Pulsar云原生分布式消息和流平台v2.8.0
Pulsar云原生分布式消息和流平台
**本人博客网站 **IT小神 www.itxiaoshen.com
Apache Pulsar是一个云原生的分布式消息和流媒体平台,最初创建于雅虎!现在是Apache软件基金会的顶级项目
官网首页列举一些关键特性和目前使用公司包括国内深度合作腾讯,目前最新版本为2.8.0,背后的开源流数据公司 StreamNative,2019年创立一家公司,作为云原生时代专注技术细分领域的佼佼者
什么是Pulsar
Pulsar即可以支持queue模式的消息中间件比如RabbitMQ和RocketMQ,也可以支持stream流模式的Kafka,几乎涵盖消息应用的领域,加上丰富企业特性如多租户隔离、百万级Topics、跨地域复制、鉴权认证,是云原生时代其他消息中间件的演化或者说是替代品也不为过


部署模式
支持多种部署模式,比如本地开发测试环境下单机运行环境,生产使用集群部署或多集群部署,还有基于容器化的Docker和K8s部署等
概览
Pulsar 是一个用于服务器到服务器的消息系统,具有多租户、高性能等优势。 Pulsar 最初由 Yahoo 开发,目前由 Apache 软件基金会管理。
Pulsar 的关键特性如下:
Pulsar 的单个实例原生支持多个集群,可跨机房在集群间无缝地完成消息复制。
极低的发布延迟和端到端延迟。
可无缝扩展到超过一百万个 topic。
支持多种topic 订阅模式(独占订阅、共享订阅、故障转移订阅)。
通过 Apache BookKeeper 提供的持久化消息存储机制保证消息传递 。
- 由轻量级的 serverless 计算框架 Pulsar Functions 实现流原生的数据处理。
基于 Pulsar Functions 的 serverless connector 框架 Pulsar IO 使得数据更易移入、移出 Apache Pulsar。
分层式存储可在数据陈旧时,将数据从热存储卸载到冷/长期存储(如S3、GCS)中。
Pulsar需要解决问题
- 企业需求和数据规模
- 多租户-百万Topics-低延迟-持久化-跨地域复制
- 解除存储计算耦合
- 运维痛点:替换机器、服务扩容、数据rebalance
- 减少文件系统依赖
- 性能难保障:持久化、一致性、多Topic
- IO不隔离:消费者度Backlog的时候会影响其他生产者和消费者,Kakfa采用顺序写的机制提升性能,当Topic和分区数大量增大后便会退化为随机写而极大减低起IO性能
架构
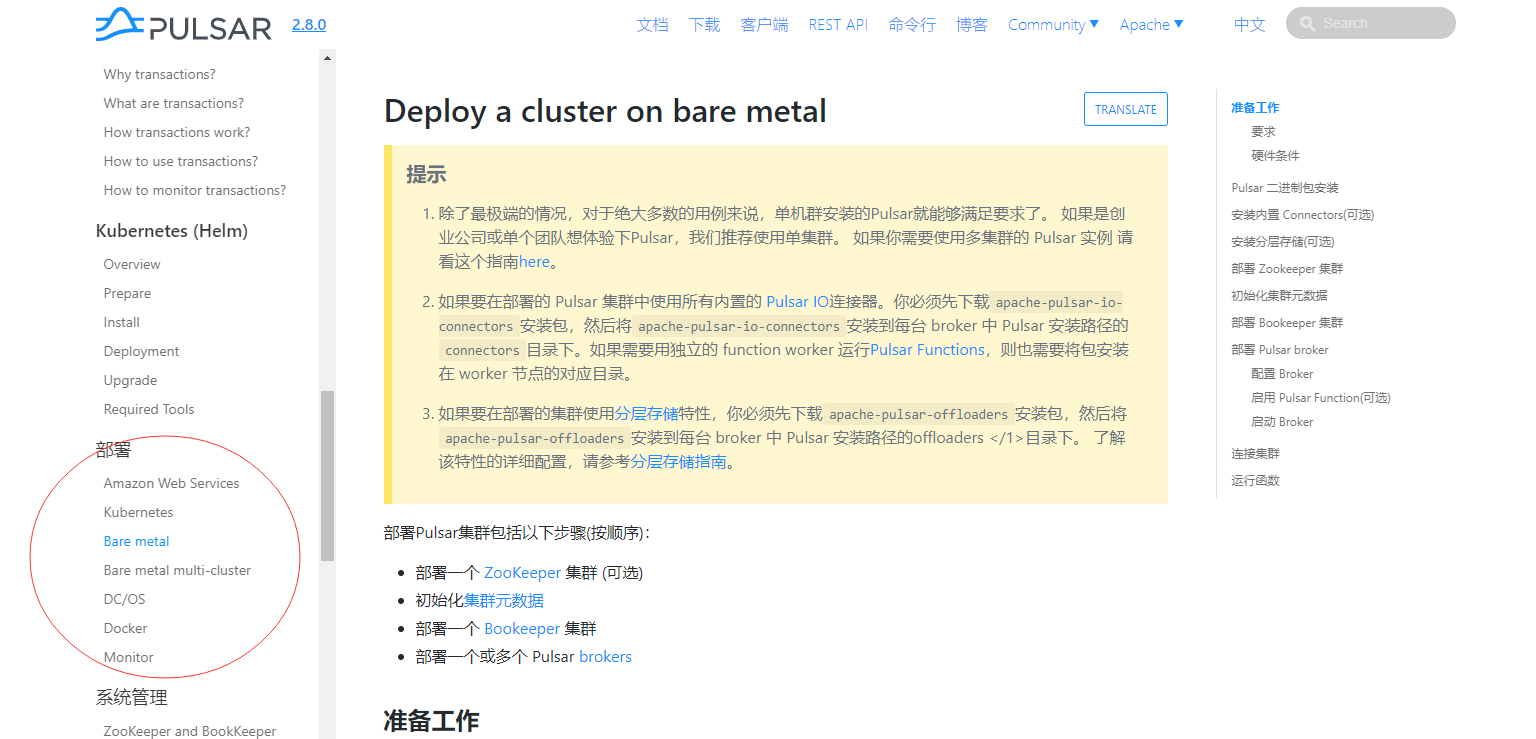
Pulsar底层最为关键技术是采用存储和计算分离以及分层+分片的架构,节点是对等的可以独立扩展并支持灵活扩容和快速容错机制,这也是为什么说Pulsar是云原生架构的主要原因;
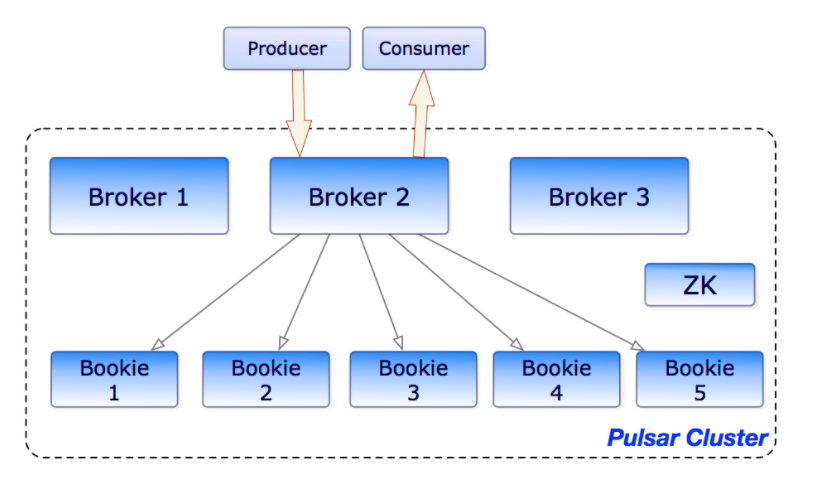

Pulsar企业级存储层采用的是Apache BookKeeper持久化存储。 BookKeeper是一个分布式的预写日志(WAL)系统,满足低延迟、高吞吐、持久化、强一致性、高可用、I/O隔离,元数据服务基于rocksdb legder存储,而基于New Sql新一代分布式关系数据库TiDb的k-v存储节点底层也是采用 性能非常强大单机存储引擎rocksdb,关于 BookKeeper我们本篇不做延展介绍,后续有时间再单独阐述。
Broker作为计算层依靠Zookeeper作为生产者和消费者的桥梁,天然属于无状态的服务,扩容通过服务发现自动动态感知;另一方面底层是分布式存储,因此扩容直接添加存储节点即可,原来在Kafka扩容节点后,如果没有属于该节点的分区数据则扩容节点是无法起作用的,需要做分区管理或rebalance,而在Pulsar中新增加节点则会实时增加数据进来,这个得益于Pulsar的架构设计,采用分层+分片的逻辑存储概念,每一块存储是可以存储不同Topic不同分区的数据,然后依赖于索引系统原理实现检索;存储节点出现故障后由于是对等架构,分布式存储有多副本机制,所以可继续提供正常服务且也不需要立即进行故障转移,可以在合适时机再做副本迁移,所以对于应用来说是无感知的
Pulsar稳定的IO质量底层机制
Ledger是一个只追加的数据结构,并且只有一个写入器,这个写入器负责多个BookKeeper存储节点(就是Bookies)的写入。 Ledger的条目会被复制到多个bookies。 Ledgers本身有着非常简单的语义:
- Pulsar Broker可以创建ledeger,添加内容到ledger和关闭ledger。
- 当一个ledger被关闭后,除非明确的要写数据或者是因为写入器挂掉导致ledger关闭,这个ledger只会以只读模式打开。
- 最后,当ledger中的条目不再有用的时候,整个legder可以被删除(ledger分布是跨Bookies的)。
Ledger读一致性
BookKeeper的主要优势在于他能在有系统故障时保证读的一致性。 由于Ledger只能被一个进程写入(之前提的写入器进程),这样这个进程在写入时不会有冲突,从而写入会非常高效。 在一次故障之后,ledger会启动一个恢复进程来确定ledger的最终状态并确认最后提交到日志的是哪一个条目。 在这之后,能保证所有的ledger读进程读取到相同的内容。
Managed ledgers
Given that Bookkeeper ledgers provide a single log abstraction, a library was developed on top of the ledger called the managed ledger that represents the storage layer for a single topic. managed ledger即消息流的抽象,有一个写入器进程不断在流结尾添加消息,并且有多个cursors 消费这个流,每个cursor有自己的消费位置。
Internally, a single managed ledger uses multiple BookKeeper ledgers to store the data. There are two reasons to have multiple ledgers:
- 在故障之后,原有的某个ledger不能再写了,需要创建一个新的。
- A ledger can be deleted when all cursors have consumed the messages it contains. This allows for periodic rollover of ledgers.
日志存储
In BookKeeper, journal files contain BookKeeper transaction logs. 在更新到 ledger之前,bookie需要确保描述这个更新的事务被写到持久(非易失)存储上面。 在bookie启动和旧的日志文件大小达到上限(由
journalMaxSizeMB参数配置)的时候,新的日志文件会被创建。
Palsar Schema
启用 schema 后,Pulsar 会解析数据,即接收字节作为输入并发送字节作为输出。 虽然数据不仅是字节,但的确需要解析这些数据,解析时还可能发生解析异常,解析异常主要出现在以下几种情况中:
- 字段不存在
- 字段类型已更改(例如,将
string更改为int)
简单来说,当我们使用 schema 去创建 producer 生产者则不再需要将消息序列化为字节,因为Pulsar schema 会在后台帮我们执行序列化操作。
Producer<User> producer = client.newProducer(JSONSchema.of(User.class))
.topic(topic)
.create();
User user = new User("Tom", 28);
producer.send(user);
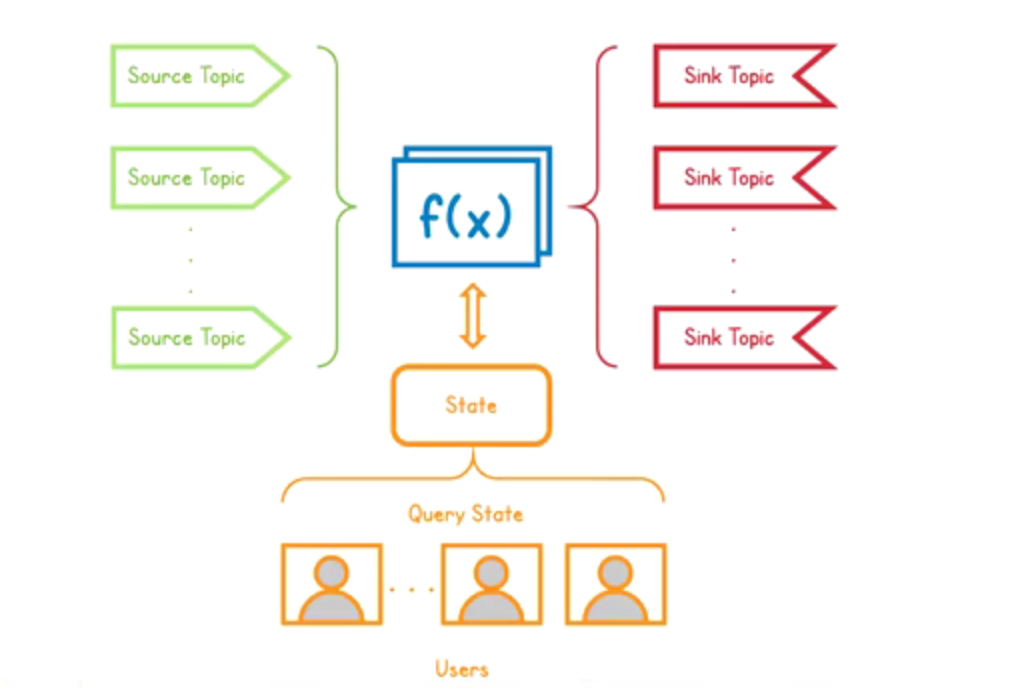
Parsar Functions
Pulsar Functions 是轻量级计算流程,具有以下特点:
- 从一个或多个 Pulsar topic 中消费消息;
- 将用户提供的处理逻辑应用于每条消息;
- 将运行结果发布到另一个 topic。
- Pulsar Functions可以看做是一种编程模型,背后的核心目标是使您能够轻松创建各种级别的复杂的的处理逻辑,而无需部署单独的类似系统(例如 Apache Storm, Apache Heron, Apache Flink, 等等) Pulsar Functions are computing infrastructure of Pulsar messaging system. The core goal is tied to a series of other goals:
- 提高开发者的生产力(用开发者熟悉的语言和Pulsar Function 的函数SDK)
- 简单的故障排查
- 操作简单(不需要外部处理系统)
Function 抽象,计算对象是消息,Function 将收到消息进行计算执行业务逻辑并写进 Output topic,Function 为开发者提供了很多便利,简单的计算都可以通过 Function 完成。可以将 Function 结合起来,由此提出一个新概念 Function Mesh,其主要基于 K8s 开发。
package org.example.functions;
import org.apache.pulsar.functions.api.Context;
import org.apache.pulsar.functions.api.Function;
import java.util.Arrays;
public class WordCountFunction implements Function<String, Void> {
// This function is invoked every time a message is published to the input topic
@Override
public Void process(String input, Context context) throws Exception {
Arrays.asList(input.split(" ")).forEach(word -> {
String counterKey = word.toLowerCase();
context.incrCounter(counterKey, 1);
});
return null;
}
}
将上面的代码编译成可部署的 JAR 文件,可以使用如下命令行将 JAR 包部署到 Pulsar 集群中。
$ bin/pulsar-admin functions create \
--jar target/my-jar-with-dependencies.jar \
--classname org.example.functions.WordCountFunction \
--tenant public \
--namespace default \
--name word-count \
--inputs persistent://public/default/sentences \
--output persistent://public/default/count
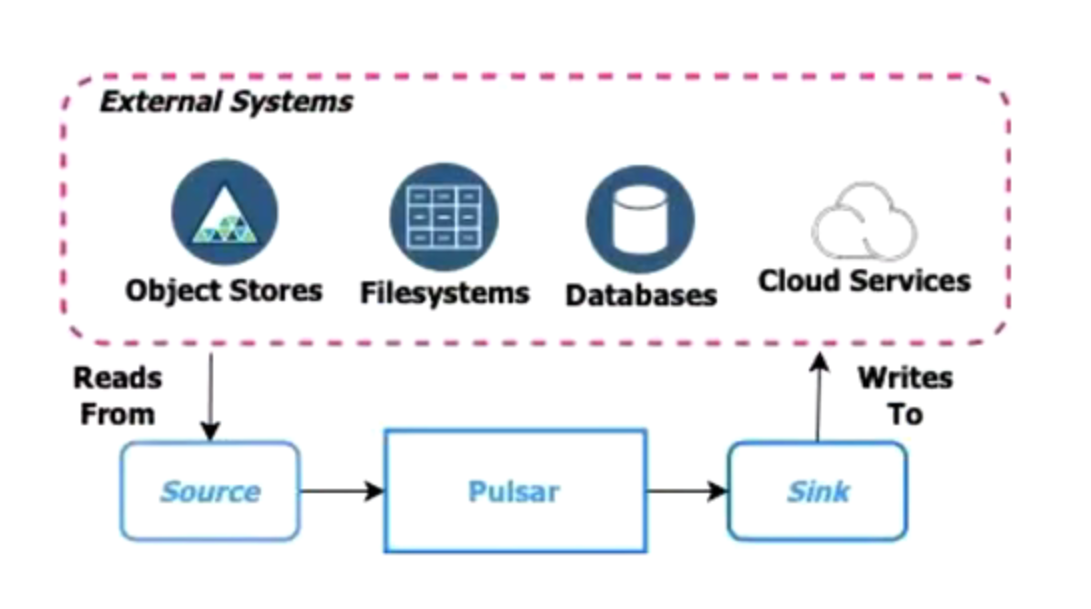
Pulsar IO
Pulsar IO连接器使您能够轻松创建、部署和管理与外部系统交互的连接器,如Apache Cassandra、Aerospike等。
可以通过 Connector Admin CLI并结合 sources 和 sinks 子命令来管理 Pulsar 连接器(例如,创建、更新、启动、停止、重启、重载、删除以及其他操作)。
连接器(sources 和 sinks)和 Functions 是实例的组成部分,都在 Functions workers 上运行。 通过 Connector Admin CLI 或 Functions Admin CLI 管理 source、sink 或者 function 时,在 worker 上就启动了一个实例。 了解更多信息,参阅 Functions worker。

Pulsar SQL
Apache Pulsar 用于存储事件数据流,事件数据结构由预定义字段组成。 借助 Schema Registry 的实现,你可以在 Pulsar 中存储结构化数据,并通过使用Trino(原先叫 Presto SQL)查询这些数据。
作为 Pulsar SQL 的核心,Presto Pulsar 连接器支持 Presto 集群中的 Presto worker 查询 Pulsar 数据。
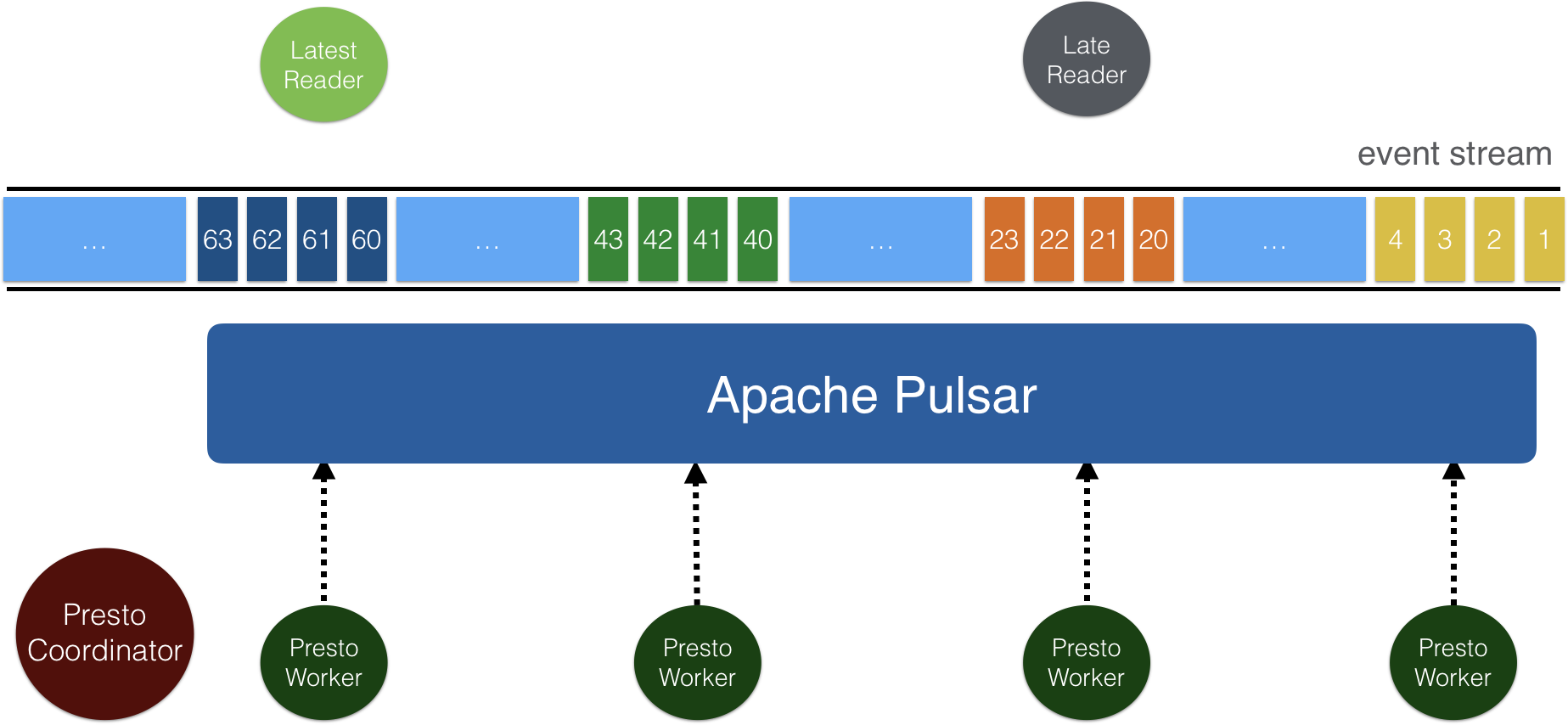
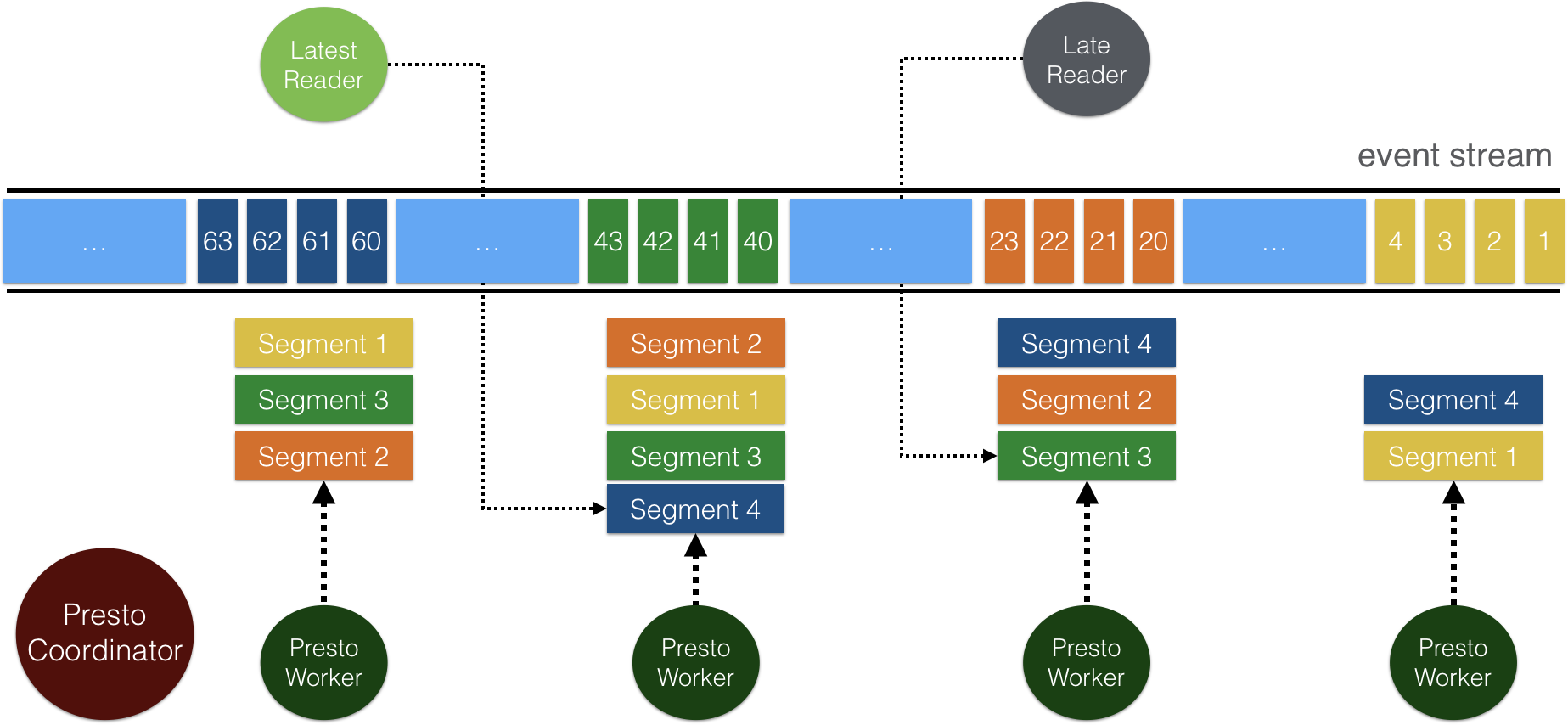
查询性能高效且高度可扩展,这得益于 Pulsar 的 分层分片架构。
Pulsar 中的主题以分片形式存储在 Apache BookKeeper 中。 每个主题分片会被复制到多个 BookKeeper 节点,可以支撑并发读和高吞吐。 你可以配置 BookKeeper 节点的数量,默认节点数是 3。 在 Presto Pulsar 连接器中,数据直接从 BookKeeper 读取,所以 Presto worker 能从水平扩展的 BookKeeper 节点中并发读取数据。
Tiered Storage
Pulsar 的分层存储 功能允许将历史 backlog 数据从 BookKeeper 中转移到更加低廉的存储介质中并且允许客户端访问无变化的 backlog 数据。
分层存储通过Apache jclouds来实现在Amazon S3和 GCS (Google Cloud Storage) 进行归档存储。
通过 jclouds,可以在未来便捷地去扩展对其他云存储的支持。
分层存储通过Apache Hadoop来实现在文件系统中进行归档存储。
通过 Hadoop,可以在未来便捷地去扩展对其他文件系统的支持。
Transactions
Pulsar事务 (txn) 使事件流应用程序能够在一个原子操作中消费、处理和生成消息。

Pulsar事务支持端到端的恰好一次流处理,这意味着消息不会从源算子(source operator)丢失,并且消息不会重复发给接收算子(sink operator)。
随着Pulsar 2.8.0中引入的事务,Pulsar Flink接收器连接器可以通过实现指定的 TwoPhaseCommitSinkFunction 并使用Pulsar事务 API 连接 Flink 接收器消息生命周期来支持exactly-once语义
Pulsar 周边和生态
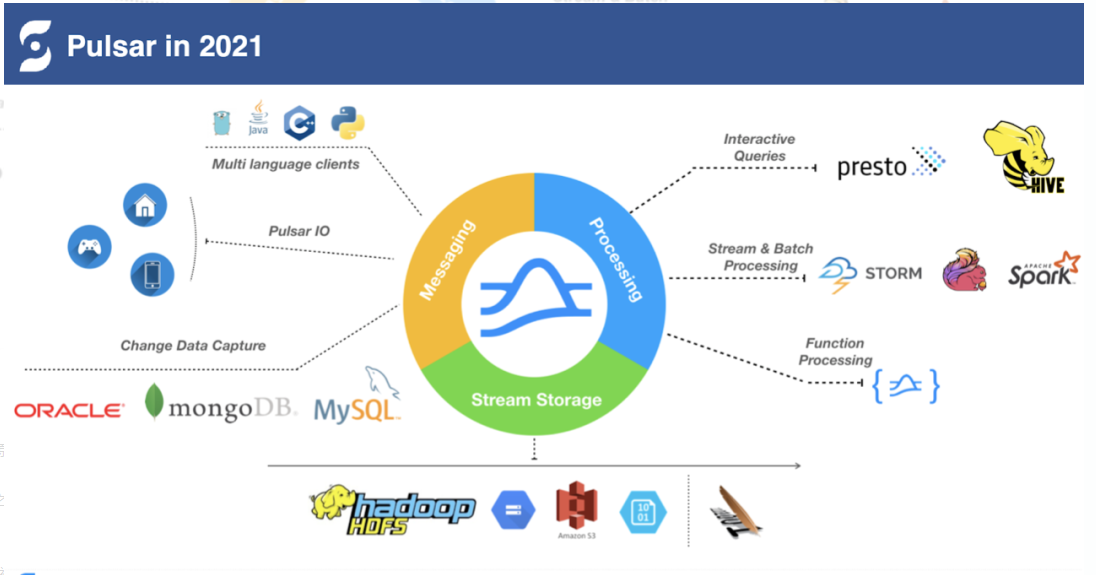
Pulsar 作为一个流原生消息平台,主要包括存储(Stream Storage)、消息(Messaging)、计算(Processing)三个方面的工作。
Messaging 是 Pulsar 诞生之初的一个主要方向。通过 Pulsar IO 和外部系统打。
下图蓝色 Processing 方面 Queries 的引擎比如 Presto 和 HIVE 进行深度整合,让 Presto 和 HIVE 能够直接读取 Pulsar 的 topic ,再结合 Pulsar 本身自带的 Schema,将 Pulsar topic 作为的一个表直接查找 Pulsar topic 中的数据。
在 Streaming & Batch Processing 方面,与大数据处理引擎包括 Storm、Flink、Spark 进行深度整合。
在 Processing 方向的思路是与现有的大数据生态做深度的融合,让大数据生态能够更好地访问 Pulsar,把 Pulsar 当作数据的存储引擎。
除此之外,Pulsar 推出了 Pulsar Function — 一个轻量级的计算框架。Pulsar Function 可以减轻很多数据的传输,可以靠近数据端完成计算,目前很多 IoT 场景的用户如涂鸦智能、EMQ、中国电信及一些车联网公司都在使用 Pulsar Function。
除了 Messaging 和 Processing ,Pulsar 拥有一个很坚实的基础,就是拥有专门为消息、流存储而设计的存储引擎 Apache BookKeeper。结合 Pulsar 对分区再分片的存储特性,我们很自然地把老的分片迁移到二级存储中,所以 Pulsar 的架构很容支持二级存储。二级存储的介质包括云上的各种资源:S3、HDFS
消息领域

很多用户在使用 Pulsar 的过程中,会发现客户端应用的改造和迁移会很难落地。比如 Kafka 往 Pulsar 迁移过程中,客户很可能也会有大量基于 Kafka Clients 的应用需要更改,由于需要更改协议导致迁移很困难。
由于短时间不可能完全从 Kafka 迁移到 Pulsar,导致对后台的运维甚至整个业务的切换带来很大的不便捷性。
Pulsar 和 Kafka 一样是以 topic 作为基础,以 log 作为抽象,Pulsar 的一致性、延迟、吞吐会更优,在这个基础上要复用 Pulsar 的存储层,在 Broker 端实现协议的解析,用户的切换成本更低。Pulsar Broker 端提供 Protocol Handler 插件(现在已经实现 Kafka、AMQP、MQTT 协议的支持)的方式来支持多种协议。这种在 Broker 端做协议解析的方法,可以更方便地支持多种协议。其次还利用 Pulsar 在存储层拥有存储、计算分离的优势,服务上层多种协议。
KoP(Kafka on Pulsar)
目前 StreamNative 联合合作伙伴已推出了 KoP 项目,主要满足想要从 Kafka 应用程序切换到 Pulsar 的用户的强烈需求。
KoP 将 Kafka 协议处理插件引入 Pulsar broker,从而实现 Apache Pulsar 对原生 Apache Kafka 协议的支持。将 KoP 协议处理插件添加到现有 Pulsar 集群后,用户不用修改代码就可以将现有的 Kafka 应用程序和服务迁移到 Pulsar,从而使用 Pulsar 的强大功能。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9i0cziCO-1629624254691)(http://www.itxiaoshen.com:3001/assets/1629618989303RWFe8zct.png)]
{kind=link}
KoP 相关特性:
- Broker 的插件,Client 不需要做任何的改动;
- 共享访问;
- 支持 Kafka 0.10-2.x 版本;
- 连续 Offset:增加对连续 ID 的支持。
- 性能改进:实现与 Kafka broker 类似的机制,无需 KoP 针对 Kafka 发送的 batch 消息进行拆包解包,将 Kafka 发送过来的消息直接以 Kafka 格式进行存储,并在 Pulsar Client 增加对 kafka 协议的解析器。
- 支持 Envoy,并实现 Pulsar Schema 与 Kafka Schema 的兼容。
AoP(AMQP on Pulsar)
AoP(AMQP on Pulsar)是 StreamNative 联合中国移动共同开发推进的项目,类似 KoP,主要解决 AMQP 应用程序迁移到 Pulsar 的需求。当前 AoP 实现了对 AMQP 协议 0.9.1 版本的支持,2021 年计划对 AMQP 1.0 协议进行整合支持。目前除了中国移动正在大规模应用 AoP 外,国外也有越来越多的用户正在使用 AoP,希望更多小伙伴加入到 AoP 使用中来,共同丰富 AoP 场景,协作增强 AoP 功能。
MoP(MQTT on Pulsar)
MQTT 协议在物联网应用十分广泛,类似 KoP、AoP,当前 Pulsar 也通过 MoP 项目提供了对 MQTT 协议的支持。当前 MoP 支持 QoS level 0、QoS level 1 协议,2021 年计划实现对 QoS level 2 协议的支持。
Apache Pulsar在日志系统中的应用
常见日志架构ELK
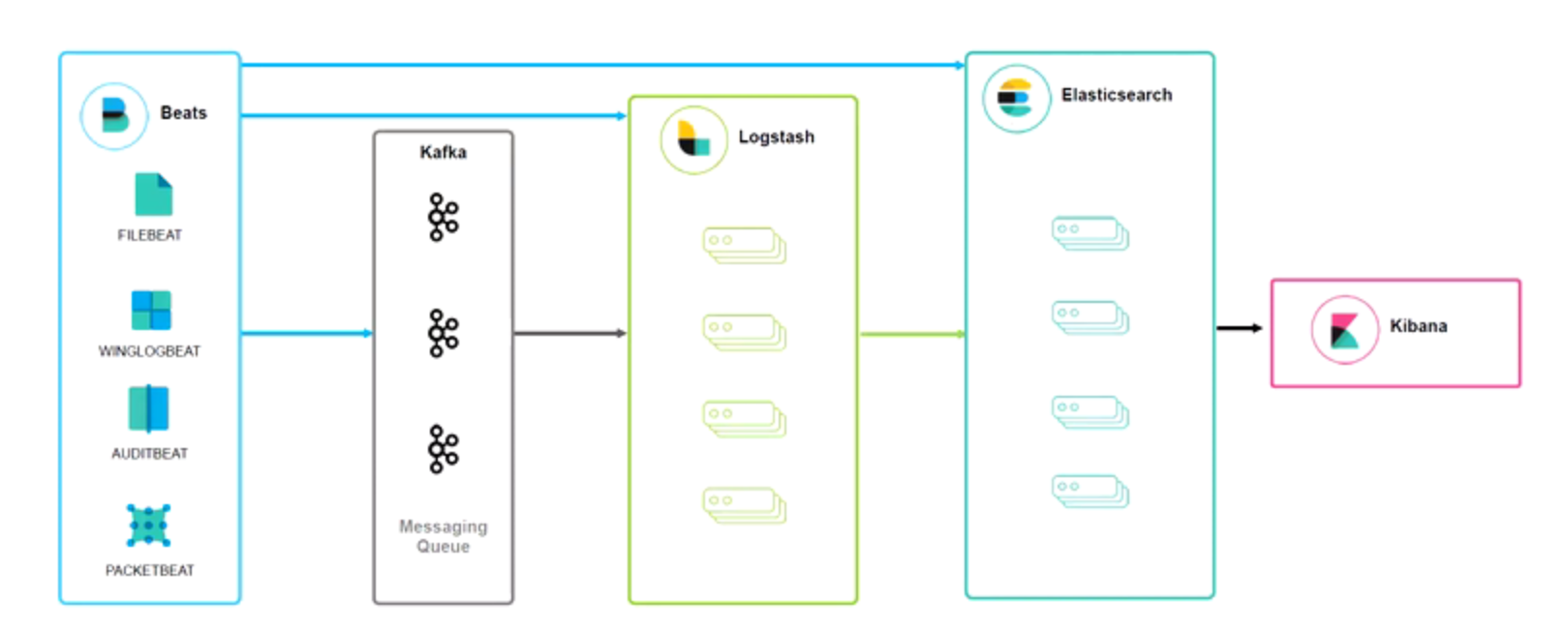
消息队列在日志场景中主要作用:削峰解耦、数据分发
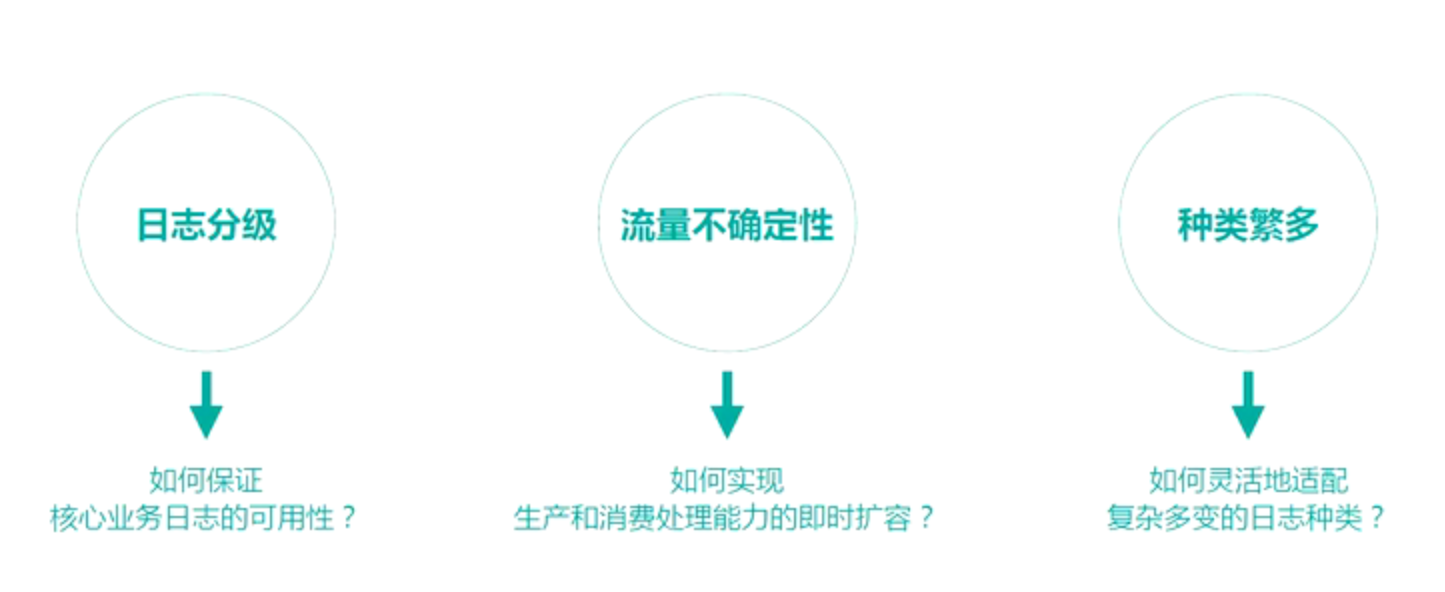
日志系统常见挑战:
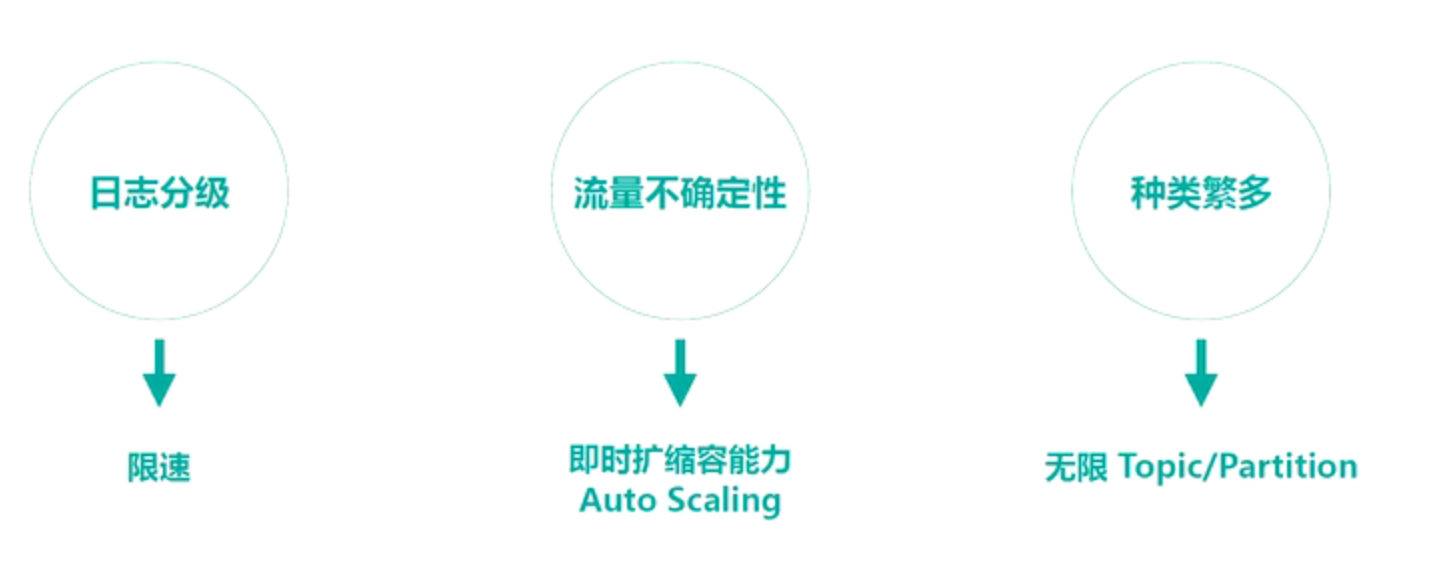
更多功能性要求:
Kafka和Pulsar对比
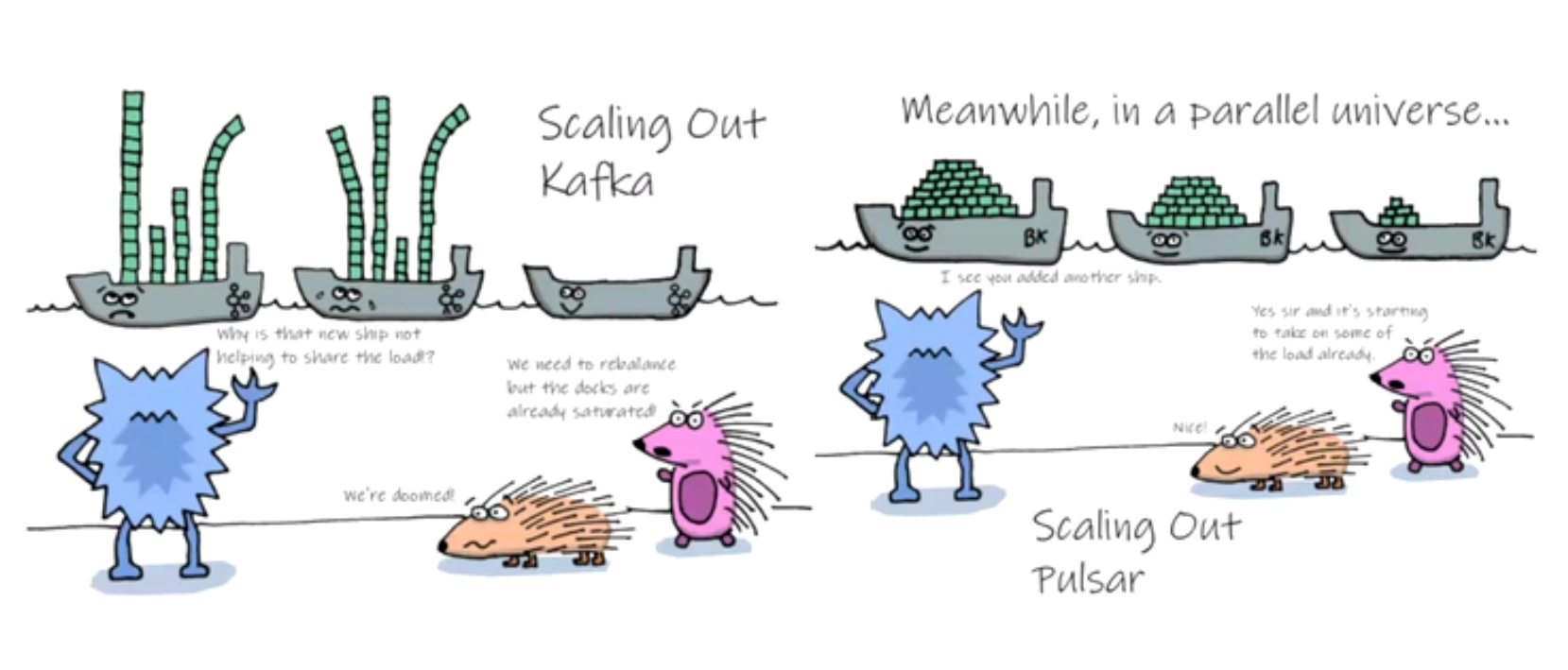
Kafka仅支持user/client-id级别、broker设置;而Pulsar则支持namespace/topic级别,粒度较小
Kafka增加新节点需要reassign partition才能使用;而Pulsar存储和计算分离,可以按需增加计算或存储节点,增加即生效,不需要reassign
Kafka消费能力受限Topic设定的partition数量;而Pulsar消费能力不受限Topic设定的partition数量,可以通过增加消费者数量增大消费能力
Kafka随着partition增多,请求下降严重,追加写模式退化为随机些;而Pulsar topic/partition仅是逻辑概念,保证追加写模式
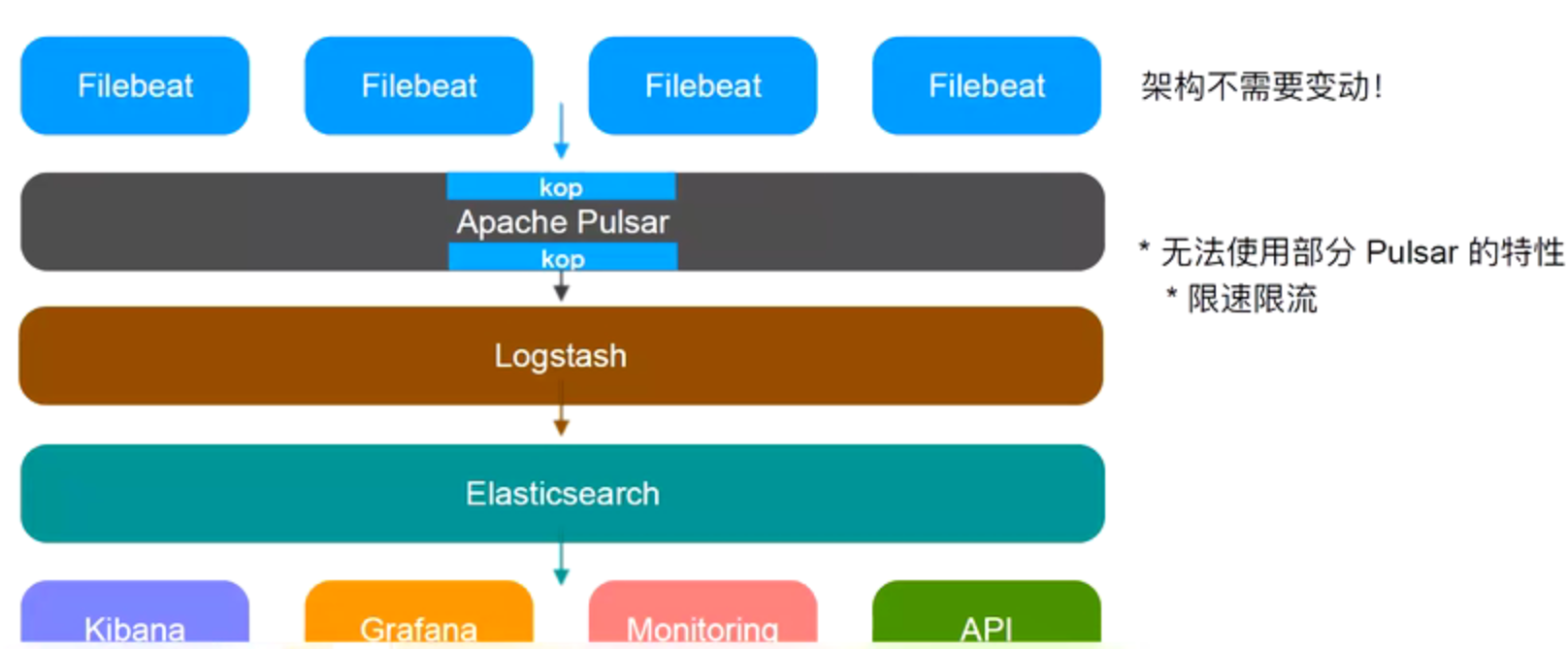
Pulsar引入架构V1
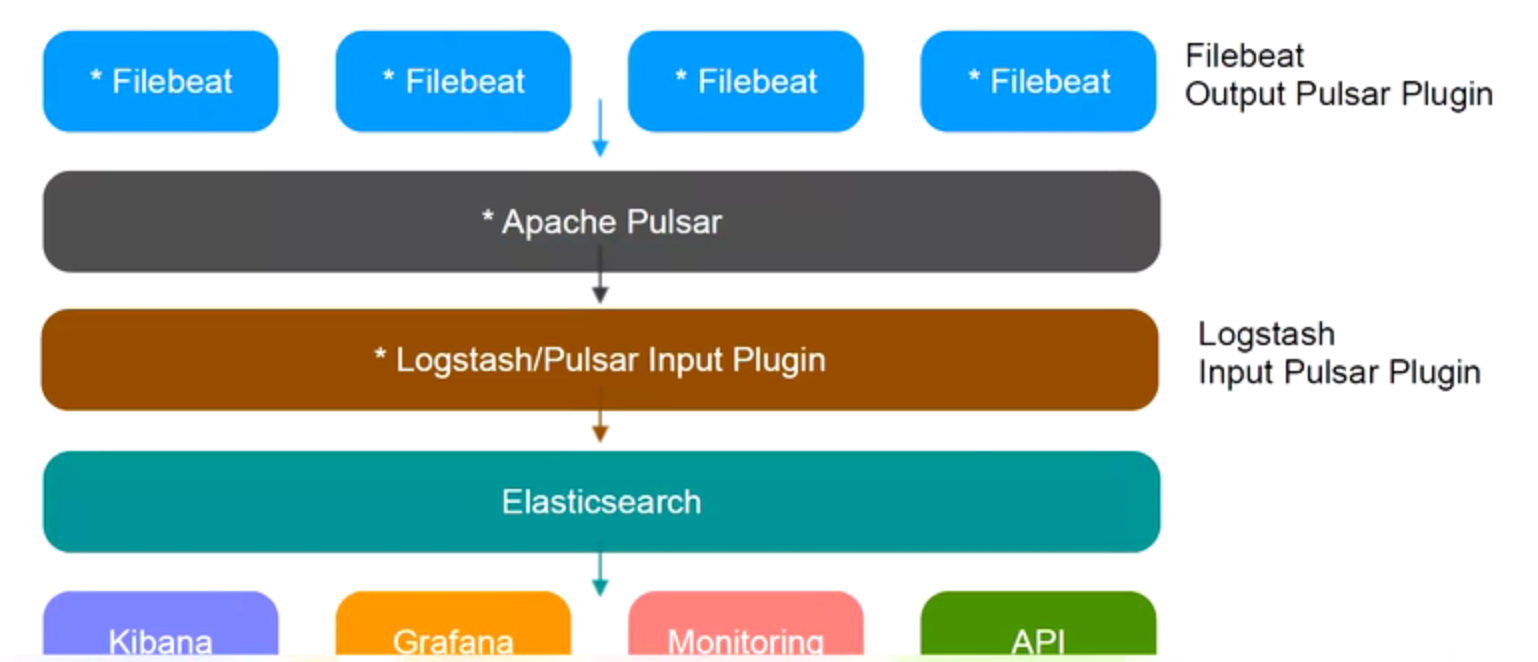
Pulsar引入架构V2
Pulsar引入架构V3
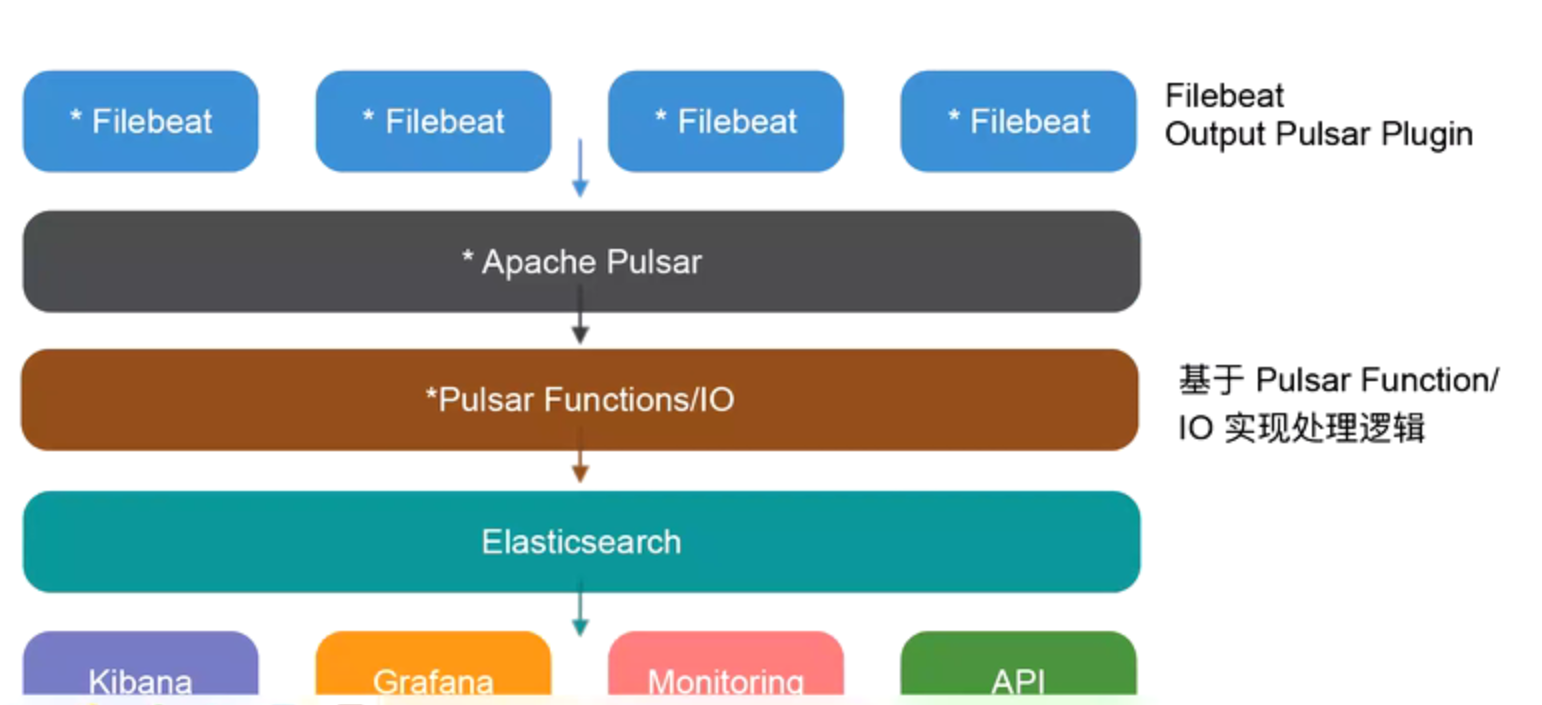
将ETL逻辑从LogStash迁移到Apache Pulsar Functions/IO中,从而起到降本提效,将数据offload到二级缓存中,满足等保要求
Pulsar引入架构V4
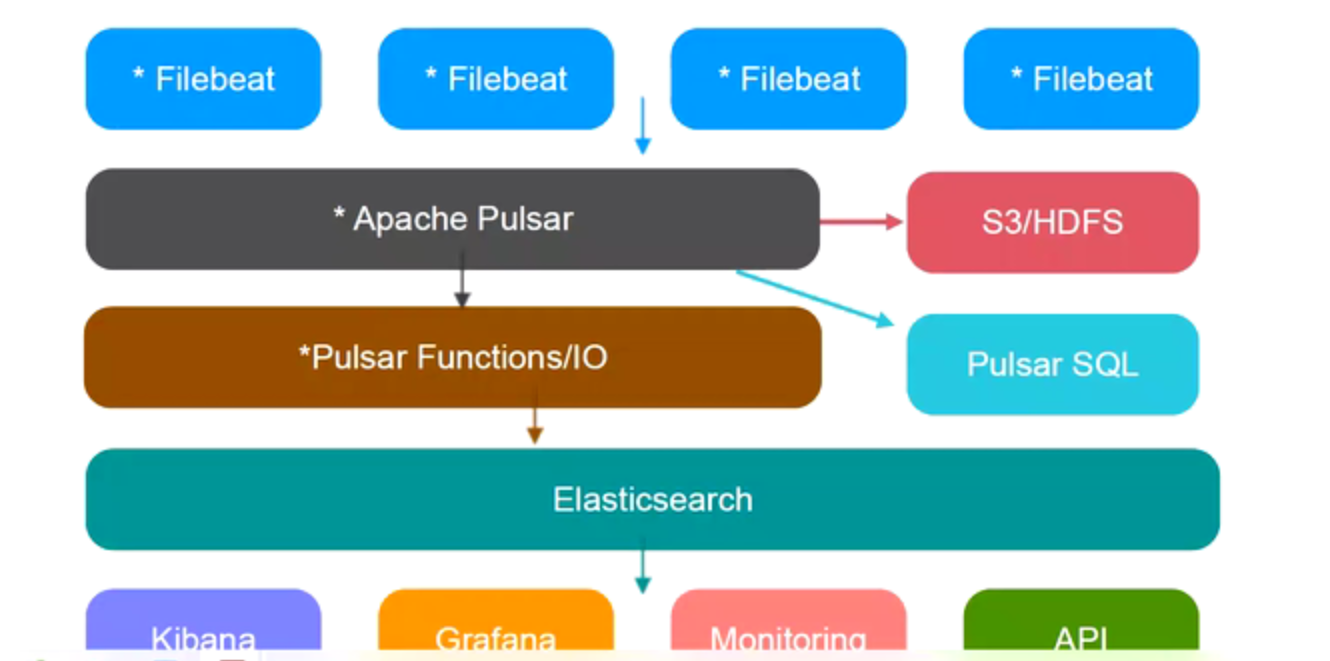
可以通过Pulsar SQL实现千万级别的精确数据查询,注意是不支持模拟查询,模拟还是需要在ES中进行
应用
- Apache Pulsar在腾讯大数据场景落地实践如TDBank-大数据实时接入平台腾讯慧聚
- Apache Pulsar在华为物联网(AMQP)之旅
- Apache Pulsar在电信计费系统的应用
- Apache Pulsar 在拉卡拉的技术实践
- KoP(Kafka on Pulsar)在 BIGO 的性能优化实践
Pulsar云原生分布式消息和流平台v2.8.0的更多相关文章
- 开源流数据公司 StreamNative 推出 Pulsar 云服务,推进企业“流优先”进程
Apache 顶级项目 Pulsar 背后的开源流数据公司 StreamNative 宣布,推出基于 Apache Pulsar 的云端服务产品--StreamNative Cloud.该产品的发布, ...
- 保姆级教程!手把手教你使用Longhorn管理云原生分布式SQL数据库!
作者简介 Jimmy Guerrero,在开发者关系团队和开源社区拥有20多年的经验.他目前领导YugabyteDB的社区和市场团队. 本文来自Rancher Labs Longhorn是Kubern ...
- DTCC 2020 | 阿里云李飞飞:云原生分布式数据库与数据仓库系统点亮数据上云之路
简介: 数据库将面临怎样的变革?云原生数据库与数据仓库有哪些独特优势?在日前的 DTCC 2020大会上,阿里巴巴集团副总裁.阿里云数据库产品事业部总裁.ACM杰出科学家李飞飞就<云原生分布式数 ...
- Longhorn 企业级云原生分布式容器存储-券(Volume)和节点(Node)
内容来源于官方 Longhorn 1.1.2 英文技术手册. 系列 Longhorn 是什么? Longhorn 云原生分布式块存储解决方案设计架构和概念 Longhorn 企业级云原生容器存储解决方 ...
- 云原生分布式文件存储 MinIO 教程
文章转载自:https://mp.weixin.qq.com/s/_52kZ5jil1Cec98P5oozoA MinIO 提供开源.高性能.兼容 s3 的对象存储,为每个公共云.每个 Kuberne ...
- Longhorn,Kubernetes 云原生分布式块存储
Longhorn 是用于 Kubernetes 的轻量级.可靠且功能强大的分布式块存储系统. Longhorn 使用容器(containers)和微服务(microservices)实现分布式块存储. ...
- Longhorn 云原生分布式块存储解决方案设计架构和概念
内容来源于官方 Longhorn 1.1.2 英文技术手册. 系列 Longhorn 是什么? 目录 1. 设计 1.1. Longhorn Manager 和 Longhorn Engine 1.2 ...
- 云原生分布式 PostgreSQL+Citus 集群在 Sentry 后端的实践
优化一个分布式系统的吞吐能力,除了应用本身代码外,很大程度上是在优化它所依赖的中间件集群处理能力.如:kafka/redis/rabbitmq/postgresql/分布式存储(CephFS,Juic ...
- Apache RocketMQ分布式消息传递和流数据平台及大厂面试宝典v4.9.2
概述 **本人博客网站 **IT小神 www.itxiaoshen.com 定义 Apache RocketMQ官网地址 https://rocketmq.apache.org/ Latest rel ...
随机推荐
- Bert文本分类实践(三):处理样本不均衡和提升模型鲁棒性trick
目录 写在前面 缓解样本不均衡 模型层面解决样本不均衡 Focal Loss pytorch代码实现 数据层面解决样本不均衡 提升模型鲁棒性 对抗训练 对抗训练pytorch代码实现 知识蒸馏 防止模 ...
- fastjson及其反序列化分析--TemplatesImpl
fastjson及其反序列化分析 源码取自 https://www.github.com/ZH3FENG/PoCs-fastjson1241 参考 (23条消息) Json详解以及fastjson使用 ...
- spring提供的可拓展接口
接口:SmartLifecycle(https://www.jianshu.com/p/7b8f2a97c8f5)
- 浅尝装饰器和AOP
[写在前面] 参考文章:https://www.cnblogs.com/huxi/archive/2011/03/01/1967600.html[从简单的例子入手进行讲解,由浅入深,很到位] 装饰器部 ...
- 用C++实现的数独解题程序 SudokuSolver 2.4 及实例分析
SudokuSolver 2.4 程序实现 本次版本实现了 用C++实现的数独解题程序 SudokuSolver 2.3 及实例分析 里发现的第三个不完全收缩 grp 算法 thirdGreenWor ...
- Noip模拟77 2021.10.15
T1 最大或 $T1$因为没有开$1ll$右移给炸掉了,调了一年不知道为啥,最后实在不懂了 换成$pow$就过掉了,但是考场上这题耽误了太多时间,后面的题也就没办法好好打了.... 以后一定要注意右移 ...
- FastAPI 学习之路(五十九)封装统一的json返回处理工具
这之前的接口,我们返回的格式都是每个接口异常返回的数据格式都会不一样,我们处理起来没有那么方便,我们可以封装一个统一的json处理. 那么我们看下如何来实现呢 from fastapi import ...
- 洛谷 P3209 [HNOI2010] 平面图判定
链接: P3209 题意: 给出 \(T\) 张无向图 \((T\leq100)\),并给出它对应的哈密顿回路,判断每张图是否是平面图. 分析: 平面图判定问题貌似是有线性做法的,这里给出链接,不是本 ...
- spring-cloud-square开发实战(三种类型全覆盖)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 前文<五分钟搞懂spring-clou ...
- Python 字符串的encode与decode
python的str,unicode对象的encode和decode方法 python中的str对象其实就是"8-bit string" ,字节字符串,本质上类似java中的byt ...