IO和零拷贝
I/O介绍
I/O模型
I/O模型分类:
一:阻塞I/O模型:在等待数据和数据复制两个阶段都处于阻塞状态
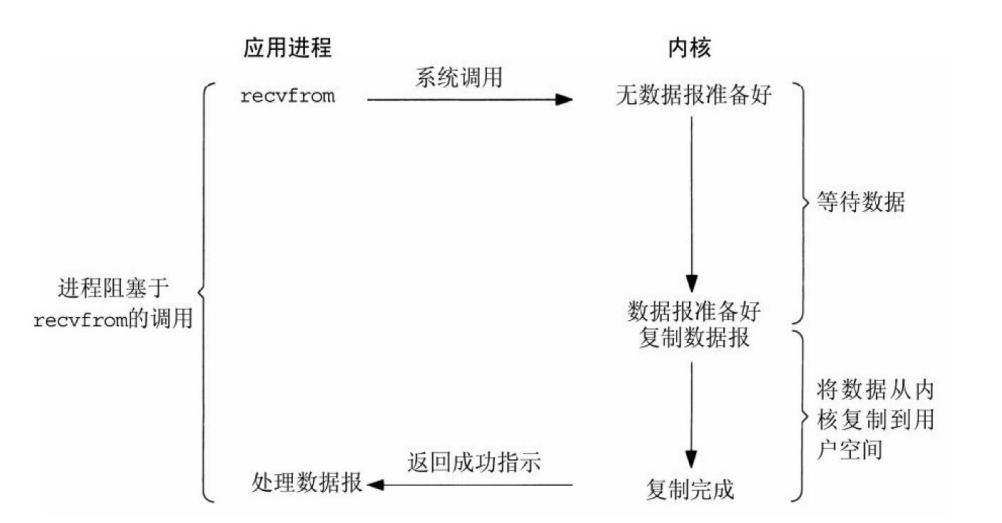
非阻塞IO模型:在等待数据和数据复制两个阶段都处于阻塞状态
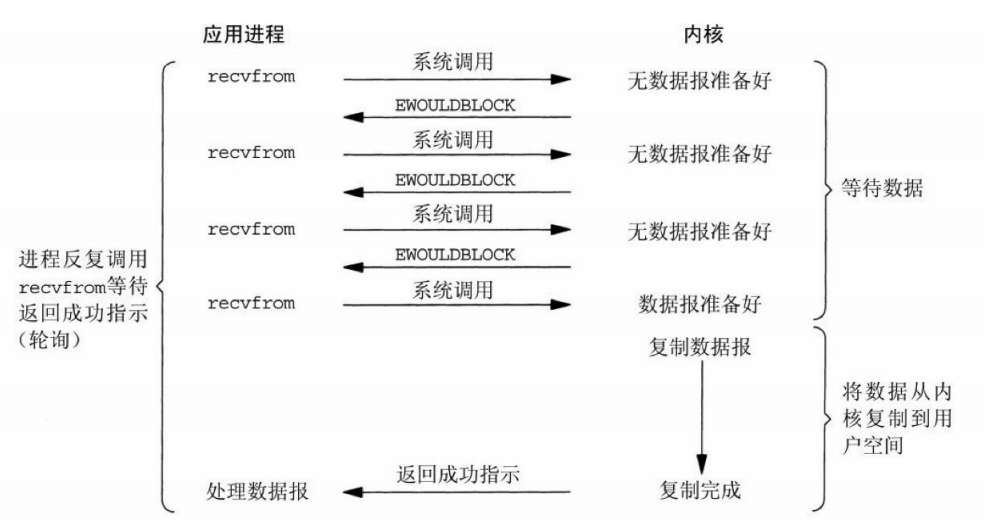
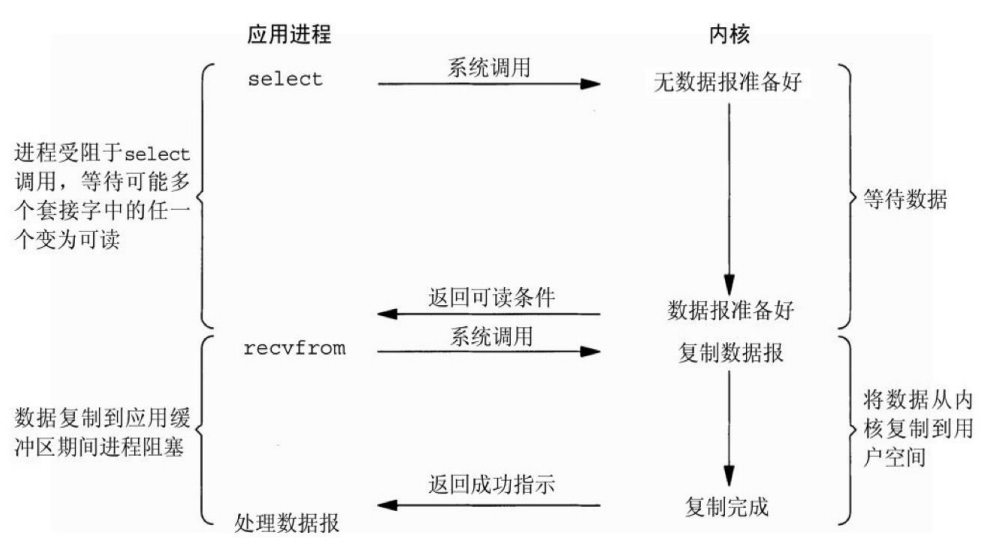
IO多路复用模型:最常用
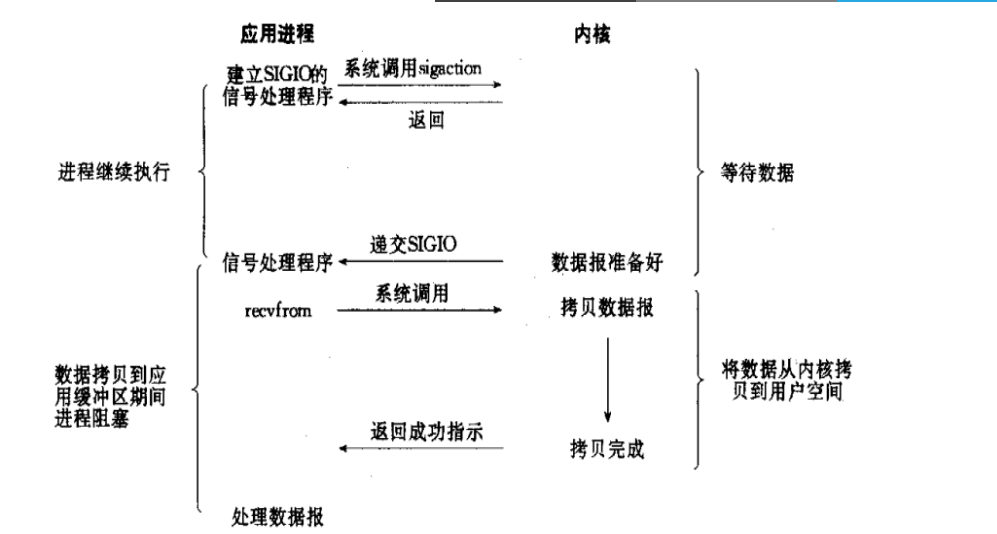
信号驱动IO:signal-driven I/O
异步IO模型
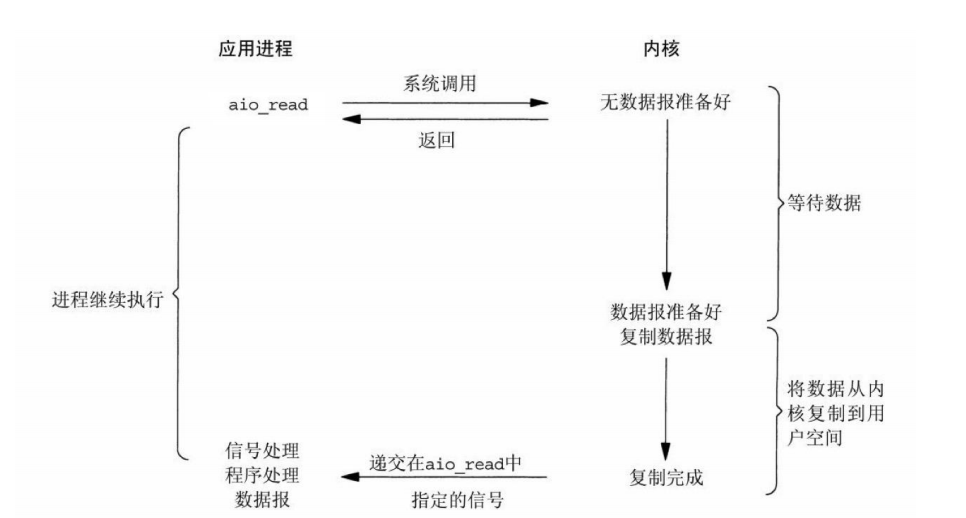
五种I/O模型对比
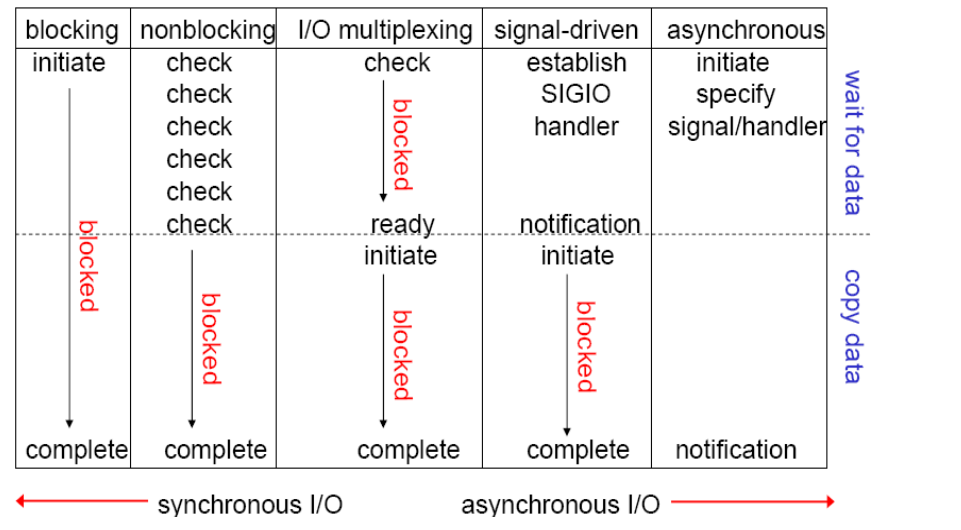
I/O模型的具体实现
select/poll/epoll
1、三种实现方式的对比。
①三种都是I/O多路复用模型的是实现
②epoll在等待数据阶段,使用了信号驱动的特性IO效率高。才使得nginx支持高并发。

零拷贝
传统Linux中 I/O 的问题
什么是零拷贝
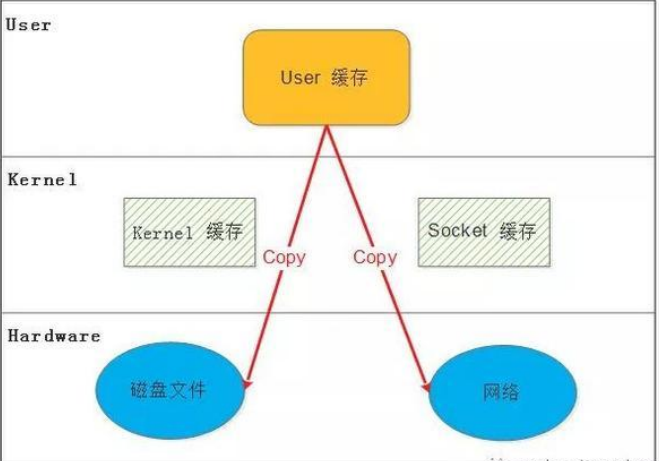
原始数据拷贝:
一次网络或者磁盘io需要先从磁盘获取数据到内核的缓存区,再拷贝到用户空间的缓冲区。这是一次完成的磁盘IO。用户空间程序处理后,构建相应报文,回复客户端。这也要经过context切换和复制。
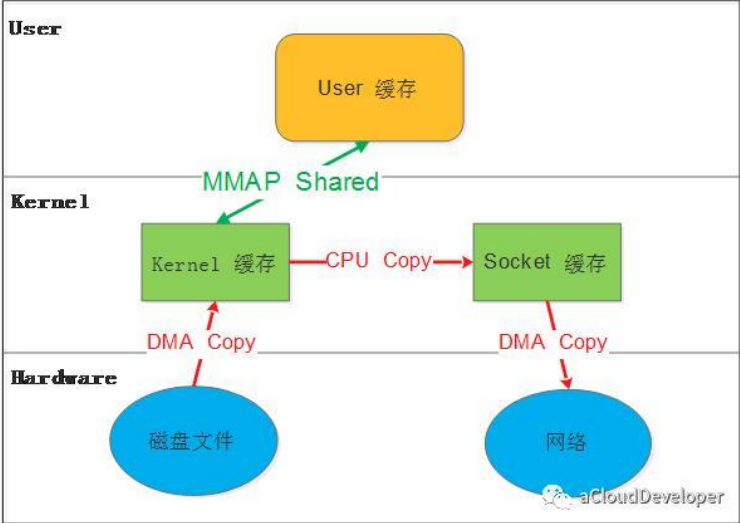
MMAP:Memory Mapping
数据到达内核的缓存后不会,复制到用户空间的缓存。而是通过内存映射,告诉user数据的位置。减少了内核空间数据向用户空间的复制,直接再内核的内存区域中复制到socket缓存,发送给客户端。
SENDFILE:直接再内核空间内复制数据,相应请求

DMA 辅助的 SENDFILE,省去了kerner 缓存到socket缓存的复制。

IO和零拷贝的更多相关文章
- 操作系统IO之零拷贝技术
磁盘可以说是计算机系统最慢的硬件之一,读写速度相差内存 10 倍以上,所以针对优化磁盘的技术非常的多,比如零拷贝.直接 I/O.异步 I/O 等等,这些优化的目的就是为了提高系统的吞吐量,另外操作系统 ...
- 直接IO 零拷贝 DAM 自缓存应用程序
直接IO 零拷贝 DAM 自缓存应用程序
- 深入剖析Linux IO原理和几种零拷贝机制的实现
深入剖析Linux IO原理和几种零拷贝机制的实现 来源 https://zhuanlan.zhihu.com/p/83398714 零壹技术栈 公众号[零壹技术栈] 前言 零拷贝(Zero ...
- 传统IO拷贝与零拷贝技术比较
1. 传统IO 由上面图知,传统io需要经过4次copy, 3次状态切换 第一次: 从硬盘 经过 DMA 拷贝 到 kernel buffer (内核buferr) 第二次: 从kernel buff ...
- Linux零拷贝技术 直接 io
Linux零拷贝技术 .https://kknews.cc/code/2yeazxe.html https://zhuanlan.zhihu.com/p/76640160 https://clou ...
- NIO学习笔记,从Linux IO演化模型到Netty—— Netty零拷贝
Netty的中零拷贝与上述零拷贝是不一样的,它并不是系统层面上的零拷贝,只是相对于ByteBuf而言的,更多的是偏向于数据操作优化这样的概念. Netty中的零拷贝: 1.CompositeByteB ...
- NIO学习笔记,从Linux IO演化模型到Netty—— Java NIO零拷贝
同样只是大致上的认识. 其中,当使用transferFrom,transferTo的时候用的sendfile(). 如果系统内核不支持 sendfile,进一步执行 transferToTrusted ...
- NIO学习笔记,从Linux IO演化模型到Netty—— Linux零拷贝
这里只是感性地认识Linux零拷贝,不涉及具体细节. 1.Linux传统的数据拷贝 用户进程是不能直接访问文件系统的,要先切换到内核态,发起系统调用,DMA把磁盘中的数据写入内核空间,内核再把数据拷贝 ...
- Linux 零拷贝技术
简介 零拷贝(zero-copy)技术可以减少数据拷贝和共享总线操作的次数,消除通信数据在存储器之间不必要的中间拷贝过程,有效地提高通信效率,是设计高速接口通道.实现高速服务器和路由器的关键技术之一. ...
随机推荐
- Java文件I/O简单介绍
目录 一.File类 1.1 构造方法 1.2 常用方法 1.3 例子 二.基础I/O:字节流.字符流 2.1 字节流 2.1.1 字节输出流 OutputStream 2.1.2 FileOutpu ...
- webSocket实现多人聊天功能
webSocket实现多人在线聊天 主要思路如下: 1.使用vue构建简单的聊天室界面 2.基于nodeJs 的webSocket开启一个socket后台服务,前端使用H5的webSocket来创建一 ...
- 常用PLC与ifix/intouch驱动地址匹配规则
常用PLC与IFIX /的InTouch驱动地址匹配规则如下(持续更新): 1.施耐德M580<----->Intouch的/ IFIX: AI:400102<-----> 4 ...
- H5页面怎么跳转到公众号主页?看过来
前言: 做公众号开发的小伙伴,可能会遇到这种需求: 在一个H5页面点击一个关注公众号按钮跳转到公众号主页. 听到这个需求的一瞬间,疑惑了!这不可能! 摸了摸高亮的额头!没办法,做还是要做的 开始上解决 ...
- 浅谈Java类中的变量初始化顺序
一.变量与构造器的初始化顺序 我们知道一个类中具有类变量.类方法和构造器(方法中的局部变量不讨论,他们是在方法调用时才被初始化),当我们初始化创建一个类对象时,其初始化的顺序为:先初始化类变量,再执行 ...
- swift文件调用oc分类时崩溃解决办法(可能全网唯一)
背景 oc为基础创建的sdk混编工程,在被sdk关联的混编demo工程中swift文件调用时,会崩溃,提示找不到sdk中oc分类方法.常规的,在demo中设置-Objc和-all_load也还是会崩. ...
- Jetpack Compose 1.0 终于要投入使用了!
前言 Jetpack Compose 是用于构建原生界面的「新款 Android 工具包」.2021 Google IO 大会上,Google宣布:「Jetpack Compose 1.0 即将面世」 ...
- 2020年!最全Android大厂面试真题合集(附答案)
这份Android面试真题涵盖了图片,网络和安全机制,网络,数据库,插件化.模块化.组件化.热修复.增量更新.Gradle,架构设计和设计模式,Android Framework .Android优秀 ...
- NTP 集群简略部署指南
NTP 集群简略部署指南 by 无若 1. NTP 简介 网络时间协议(英语:Network Time Protocol,简称NTP)是在数据网络潜伏时间可变的计算机系统之间通过分组交换进行时钟同步的 ...
- Create Shortcut to Get Jar File Meta Information
You have to get meta information of cobertura.jar with command "unzip -q -c cobertura.jar META- ...