循环神经网络LSTM RNN回归:sin曲线预测
摘要:本篇文章将分享循环神经网络LSTM RNN如何实现回归预测。
本文分享自华为云社区《[Python人工智能] 十四.循环神经网络LSTM RNN回归案例之sin曲线预测 丨【百变AI秀】》,作者:eastmount。
一.RNN和LSTM回顾
1.RNN
(1) RNN原理
循环神经网络英文是Recurrent Neural Networks,简称RNN。假设有一组数据data0、data1、data2、data3,使用同一个神经网络预测它们,得到对应的结果。如果数据之间是有关系的,比如做菜下料的前后步骤,英文单词的顺序,如何让数据之间的关联也被神经网络学习呢?这就要用到——RNN。
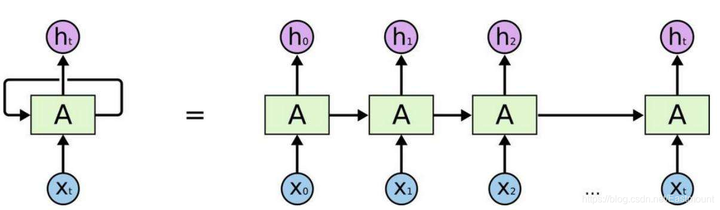
假设存在ABCD数字,需要预测下一个数字E,会根据前面ABCD顺序进行预测,这就称为记忆。预测之前,需要回顾以前的记忆有哪些,再加上这一步新的记忆点,最终输出output,循环神经网络(RNN)就利用了这样的原理。
首先,让我们想想人类是怎么分析事物之间的关联或顺序的。人类通常记住之前发生的事情,从而帮助我们后续的行为判断,那么是否能让计算机也记住之前发生的事情呢?
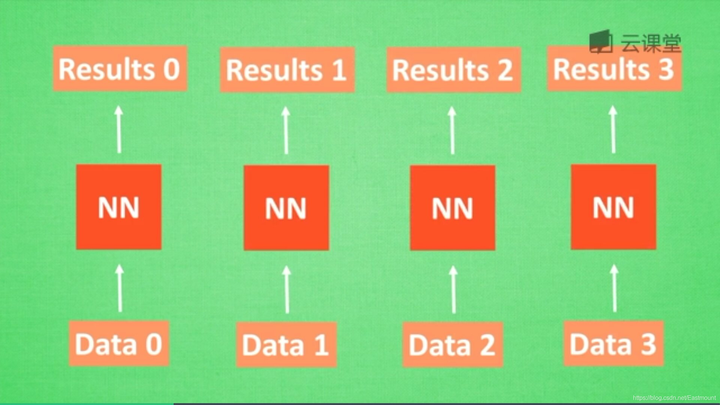
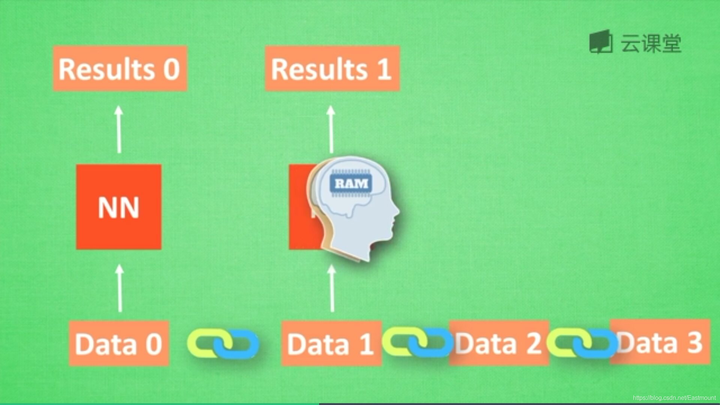
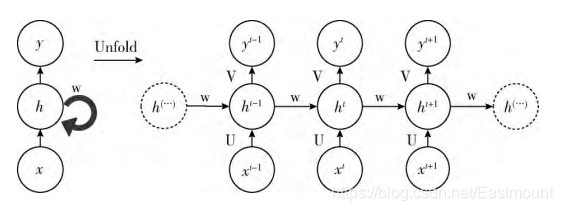
在分析data0时,我们把分析结果存入记忆Memory中,然后当分析data1时,神经网络(NN)会产生新的记忆,但此时新的记忆和老的记忆没有关联,如上图所示。在RNN中,我们会简单的把老记忆调用过来分析新记忆,如果继续分析更多的数据时,NN就会把之前的记忆全部累积起来。
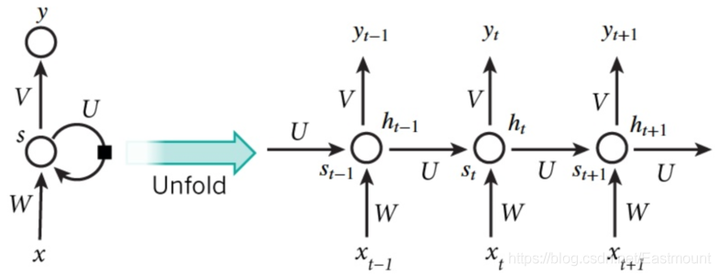
RNN结构如下图所示,按照时间点t-1、t、t+1,每个时刻有不同的x,每次计算会考虑上一步的state和这一步的x(t),再输出y值。在该数学形式中,每次RNN运行完之后都会产生s(t),当RNN要分析x(t+1)时,此刻的y(t+1)是由s(t)和s(t+1)共同创造的,s(t)可看作上一步的记忆。多个神经网络NN的累积就转换成了循环神经网络,其简化图如下图的左边所示。
总之,只要你的数据是有顺序的,就可以使用RNN,比如人类说话的顺序,电话号码的顺序,图像像素排列的顺序,ABC字母的顺序等。在前面讲解CNN原理时,它可以看做是一个滤波器滑动扫描整幅图像,通过卷积加深神经网络对图像的理解。
而RNN也有同样的扫描效果,只不过是增加了时间顺序和记忆功能。RNN通过隐藏层周期性的连接,从而捕获序列化数据中的动态信息,提升预测结果。
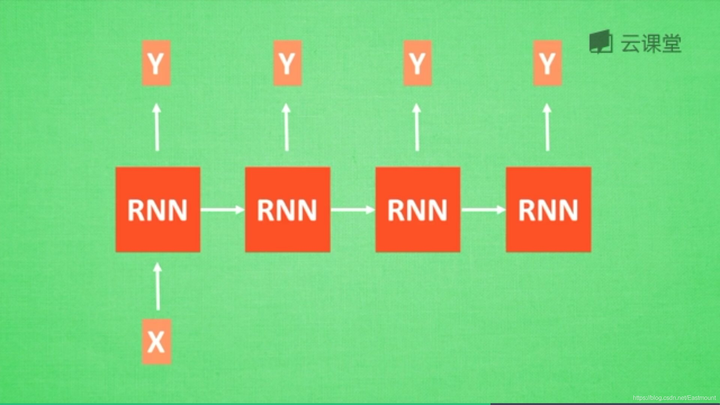
(2) RNN应用
RNN常用于自然语言处理、机器翻译、语音识别、图像识别等领域,下面简单分享RNN相关应用所对应的结构。
- RNN情感分析: 当分析一个人说话情感是积极的还是消极的,就用如下图所示的RNN结构,它有N个输入,1个输出,最后时间点的Y值代表最终的输出结果。

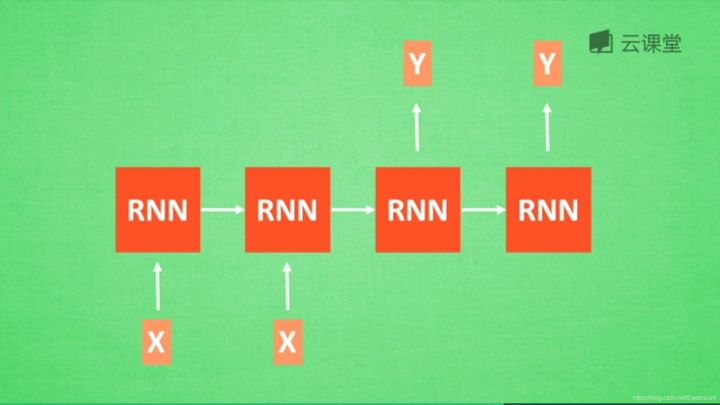
- RNN图像识别: 此时有一张图片输入X,N张对应的输出。
- RNN机器翻译: 输入和输出分别两个,对应的是中文和英文,如下图所示。
2.LSTM
接下来我们看一个更强大的结构,称为LSTM。
(1) 为什么要引入LSTM呢?
RNN是在有序的数据上进行学习的,RNN会像人一样对先前的数据发生记忆,但有时候也会像老爷爷一样忘记先前所说。为了解决RNN的这个弊端,提出了LTSM技术,它的英文全称是Long short-term memory,长短期记忆,也是当下最流行的RNN之一。
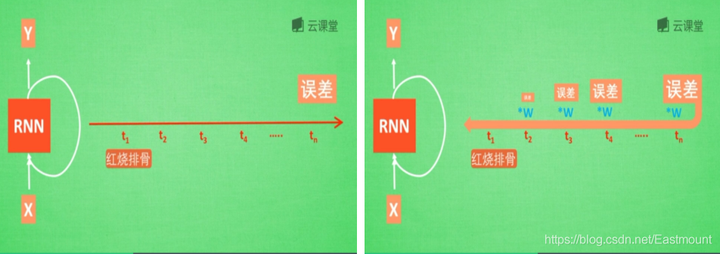
假设现在有一句话,如下图所示,RNN判断这句话是红烧排骨,这时需要学习,而“红烧排骨“在句子开头。

"红烧排骨"这个词需要经过长途跋涉才能抵达,要经过一系列得到误差,然后经过反向传递,它在每一步都会乘以一个权重w参数。如果乘以的权重是小于1的数,比如0.9,0.9会不断地乘以误差,最终这个值传递到初始值时,误差就消失了,这称为梯度消失或梯度离散。
反之,如果误差是一个很大的数,比如1.1,则这个RNN得到的值会很大,这称为梯度爆炸。
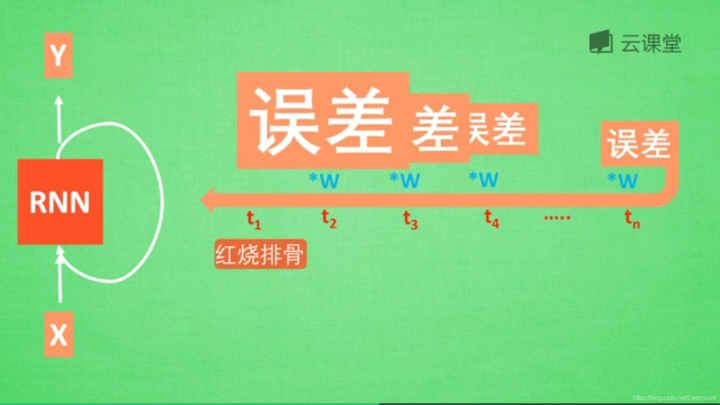
梯度消失或梯度爆炸:在RNN中,如果你的State是一个很长的序列,假设反向传递的误差值是一个小于1的数,每次反向传递都会乘以这个数,0.9的n次方趋向于0,1.1的n次方趋向于无穷大,这就会造成梯度消失或梯度爆炸。
这也是RNN没有恢复记忆的原因,为了解决RNN梯度下降时遇到的梯度消失或梯度爆炸问题,引入了LSTM。
(2) LSTM
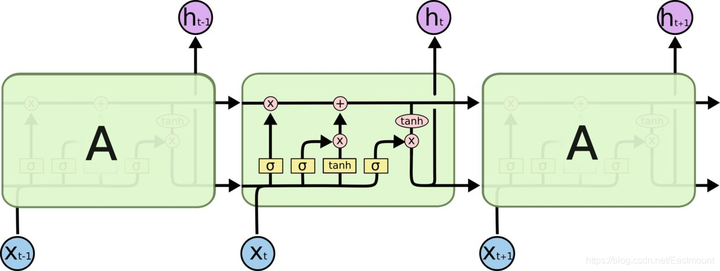
LSTM是在普通的RNN上面做了一些改进,LSTM RNN多了三个控制器,即输入、输出、忘记控制器。左边多了个条主线,例如电影的主线剧情,而原本的RNN体系变成了分线剧情,并且三个控制器都在分线上。

- 输入控制器(write gate): 在输入input时设置一个gate,gate的作用是判断要不要写入这个input到我们的内存Memory中,它相当于一个参数,也是可以被训练的,这个参数就是用来控制要不要记住当下这个点。
- 输出控制器(read gate): 在输出位置的gate,判断要不要读取现在的Memory。
- 忘记控制器(forget gate): 处理位置的忘记控制器,判断要不要忘记之前的Memory。
LSTM工作原理为:如果分线剧情对于最终结果十分重要,输入控制器会将这个分线剧情按重要程度写入主线剧情,再进行分析;如果分线剧情改变了我们之前的想法,那么忘记控制器会将某些主线剧情忘记,然后按比例替换新剧情,所以主线剧情的更新就取决于输入和忘记控制;最后的输出会基于主线剧情和分线剧情。
通过这三个gate能够很好地控制我们的RNN,基于这些控制机制,LSTM是延缓记忆的良药,从而带来更好的结果。
二.LSTM RNN回归案例说明
前面我们讲解了RNN、CNN的分类问题,这篇文章将分享一个回归问题。在LSTM RNN回归案例中,我们想要用蓝色的虚线预测红色的实线,由于sin曲线是波浪循环,所以RNN会用一段序列来预测另一段序列。
代码基本结构包括:
- (1) 生成数据的函数get_batch()
- (2) 主体LSTM RNN
- (3) 三层神经网络,包括input_layer、cell、output_layer,和之前分类RNN的结构一样。
def add_input_layer(self,):
pass
def add_cell(self):
pass
def add_output_layer(self):
pass
- (4) 计算误差函数 computer_cost
- (5) 误差weight和偏置biases
- (6) 主函数建立LSTM RNN模型
- (7) TensorBoard可视化神经网络模型,matplotlib可视化拟合曲线、
最后再补充下BPTT,就开始我们的代码编写。
(1) 普通RNN
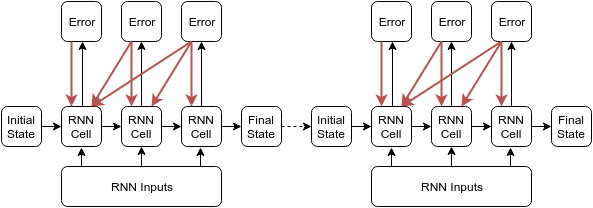
假设我们训练含有1000000个数据的序列,如果全部训练的话,整个的序列都feed进RNN中,容易造成梯度消失或爆炸的问题。所以解决的方法就是截断反向传播 (Truncated Backpropagation,BPTT) ,我们将序列截断来进行训练(num_steps)。
一般截断的反向传播是:在当前时间t,往前反向传播num_steps步即可。如下图,长度为6的序列,截断步数是3,Initial State和Final State在RNN Cell中传递。

(2) TensorFlow版本的BPTT
但是Tensorflow中的实现并不是这样,它是将长度为6的序列分为了两部分,每一部分长度为3,前一部分计算得到的final state用于下一部分计算的initial state。如下图所示,每个batch进行单独的截断反向传播。此时的batch会保存Final State,并作为下一个batch的初始化State。
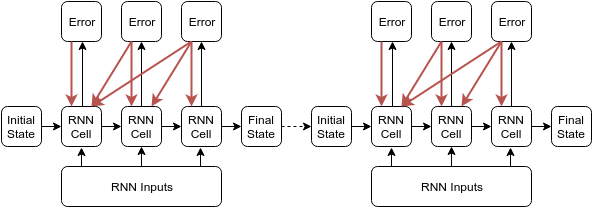
参考:深度学习(07)RNN-循环神经网络-02-Tensorflow中的实现 - 莫失莫忘Lawlite
三.代码实现
第一步,打开Anaconda,然后选择已经搭建好的“tensorflow”环境,运行Spyder。
第二步,导入扩展包。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
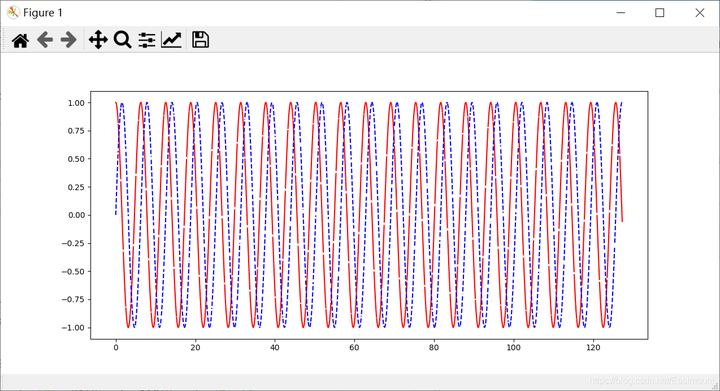
第三步,编写生成数据的函数get_batch(),它生成了sin曲线的序列。
# 获取批量数据
def get_batch():
global BATCH_START, TIME_STEPS
# xs shape (50batch, 20steps)
xs = np.arange(BATCH_START, BATCH_START+TIME_STEPS*BATCH_SIZE).reshape((BATCH_SIZE, TIME_STEPS)) / (10*np.pi)
seq = np.sin(xs)
res = np.cos(xs)
BATCH_START += TIME_STEPS
# 显示原始曲线
plt.plot(xs[0, :], res[0, :], 'r', xs[0, :], seq[0, :], 'b--')
plt.show()
# 返回序列seq 结果res 输入xs
return [seq[:, :, np.newaxis], res[:, :, np.newaxis], xs]
此时的输出结果如下图所示,注意它只是模拟的预期曲线,还不是我们神经网络学习的结构。
第四步,编写LSTMRNN类,它用于定义我们的循环神经网络结构,初始化操作和所需变量。
初始化init()函数的参数包括:
- n_steps表示batch中的步骤,共有3步。
- input_size表示传入batch data时,每个input的长度,该实例中input_size和output_size均为1。如下图所示,假设我们batch长度为一个周期(0-6),每个input是线的x值,input size表示每个时间点有多少个值,只有一个点故为1。
- output_size表示输出的值,输出对应input线的y值,其大小值为1。
- cell_size表示RNN Cell的个数,其值为10。
- batch_size表示一次性传给神经网络的batch数量,设置为50。
该部分代码如下,注意xs和ys的形状。同时,我们需要使用Tensorboard可视化RNN的结构,所以调用tf.name_scope()设置各神经层和变量的命名空间名称,详见第五篇文章。
#----------------------------------定义参数----------------------------------
BATCH_START = 0
TIME_STEPS = 20
BATCH_SIZE = 50 # BATCH数量
INPUT_SIZE = 1 # 输入一个值
OUTPUT_SIZE = 1 # 输出一个值
CELL_SIZE = 10 # Cell数量
LR = 0.006
BATCH_START_TEST = 0 #----------------------------------LSTM RNN----------------------------------
class LSTMRNN(object):
# 初始化操作
def __init__(self, n_steps, input_size, output_size, cell_size, batch_size):
self.n_steps = n_steps
self.input_size = input_size
self.output_size = output_size
self.cell_size = cell_size
self.batch_size = batch_size # TensorBoard可视化操作使用name_scope
with tf.name_scope('inputs'): #输出变量
self.xs = tf.placeholder(tf.float32, [None, n_steps, input_size], name='xs')
self.ys = tf.placeholder(tf.float32, [None, n_steps, output_size], name='ys')
with tf.variable_scope('in_hidden'): #输入层
self.add_input_layer()
with tf.variable_scope('LSTM_cell'): #处理层
self.add_cell()
with tf.variable_scope('out_hidden'): #输出层
self.add_output_layer()
with tf.name_scope('cost'): #误差
self.compute_cost()
with tf.name_scope('train'): #训练
self.train_op = tf.train.AdamOptimizer(LR).minimize(self.cost)
第五步,接着开始编写三个函数(三层神经网络),它是RNN的核心结构。
# 输入层
def add_input_layer(self,):
pass
# cell层
def add_cell(self):
pass
# 输出层
def add_output_layer(self):
pass
这三个函数也是增加在LSTMRNN的Class中,核心代码及详细注释如下所示:
#--------------------------------定义核心三层结构-----------------------------
# 输入层
def add_input_layer(self,):
# 定义输入层xs变量 将xs三维数据转换成二维
# [None, n_steps, input_size] => (batch*n_step, in_size)
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='2_2D')
# 定义输入权重 (in_size, cell_size)
Ws_in = self._weight_variable([self.input_size, self.cell_size])
# 定义输入偏置 (cell_size, )
bs_in = self._bias_variable([self.cell_size,])
# 定义输出y变量 二维形状 (batch * n_steps, cell_size)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# 返回结果形状转变为三维
# l_in_y ==> (batch, n_steps, cell_size)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='2_3D') # cell层
def add_cell(self):
# 选择BasicLSTMCell模型
# forget初始偏置为1.0(初始时不希望forget) 随着训练深入LSTM会选择性忘记
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
# 设置initial_state全为0 可视化操作用name_scope
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
# RNN循环 每一步的输出都存储在cell_outputs序列中 cell_final_state为最终State并传入下一个batch中
# 常规RNN只有m_state LSTM包括c_state和m_state
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False) # 输出层 (类似输入层)
def add_output_layer(self):
# 转换成二维 方能使用W*X+B
# shape => (batch * steps, cell_size)
l_out_x = tf.reshape(self.cell_outputs, [-1, self.cell_size], name='2_2D')
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size, ])
# 返回预测结果
# shape => (batch * steps, output_size)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(l_out_x, Ws_out) + bs_out
注意,上面调用了reshape()进行形状更新,为什么要将三维变量改成二维呢?因为只有变成二维变量之后,才能计算W*X+B。
第六步,定义计算误差函数。
这里需要注意:我们使用了seq2seq函数。它求出的loss是整个batch每一步的loss,然后把每一步loss进行sum求和,变成了整个TensorFlow的loss,再除以batch size平均,最终得到这个batch的总cost,它是一个scalar数字。
# 定义误差计算函数
def compute_cost(self):
# 使用seq2seq序列到序列模型
# tf.nn.seq2seq.sequence_loss_by_example()
losses = tf.contrib.legacy_seq2seq.sequence_loss_by_example(
[tf.reshape(self.pred, [-1], name='reshape_pred')],
[tf.reshape(self.ys, [-1], name='reshape_target')],
[tf.ones([self.batch_size * self.n_steps], dtype=tf.float32)],
average_across_timesteps=True,
softmax_loss_function=self.msr_error,
name='losses'
)
# 最终得到batch的总cost 它是一个数字
with tf.name_scope('average_cost'):
# 整个TensorFlow的loss求和 再除以batch size
self.cost = tf.div(
tf.reduce_sum(losses, name='losses_sum'),
self.batch_size,
name='average_cost')
tf.summary.scalar('cost', self.cost)
后面的文章我们会详细写一篇机器翻译相关的内容,并使用seq2seq模型。
Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。如下图所,输入的中文长度为4,输出的英文长度为2。
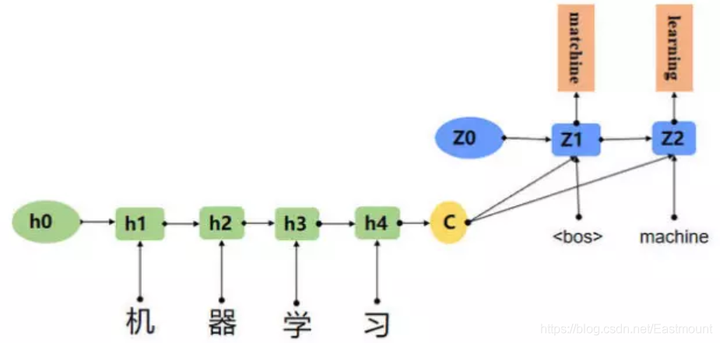
在网络结构中,输入一个中文序列,然后输出它对应的中文翻译,输出的部分的结果预测后面,根据上面的例子,也就是先输出“machine”,将"machine"作为下一次的输入,接着输出"learning",这样就能输出任意长的序列。
机器翻译、人机对话、聊天机器人等等,这些都是应用在当今社会都或多或少的运用到了我们这里所说的Seq2Seq。
第七步,定义msr_error计算函数、误差计算函数和偏置计算函数。
# 该函数用于计算
# 相当于msr_error(self, y_pre, y_target) return tf.square(tf.sub(y_pre, y_target))
def msr_error(self, logits, labels):
return tf.square(tf.subtract(logits, labels))
# 误差计算
def _weight_variable(self, shape, name='weights'):
initializer = tf.random_normal_initializer(mean=0., stddev=1.,)
return tf.get_variable(shape=shape, initializer=initializer, name=name)
# 偏置计算
def _bias_variable(self, shape, name='biases'):
initializer = tf.constant_initializer(0.1)
return tf.get_variable(name=name, shape=shape, initializer=initializer)
写到这里,整个Class就定义完成。
第八步,接下来定义主函数,进行训练和预测操作,这里先尝试TensorBoard可视化展现。
#----------------------------------主函数 训练和预测----------------------------------
if __name__ == '__main__':
# 定义模型并初始化
model = LSTMRNN(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess = tf.Session()
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("logs", sess.graph)
sess.run(tf.initialize_all_variables())
四.完整代码及可视化展示
该阶段的完整代码如下,我们先尝试运行下代码:
# -*- coding: utf-8 -*-
"""
Created on Thu Jan 9 20:44:56 2020
@author: xiuzhang Eastmount CSDN
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt #----------------------------------定义参数----------------------------------
BATCH_START = 0
TIME_STEPS = 20
BATCH_SIZE = 50 # BATCH数量
INPUT_SIZE = 1 # 输入一个值
OUTPUT_SIZE = 1 # 输出一个值
CELL_SIZE = 10 # Cell数量
LR = 0.006
BATCH_START_TEST = 0 # 获取批量数据
def get_batch():
global BATCH_START, TIME_STEPS
# xs shape (50batch, 20steps)
xs = np.arange(BATCH_START, BATCH_START+TIME_STEPS*BATCH_SIZE).reshape((BATCH_SIZE, TIME_STEPS)) / (10*np.pi)
seq = np.sin(xs)
res = np.cos(xs)
BATCH_START += TIME_STEPS
# 返回序列seq 结果res 输入xs
return [seq[:, :, np.newaxis], res[:, :, np.newaxis], xs] #----------------------------------LSTM RNN----------------------------------
class LSTMRNN(object):
# 初始化操作
def __init__(self, n_steps, input_size, output_size, cell_size, batch_size):
self.n_steps = n_steps
self.input_size = input_size
self.output_size = output_size
self.cell_size = cell_size
self.batch_size = batch_size # TensorBoard可视化操作使用name_scope
with tf.name_scope('inputs'): #输出变量
self.xs = tf.placeholder(tf.float32, [None, n_steps, input_size], name='xs')
self.ys = tf.placeholder(tf.float32, [None, n_steps, output_size], name='ys')
with tf.variable_scope('in_hidden'): #输入层
self.add_input_layer()
with tf.variable_scope('LSTM_cell'): #处理层
self.add_cell()
with tf.variable_scope('out_hidden'): #输出层
self.add_output_layer()
with tf.name_scope('cost'): #误差
self.compute_cost()
with tf.name_scope('train'): #训练
self.train_op = tf.train.AdamOptimizer(LR).minimize(self.cost) #--------------------------------定义核心三层结构-----------------------------
# 输入层
def add_input_layer(self,):
# 定义输入层xs变量 将xs三维数据转换成二维
# [None, n_steps, input_size] => (batch*n_step, in_size)
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='2_2D')
# 定义输入权重 (in_size, cell_size)
Ws_in = self._weight_variable([self.input_size, self.cell_size])
# 定义输入偏置 (cell_size, )
bs_in = self._bias_variable([self.cell_size,])
# 定义输出y变量 二维形状 (batch * n_steps, cell_size)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# 返回结果形状转变为三维
# l_in_y ==> (batch, n_steps, cell_size)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='2_3D') # cell层
def add_cell(self):
# 选择BasicLSTMCell模型
# forget初始偏置为1.0(初始时不希望forget) 随着训练深入LSTM会选择性忘记
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
# 设置initial_state全为0 可视化操作用name_scope
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
# RNN循环 每一步的输出都存储在cell_outputs序列中 cell_final_state为最终State并传入下一个batch中
# 常规RNN只有m_state LSTM包括c_state和m_state
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False) # 输出层 (类似输入层)
def add_output_layer(self):
# 转换成二维 方能使用W*X+B
# shape => (batch * steps, cell_size)
l_out_x = tf.reshape(self.cell_outputs, [-1, self.cell_size], name='2_2D')
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size, ])
# 返回预测结果
# shape => (batch * steps, output_size)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(l_out_x, Ws_out) + bs_out #--------------------------------定义误差计算函数-----------------------------
def compute_cost(self):
# 使用seq2seq序列到序列模型
# tf.nn.seq2seq.sequence_loss_by_example()
losses = tf.contrib.legacy_seq2seq.sequence_loss_by_example(
[tf.reshape(self.pred, [-1], name='reshape_pred')],
[tf.reshape(self.ys, [-1], name='reshape_target')],
[tf.ones([self.batch_size * self.n_steps], dtype=tf.float32)],
average_across_timesteps=True,
softmax_loss_function=self.msr_error,
name='losses'
)
# 最终得到batch的总cost 它是一个数字
with tf.name_scope('average_cost'):
# 整个TensorFlow的loss求和 再除以batch size
self.cost = tf.div(
tf.reduce_sum(losses, name='losses_sum'),
self.batch_size,
name='average_cost')
tf.summary.scalar('cost', self.cost) # 该函数用于计算
# 相当于msr_error(self, y_pre, y_target) return tf.square(tf.sub(y_pre, y_target))
def msr_error(self, logits, labels):
return tf.square(tf.subtract(logits, labels))
# 误差计算
def _weight_variable(self, shape, name='weights'):
initializer = tf.random_normal_initializer(mean=0., stddev=1.,)
return tf.get_variable(shape=shape, initializer=initializer, name=name)
# 偏置计算
def _bias_variable(self, shape, name='biases'):
initializer = tf.constant_initializer(0.1)
return tf.get_variable(name=name, shape=shape, initializer=initializer) #----------------------------------主函数 训练和预测----------------------------------
if __name__ == '__main__':
# 定义模型并初始化
model = LSTMRNN(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess = tf.Session()
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("logs", sess.graph)
sess.run(tf.initialize_all_variables())
此时会在Python文件目录下新建一个“logs”文件夹和events的文件,如下图所示。
接下来尝试打开它。首先调出Anaconda Prompt,并激活TensorFlow,接着去到events文件的目录,调用命令“tensorboard --logdir=logs运行即可,如下图所示。注意,这里只需要指引到文件夹,它就会自动索引到你的文件。
activate tensorflow
cd\
cd C:\Users\xiuzhang\Desktop\TensorFlow\blog
tensorboard --logdir=logs
此时访问网址“http://localhost:6006/”,选择“Graphs”,运行之后如下图所示,我们的神经网络就出现了。
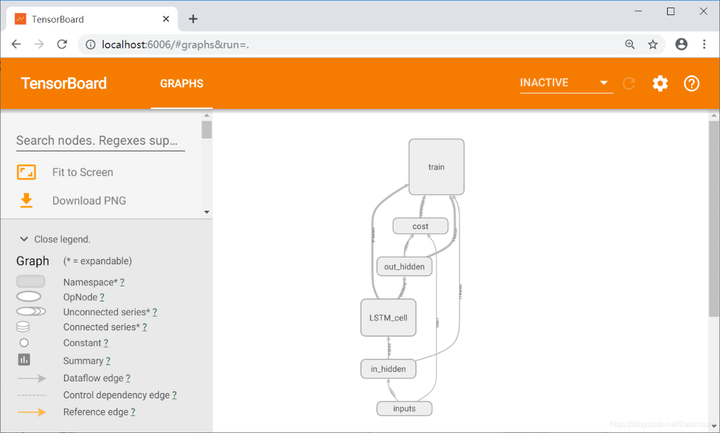
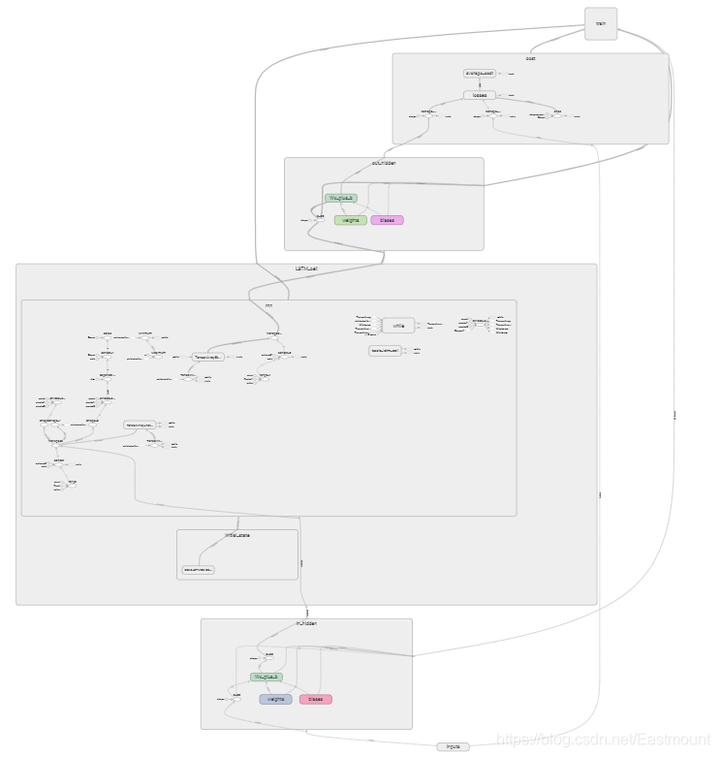
神经网络结构如下图所示,包括输入层、LSTM层、输出层、cost误差计算、train训练等。
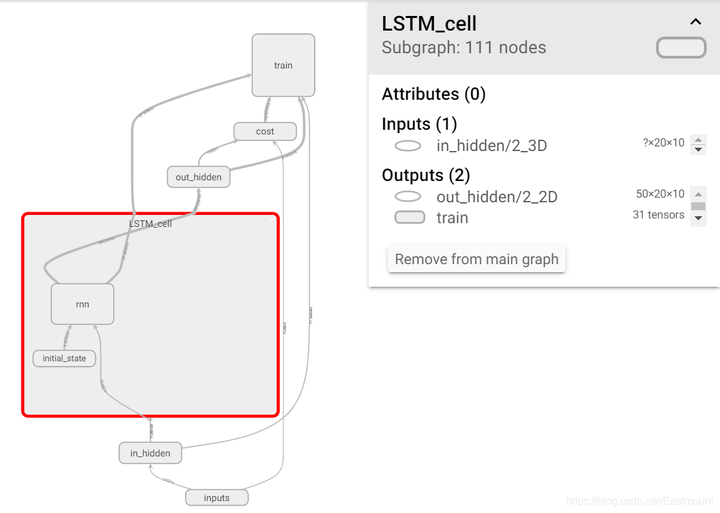
详细结构如下图所示:
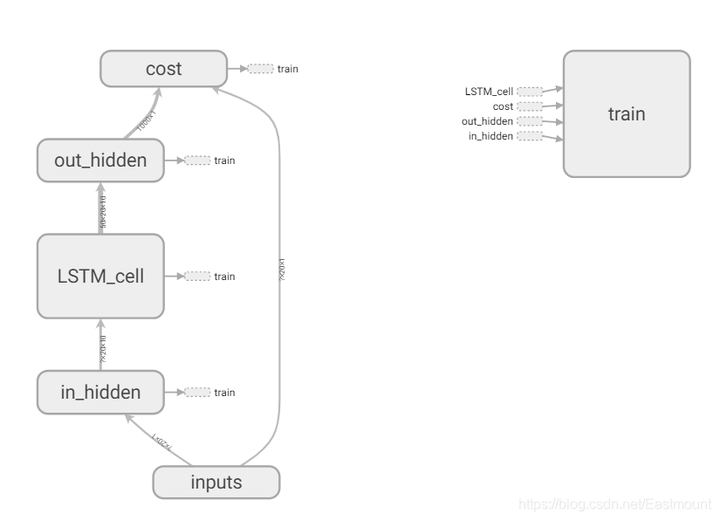
通常我们会将train部分放置一边,选中“train”然后鼠标右键点击“Remove from main graph”。核心结构如下,in_hidden是接受输入的第一层,之后是LSTM_cell,最后是输出层out_hidden。
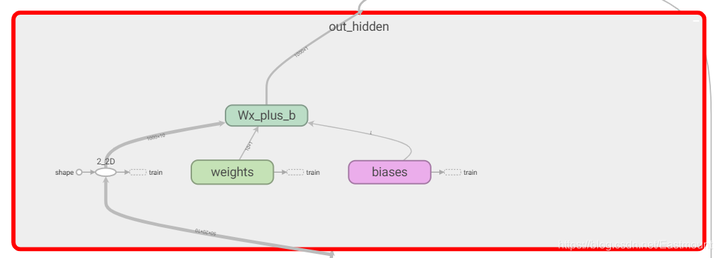
- in_hidden: 包括了权重Weights和biases,计算公式Wx_plus_b。同时,它包括了reshape操作,2_2D和2_3D。
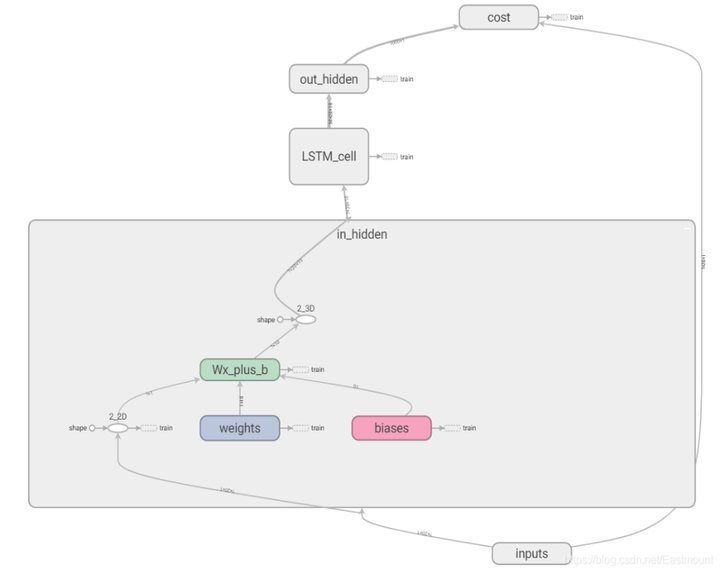
- out_hidden: 包括了权重weights、偏置biases、计算公式Wx_plus_b、二维数据2_2D,并且输出结果为cost。
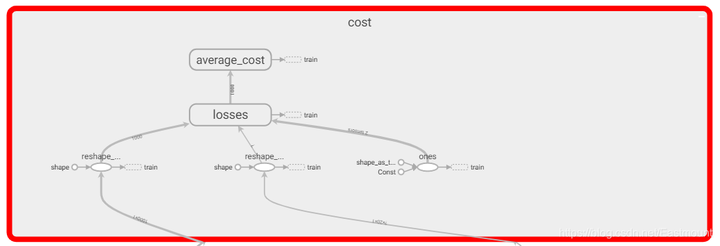
- cost: 计算误差。
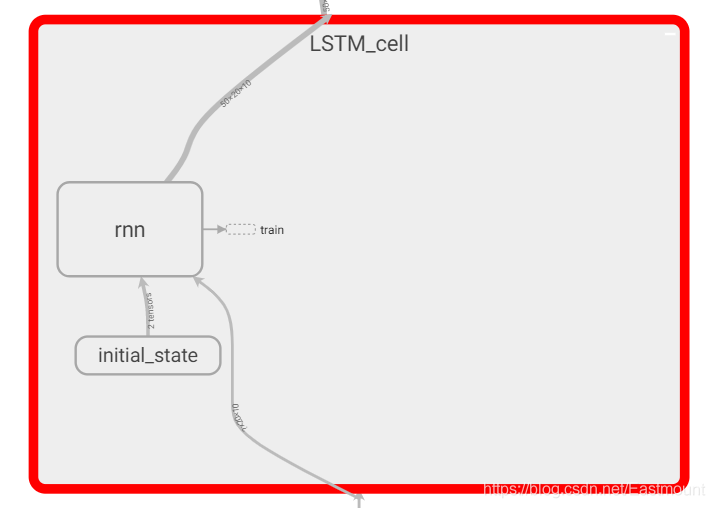
- 中间是LSTM_cell: 包括RNN循环神经网络,初始化initial_state,之后会被state更新替换。
注意版本问题,读者可以结合自己的TensorFlow版本进行适当修改运行。作者版本版本信息为:Python3.6、Anaconda3、Win10、Tensorflow1.15.0。
如果您报错 AttributeError: module ‘tensorflow._api.v1.nn’ has no attribute ‘seq2seq’,这是TensorFlow 版本升级,方法调用更改。解决方式:

如果您报错 TypeError: msr_error() got an unexpected keyword argument ‘labels’,msr_error() 函数得到一个意外的关键参数 ‘lables’。其解决方式:定义msr_error() 函数时,使用 labels,logits 指定,将
def msr_error(self, y_pre, y_target):
return tf.square(tf.subtract(y_pre, y_target))
改为:
def msr_error(self, logits, labels):
return tf.square(tf.subtract(logits, labels))
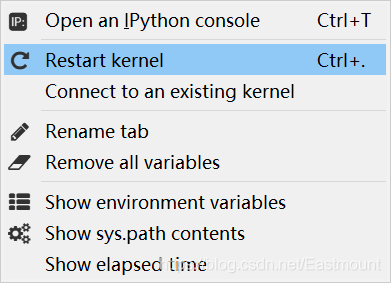
如果您报错 ValueError: Variable in_hidden/weights already exists, disallowed. Did you mean to set reuse=True or reuse=tf.AUTO_REUSE in VarScope? ,则重新启动kernel即可运行。
五.预测及曲线拟合
最后,我们在主函数中编写RNN训练学习和预测的代码。
首先我们来测试cost学习的结果。代码如下,if判断中cell_init_state为前面已初始化的state,之后更新state(model.cell_init_state: state ),其实就是将Final State换成下一个batch的Initial State,从而符合我们定义的结构。
#----------------------------------主函数 训练和预测----------------------------------
if __name__ == '__main__':
# 定义模型并初始化
model = LSTMRNN(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess = tf.Session()
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("logs", sess.graph)
sess.run(tf.initialize_all_variables())
# Tensorboard可视化展现神经网络结果 #------------------------------RNN学习-------------------------------------
# 训练模型
for i in range(200):
# 用seq预测res (序列-seq 结果-res 输入-xs)
seq, res, xs = get_batch()
# 第一步赋值 之后会更新cell_init_state
if i == 0:
feed_dict = {
model.xs: seq,
model.ys: res,
# create initial state (前面cell_init_state已初始化state)
}
else:
feed_dict = {
model.xs: seq,
model.ys: res,
model.cell_init_state: state
# use last state as the initial state for this run
} # state为final_state
_, cost, state, pred = sess.run(
[model.train_op, model.cost, model.cell_final_state, model.pred],
feed_dict=feed_dict) # 每隔20步输出结果
if i % 20 == 0:
print('cost: ', round(cost, 4))
每隔20步输出结果,如下所示,误差从最初的33到最后的0.335,神经网络在不断学习,误差在不断减小。
cost: 33.1673
cost: 9.1332
cost: 3.8899
cost: 1.3271
cost: 0.2682
cost: 0.4912
cost: 1.0692
cost: 0.3812
cost: 0.63
cost: 0.335
接下来增加matplotlib可视化的sin曲线动态拟合过程,最终完整代码如下所示:
# -*- coding: utf-8 -*-
"""
Created on Thu Jan 9 20:44:56 2020
@author: xiuzhang Eastmount CSDN
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt #----------------------------------定义参数----------------------------------
BATCH_START = 0
TIME_STEPS = 20
BATCH_SIZE = 50 # BATCH数量
INPUT_SIZE = 1 # 输入一个值
OUTPUT_SIZE = 1 # 输出一个值
CELL_SIZE = 10 # Cell数量
LR = 0.006
BATCH_START_TEST = 0 # 获取批量数据
def get_batch():
global BATCH_START, TIME_STEPS
# xs shape (50batch, 20steps)
xs = np.arange(BATCH_START, BATCH_START+TIME_STEPS*BATCH_SIZE).reshape((BATCH_SIZE, TIME_STEPS)) / (10*np.pi)
seq = np.sin(xs)
res = np.cos(xs)
BATCH_START += TIME_STEPS # 显示原始曲线
# plt.plot(xs[0, :], res[0, :], 'r', xs[0, :], seq[0, :], 'b--')
# plt.show() # 返回序列seq 结果res 输入xs
return [seq[:, :, np.newaxis], res[:, :, np.newaxis], xs] #----------------------------------LSTM RNN----------------------------------
class LSTMRNN(object):
# 初始化操作
def __init__(self, n_steps, input_size, output_size, cell_size, batch_size):
self.n_steps = n_steps
self.input_size = input_size
self.output_size = output_size
self.cell_size = cell_size
self.batch_size = batch_size # TensorBoard可视化操作使用name_scope
with tf.name_scope('inputs'): #输出变量
self.xs = tf.placeholder(tf.float32, [None, n_steps, input_size], name='xs')
self.ys = tf.placeholder(tf.float32, [None, n_steps, output_size], name='ys')
with tf.variable_scope('in_hidden'): #输入层
self.add_input_layer()
with tf.variable_scope('LSTM_cell'): #处理层
self.add_cell()
with tf.variable_scope('out_hidden'): #输出层
self.add_output_layer()
with tf.name_scope('cost'): #误差
self.compute_cost()
with tf.name_scope('train'): #训练
self.train_op = tf.train.AdamOptimizer(LR).minimize(self.cost) #--------------------------------定义核心三层结构-----------------------------
# 输入层
def add_input_layer(self,):
# 定义输入层xs变量 将xs三维数据转换成二维
# [None, n_steps, input_size] => (batch*n_step, in_size)
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='2_2D')
# 定义输入权重 (in_size, cell_size)
Ws_in = self._weight_variable([self.input_size, self.cell_size])
# 定义输入偏置 (cell_size, )
bs_in = self._bias_variable([self.cell_size,])
# 定义输出y变量 二维形状 (batch * n_steps, cell_size)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# 返回结果形状转变为三维
# l_in_y ==> (batch, n_steps, cell_size)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='2_3D') # cell层
def add_cell(self):
# 选择BasicLSTMCell模型
# forget初始偏置为1.0(初始时不希望forget) 随着训练深入LSTM会选择性忘记
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
# 设置initial_state全为0 可视化操作用name_scope
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
# RNN循环 每一步的输出都存储在cell_outputs序列中 cell_final_state为最终State并传入下一个batch中
# 常规RNN只有m_state LSTM包括c_state和m_state
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False) # 输出层 (类似输入层)
def add_output_layer(self):
# 转换成二维 方能使用W*X+B
# shape => (batch * steps, cell_size)
l_out_x = tf.reshape(self.cell_outputs, [-1, self.cell_size], name='2_2D')
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size, ])
# 返回预测结果
# shape => (batch * steps, output_size)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(l_out_x, Ws_out) + bs_out #--------------------------------定义误差计算函数-----------------------------
def compute_cost(self):
# 使用seq2seq序列到序列模型
# tf.nn.seq2seq.sequence_loss_by_example()
losses = tf.contrib.legacy_seq2seq.sequence_loss_by_example(
[tf.reshape(self.pred, [-1], name='reshape_pred')],
[tf.reshape(self.ys, [-1], name='reshape_target')],
[tf.ones([self.batch_size * self.n_steps], dtype=tf.float32)],
average_across_timesteps=True,
softmax_loss_function=self.msr_error,
name='losses'
)
# 最终得到batch的总cost 它是一个数字
with tf.name_scope('average_cost'):
# 整个TensorFlow的loss求和 再除以batch size
self.cost = tf.div(
tf.reduce_sum(losses, name='losses_sum'),
self.batch_size,
name='average_cost')
tf.summary.scalar('cost', self.cost) # 该函数用于计算
# 相当于msr_error(self, y_pre, y_target) return tf.square(tf.sub(y_pre, y_target))
def msr_error(self, logits, labels):
return tf.square(tf.subtract(logits, labels))
# 误差计算
def _weight_variable(self, shape, name='weights'):
initializer = tf.random_normal_initializer(mean=0., stddev=1.,)
return tf.get_variable(shape=shape, initializer=initializer, name=name)
# 偏置计算
def _bias_variable(self, shape, name='biases'):
initializer = tf.constant_initializer(0.1)
return tf.get_variable(name=name, shape=shape, initializer=initializer) #----------------------------------主函数 训练和预测----------------------------------
if __name__ == '__main__':
# 定义模型并初始化
model = LSTMRNN(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess = tf.Session()
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("logs", sess.graph)
sess.run(tf.initialize_all_variables())
# Tensorboard可视化展现神经网络结果 #------------------------------RNN学习-------------------------------------
# 交互模式启动
plt.ion()
plt.show() # 训练模型
for i in range(200):
# 用seq预测res (序列-seq 结果-res 输入-xs)
seq, res, xs = get_batch()
# 第一步赋值 之后会更新cell_init_state
if i == 0:
feed_dict = {
model.xs: seq,
model.ys: res,
# create initial state (前面cell_init_state已初始化state)
}
else:
feed_dict = {
model.xs: seq,
model.ys: res,
model.cell_init_state: state
# use last state as the initial state for this run
} # state为final_state
_, cost, state, pred = sess.run(
[model.train_op, model.cost, model.cell_final_state, model.pred],
feed_dict=feed_dict) # plotting
# 获取第一批数据xs[0,:] 获取0到20区间的预测数据pred.flatten()[:TIME_STEPS]
plt.plot(xs[0, :], res[0].flatten(), 'r', xs[0, :], pred.flatten()[:TIME_STEPS], 'b--')
plt.ylim((-1.2, 1.2))
plt.draw()
plt.pause(0.3) # 每隔20步输出结果
if i % 20 == 0:
print('cost: ', round(cost, 4))
# result = sess.run(merged, feed_dict)
# writer.add_summary(result, i)
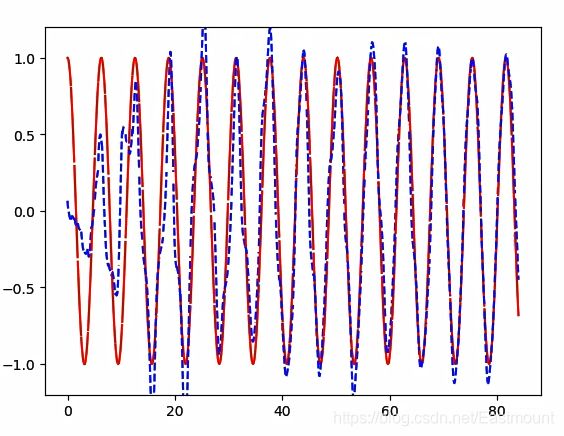
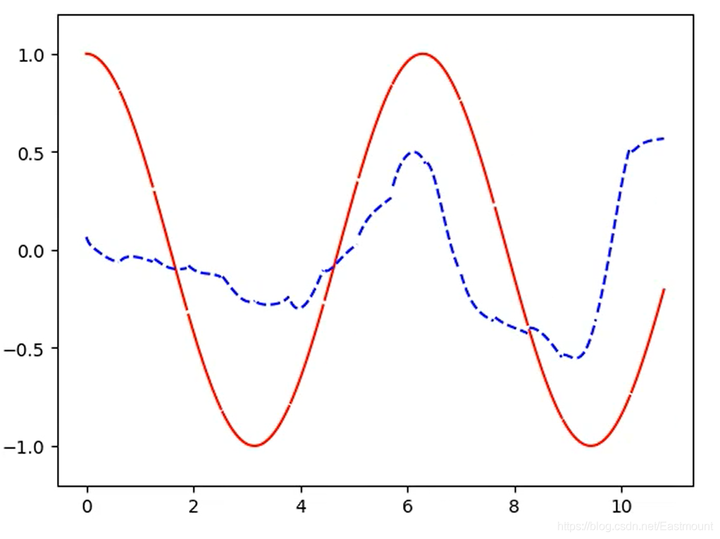
写道这里,这篇文章终于写完了。文章非常长,但希望对您有所帮助。LSTM RNN通过一组数据预测另一组数据。预测效果如下图所示,红色的实线表示需要预测的线,蓝色的虚线表示RNN学习的线,它们在不断地逼近,蓝线学到了红线的规律,最终将蓝线基本拟合到红线上。

六.总结
本文介绍完了,更多TensorFlow深度学习文章会继续分享,接下来我们会分享监督学习、GAN、机器翻译、文本识别、图像识别、语音识别等内容。如果读者有什么想学习的,也可以私聊我,我去学习并应用到你的领域。
最后,希望这篇基础性文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵~作为人工智能的菜鸟,我希望自己能不断进步并深入,后续将它应用于图像识别、网络安全、对抗样本等领域,指导大家撰写简单的学术论文,一起加油!
代码下载地址(欢迎大家关注点赞):
循环神经网络LSTM RNN回归:sin曲线预测的更多相关文章
- 大话循环神经网络(RNN)
在上一篇文章中,介绍了 卷积神经网络(CNN)的算法原理,CNN在图像识别中有着强大.广泛的应用,但有一些场景用CNN却无法得到有效地解决,例如: 语音识别,要按顺序处理每一帧的声音信息,有些结果 ...
- 十 | 门控循环神经网络LSTM与GRU(附python演练)
欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习.深度学习的知识! 目录: 门控循环神经网络简介 长短期记忆网络(LSTM) 门控制循环单元(GRU) ...
- 深度学习项目——基于循环神经网络(RNN)的智能聊天机器人系统
基于循环神经网络(RNN)的智能聊天机器人系统 本设计研究智能聊天机器人技术,基于循环神经网络构建了一套智能聊天机器人系统,系统将由以下几个部分构成:制作问答聊天数据集.RNN神经网络搭建.seq2s ...
- Tensorflow 循环神经网络 基本 RNN 和 LSTM 网络 拟合、预测sin曲线
时序预测一直是比较重要的研究问题,在统计学中我们有各种的模型来解决时间序列问题,但是最近几年比较火的深度学习中也有能解决时序预测问题的方法,另外在深度学习领域中时序预测算法可以解决自然语言问题等. 在 ...
- Pytorch循环神经网络LSTM时间序列预测风速
#时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大 ...
- 【学习笔记】循环神经网络(RNN)
前言 多方寻找视频于博客.学习笔记,依然不能完全熟悉RNN,因此决定还是回到书本(<神经网络与深度学习>第六章),一点点把啃下来,因为这一章对于整个NLP学习十分重要,我想打好基础. 当然 ...
- 深度学习之循环神经网络(RNN)
循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络,适合用于处理视频.语音.文本等与时序相关的问题.在循环神经网络中,神经元不但可以接收其他神经元 ...
- 循环神经网络-LSTM
LSTM(Long Short-Term Memory)是长短期记忆网络,是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件. LSTM能够很大程度上缓解长期依赖的问题. ...
- 循环神经网络(RNN)
1. 场景与应用 在循环神经网络可以用于文本生成.机器翻译还有看图描述等,在这些场景中很多都出现了RNN的身影. 2. RNN的作用 传统的神经网络DNN或者CNN网络他们的输入和输出都是 ...
随机推荐
- solr(CVE-2019-17558)远程命令执行
影响版本 Apache Solr 5.x到8.2.0版本 测试 https://github.com/jas502n/CVE-2019-0193
- xxe 回显与无回显
转载学习于红日安全 一.有回显 (1)直接将外部实体引用的URI设置为敏感目录 <!DOCTYPE foo [<!ELEMENT foo ANY > <!ENTITY xxe ...
- openssl not found 离线安装的openssl问题
离线安装问题 正常我们在Linux中按照 nginx的openssl依赖都是通过 yum来安装的,但是由于一些特殊的服务器公司不让服务器连接互联网,所以就导致我们必须通过离线方式来进行安装,但是我们离 ...
- Windows 系统安装 git基础小白的简单操作包含基本输入命令
首先 去官网下载git应用 https://git-scm.com/downloads 点击前往 安装的操作也比较简单,一直点击下一步 安装完成之后 在空白桌面点击是否有 Git Gui ...
- Ubuntu Server安装telnet服务时"Unable to locate package telnetd"解决方法
装好Ubuntu Server 12.04后,用apt-get安装telnetd报"E: Unable to locate package telnetd",解决方法如下: 虚拟机 ...
- Nginx搭建与相关配置
目录 一.Nginx简介 1.1 概述 1.2 Nginx与Apache的差异 二.编译安装Nginx服务 2.1 将nginx软件包传到主机/opt目录下 2.2.安装依赖包 2.3.添加模块编译安 ...
- NOIP 模拟 $13\; \text{卡常题}$
题解 一道环套树的最小点覆盖题目,所谓环套树就是有在 \(n\) 个点 \(n\) 条边的无向联通图中存在一个环 我们可以发现其去掉一条环上的边后就是一棵树 那么对于此题,我们把所有 \(x\) 方点 ...
- 自定义Vue&Element组件,实现用户选择和显示
在我们很多前端业务开发中,往往为了方便,都需要自定义一些用户组件,一个是减少单一页面的代码,提高维护效率:二个也是方便重用.本篇随笔介绍在任务管理操作中,使用自定义Vue&Element组件, ...
- flutter canvas圆圈转圈动画
import 'dart:math'; import 'dart:ui'; import 'package:flutter/material.dart'; void main() => runA ...
- 3、二进制安装K8s之部署kube-apiserver
二进制安装K8s之部署kube-apiserver 一.生成 kube-apiserver 证书 1.自签证书颁发机构(CA) cat > ca-config.json <<EOF ...