JS生成的内容,也介绍了通过寻找API借口来获取数据. 但是有的时候,网页数据由JS生成,A ...
- python爬虫实战:利用scrapy,短短50行代码下载整站短视频
近日,有朋友向我求助一件小事儿,他在一个短视频app上看到一个好玩儿的段子,想下载下来,可死活找不到下载的方法.这忙我得帮,少不得就抓包分析了一下这个app,找到了视频的下载链接,帮他解决了这个小问题 ...
- Python爬虫 —— 知乎之selenium模拟登陆获取cookies+requests.Session()访问+session序列化
代码如下: # coding:utf-8 from selenium import webdriver import requests import sys import time from lxml ...
- 【python爬虫实战】使用Selenium webdriver采集山东招考数据
目录 1.目标 2.Selenium webdriver说明 2.1 为什么使用webdriver 2.2 webdriver支持浏览器 2.3 配置与使用说明 3.采集 3.1 分析网站 3.2 遍 ...
- selenium自动登陆
import osfrom selenium import webdriverimport time,jsonclass Cookie(object): def __init__(self,drive ...
随机推荐
- struts过滤器的不同2.16以后应该是: org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter 2.12以前应该是org.apache.struts2.dispatcher.Filterdispatcher
版本不同过滤器不同.2.16以后应该是:org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter2.12以前应该是or ...
- Repository与UnitOfWork引入
Repository是什么? 马丁大叔的书上同样也有解释:它是衔接数据映射层和域之间的一个纽带,作用相当于一个在内存中的域对象映射集合,它分离了领域对象和数据库访问代码的细 节.Repository受 ...
- 如何把HTML标记分类
p.h1.或div等元素常常称为块级元素,这些元素显示为一块内容:Strong,span等元素称为行内元素,它们的内容显示在行中,即“行内框”.(可以使用display=block将行内元素转换成块元 ...
- 使用jq Deferred防止代码被回调函数分解分解的支离破碎
//移动人物 function moveInterval(stopPosotion){ var dtd = $.Deferred(); // 生成Deferred对象 var yidong= wind ...
- PHP 抽象类的使用
//抽象类就是一个模版 abstract class db{ /* 参数:sql语句 返回值:索引的数组 */ abstract public function test($str); //没有方法体 ...
- atitit.软件设计模式大的总结attialx总结
atitit.软件设计模式大的总结attialx总结 1. 设计模式的历史3 2. 设计模式的数量(253个)3 3. 设计模式的结构4 3.1. 应用场景and条件Context4 3.2. Pro ...
- python3 解析xml
转载:http://www.jb51.net/article/79494.htm 这篇文章主要为大家详细介绍了深入解读Python解析XML的几种方式,以ElementTree模块为例,演示具体使用方 ...
- 分时段显示不同的提示的网页JS特效代码
脚本说明: 把如下代码加入body区域中 <SCRIPT> today=new Date(); var day; var date; var hello; var wel; hour=ne ...
- Discuz!X3.2修改用户名注册长度限制的方法
Discuz!X3.2用户名注册长度限制为15个字符,有些站长朋友觉得太短,需要改的长一点,但是很多人都不知道怎么修改,下面就告诉大家如何修改这个限制.按照以下步骤来就可以了! 1.打开 ) { ...
- session用户账号认证(一个用户登陆,踢出前一个用户)
在web.xml中配置: <listener> <listener-class>cn.edu.hbcf.common.listener.SessionAttributeList ...