四十一 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
elasticsearch(搜索引擎)基本的索引和文档CRUD操作
也就是基本的索引和文档、增、删、改、查、操作
注意:以下操作都是在kibana里操作的
elasticsearch(搜索引擎)都是基于http方法来操作的
GET 请求指定的页面信息,并且返回实体主体
POST 向指定资源提交数据进行处理请求,数据被包含在请求体中,POST请求可能会导致新的资源的建立和/或已有资源的修改
PUT 向服务器传送的数据取代指定的文档的内容
DELETE 请求服务器删除指定的页面
1、索引初始化,相当于创建一个数据库
用kibana创建
代码说明

# 初始化索引(也就是创建数据库)
# PUT 索引名称
"""
PUT jobbole #设置索引名称
{
"settings": { #设置
"index": { #索引
"number_of_shards":5, #设置分片数
"number_of_replicas":1 #设置副本数
}
}
}
"""
代码
# 初始化索引(也就是创建数据库)
# PUT 索引名称 PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
}
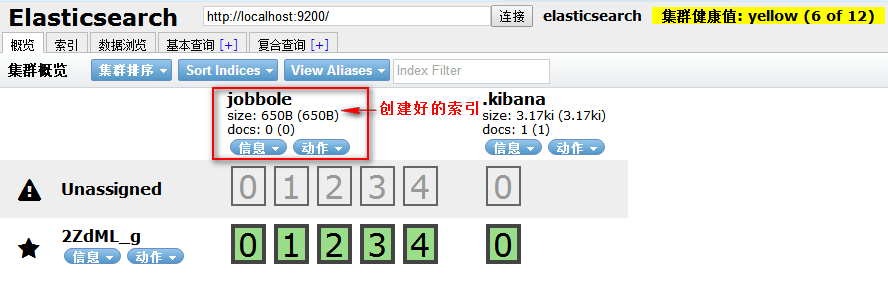
我们也可以使用可视化根据创建索引
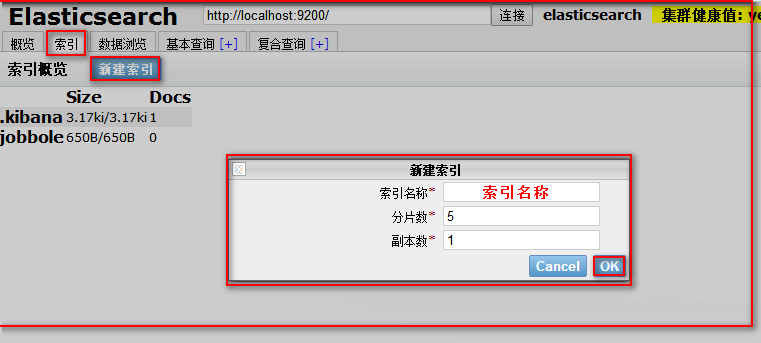
注意:索引一旦创建,分片数量不可修改,副本数量可以修改的
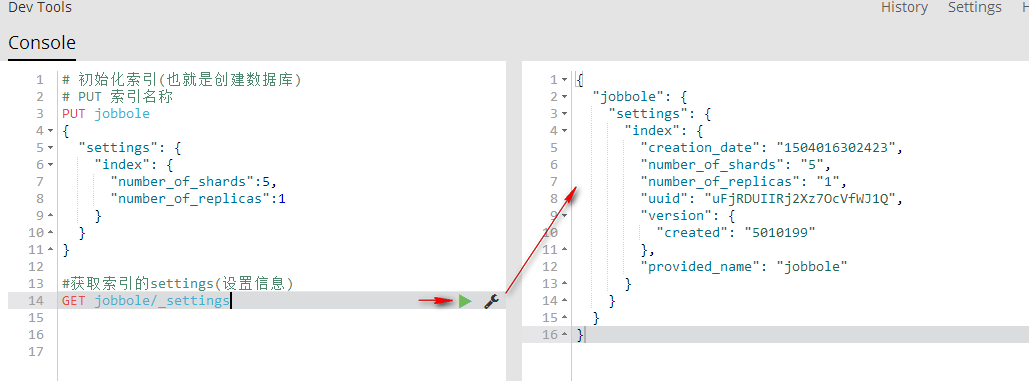
2、获取索引的settings(设置信息)
GET 索引名称/_settings 获取指定索引的settings(设置信息)
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取指定索引的settings(设置信息)
GET jobbole/_settings
GET _all/_settings 获取所有索引的settings(设置信息)
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings #获取所有索引的settings(设置信息)
GET _all/_settings
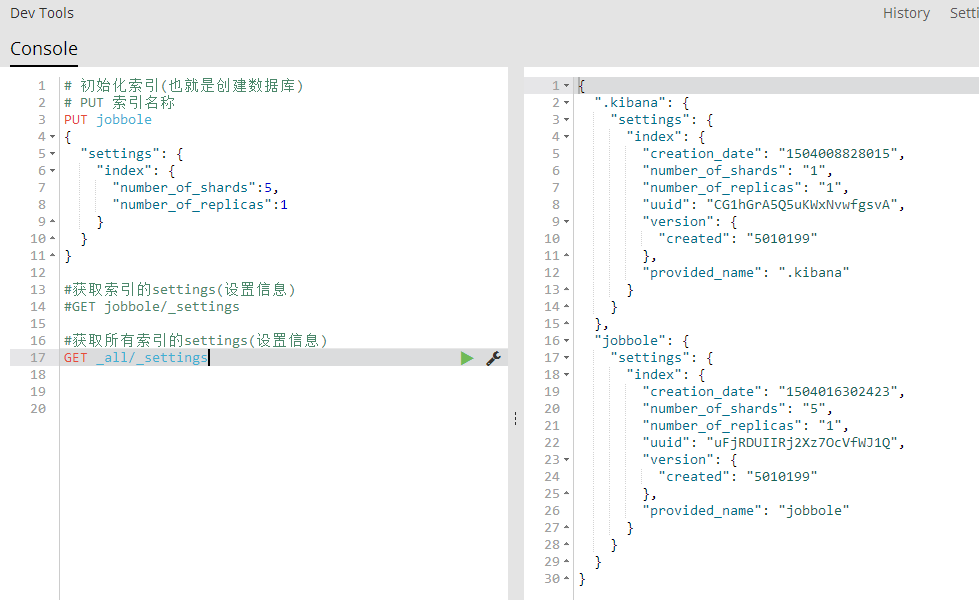
GET .索引名称,索引名称/_settings 获取多个索引的settings(设置信息)
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings #获取所有索引的settings(设置信息)
#GET _all/_settings
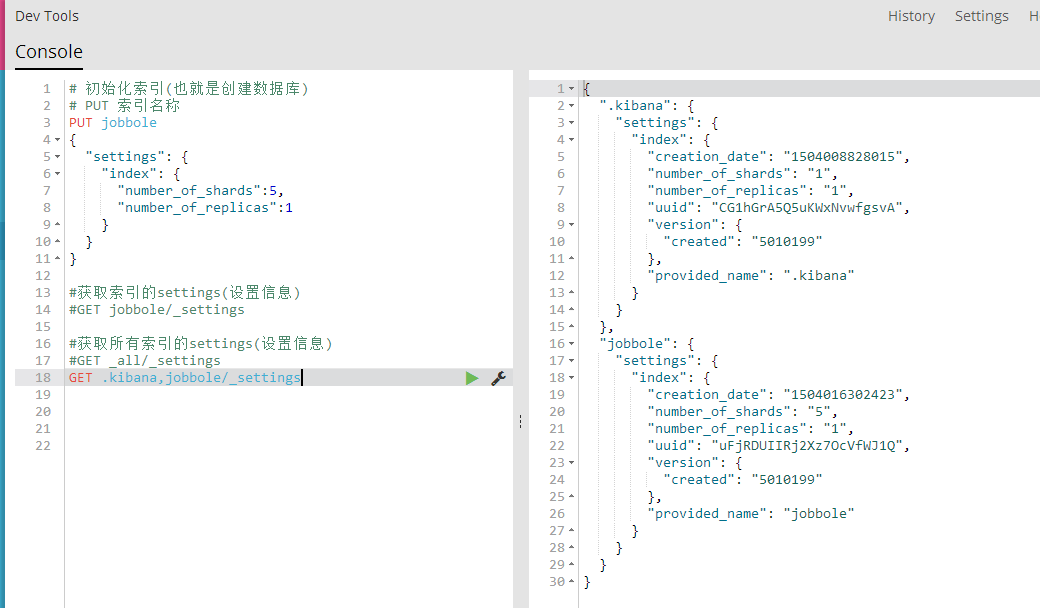
GET .kibana,jobbole/_settings
3、更新索引的settings(设置信息)
PUT 索引名称/_settings 更新指定索引的设置信息
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
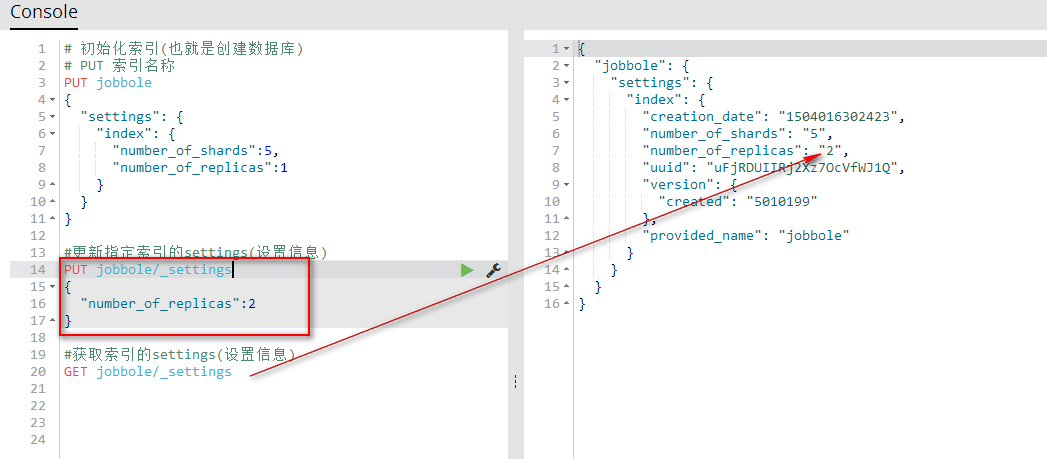
} #更新指定索引的settings(设置信息)
PUT jobbole/_settings
{
"number_of_replicas":2
} #获取索引的settings(设置信息)
GET jobbole/_settings
4、获取索引的(索引信息)
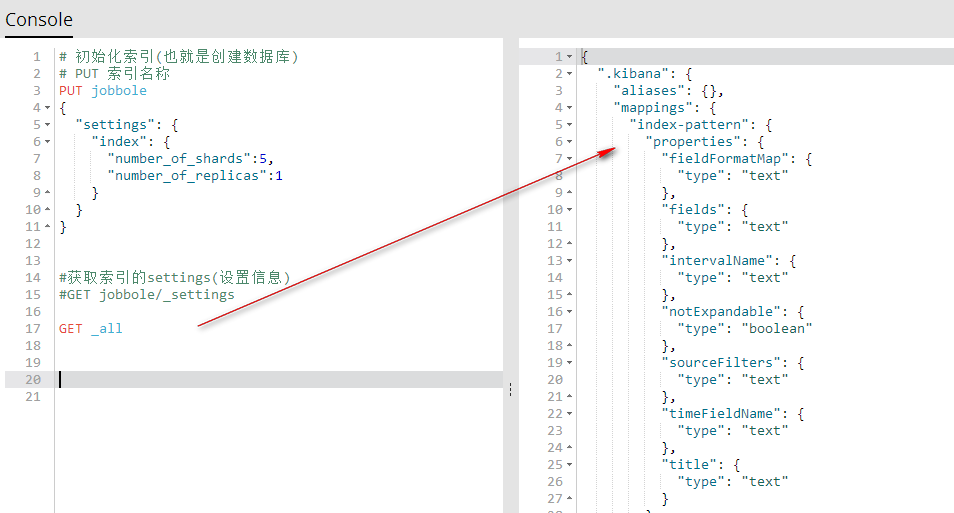
GET _all 获取所有索引的索引信息
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings GET _all
GET 索引名称 获取指定的索引信息
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings
#GET _all
GET jobbole
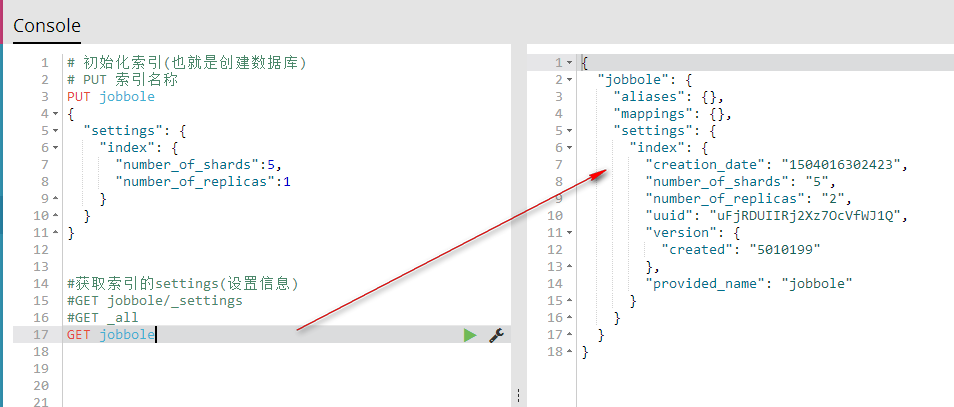
5、保存文档(相当于数据库的写入数据)
PUT index(索引名称)/type(相当于表名称)/1(相当于id){字段:值} 保存文档自定义id(相当于数据库的写入数据)
#保存文档(相当于数据库的写入数据)
PUT jobbole/job/1
{
"title":"python分布式爬虫开发",
"salary_min":15000,
"city":"北京",
"company":{
"name":"百度",
"company_addr":"北京市软件园"
},
"publish_date":"2017-4-16",
"comments":15
}
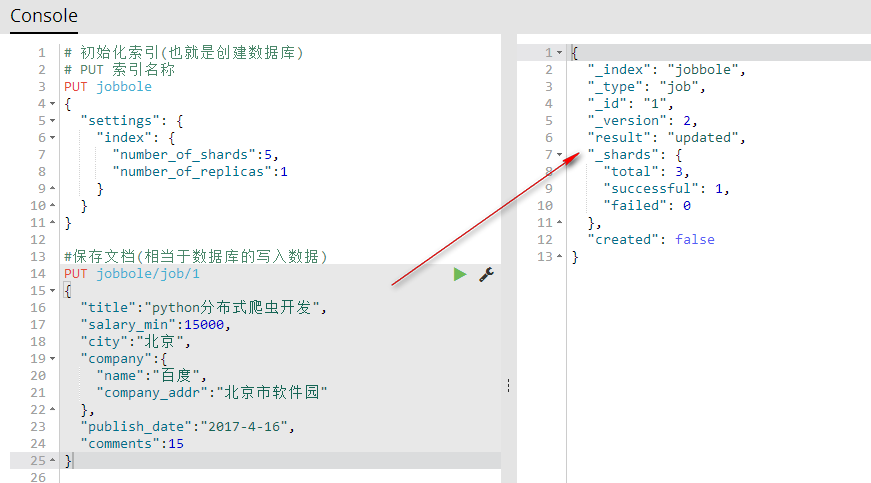
可视化查看

POST index(索引名称)/type(相当于表名称)/{字段:值} 保存文档自动生成id(相当于数据库的写入数据)
注意:自动生成id需要用POST方法
#保存文档(相当于数据库的写入数据)
POST jobbole/job
{
"title":"html开发",
"salary_min":15000,
"city":"上海",
"company":{
"name":"微软",
"company_addr":"上海市软件园"
},
"publish_date":"2017-4-16",
"comments":15
}

6、获取文档(相当于查询数据)
GET 索引名称/表名称/id 获取指定的文档所有信息
#获取文档(相当于查询数据)
GET jobbole/job/1
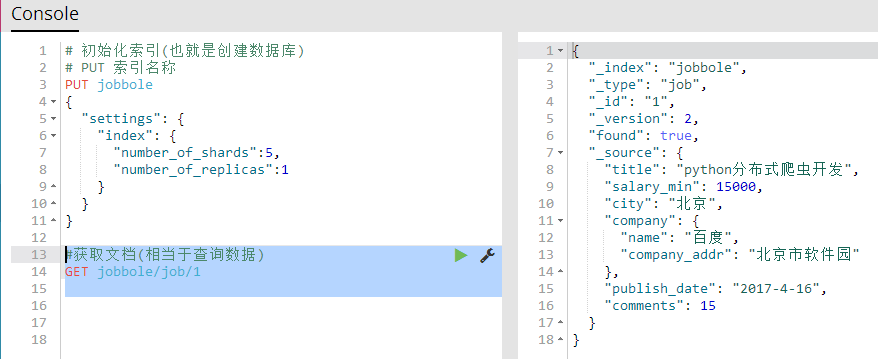
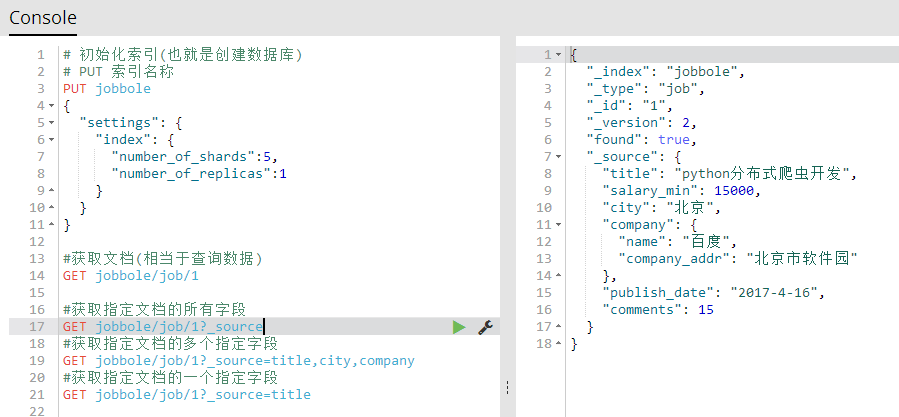
GET 索引名称/表名称/id?_source 获取指定文档的所有字段
GET 索引名称/表名称/id?_source=字段名称,字段名称,字段名称 获取指定文档的多个指定字段
GET 索引名称/表名称/id?_source=字段名称 获取指定文档的一个指定字段
#获取指定文档的所有字段
GET jobbole/job/1?_source
#获取指定文档的多个指定字段
GET jobbole/job/1?_source=title,city,company
#获取指定文档的一个指定字段
GET jobbole/job/1?_source=title
7、修改文档(相当于修改数据)
修改文档(用保存文档的方式,进行覆盖来修改文档)原有数据全部被覆盖
#修改文档(用保存文档的方式,进行覆盖来修改文档)
PUT jobbole/job/1
{
"title":"python分布式爬虫开发",
"salary_min":15000,
"city":"北京",
"company":{
"name":"百度",
"company_addr":"北京市软件园"
},
"publish_date":"2017-4-16",
"comments":20
}
修改文档(增量修改,没修改的原数据不变)【推荐】
POST 索引名称/表/id/_update
{
"doc": {
"字段":值,
"字段":值
}
}
#修改文档(增量修改,没修改的原数据不变)
POST jobbole/job/1/_update
{
"doc": {
"comments":20,
"city":"天津"
}
}
8、删除索引,删除文档
DELETE 索引名称/表/id 删除索引里的一个指定文档
DELETE 索引名称 删除一个指定索引
#删除索引里的一个指定文档
DELETE jobbole/job/1
#删除一个指定索引
DELETE jobbole
四十一 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查的更多相关文章
- 第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引
第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引 倒排索引 倒排索引源于实际应用中需要根据属性的值来查找记录.这种索引表中的每一项都包 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 五十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
随机推荐
- Redis数据存储优化机制(转)
原文:Redis学习笔记4--Redis数据存储优化机制 1.zipmap优化hash: 前面谈到将一个对象存储在hash类型中会占用更少的内存,并且可以更方便的存取整个对象.省内存的原因是新建一个h ...
- mysql创建索引/删除索引操作
-- 1.ALTER 创建索引 -- table_name表名,column_list列名,index_name索引名 -- 创建index索引 ALTER TABLE table_name ADD ...
- 我的Android进阶之旅------>解决DownloadManager报错java.lang.SecurityException: Invalid value for visibility: 2
1.问题描述 今天使用Android系统的DownloadManager进行下载操作时,爆了如下所示的错误: java.lang.RuntimeException: Unable to start s ...
- Linux命令之pip
使用pip进行install,sudo pip install xxx 使用pip进行update,sudo pip install --update xxx 使用pip设置超时时间,sudo pip ...
- 去除MyEclipse 中新建servlet多余的注释问题
1.找到你的MyEclipse 的安装目录 2.点击文件位置,找到安装目录下的Common 文件夹下的plugins 3.找到com.genuitec.eclipse.wizards.jar 文件, ...
- Oracle DG强制激活 备库
在实际运营环境中,我们经常碰到类似这样的需求,譬如想不影响现网业务评估DB补丁在现网环境中运行的时间,或者是想在做DB切换前想连接Standby DB做实际业务运行的测试,如果在9i版本的时候,想做到 ...
- 关于shared pool的深入探讨(四)
我们进一步来讨论一下shared pool的处理: 先进行相应查询,获得测试数据: [oracle@jumper udump]$ sqlplus "/ as sysdba" SQL ...
- java队列的实现
队列也可以通过数组和链表两种方式来实现. 1.链表方式实现 class Node{ Node next = null; int data; public Node(int data){this.dat ...
- 高通平台下安卓opencl小例子
http://blog.csdn.net/wcj0626/article/details/26272019 先到高通的qdn下载adreno GPU SDK,里面有OpenCL的例子.https:// ...
- 转一篇Git代码回滚技巧
转 https://github.com/geeeeeeeeek/git-recipes/wiki/5.2-代码回滚:Reset.Checkout.Revert的选择